






👉 这是一个或许对你有用的社群
🐱 一对一交流/面试小册/简历优化/求职解惑,欢迎加入「芋道快速开发平台」知识星球。下面是星球提供的部分资料:
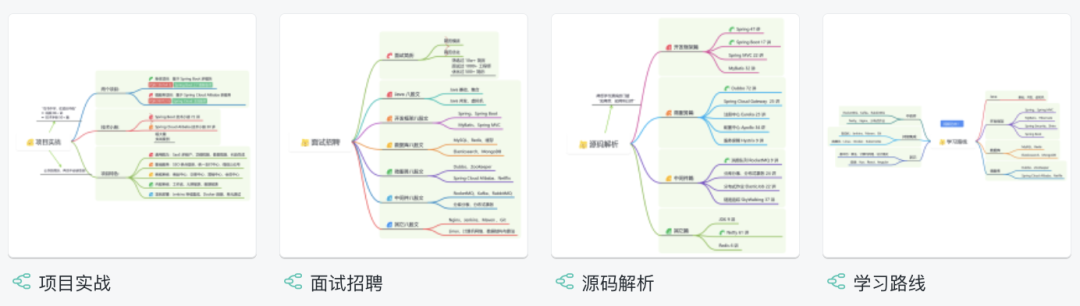
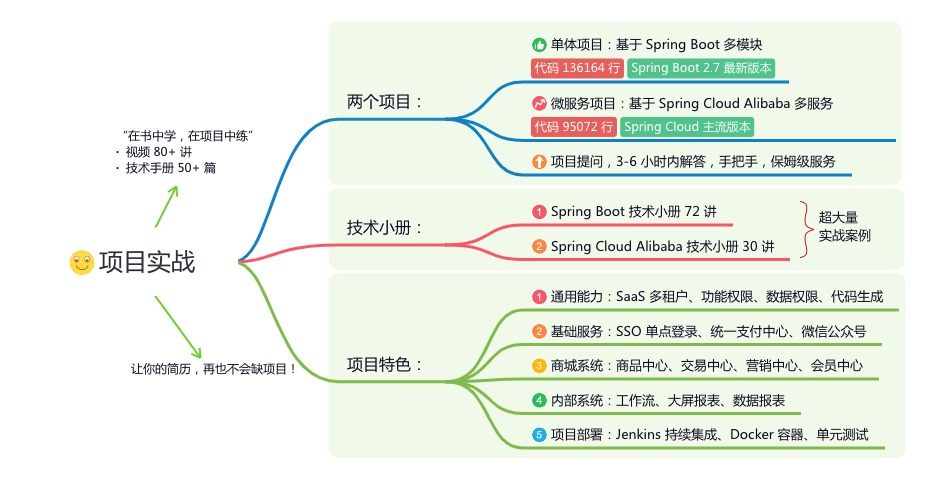
《项目实战(视频)》:从书中学,往事上“练”
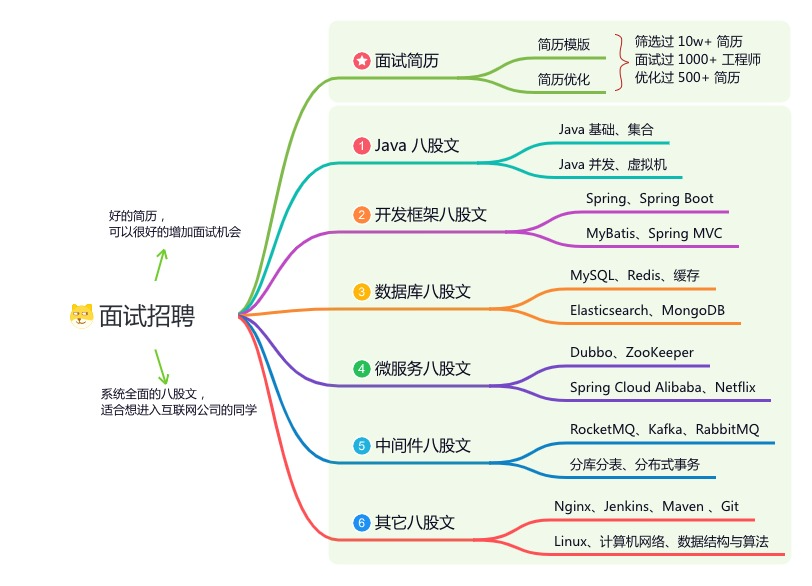
《互联网高频面试题》:面朝简历学习,春暖花开
《架构 x 系统设计》:摧枯拉朽,掌控面试高频场景题
《精进 Java 学习指南》:系统学习,互联网主流技术栈
《必读 Java 源码专栏》:知其然,知其所以然
👉这是一个或许对你有用的开源项目
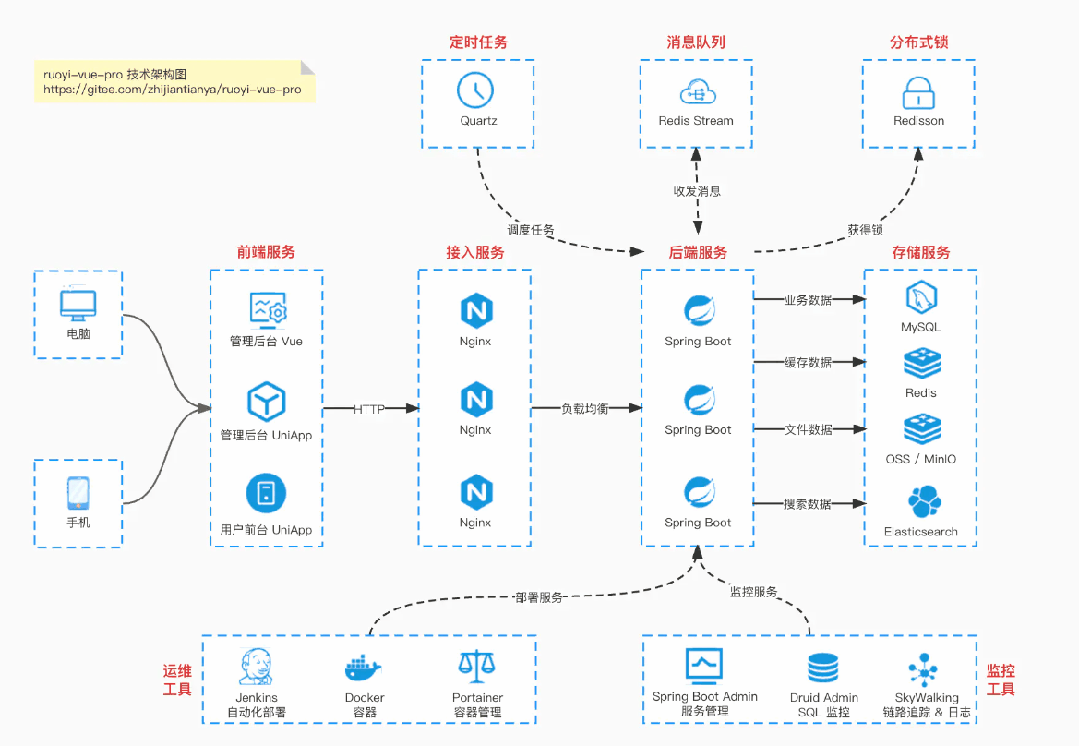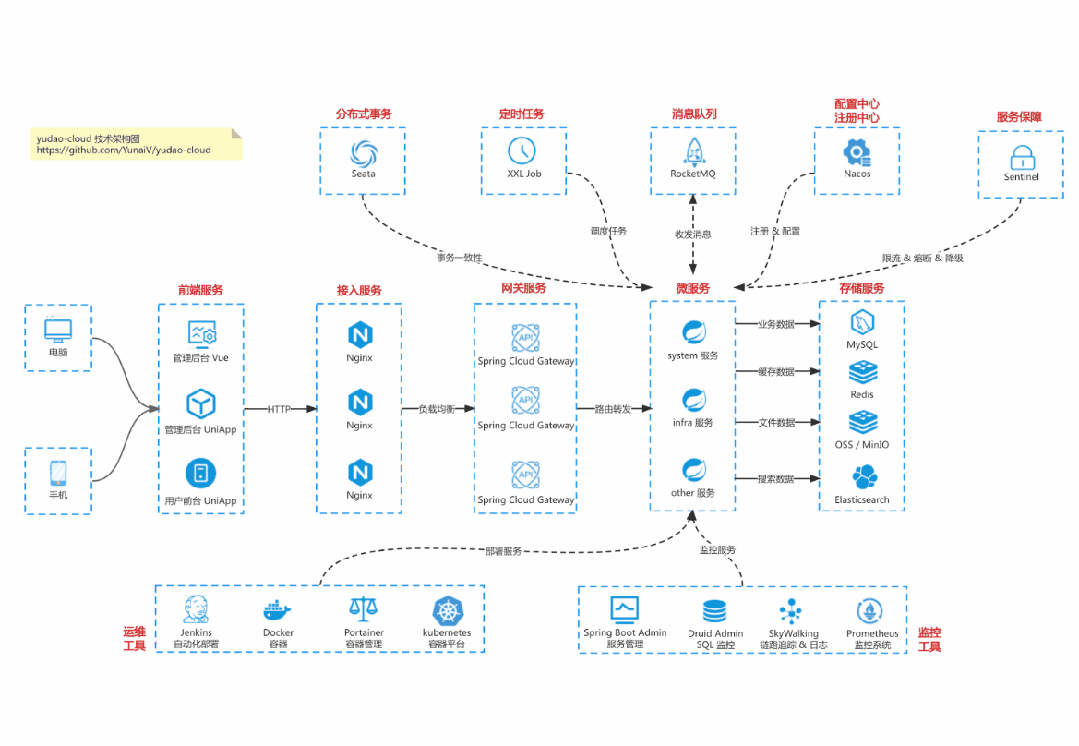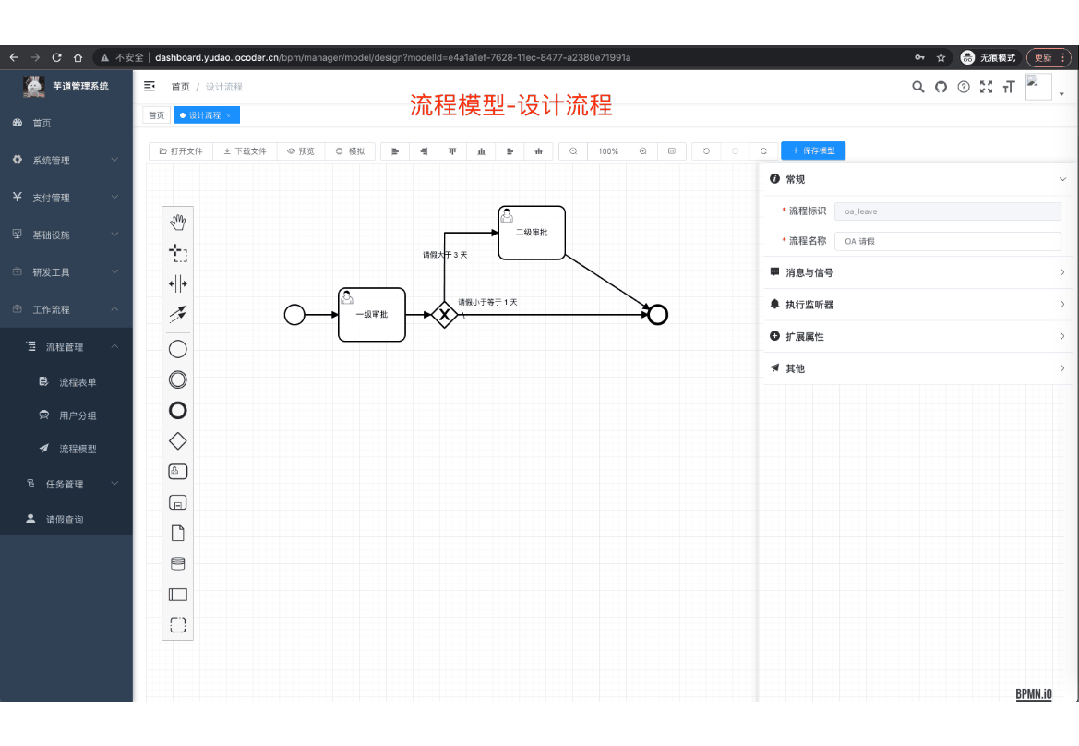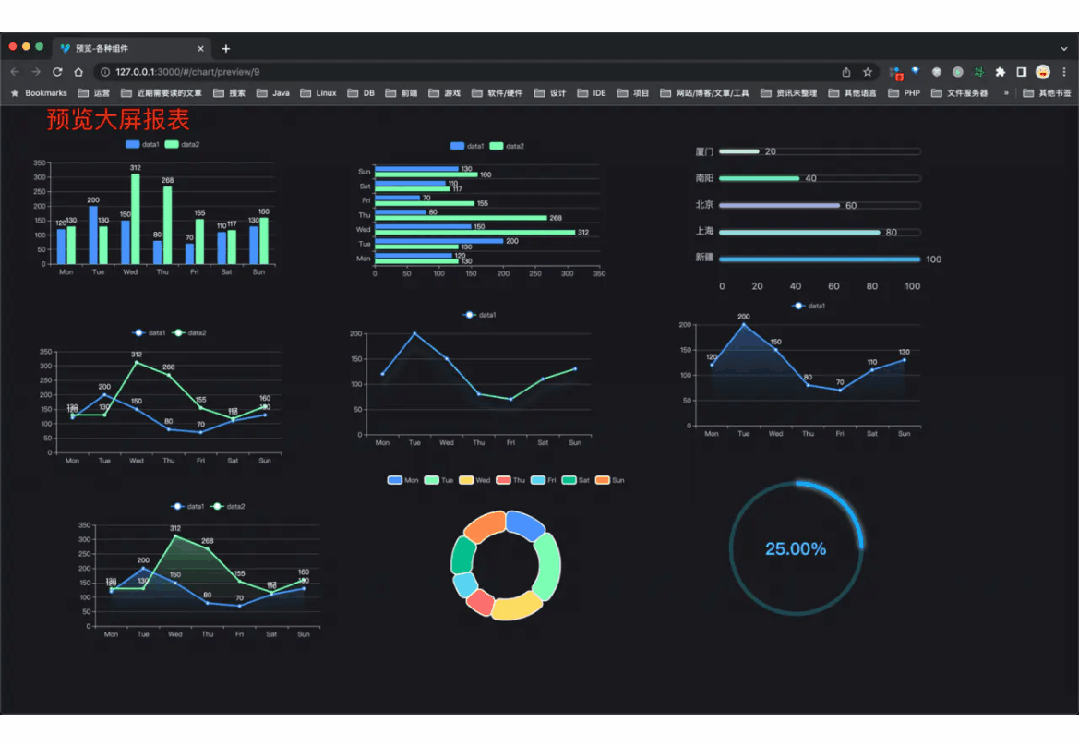
国产 Star 破 10w+ 的开源项目,前端包括管理后台 + 微信小程序,后端支持单体和微服务架构。
功能涵盖 RBAC 权限、SaaS 多租户、数据权限、商城、支付、工作流、大屏报表、微信公众号、CRM 等等功能:
Boot 仓库:https://gitee.com/zhijiantianya/ruoyi-vue-pro
Cloud 仓库:https://gitee.com/zhijiantianya/yudao-cloud
视频教程:https://doc.iocoder.cn
【国内首批】支持 JDK 21 + SpringBoot 3.2.2、JDK 8 + Spring Boot 2.7.18 双版本
来源:juejin.cn/post/
7336799230978261029

批量处理是接口调优中常见的策略之一,可以减少数据库和网络开销,提高处理效率。
一、必要性
进行批量处理优化是接口调优的一项重要策略,它可以带来多方面的性能优势。
以下是一些批量处理优化的主要原因:
减少数据库访问次数 : 批量处理将多个操作合并成一个批次执行,从而减少了与数据库的交互次数。数据库访问通常是接口调优中的瓶颈之一,通过批量处理可以显著降低数据库连接和关闭的开销,提高性能。
降低网络开销 : 数据库操作涉及网络通信,而网络通信的开销是相对较高的。通过批量处理,可以在一次通信中传递多个操作,减少了网络开销,特别是在高延迟的网络环境中更为明显。
提高事务效率 : 在一些需要事务的场景下,批量处理可以减少事务的开始和提交次数,从而提高整体事务的效率。减少事务的嵌套和开销对于数据库性能和并发控制有积极影响。
降低资源消耗 : 单独执行大量小规模的操作可能会导致过多的资源消耗,如数据库连接池中的连接数。批量处理可以减少这种资源的浪费,提高系统的稳定性。
优化内存使用 : 批量处理可以更好地利用内存,减少了单个操作导致的内存分配和回收开销。这对于处理大数据量时尤为重要,可以降低内存压力。
提高并发度 : 批量处理可以在一定程度上提高并发度。在一次批量操作中,可以并发处理多个批次,从而加速整体处理速度,特别是在多线程或异步操作的情况下。
降低锁的竞争 : 在涉及事务的情况下,批量处理可以降低对数据库表的锁的竞争。减少锁竞争可以提高系统的并发性,减少潜在的死锁和性能问题。
提高整体性能 : 通过以上方式,批量处理可以有效地提高整体接口的性能,降低系统的响应时间,提升用户体验。
批量处理优化是一种综合性的性能提升手段,适用于处理大量数据的场景。在设计和实现接口时,考虑采用批量处理的策略,可以有效地降低系统的负载,提高性能,同时减少资源的消耗。
基于 Spring Boot + MyBatis Plus + Vue & Element 实现的后台管理系统 + 用户小程序,支持 RBAC 动态权限、多租户、数据权限、工作流、三方登录、支付、短信、商城等功能
项目地址:https://github.com/YunaiV/ruoyi-vue-pro
视频教程:https://doc.iocoder.cn/video/
二、建议
以下是关于接口调优中批量处理的一些建议:
2.1 批量数据库操作
尽量减少数据库交互次数,使用批量插入、更新或删除操作,以减小数据库负担。数据库的批量操作通常比单条操作更高效。通过减少数据库交互次数,批量处理可以显著提高接口性能。
以下是一些进行批量数据库操作的通用方法:
1) 使用批处理语句
大多数数据库支持批处理语句,通过将多个操作合并成一个批量操作,减少了与数据库的通信次数。例如,在 Java 中,使用 JDBC 可以通过 addBatch 和 executeBatch 来执行批处理语句。
// 使用JDBC批处理插入数据
Connection connection = // 获取数据库连接
Statement statement = connection.createStatement();
for (int i = 0; i < data.size(); i++) {
statement.addBatch("INSERT INTO table_name (column1, column2) VALUES ('value1', 'value2')");
}
int[] result = statement.executeBatch();2) 使用 ORM 框架的批量操作
如果我们使用了对象关系映射(ORM)框架,如 Hibernate 或 MyBatis,通常它们提供了批量插入、更新和删除的机制。这些框架会优化生成的 SQL 语句,以实现批处理效果。
// 使用Hibernate批量插入数据
Session session = // 获取Hibernate Session
Transaction transaction = session.beginTransaction();
for (Entity entity : entities) {
session.save(entity);
}
transaction.commit()3) 使用存储过程
将多个数据库操作放在一个存储过程中,通过一次调用执行多个操作。存储过程通常在数据库端执行,可以减少数据在网络中的传输。
4) 使用数据库工具
一些数据库系统提供了专门的工具或语法用于批量处理,如 MySQL 的 LOAD DATA INFILE 语句。使用这些工具可以快速地导入大量数据。
5) 使用批量更新的优化方式
对于大规模的更新操作,考虑使用批量更新的优化方式,例如使用 CASE WHEN 语句。
UPDATE table_name
SET column1 = CASE WHEN id = 1 THEN 'value1'
WHEN id = 2 THEN 'value2'
ELSE column1 END,
column2 = CASE WHEN id = 1 THEN 'value3'
WHEN id = 2 THEN 'value4'
ELSE column2 END
WHERE id IN (1, 2);6) 分批次处理
将大量数据分成小批次进行处理,避免一次性处理大量数据。这对于大型数据集和复杂业务逻辑有利。
7) 使用批处理框架
对于大规模的数据处理,可以考虑使用专业的批处理框架,如 Spring Batch 等。这些框架提供了丰富的功能和配置选项,可以更好地管理和优化批量处理任务。
在进行批量数据库操作时,需根据具体场景和需求选择适当的方式。确保在设计和实现过程中考虑事务管理、异常处理和性能监控,以保证批处理的正确性和高效性。
2.2 合并网络请求
如果接口涉及到与其他服务通信,考虑将多个请求合并为一个,以减小网络开销。这可以通过合并请求参数、使用批量接口或 GraphQL 等方式实现。特别适用于需要从服务端获取多个资源或执行多个操作的情况。通过减少网络请求次数,可以降低延迟和提高性能。
以下是一些合并网络请求的方法:
1) 使用HTTP/2 或 HTTP/3
这些协议支持多路复用,允许多个请求同时在同一连接上进行,避免了建立多个连接的开销。这有助于减少网络请求的总体延迟。
2) 使用异步请求
在客户端使用异步请求,可以并发地发送多个请求。这可以通过 JavaScript 中的 XMLHttpRequest 对象或 fetch API 来实现。在服务端,也可以考虑使用异步框架来处理并发请求。
3) 合并资源请求
将多个资源请求合并为一个请求。例如,将多个 CSS 或 JavaScript 文件合并为一个文件,减少页面加载时的请求数。
4) 使用批处理请求
将多个操作合并成一个请求,服务端一次性处理所有操作。这可以通过设计相应的接口或使用批处理框架来实现。
// 例子:合并多个查询请求
{
"requests": [
{"type": "getUser", "userId": 1},
{"type": "getOrders", "userId": 1}
]
}5) 使用 GraphQL
GraphQL 是一种查询语言,允许客户端指定需要的数据,从而避免了多个接口请求。服务端可以根据一个 GraphQL 查询来满足客户端的多个请求。
// 例子:GraphQL查询
query {
getUser(id: 1) {
name
email
}
getOrders(userId: 1) {
orderId
orderDate
}
}6) 缓存请求结果
对于可能重复的请求,可以在客户端或服务端进行结果的缓存,避免重复的请求。
使用 WebSocket:WebSocket 提供了双向通信的能力,允许在同一连接上进行多个请求和响应。这对于实时应用程序和推送通知很有用。
7) 减少不必要的请求
在设计接口时,避免设计过多、过于细粒度的接口,减少不必要的请求。只请求客户端需要的数据,避免获取冗余信息。
合并网络请求需要在设计接口和客户端请求逻辑时进行权衡。在某些场景下,合并请求可以显著提高性能,但在其他场景下可能会引入复杂性。因此,需要根据具体的业务需求和性能要求进行综合考虑。
2.3 使用批处理任务
将相关的任务组织成批处理任务,以提高任务执行的效率。这对于异步任务、定时任务等场景非常有效。特别是在需要处理大量数据或执行耗时操作的情况下。
以下是一些建议和示例,说明如何使用批处理任务进行优化:
1) 明确定义批处理的操作
在开始批处理任务之前,明确定义需要进行批处理的具体操作。这可能包括数据库插入、更新、删除,文件处理,网络请求等。
2) 分批次处理数据
将大量数据分成小批次进行处理,而不是一次性处理整个数据集。这可以帮助降低内存使用,提高系统稳定性,同时也有助于并发处理。
3) 使用批处理框架
利用批处理框架可以简化批处理任务的管理和执行。例如,Java 中的 Spring Batch 框架提供了强大的批处理功能,包括事务管理、错误处理、并发执行等。
// 使用Spring Batch的示例
@Configuration
@EnableBatchProcessing
public class BatchConfiguration {
@Autowired
private JobBuilderFactory jobBuilderFactory;
@Autowired
private StepBuilderFactory stepBuilderFactory;
@Bean
public ItemReader<String> itemReader() {
// 定义数据读取逻辑
}
@Bean
public ItemProcessor<String, String> itemProcessor() {
// 定义数据处理逻辑
}
@Bean
public ItemWriter<String> itemWriter() {
// 定义数据写入逻辑
}
@Bean
public Step myStep() {
return stepBuilderFactory.get("myStep")
.<String, String>chunk(10) // 指定批处理的大小
.reader(itemReader())
.processor(itemProcessor())
.writer(itemWriter())
.build();
}
@Bean
public Job myJob() {
return jobBuilderFactory.get("myJob")
.start(myStep())
.build();
}
}4) 优化数据库批处理
对于数据库批处理,使用数据库提供的批量操作语句(如 JDBC 的 addBatch和executeBatch)或者 ORM 框架的批处理功能。这可以显著减少数据库访问次数。
5) 并行处理批次
在处理数据的过程中,考虑在批次之间进行并行处理。这可以通过多线程、异步任务等方式实现,提高整体处理速度。
6) 容错和事务管理
在设计批处理任务时,考虑容错机制和事务管理。保证任务的稳定性,避免因异常导致任务无法正常完成。
7) 定时执行
针对需要定期执行的批处理任务,使用定时任务来触发批处理任务的执行。这有助于在非高峰时段执行任务,减少对系统其他功能的影响。
8) 合理设置批处理的大小
根据具体场景,合理设置批处理的大小,考虑到内存使用、数据库压力和系统并发度等因素。
使用批处理任务可以有效地优化接口性能,尤其是在处理大规模数据或需要长时间执行的任务时。选择合适的批处理框架和优化策略,结合系统需求和性能目标,可以提高系统的稳定性和响应性。
2.4 合并小文件
如果接口涉及到文件操作,考虑将多个小文件合并为一个大文件,减小文件操作的开销。这对于文件上传、下载等场景有帮助。合并小文件可以降低文件数量,减小文件系统的开销,提高文件操作的效率。
以下是一些建议和方法,说明如何合并小文件:
1) 批量读取和写入
使用缓冲流一次性读取多个小文件的内容,并将它们合并写入到一个大文件中。这样可以减少文件读写的次数,提高效率。
// Java示例:合并多个小文件到一个大文件
try (BufferedOutputStream outputStream = new BufferedOutputStream(new FileOutputStream("mergedFile.txt"))) {
List<String> smallFileNames = // 获取小文件的文件名列表
for (String fileName : smallFileNames) {
try (BufferedInputStream inputStream = new BufferedInputStream(new FileInputStream(fileName))) {
byte[] buffer = new byte[1024];
int bytesRead;
while ((bytesRead = inputStream.read(buffer)) != -1) {
outputStream.write(buffer, 0, bytesRead);
}
}
}
} catch (IOException e) {
e.printStackTrace();
}2) 使用文件合并工具
对于大规模的文件合并操作,可以考虑使用专门的文件合并工具。这些工具通常能够并行处理文件合并操作,提高整体效率。
3) 合并文件路径存储
如果小文件较多,并且它们分布在不同的目录下,可以将这些目录逐一合并,形成一个更大的目录结构。这有助于降低文件系统的索引开销。
4) 使用压缩文件
将小文件打包成一个压缩文件,减少文件数量。这可以通过使用 ZIP、TAR 等压缩格式来实现。需要注意的是,压缩文件可能会增加读取时的解压开销。
5) 合并文件在内存中处理
如果小文件的总大小可以容纳在内存中,可以考虑将它们读取到内存中进行合并处理,然后将结果写入一个大文件。
6) 使用 MapReduce
对于大规模分布式文件处理,可以考虑使用 MapReduce 框架。MapReduce 可以在分布式环境中并行处理大量小文件的合并任务。
7) 使用数据库存储
将小文件的内容存储在数据库中,并通过数据库操作进行合并。这种方式适用于需要对文件内容进行复杂查询和处理的场景。
8) 考虑合并策略
根据实际需求,选择合适的合并策略。有时可以按照文件名、时间戳等进行有序合并,以便更容易管理和维护。
在合并小文件时,需要根据具体的业务需求和性能目标选择合适的方法。确保在实施合并策略时,对文件的内容、结构和后续处理要求有清晰的了解,以避免引入潜在问题。
2.5 合并数据查询
在数据库查询中,避免在循环中逐个查询,而是使用 IN 查询或者 JOIN 操作,将多个查询合并成一个,减少数据库查询次数。 在接口调优中,合并数据查询是一项关键的优化策略,特别是在需要获取多个相关数据的情况下。通过合并查询可以减少数据库访问次数,降低系统负担,提高性能。以下是一些合并数据查询的方法:
1) 使用 JOIN 语句
如果数据分布在不同的表中,并且之间存在关联关系,使用 SQL 的 JOIN 语句可以在一次查询中获取多个表的相关数据,避免多次单表查询。
-- 示例:使用INNER JOIN合并两个表的查询
SELECT users.id, users.name, orders.order_id, orders.order_date
FROM users
INNER JOIN orders ON users.id = orders.user_id
WHERE users.id = 1;2) 采用子查询
在某些情况下,使用子查询可以将多个查询合并为一个,减少数据库访问次数。确保使用子查询时考虑到性能和查询的复杂性。
-- 示例:使用子查询合并两次查询
SELECT id, name, (SELECT COUNT(*) FROM orders WHERE user_id = users.id) AS order_count
FROM users
WHERE id = 1;3) 使用 IN 或 EXISTS 子句
使用 IN 或 EXISTS 子句可以合并多个查询条件,将它们合并成一个查询。
-- 示例:使用IN合并两次查询
SELECT id, name
FROM users
WHERE id IN (1, 2, 3);
SELECT order_id, order_date
FROM orders
WHERE user_id IN (1, 2, 3);4) 缓存查询结果
对于一些不经常变化的数据,可以考虑将查询结果缓存起来,避免多次查询相同的数据。
5) 使用存储过程
将多个查询逻辑封装在存储过程中,通过一次调用存储过程获取所有需要的数据。
6) 使用 ORM 框架的关联查询
对象关系映射(ORM)框架如 Hibernate 或 MyBatis 通常提供了关联查询的功能,能够方便地在一次查询中获取相关联的数据。
7) 合并多个接口请求
对于 Web 服务或 RESTful 接口,可以考虑设计一个接口,通过一次请求获取多个相关数据,而不是分多次请求获取。
在进行合并数据查询时,需要综合考虑数据库表结构、查询性能、业务需求以及系统的并发情况。选择适当的合并策略可以显著提高系统性能,降低响应时间。
2.6 分页批量处理
对于大量数据的处理,使用分页机制进行批量处理,以避免一次性处理大量数据导致内存占用过高。通过将数据分成适当大小的页,可以有效地控制内存使用,并提高系统的性能。
以下是一些分页批量处理的方法:
1) 分页查询数据库
对于大量数据存储在数据库中的情况,使用分页查询是一种常见的方式。通过在查询语句中使用 LIMIT 和 OFFSET,可以控制每次查询返回的数据量和起始位置。
-- 示例:分页查询数据库
SELECT * FROM orders
ORDER BY order_date
LIMIT 10 OFFSET 0; -- 第一页
SELECT * FROM orders
ORDER BY order_date
LIMIT 10 OFFSET 10; -- 第二页2) 使用分页参数
在接口中引入分页参数,允许客户端指定要获取的页数和每页的数据量。这样可以根据需求调整分页大小。
// 示例:接口请求中包含分页参数
{
"page": 1,
"pageSize": 10
}3) 处理器中使用分页逻辑
在后端处理器(Controller、Service 等)中实现分页逻辑,根据分页参数计算出应该查询的数据范围,并执行相应的操作。
// 示例:在Java中处理分页逻辑
public List<Order> getOrders(int page, int pageSize) {
int offset = (page - 1) * pageSize;
int limit = pageSize;
// 执行数据库查询
return orderRepository.getOrders(offset, limit);
}4) 支持排序
允许客户端指定排序方式,以确保在不同页之间的数据顺序是一致的。
// 示例:接口请求中包含排序参数
{
"page": 1,
"pageSize": 10,
"sort": "order_date",
"direction": "asc"
}5) 数据缓存和预加载
针对热门数据,可以考虑使用缓存机制,或者在系统启动时预加载一部分数据到内存中,以提高访问速度。
6) 异步处理
对于批量处理任务,可以考虑使用异步处理来提高系统的并发性能。例如,将大量数据的处理任务放入消息队列中异步执行。
7) 监控和优化
在实施分页批量处理后,监控系统的性能和资源使用情况,通过性能测试和负载测试找到系统的瓶颈,进一步优化系统。
8) 合理设置分页大小
根据实际情况和系统负载合理设置每页的数据量。太小的分页可能会增加数据库查询的开销,太大的分页可能导致内存占用过高。
分页批量处理是一种平衡内存和性能的策略,通过合理的分页设计,可以使系统更具弹性,更好地适应不同规模的数据量。
2.7 批量提交事务
如果接口涉及到事务,尽量将多个操作放在同一个事务中,以减少事务提交的开销。特别是在需要处理大量数据或执行多个操作的情况下。批量提交事务可以减少事务的开销,提高系统性能。
以下是一些方法和建议,说明如何批量提交事务:
1) 分批次处理并提交事务
将大量数据分成小批次处理,并在每个批次处理完成后提交事务。这有助于控制事务的大小,避免一次性处理大量数据导致事务过长的问题。
// Java示例:分批次处理并提交事务
Connection connection = // 获取数据库连接
Statement statement = connection.createStatement();
for (int i = 0; i < data.size(); i++) {
statement.addBatch("INSERT INTO table_name (column1, column2) VALUES ('value1', 'value2')");
// 每1000条数据提交一次事务
if (i % 1000 == 0) {
statement.executeBatch();
connection.commit();
}
}
// 提交剩余的数据
statement.executeBatch();
connection.commit();2) 使用事务回滚点
在处理大事务时,可以使用事务回滚点(Savepoint)来划分事务中的子事务,实现分批提交。在需要回滚时,可以回到指定的事务回滚点。
// Java示例:使用事务回滚点分批提交事务
Connection connection = // 获取数据库连接
Savepoint savepoint = connection.setSavepoint();
try {
// 执行一批数据操作
// 提交一批数据
connection.commit();
} catch (SQLException e) {
// 发生异常,回滚到事务回滚点
connection.rollback(savepoint);
}3) 使用批处理框架
对于大规模的数据处理,可以考虑使用专业的批处理框架,如 Spring Batch 等。这些框架提供了丰富的功能和配置选项,可以更好地管理和优化批量处理任务。
在实施批量提交事务时,需根据具体场景和需求选择适当的方式。确保在设计和实现过程中考虑事务管理、异常处理和性能监控,以保证批处理的正确性和高效性。
2.8 并行批量处理
在适当的场景下,可以考虑使用并行处理多个批量任务,以提高整体的处理速度。 并行批量处理是接口调优中一种常见的策略,可以提高系统性能,特别是在需要处理大量数据或执行耗时操作的情况下。
以下是一些方法和建议,说明如何实现并行批量处理:
1) 多线程处理
利用多线程来并行处理批量任务。将大量数据分成多个小任务,每个任务在独立的线程中执行,以充分利用多核处理器的性能。
// Java示例:使用多线程并行处理批量任务
List<BatchTask> tasks = // 分割的批量任务列表
// 创建线程池
ExecutorService executorService = Executors.newFixedThreadPool(5);
// 提交任务并行执行
List<Future<Result>> futures = new ArrayList<>();
for (BatchTask task : tasks) {
Future<Result> future = executorService.submit(() -> {
// 执行批量任务的逻辑
return performBatchTask(task);
});
futures.add(future);
}
// 等待所有任务完成
for (Future<Result> future : futures) {
Result result = future.get(); // 阻塞等待任务完成
// 处理任务结果
}
// 关闭线程池
executorService.shutdown();**2) 使用并行流(Parallel Streams)
**
如果使用 Java 8 及以上版本,可以使用并行流来简化并行处理。通过调用 parallel() 方法,可以将集合的操作转换为并行操作。
// Java 8示例:使用并行流并行处理批量任务
List<BatchTask> tasks = // 批量任务列表
tasks.parallelStream()
.map(task -> performBatchTask(task))
.forEach(result -> {
// 处理任务结果
});3) 使用分布式计算框架
对于更大规模的数据处理,可以考虑使用分布式计算框架,如 Apache Spark、Hadoop 等。这些框架可以将任务分布到多个节点上并行执行,实现横向扩展。
4) 批量任务拆分
将大批量任务拆分成多个小任务,每个小任务独立执行。这有助于并行化处理,并能够更好地利用系统资源。
5) 异步任务处理
将批量任务设计成异步执行的形式,可以通过消息队列或事件驱动的方式实现。每个异步任务在独立的线程或进程中执行,提高并行度。
6) 数据分片并行处理
将数据分片后并行处理,每个分片独立处理。这适用于大量数据需要进行相似操作的场景。
7) 使用并行算法
针对特定的批量任务,可以考虑使用并行算法来提高处理效率。例如,并行排序算法、并行搜索算法等。
8) 适当的并发控制
在进行并行处理时,需要适当控制并发度,避免过多的并发导致系统资源不足。可以通过调整并发度来优化性能。
在实现并行批量处理时,需谨慎考虑并发安全性、资源管理和系统负载等因素。通过合理设计任务拆分和并行执行的逻辑,可以更好地利用硬件资源,提高系统的整体性能。
2.9 使用缓存
对于一些不经常变化的数据,可以考虑在缓存中进行批量查询,减少数据库的访问。 缓存可以减少对底层数据存储的访问,提高数据读取速度,降低系统负载。
以下是一些关于如何在批量处理中使用缓存的方法和建议:
1) 缓存热点数据
针对常被访问的数据,使用缓存将其存储在内存中,避免重复从数据库或其他数据源中读取。这样可以显著提高数据的读取速度。
2) 使用分布式缓存
对于分布式系统,考虑使用分布式缓存系统,如 Redis、Memcached 等。这样可以实现在多个节点之间共享缓存数据,提高整体性能。
3) 缓存查询结果
如果某个查询的结果是稳定的且不经常变化,可以将查询结果缓存起来,下次相同的查询直接从缓存中获取,避免重复查询。
4) 缓存结果集
在批量处理中,如果有一些中间结果集是可以复用的,可以将这些结果集缓存起来,以减少计算或查询的开销。
5) 使用本地缓存
对于单机应用,可以使用本地内存缓存,如 Guava Cache。这种缓存适用于存储相对较小、生命周期较短的数据。
// Java示例:使用Guava Cache
Cache<String, Result> cache = CacheBuilder.newBuilder()
.maximumSize(1000)
.expireAfterWrite(10, TimeUnit.MINUTES)
.build();
// 从缓存中获取数据
Result result = cache.get("key", () -> expensiveOperation("key"));6) 考虑缓存失效策略
对于缓存中的数据,需要考虑合适的失效策略,以确保缓存中的数据是最新的。可以根据数据的更新频率设置缓存的过期时间。
7) 缓存预加载
在系统启动时,可以预先加载一部分数据到缓存中,以提高系统初始性能。这对于那些被频繁访问的数据特别有效。
8) 使用缓存注解
对于基于 Java 的应用,可以使用缓存注解,如 Spring 的 @Cacheable,简化缓存的使用和管理。
// Java示例:使用Spring的@Cacheable注解
@Cacheable(value = "myCache", key = "#key")
public Result getData(String key) {
// 查询数据的逻辑
}9) 缓存清理策略
定期清理缓存中的过期数据,以释放内存并保持缓存的健康状态。这可以通过定时任务或缓存系统本身的清理机制来实现。
10) 分布式锁和缓存一致性
当使用分布式缓存时,需要考虑分布式锁和缓存一致性的问题,以避免并发访问导致的数据不一致。
在使用缓存时,需要根据实际业务场景和性能需求,选择合适的缓存方案和配置参数。同时,要注意缓存的内存占用、缓存击穿、缓存雪崩等缓存相关的常见问题。
2.10 监控和调优
部署监控系统以监控批处理任务的执行情况是非常重要的,它能够及时发现性能瓶颈、异常情况和资源利用情况,从而进行有效的调优。
以下是一些建议,说明如何部署监控系统并监控批处理任务:
1) 选择监控工具和系统
选择适合我们应用和环境的监控工具。一些常用的监控工具包括 Prometheus、Grafana、ELK Stack(Elasticsearch、Logstash、Kibana)、Datadog 等。确保所选工具支持批处理任务的监控。将监控工具集成到我们的应用中。通过使用监控代理或监控库,可以方便地将监控数据发送到监控系统。
2) 监控批处理任务
确定批处理任务中的关键性能指标,例如任务执行时间、吞吐量、成功率、错误率等。在批处理任务的关键代码路径中添加监控点。这可以通过在代码中插入性能日志、指标记录或使用监控工具提供的API来实现。配置日志监控,确保批处理任务的日志包含足够的信息。使用监控系统来分析日志,检测异常情况并及时报警。
// Java示例:使用Prometheus的Java客户端
import io.prometheus.client.Counter;
public class BatchProcessor {
private static final Counter batchExecutionCounter = Counter.build()
.name("batch_execution_count")
.help("Number of batch executions")
.register();
public void processBatch() {
// 执行批处理任务
// 在关键位置增加监控点
batchExecutionCounter.inc();
}
}3) 设定警报规则
基于关键性能指标,设定适当的警报规则。例如,当批处理任务执行时间超过阈值或错误率升高时,触发警报。将监控系统与通知系统(如 Slack、Email、短信等)整合,以便在触发警报时及时通知相关人员。
4) 可视化监控仪表板
利用监控工具提供的仪表板功能,创建针对批处理任务的可视化仪表板。仪表板应包含关键性能指标和警报信息。 配置实时监控,确保能够实时查看批处理任务的执行情况。这有助于迅速发现性能问题。
5) 周期性分析和优化
定期进行性能分析,通过监控系统的历史数据和趋势分析,找出性能瓶颈和潜在问题。根据性能分析结果,进行相应的优化和调整。可能需要优化代码、调整数据库索引、增加硬件资源等。
6) 分布式追踪
使用分布式追踪工具来跟踪批处理任务在分布式系统中的调用链。这有助于定位性能问题和优化点。 将分布式追踪信息整合到监控系统中,以便在仪表板上查看批处理任务的完整调用链。
7) 定期性能测试
在不同负载下进行定期性能测试,以验证系统在不同情况下的性能表现,及时发现潜在的性能问题。确保性能测试环境与生产环境尽可能相似,以保证性能测试的准确性。
8) 安全和权限
确保监控系统的安全性,采取合适的措施保护监控数据,避免敏感信息泄露。控制访问监控系统的权限,确保只有授权人员能够查看和修改监控配置。
通过以上步骤,可以建立一个全面的监控体系,确保对批处理任务的执行情况进行实时监控、及时发现潜在问题、并进行相应的调优。
2.11 分布式批处理
如果系统规模较大,可以考虑使用分布式批处理框架,将任务分发到多个节点进行处理,以提高整体的处理能力。
以下是进行分布式批处理时的一些建议和方法:
数据分片 将大数据集分割成小的数据片段,每个片段称为一个数据分片。数据分片的划分可以基于某种规则,例如按照数据范围、按照数据的散列值等。对数据分片进行元数据管理,记录每个数据分片的信息,包括所在节点、状态、处理进度等。元数据管理有助于跟踪和监控分布式批处理的执行情况。
任务调度与协调 使用任务调度系统来协调和调度分布式批处理任务。常见的任务调度框架包括 Apache Hadoop YARN、Apache Mesos、Kubernetes 等。对于批处理作业的协调,可以使用分布式作业调度系统,例如 Apache Airflow、Apache Oozie 等。
并行处理 在每个节点上并行执行数据分片的处理任务。确保任务之间相互独立,可以同时运行,从而提高整体处理速度。需要在节点之间进行适当的数据通信,确保节点之间的数据同步。但在设计时要避免过度的数据传输,以减少通信开销。
容错和恢复 在分布式环境中,任务可能因为节点故障或其他原因而失败。需要实施适当的容错机制,例如重新执行失败的任务、检查点机制等。对于需要原子性处理的任务,确保实施事务性处理机制,以避免部分成功和部分失败的情况。
资源管理 确保每个节点都有足够的资源(CPU、内存、磁盘等)来执行任务,防止因为资源不足而导致性能下降。考虑使用动态伸缩机制,根据负载自动调整节点的数量,以适应不同处理阶段的资源需求。
数据一致性 对于需要保证数据一致性的任务,可以考虑使用分布式事务机制,确保在整个分布式系统中的数据操作具有原子性。在设计任务时考虑幂等性,使得任务在失败并需要重试时不会引入额外的影响。
部署模式 考虑在云服务中部署分布式批处理任务,利用云服务提供的资源管理和弹性伸缩功能。使用容器技术(如 Docker、Kubernetes)将分布式批处理任务容器化,简化部署和管理。
系统安全 在数据传输和存储中使用加密机制,确保数据的安全性。对分布式环境中的节点进行身份认证与授权,以确保系统的安全性。
通过以上方法,可以有效地设计和实现分布式批处理系统,提高数据处理效率,保证任务的正确性和可靠性。在实际应用中,根据具体场景和需求选择适当的技术栈和工具。
2.12 合理设置批处理大小
针对具体的业务场景,合理设置批处理的大小,以达到平衡系统资源和性能的目的。 下面是一些关于如何合理设置批处理大小的建议:
1) 考虑系统资源
批处理大小应该合理考虑系统的内存资源。如果批处理任务占用大量内存,可以适当减小批处理大小,防止系统因内存不足而产生性能问题。批处理任务的计算密集型部分可能会占用大量 CPU 资源。在设置批处理大小时,需要考虑系统的 CPU 利用率,避免过度消耗 CPU 资源导致其他任务性能下降。
2) 数据库性能
对于涉及数据库操作的批处理任务,数据库连接数是一个重要的考虑因素。合理设置批处理大小可以控制数据库连接数,防止连接数过多导致数据库性能下降。批处理任务中使用的事务大小对数据库性能也有影响。过大的事务可能导致数据库锁定,过小的事务可能增加事务处理的开销。需要根据实际情况进行调优。
3) 网络通信
批处理任务可能涉及到网络通信,特别是在分布式系统中。考虑网络带宽限制,避免设置过大的批处理大小导致网络拥塞。如果批处理任务需要与其他服务进行通信,需要考虑服务的响应时间。设置合理的批处理大小可以控制请求的并发度,避免因等待响应而产生延迟。
4) 任务并发度
批处理任务的并发度直接影响到系统资源的使用情况。合理设置批处理大小可以控制任务的并发度,防止过度占用系统资源。在分布式环境中,任务调度系统可以用来控制任务的并发度。根据任务调度系统的能力和配置,适当设置批处理大小。
5) 批处理性能
进行性能评估测试,通过尝试不同的批处理大小,观察系统的性能变化。根据实际测试结果进行调整。使用监控系统监控关键性能指标,如响应时间、吞吐量、资源利用率等,以便实时了解系统的运行情况。
6) 数据处理逻辑
批处理任务的数据处理逻辑可能有复杂的计算或操作。合理设置批处理大小可以平衡计算开销和系统资源利用效率。如果批处理任务涉及到事务,需要考虑事务的大小。设置适当的批处理大小以保证事务的有效性和性能。
7) 系统稳定性
避免设置过大的批处理大小,防止长时间运行的批处理任务占用系统资源,导致其他任务受到影响。考虑在系统运行中动态调整批处理大小,根据系统负载和性能表现进行实时调整。
设置合理的批处理大小需要综合考虑系统资源、数据库性能、网络通信等多个因素。通过测试和监控,及时调整批处理大小,以达到系统性能最优化。
在实施批量处理时,需要根据具体的业务场景和需求,灵活选择合适的批量处理策略。批量处理通常可以显著提高系统的性能和效率,降低系统的负担。
欢迎加入我的知识星球,全面提升技术能力。
👉 加入方式,“长按”或“扫描”下方二维码噢:

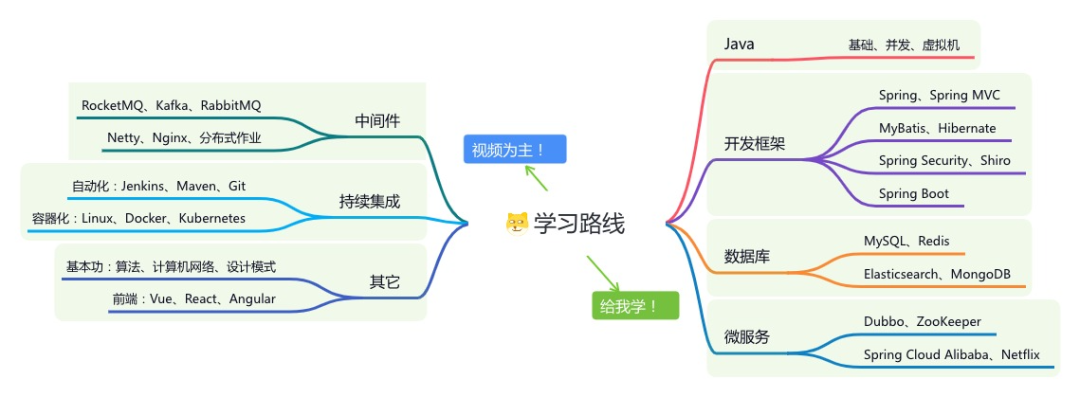
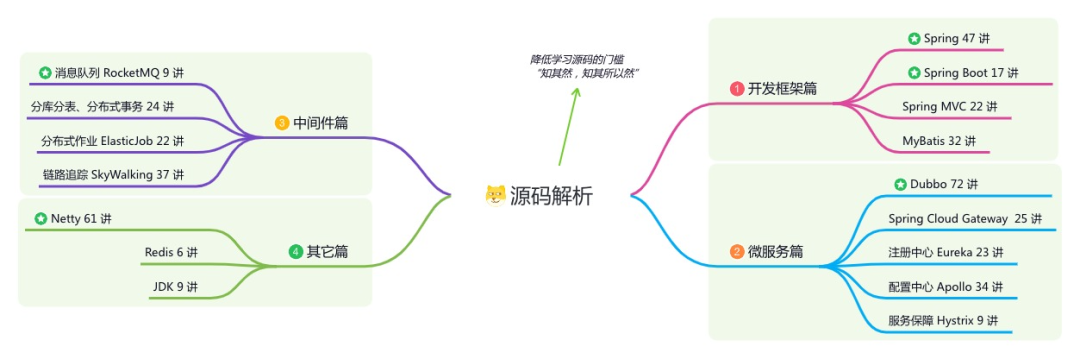
星球的内容包括:项目实战、面试招聘、源码解析、学习路线。
文章有帮助的话,在看,转发吧。
谢谢支持哟 (*^__^*)














 392
392











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









