









目录
1.聚合函数
2.分组查询
3.分页查询
4.内连接
5.外连接(左,右连接)
文章目录
- 聚合函数
- 分组查询
- 分页查询
- 内连接
- 外连接
前言
基础的sql查询语言我上篇已经记录过了,这次记录一下比较进阶点的查询语句,当然我记录的可能有不足,若有错误,感谢斧正。
一、聚合函数
将一列数据作为一个整体,进行纵向计算。
例如:有以下表,需要求表中所有数据的account总和,就是对account字段纵向求和
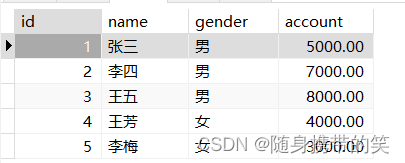
聚合函数分类
|
函数名
|
功能
|
|
count(
列名)
|
统计数量(值为null的列不统计计算
)
|
|
max(
列名
)
|
求当列最大值
|
|
min(
列名
)
|
求当列最小值
|
|
sum(
列名
)
|
求当列总和
|
|
avg(
列名
)
|
求当列平均值
|
聚合函数语法
SELECT 聚合函数名(列名) FROM 表;
所以上表的account求和为: select sum(account)from bank;
二、分组查询
语法
SELECT
字段列表
FROM
表名
[
WHERE
分组前条件限定
]
GROUP BY
分组字段名
[
HAVING
分组后条件过滤
]
;
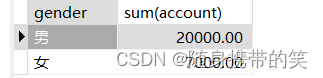
例如: 我们继续对这个表操作,分别求出男士的总account和女士的总account
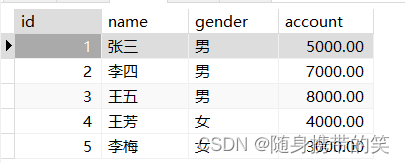
select gender
,
sum
(
account
)
from bank
group by gender
;
查询结果为:
where
和
having
区别:
执行时机不一样:
where
是分组之前进行限定,不满足
where
条件,则不参与分组,而
having
是分组之后对结果进行过
滤。
可判断的条件不一样:
where
不能对聚合函数进行判断,
having
可以
三.分页查询
很多网站都见过类似的效果,如京东、百度、淘宝等,将数据一页一页展示给用户,既能缓解内存压力,还可以方便用户查阅。
语法: SELECT 字段列表 FROM 表名 LIMIT 起始索引 , 查询条目数;
例如: 每页显示5条数据,查询第1页数据
select
*
from
stu
limit
0
,
5
;
推导出起始索引计算公式:
起始索引 = (当前页码 - 1) * 每页显示的条数
四.内连接
内连接查询 分为显示内连接和隐式内连接
语法:
--
隐式内连接
SELECT
字段列表
FROM
表
1,
表
2…
WHERE
条件
;
内连接相当于查询
A B
交集数据
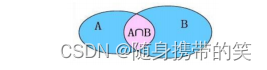
隐式内连接
select *from emp dept where emp.dept_id=dept.did;
上面emp为员工表,dept为部门表,dept_id是emp表的外键,did是dept表的主键
插询结果为两表相连
--
显示内连接
SELECT
字段列表
FROM
表
1
[
INNER
]
JOIN
表
2
ON
条件
;
显示内连接 例
select * from emp inner join dept on emp.dep_id = dept.did;
五.外连接
--
左外连接
SELECT
字段列表
FROM
表
1
LEFT
[
OUTER
]
JOIN
表
2
ON
条件
;
--
右外连接
SELECT
字段列表
FROM
表
1
RIGHT
[
OUTER
]
JOIN
表
2
ON
条件
;
左外连接:相当于查询
A
表所有数据和交集部分数据
右外连接:相当于查询
B
表所有数据和交集部分数据
查询
emp
表所有数据和对应的部门信息(左外连接)
select
*
from
emp
left join
dept
on
emp
.dep_id
=
dept
.did
;
查询
dept
表所有数据和对应的员工信息(右外连接)
select
*
from
emp
right join
dept
on
emp
.dep_id
=
dept
.did
;
















 297
297

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











