






现在预训练方法存在的问题:
- 在现有方法中,普遍使用了人造符号“[MASK]”。而在真实数据中是不存在这样的人造符号的,这导致了预训练和微调存在差异。
- 对跨语言的对齐信息(如果存在的话)利用不是很充分。
CSP方法的简要说明:不再使用[MASK]去随机替代源语言中的词,而是使用原词在目标语言中的对应词去进行替换,仍旧让模型去预测原词是什么。
第一步:创建共享词表
因为要做目标语言替换,所以必须共享词表(即编码器和解码器共用词表,但不是源语言和目标语言词表的简单拼加,而是做空间映射得到的新词表)。否则任何替换的词都会被视作[UNK]也就失去了code-switch的意义了。
第二步:抽取翻译概率词典
此处的词典定义为,由源语言到目标语言的“一对多”关系,替换时根据该词表进行替换。词典的获取方式,将源语言和目标语言的词向量映射到共享空间里去,然后计算共享空间中的余弦相似度,选择相似度最高的K个目标端词组成对应关系。
- 在获取词典的过程中,需要两种语言的语料,但是并不需要这两种语料对齐。
第三步:替换
根据词典,在K个目标语言词中进行随机抽样替换。
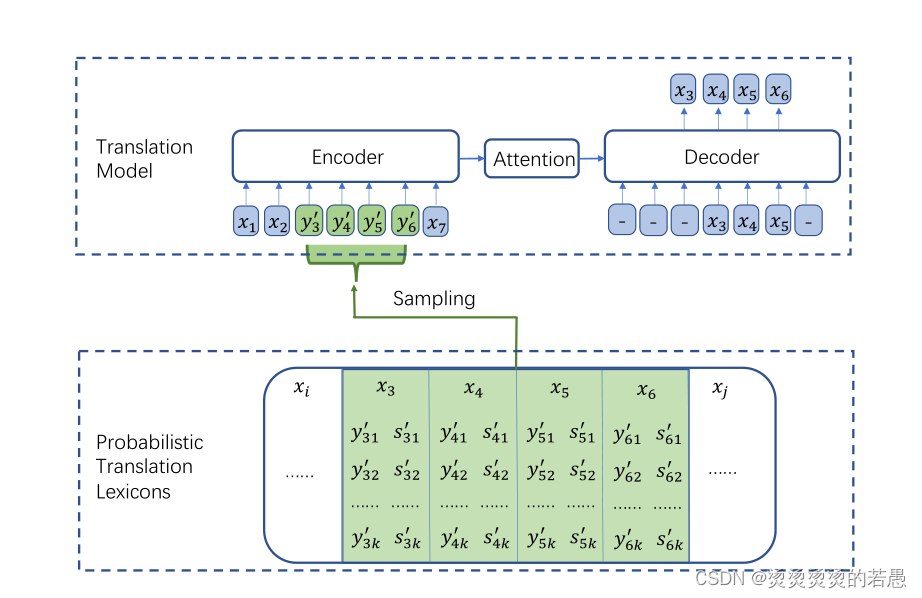
第四步:预测



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









