







Spark SQL
数据读写
Hive
Parquet
JSON
RDD
JDBC/ODBC
用户自定义函数(UDF)
UDF可以轻松实现复杂操作以及它们的反复使用。用户可以在dataframe的select(),withColumn(),以及SQL中的udf()调用Python中注册的自定义函数,简单来说就是对于复杂一些的处理,用户不需要在SQL中进行直接编程来实现,而是使用Python实现该功能,并作为一个UDF在SQL中调用。PySpark同时支持Spark SQL以及Hive的UDF。需要注意的是,由于对于Spark而言,UDF相当于一个黑盒,Spark内部对dataframe的优化无法应用在UDF上。因此UDF本身的开销比较大,原则上如果能使用其他方式达成目的,尽量不要使用UDF。
Spark SQL UDF
以MovieLens 1M数据集为例,首先将movies数据集读入PySpark。
from pyspark.sql import SparkSession
from pyspark import SparkConf, SparkContext
conf = SparkConf().setMaster('local').setAppName('movielens')
sc = SparkContext(conf=conf)
spark = SparkSession(sc)
movies = spark.read.csv('movielens_1m/movies.csv', header=True)
movies.show(20)
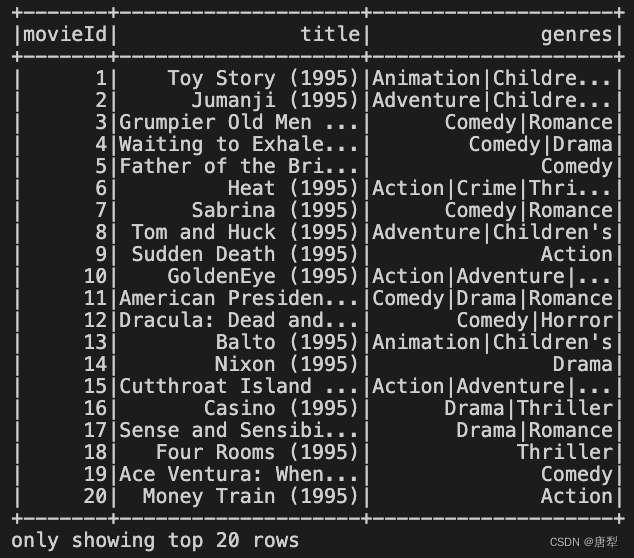
由于每一部电影的上映年份都是作为title的一部分拼在电影名称的最后的,因此我们可以通过一个字符串处理的函数将上映年份从标题中提取出来。
import datetime
# extract release year from the title
def extract_release_year(title):
title = title.strip()
title_list = title.split('(')
year = None
if len(title_list) >= 2:
try:
year = int(title_list[-1].strip(')').strip())
except ValueError:
return year
else:
year = None if year > datetime.date.today().year or year < 1000 else year
return year
现在将这个提取年份的函数作为一个UDF,使用withColumn()创建一个新的数据列。在调用UDF时,需要对返回值的类型进行声明。
from pyspark.sql.functions import udf
from pyspark.sql.types import StringType, IntegerType
udf_year_extract = udf(extract_release_year, IntegerType())
movies.withColumn('releaseYear', udf_year_extract('title')).show(20)
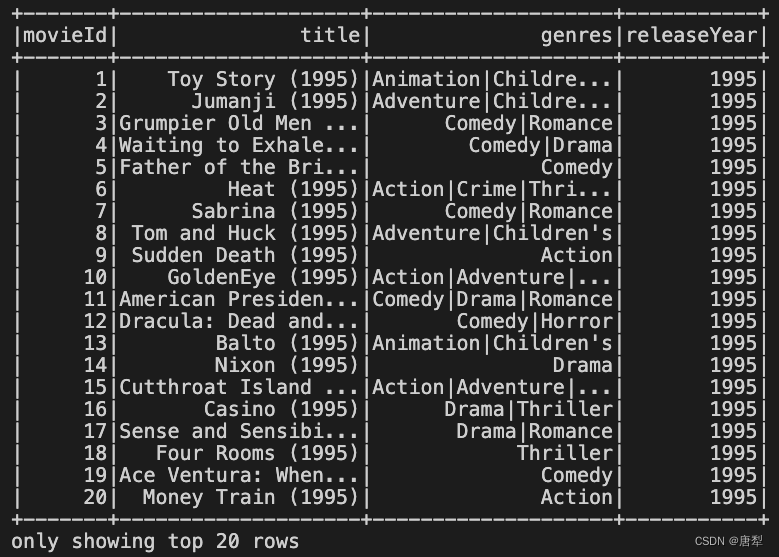
由于udf()接收的参数就是一个Python函数,因此你也可以将上面的步骤以装饰器的形式实现,之后将目标列直接传入该函数即可。两者效果是完全一样的:
from pyspark.sql.functions import col
@udf(returnType=IntegerType())
def extract_release_year(title):
title = title.strip()
title_list = title.split('(')
year = None
if len(title_list) >= 2:
try:
year = int(title_list[-1].strip(')').strip())
except ValueError:
return year
else:
year = None if year > datetime.date.today().year or year < 1000 else year
return year
movies.withColumn('releaseYear', udf_year_extract(col('title'))).show(20)















 1370
1370











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









