






原文地址: https://blog.csdn.net/github_38647413/article/details/124365490
文章目录
- 一、初识 Redis
- 二、API 的理解和使用
- 三、小功能大用处
- 四、客户端
- 五、持久化
- 六、复制
- 七、Redis 的噩梦:阻塞
- 八、理解内存
- 九、哨兵
- 1、Redis Sentinel 相关名词解释
- 2、主从复制的问题
- 3、Redis Sentinel 的高可用性
- 4、部署 Redis 数据节点
- 5、部署 Sentinel 节点
- 6、配置优化
- 7、部署技巧
- 8、API
- 9、Redis Sentinel 的客户端
- 10、Redis Sentinel 客户端基本实现原理
- 12、Redis Sentinel 的基本实现原理之一——Redis Sentinel 的三个定时任务
- 13、Redis Sentinel 的基本实现原理之二——主观下线和客观下线
- 14、Redis Sentinel 的基本实现原理之三——领导者 Sentinel 节点选举
- 15、故障转移
- 16、故障转移日志分析
- 17、节点运维
- 18、Redis Sentinel 读写分离设计思路
- 19、汇总
- 十、集群
- 1、概述
- 2、数据分布理论
- 3、Redis 数据分区
- 4、集群功能限制
- 5、搭建集群
- 6、搭建集群步骤一:准备节点
- 7、搭建集群步骤二:节点握手
- 8、搭建集群步骤三:分配槽
- 9、用 redis-trib.rb 搭建集群
- 10、节点通信流程
- 11、Gossip 消息
- 12、节点选择
- 13、集群伸缩原理
- 14、扩容集群
- 15、收缩集群
- 17、请求路由——Smart 客户端
- 18、请求路由——ASK 重定向
- 19、故障转移之故障发现
- 20、故障转移之故障恢复
- 21、故障转移之故障转移时间
- 22、集群运维——集群完整性
- 23、集群运维——带宽消耗
- 24、集群运维——Pub/Sub 广播问题
- 25、集群运维——集群倾斜
- 26、集群运维——集群读写分离
- 27、集群运维——手动故障转移
- 28、集群运维——数据迁移
- 十一、缓存设计
- 十二、开发运维的 “陷阱”
- 1、Linux 配置优化之内存分配控制
- 2、Linux 配置优化之 swappiness
- 3、Linux 配置优化之 THP
- 4、Linux 配置优化之 OOM killer
- 5、Linux 配置优化之使用 NTP
- 6、Linux 配置优化之 ulimit
- 7、Linux 配置优化之 TCP backlog
- 8、flushall/flushdb 误操作之缓存与存储
- 9、flushall/flushdb 误操作之借助 AOF 机制恢复
- 10、flushall/flushdb 误操作之 RDB 变化
- 11、flushall/flushdb 误操作之从节点变化
- 12、flushall/flushdb 误操作之快速恢复数据
- 13、安全的 Redis 概述
- 14、安全的 Redis 之 Redis 密码机制
- 15、安全的 Redis 之伪装危险命令
- 16、安全的 Redis 之防火墙
- 17、安全的 Redis 之 bind
- 18、安全的 Redis 之定期备份数据
- 19、安全的 Redis 之不使用默认端口
- 20、安全的 Redis 之使用非 root 用户启动
- 21、处理 bigkey
- 22、bigkey 的危害
- 23、如何发现 bigkey
- 24、如何删除 bigkey
- 25、bigkey 最佳实践思路
- 26、寻找热点 key
- 27、汇总
- 十三、Redis 配置统计字典
一、初识 Redis
1、在 Centos7 下安装 Redis
1)安装
一般推荐使用的安装方式:源码的方式进行安装。下面以 3.0.7 版本为例 (只需 6 步):
# 如果没有安装则通过以下命令安装:
$ yum install -y gcc
$ wget http://download.redis.io/releases/redis-3.0.7.tar.gz
$ tar xzf redis-3.0.7.tar.gz
$ ln -s redis-3.0.7 redis # 建立一个redis目录的软连接,指向redis-3.0.7。
$ cd redis
$ make # 编译(编译前确保操作系统已经安装gcc)
$ make install # 指定安装目录并进行安装: make install PREFIX=/usr/local/redis
$ redis-cli -v # 查看Redis的版本
2)通过守护进程方式启动
# 第一步:从 redis 的源码目录中复制 redis.conf 到 redis 的安装目录
cp /root/redis-6.2.6/redis.conf /usr/local/redis/bin/
# 第二步:修改redis.conf配置文件
cd /usr/local/redis/bin/
vi redis.conf
# 修改内容如下:
#daemonize 的值从 no 修改成 yes
# 第三步:启动服务
./redis-server redis.conf
# 第四步:查看进程来确定redis是否启动成功,非必须
ps -ef |grep redis
3)设置开机自动启动
切换到 / lib/systemd/system / 目录,创建 redis.service 文件。命令如下:
cd /lib/systemd/system/
vim redis.service
文件内容如下:
[Unit]
Description=redis-server
After=network.target
[Service]
Type=forking
# ExecStart需要按照实际情况修改成自己的地址
ExecStart=/usr/local/redis/bin/redis-server /usr/local/redis/bin/redis.conf
ExecReload=/bin/kill -s HUP $MAINPID
ExecStop=/usr/local/redis/bin/redis-cli -p 6379 shutdown
PrivateTmp=true
[Install]
WantedBy=multi-user.target
设置开启自动启动
# 开机自动启动
systemctl enable redis.service
# 启动redis服务
systemctl start redis.service
# 查看服务状态
systemctl status redis.service
# 停止服务
systemctl stop redis.service
# 取消开机自动启动(卸载服务)
systemctl disabled redis.service
4)客户端连接
# 本地连接:进入bin目录执行客户端连接操作
./redis-cli -h localhost –p 6379
127.0.0.1:6379> set hello world
OK
127.0.0.1:6379> get hello
"world"
# 通过 redis-cli -h {host} -p {port} {command} 就可以直接得到命令的返回结果。
redis-cli -h 127.0.0.1 -p 6379 get hello
"world"
# redis客户端显示中文
redis-cli -p 7000 --raw
# 远程连接
# 注意:默认redis服务器是没有开启远程连接
# 1、修改配置开启远程连接
vim redis.conf 修改如下配置
bind 0.0.0.0 # 允许一切客户端连接
# 2、重启服务
2、Redis 可执行文件说明
| 可执行文件 | 作用 |
|---|---|
| redis-server | 启动 Redis |
| redis-cli | Redis 命令行客户端 |
| redis-benchmark | Redis 基准测试工具 |
| redis-check-aof | Redis AOF 持久化文件检测和修复工具 |
| redis-check-dump | Redis RDB 持久化文件检测和修复工具 |
| redis-sentinel | 启动 Redis Sentinel |
redis-cli 详解
要了解 redis-cli 的全部参数,可以执行 redis-cli --help 命令来进行查看。
1)-r (repeat) 选项代表将命令执行多次
$ redis-cli -r 3 ping # 执行三次ping命令
pong
pong
pong
2)-i (interval) 选项代表每隔几秒执行一次命令,但是 - i 选项必须和 - r 选项一起使用。
# 注意 - i 的单位是秒,不支持毫秒为单位,但是如果想以每隔 10 毫秒执行一次,可以用 - i0.0。
$ redis-cli -r 5 -i 1 ping # 每隔1秒执行一次ping命令,一共执行5次
PONG
PONG
PONG
PONG
PONG
$ redis-cli -r 100 -i 1 info | grep used_memory_human # 每隔1秒输出内存的使用量,一共输出 100次
used_memory_human:2.95G
used_memory_human:2.95G
. . . . . . . . . . . . . . . . . . . . . .
used_memory_human:2.94G
3)-x 选项代表从标准输入 (stdin) 读取数据作为 redis-cli 的最后一个参数。
$ echo "world" | redis-cli -x set hello
OK
4)-c (cluster) 选项是连接 Redis Cluster 节点时需要使用的,-c 选项可以防止 moved 和 ask 异常。
5)-a 如果 Redis 配置了密码,可以用 - a(auth) 选项,有了这个选项就不需要手动输入 auth 命令。
6)–scan 和–pattern 用于扫描指定模式的键,相当于使用 scan 命令。
7)–slave 选项是把当前客户端模拟成当前 Redis 节点的从节点,可以用来获取当前 Redis 节点的更新操作。合理的利用这个选项可以记录当前连接 Redis 节点的一些更新操作,这些更新操作很可能是实际开发业务时需要的数据。
# ①下面开启第一个客户端,使用--slave选项,看到同步已完成:
$ redis-cli --slave
SYNC with master, discarding 72 bytes of bulk transfer . . .
SYNC done . Logging commands from master .
# ②再开启另一个客户端做一些更新操作:
redis-cli
127.0.0.1:6379> set hello world
OK
127.0.0.1:6379> set a b
OK
127.0.0.1:6379> incr count
1
127.0.0.1:6379> get hello
"world"
# ③第一个客户端会收到Redis节点的更新操作:(PING命令是由于主从复制产生的)
redis-cli --slave
SYNC with master, discarding 72 bytes of bulk transfer . . .
SYNC done . Logging commands from master .
"PING"
"PING"
"PING"
"PING"
"PING"
"SELECT","0"
"set","hello","world"
"set","a","b"
"PING"
"incr","count"
8)–rdb 选项会请求 Redis 实例生成并发送 RDB 持久化文件,保存在本地。可使用它做持久化文件的定期备份。
9)–pipe 选项用于将命令封装成 Redis 通信协议定义的数据格式,批量发送给 Redis 执行。
# 下面操作同时执行了set hello world和incr counter两条命令:
echo -en '*3\r\n$3\r\nSET\r\n$5\r\nhello\r\n$5\r\nworld\r\n*2\r\n$4\r\nincr\r\ n$7\r\ncounter\r\n ' | redis-cli --pipe
10)–bigkeys 选项使用 scan 命令对 Redis 的键进行采样,从中找到内存占用比较大的键值,这些键可能是系统的瓶颈。
11)–eval 选项用于执行指定 Lua 脚本。
12)–latency 有三个选项,分别是–latency、–latency-history、–latency-dist。它们都可以检测网络延迟。 1. –latency:该选项可以测试客户端到目标 Redis 的网络延迟。 2. –latency-history:–latency 的执行结果只有一条,而–latency-history 可以以分时段的形式了解延迟信息。 3. –latency-dist:该选项会使用统计图表的形式从控制台输出延迟统计信息。
redis-cli -h {machineB} --latency
min: 0, max: 1, avg: 0.07 (4211 samples)
# 延时信息每15秒输出一次,可以通过-i参数控制间隔时间
redis-cli -h 10.10.xx.xx --latency-history
min: 0, max: 1, avg: 0.28 (1330 samples) -- 15.01 seconds range…
min: 0, max: 1, avg: 0.05 (1364 samples) 15.01 seconds range
13)–stat 选项可以实时获取 Redis 的重要统计信息,虽然 info 命令中的统计信息更全,但是能实时看到一些增量的数据 (例如 requests) 对于 Redis 的运维还是有一定帮助的。
14)–raw 和–no-raw :no-raw 选项是要求命令的返回结果必须是原始的格式,raw 恰恰相反,返回格式化后的结果。
# ①在Redis中设置一个中文的value:
$redis-cli set hello "你好"
OK
# ②如果正常执行get或者使用--no-raw选项,那么返回的结果是二进制格式;如果使用了--raw选项,将会返回中文。
$redis-cli get hello
"\xe4\xbd\xa0\xe5\xa5\xbd"
$redis-cli --no-raw get hello
"\xe4\xbd\xa0\xe5\xa5\xbd"
$redis-cli --raw get hello
你好
redis-server 详解
redis-server 除了启动 Redis 外,还有一个 -–test-memory 选项。redis-server -–test-memory 可以用来检测当前操作系统能否稳定地分配指定容量的内存给 Redis,通过这种检测可以有效避免因为内存问题造成 Redis 崩溃。
下面操作检测当前操作系统能否提供1G的内存给Redis:
redis-server --test-memory 1024
- 整个内存检测的时间比较长。当输出 passed this test 时说明内存检测完毕,最后会提示–test-memory 只是简单检测,如果有质疑可以使用更加专业的内存检测工具。
- 通常无需每次开启 Redis 实例时都执行–test-memory 选项,该功能更偏向于调试和测试。
redis-benchmark 详解
redis-benchmark 可以为 Redis 做基准性能测试。
1)-c(clients) 选项代表客户端的并发数量 (默认是 50)。
2)-n<requests> (num) 选项代表客户端请求总量 (默认是 100000)。
# redis-benchmark -c 100 -n 20000代表100个客户端同时请求Redis,一共执行20000次。
# redis-benchmark会对各类数据结构的命令进行测试,并给出性能指标.
====== GET ======
20000 requests completed in 0.27 seconds
100 parallel clients
3 bytes payload keep alive: 1
99.11% <= 1 milliseconds
100.00% <= 1 milliseconds
73529.41 requests per second
3)-q 选项仅仅显示 redis-benchmark 的 requests per second 信息
$redis-benchmark -c 100 -n 20000 -q
PING_INLINE: 74349.45 requests per second
PING_BULK: 68728.52 requests per second
SET : 71174.38 requests per second…
LRANGE_500 (first 450 elements) : 11299.44 requests per second
LRANGE_600 (first 600 elements) : 9319.67 requests per second
MSET (10 keys) : 70671.38 requests per second
4)-r 选项会在 key、counter 键上加一个 12 位的后缀,-r 10000 代表只对后四位做随机处理 (-r 不是随机数的个数)。
# 如果想向 Redis 插入更多的键,可以执行使用 - r(random) 选项,可以向 Redis 插入更多随机的键。
# 在一个空的Redis上执行了redis-benchmark会发现只有3个键:
127.0.0.1:6379> dbsize
(integer) 3
127.0.0.1:6379> keys *
1) "counter:__rand_int__"
2) "mylist"
3) "key:__rand_int__"
$redis-benchmark -c 100 -n 20000 -r 10000
5)-P 选项代表每个请求 pipeline 的数据量 (默认为 1)。
6)-k<boolean> 选项代表客户端是否使用 keepalive,1 为使用,0 为不使用,默认值为 1。
7)-t 选项可以对指定命令进行基准测试。
redis-benchmark -t get,set -q
SET: 98619.32 requests per
GET: 97560.98 requests per
8)–csv 选项会将结果按照 csv 格式输出,便于后续处理,如导出到 Excel 等。
redis-benchmark -t get,set --csv
"SET","81300.81"
"GET","79051.38"
3、 停止 Redis 服务
Redis 提供了 shutdown 命令来停止 Redis 服务。
$ redis-cli shutdown # 停掉127.0.0.1上6379端口上的Redis服务
-
Redis 关闭的过程:断开与客户端的连接、持久化文件生成,是一种相对优雅的关闭方式。
-
除了可以通过 shutdown 命令关闭 Redis 服务以外,还可以通过 kill 进程号的方式关闭掉 Redis,但是不要粗暴地使用 kill -9 强制杀死 Redis 服务,不但不会做持久化操作,还会造成缓冲区等资源不能被优雅关闭,极端情况会造成 AOF 和复制丢失数据的情况。
-
shutdown 还有一个参数,代表是否在关闭 Redis 前,生成持久化文件。
$ redis-cli shutdown nosave|save
二、API 的理解和使用
1、单线程架构
- Redis 将所有数据放在内存中,内存的响应时长大约为 100ns。
- Redis 使用 epoll 作为 I/O 多路复用技术的实现,再加上 Redis 自身的事件处理模型将 epoll 中的连接、读写、关闭都转换为事件,不在网络 I/O 上浪费过多的时间。
- 单线程避免了线程切换和竞态产生的消耗。
2、数据库管理
1)数库操作指令
Redis 提供了几个面向 Redis 数据库的操作,它们分别是 dbsize、select、flushdb/flushall 命令
# 1、切换数据库
# 使用redis的默认配置器动redis服务后,默认会存在16个库,编号从0-15
# 可以使用select 库的编号 来选择一个redis的库
select dbIndex
127.0.0.1:6379> set hello world # 默认进到0号数据库
OK
127.0.0.1:6379> get hello
"world"
127.0.0.1:6379> select 15 # 切换到15号数据库
OK
127.0.0.1:6379 [15]> get hello # 因为15号数据库和0号数据库是隔离的,所以get hello为空
(nil)
# 2、flushdb/flushall
# 清空当前的库 FLUSHDB
# 清空全部的库 FLUSHALL
127.0.0.1:6379> dbsize
(integer) 4 # 当前0号数据库有四个键值对
127.0.0.1:6379> select 1
OK
127.0.0.1:6379 [1]> dbsize
(integer) 3
127.0.0.1:6379> flushdb
OK
127.0.0.1:6379> dbsize
(integer) 0
127.0.0.1:6379> select 1
OK
127.0.0.1:6379 [1]> dbsize
(integer) 3
127.0.0.1:6379> flushall # 在任意数据库执行flushall会将所有数据库清除.
OK
127.0.0.1:6379> select 1
OK
127.0.0.1:6379 [1]> dbsize
(integer) 0
- Redis Cluster 只允许使用 0 号数据库。
2)全局命令
-
DEL 指令
- 语法 : DEL key [key …]
- 作用 : 删除给定的一个或多个 key 。不存在的 key 会被忽略。
- 返回值: 被删除 key 的数量。
-
EXISTS 指令
- 语法: EXISTS key
- 作用: 检查给定 key 是否存在。
- 返回值: 若 key 存在,返回 1 ,否则返回 0。
-
EXPIRE
- 语法: EXPIRE key seconds
- 作用: 为给定 key 设置生存时间,当 key 过期时(生存时间为 0 ),它会被自动删除。
- 时间复杂度: O(1)
- 返回值:设置成功返回 1 。
-
KEYS
- 作用 : 查找所有符合给定模式 pattern 的 key 。keys 命令会遍历所有键,所以它的时间复杂度是 O(n),当 Redis 保存了大量键时,线上环境禁止使用。
- 语法 : KEYS pattern
KEYS * 查找数据库中所有 key 。
KEYS h?llo 匹配 hello ,hallo 和 hxllo 等。
KEYS h*llo 匹配 hllo 和 heeeeello 等。
KEYS h[ae]llo 匹配 hello 和 hallo ,但不匹配 hillo 。特殊符号用 “” 隔开 - 返回值: 符合给定模式的 key 列表。
-
MOVE
- 语法 : MOVE key db
- 作用 : 将当前数据库的 key 移动到给定的数据库 db 当中。
- 返回值: 移动成功返回 1 ,失败则返回 0 。
-
PEXPIRE
- 语法 : PEXPIRE key milliseconds
- 作用 : 这个命令和 EXPIRE 命令的作用类似,但是它以毫秒为单位设置 key 的生存时间,而不像 EXPIRE 命令那样,以秒为单位。
- 时间复杂度: O(1)
- 返回值:设置成功,返回 1 key 不存在或设置失败,返回 0
-
PEXPIREAT
- 语法 : PEXPIREAT key milliseconds-timestamp
- 作用 : 这个命令和 EXPIREAT 命令类似,但它以毫秒为单位设置 key 的过期 unix 时间戳,而不是像 EXPIREAT 那样,以秒为单位。
- 返回值:如果生存时间设置成功,返回 1 。当 key 不存在或没办法设置生存时间时,返回 0 。(查看 EXPIRE 命令获取更多信息)
-
TTL
- 语法 : TTL key
- 作用 : 以秒为单位,返回给定 key 的剩余生存时间(TTL, time to live)。
- 返回值:
当 key 不存在时,返回-2 。
当 key 存在但没有设置剩余生存时间时,返回-1 。
否则,以秒为单位,返回 key 的剩余生存时间。
-
PTTL
- 语法 : PTTL key
- 作用 : 这个命令类似于 TTL 命令,但它以毫秒为单位返回 key 的剩余生存时间,而不是像 TTL 命令那样,以秒为单位。
- 返回值:
当 key 不存在时,返回-2 。
当 key 存在但没有设置剩余生存时间时,返回-1 。
否则,以毫秒为单位,返回 key 的剩余生存时间。 - 注意 : 在 Redis 2.8 以前,当 key 不存在,或者 key 没有设置剩余生存时间时,命令都返回-1 。
-
RANDOMKEY
- 语法 : RANDOMKEY
- 作用 : 从当前数据库中随机返回(不删除) 一个 key。当数据库为空时,返回 nil 。
-
RENAME
- 语法 : RENAME key newkey
- 作用 : 将 key 改名为 newkey 。当 key 和 newkey 相同,或者 key 不存在时,返回一个错误。当 newkey 已经存在时,RENAME 命令将覆盖旧值。
- 返回值: 改名成功时提示 OK ,失败时候返回一个错误。
# rename key newkey
# 由于重命名键期间会执行 del 命令删除旧的键,如果键对应的值比较大,会存在阻塞 Redis 的可能性。
127.0.0.1:6379> get python
"jedis"
127.0.0.1:6379> set python jedis
OK
127.0.0.1:6379> rename python java # 如果在rename之前,键java 已经存在,那么它的值也将被覆盖
OK
127.0.0.1:6379> get python
(nil)
127.0.0.1:6379> get java
"jedis"
127.0.0.1:6379> set java jedis
OK
127.0.0.1:6379> set python redis-py
OK
# 为了防止被强行 rename,Redis 提供了 renamenx 命令,确保只有 newKey 不存在时候才被覆盖。
127.0.0.1:6379> renamenx java python
(integer) 0 # 返回结果是0代表没有完成重命名
127.0.0.1:6379> get java
"jedis"
127.0.0.1:6379> get python
"redis-py"
-
TYPE
- 语法 : TYPE key
- 作用 : 返回 key 所储存的值的类型。
- 返回值:
none (key 不存在)
string (字符串)
list (列表)
set (集合)
zset (有序集)
hash (哈希表)
3、字符串 String
1)String 操作命令
- 字符串类型的值实际可以是字符串 (简单的字符串、复杂的字符串 (例如 JSON、XML))、数字 (整数、浮点数),甚至是二进制 (图片、音频、视频),但是值最大不能超过 512MB。
| 命令 | 说明 | 实例 |
|---|---|---|
| set | 设置一个 key/value。 set key value [ex seconds][px milliseconds] [nx|xx] - ex seconds:为键设置秒级过期时间 - px milliseconds:为键设置毫秒级过期时间。 - nx:键必须不存在,才可以设置成功,用于添加。 - xx:与 nx 相反,键必须存在,才可以设置成功,用于更新。 | xx]set hello world |
| get | 根据 key 获得对应的 value。键不存在,则返回 nil。 | get hello |
| mset | 一次设置多个 key value | mset a 1 b 2 c 3 d 4 |
| mget | 一次获得多个 key 的 value | mget a b c d |
| getset | 获得原始 key 的值,同时设置新值 | |
| strlen | 获得对应 key 存储 value 的长度 | |
| append | 为对应 key 的 value 追加内容 | |
| getrange | 索引 0 开始 截取 value 的内容 | |
| setex | 设置一个 key 存活的有效期(秒) | |
| psetex | 设置一个 key 存活的有效期(毫秒) | |
| setnx | key 存在时不做任何操作, key 不存在时添加 失败,返回结果为 0。成功,返回结果为 OK。 | setnx hello redis |
| msetnx | 同时设置多个 key,只要有一个存在都不保存(原子操作) | |
| decr | 进行数值类型的 - 1 操作 | |
| decrby | 根据提供的数据进行减法操作 | |
| Incr | 进行数值类型的 + 1 操作 | incr key |
| incrby | 根据提供的数据进行加法操作 | |
| Incrbyfloat | 根据提供的数据加入浮点数 |
2)字符串内部编码
字符串类型的内部编码有 3 种:
- int:8 个字节的长整型。
- embstr:小于等于 39 个字节的字符串。
- raw:大于 39 个字节的字符串。
3)字符串典型使用场景
(1)缓存
(2)计数器
long incrVideoCounter(long id){
key = "video:playCount:" + id;
return redis.incr(key);
}
(3)共享 Session
- 例如,一个分布式 Web 服务使用 Redis 将用户的 Session 进行集中管理。
(4)限速
- 例如,限制用户获取短信验证码频率、限制一个 IP 地址不能在一秒钟之内访问超过 n 次。
phoneNum = "138xxxxxxx";
key = "shortMsg:limit:" + phoneNum;
// SET key value EX 60 NX
isExists = redis.set(key, 1, "EX 60", "NX");
if(isExists != null || redis.incr(key) <= 5)
// 通过
else
// 限速
4、哈希 Hash
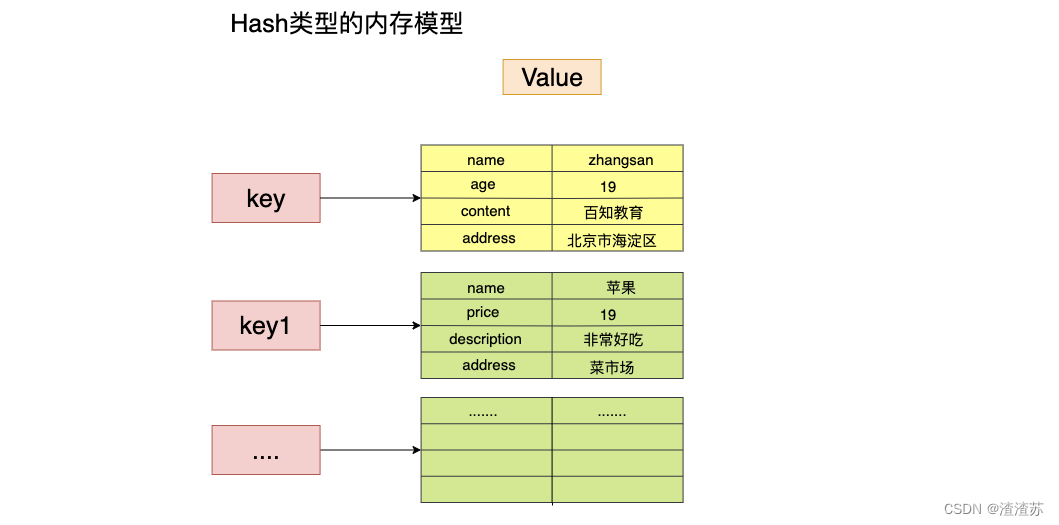
在 Redis 中,哈希类型是指键值本身又是一个键值对结构,形如 value={{field1, value1},…{fieldN, valueN}}。
1)Hash 命令
| 命令 | 说明 | 实例 |
|---|---|---|
| hset | 设置一个 key/value 对 | hset user:1 name tom |
| hget | 获得一个 key 对应的 value | hget user:1 name |
| hgetall | 获得所有的 key/value 对 | hgetall user:1 |
| hdel | 删除某一个 key/value 对 | hdel user:1 name |
| hexists | 判断一个 key 是否存在 | hexists user:1 name |
| hkeys | 获得所有的 key | hkeys user:1 |
| hvals | 获得所有的 value | hvals user:1 |
| hmset | 设置多个 key/value | hmset user:1 name mike age 12 |
| hmget | 获得多个 key 的 value | hmget user:1 name age |
| hsetnx | 设置一个不存在的 key 的值 | |
| hincrby | 为 value 进行加法运算 | |
| hincrbyfloat | 为 value 加入浮点值 | |
| hlen | 计算 field 个数 | hlen user:1 |
# ①设置值:hset key field value
# 成功会返回 1,反之会返回 0。
127.0.0.1:6379> hset user:1 name tom # 为user:1添加一对field-value
(integer) 1
# ②获取值:hget key field
127.0.0.1:6379> hget user:1 name # 获取user:1的name域(属性)对应的值
"tom"
127.0.0.1:6379> hget user:2 name # 如果键或filed不存在,会返回nil。
(nil)
127.0.0.1:6379> hget user:1 age
(nil)
# ③删除field:hdel key field [field ...]
# hdel 会删除一个或多个 field,返回结果为成功删除 field 的个数。
127.0.0.1:6379> hdel user:1 name
(integer) 1
127.0.0.1:6379> hdel user:1 age
(integer) 0
# ④计算field个数: hlen key
127.0.0.1:6379> hset user:1 name tom
(integer) 1
127.0.0.1:6379> hset user:1 age 23
(integer) 1
127.0.0.1:6379> hset user:1 city tianjin
(integer) 1
127.0.0.1:6379> hlen user:1
(integer) 3
# ⑤批量设置或获取field-value:
hmget key field [field ...]
hmset key field value [field value ...]
127.0.0.1:6379> hmset user:1 name mike age 12 city tianjin
OK
127.0.0.1:6379> hmget user:1 name city
1) "mike"
2) "tianjin"
# ⑥判断field是否存在:hexists key field
# 判断存在时返回结果为 1,不包含时返回 0。
127.0.0.1:6379> hexists user:1 name
(integer) 1
# ⑦获取所有field:hkeys key
# 返回指定哈希键所有的 field。
127.0.0.1:6379> hkeys user:1
1) "name"
2) "age"
3) "city"
# ⑧获取所有value:hvals key
127.0.0.1:6379> hvals user:1
1) "mike"
2) "12"
3) "tianjin"
# ⑨获取所有的field-value: hgetall key
# 在使用 hgetall 时,如果哈希元素个数比较多,会存在阻塞 Redis 的可能。如果开发人员只需要获取部分 field,可以使用 hmget,如果一定要获取全部 field-value,可以使用 hscan 命令,该命令会渐进式遍历哈希类型。
127.0.0.1:6379> hgetall user:1
1) "name"
2) "mike"
3) "age"
4) "12"
5) "city"
6) "tianjin"
# ⑩hincrby hincrbyfloat
hincrby key field
hincrbyfloat key field
# ⑪计算value的字符串长度(需要Redis3.2以上)
hstrlen key field
127.0.0.1:6379> hstrlen user:1 name
(integer) 3 # hget user:1 name的value是tom,所有hstrlen的返回结果是3.
2)哈希内部编码
哈希类型的内部编码有两种:
- ziplist(压缩列表):当哈希类型元素个数小于
hash-max-ziplist-entries配置 (默认 512 个)、同时所有值都小于hash-max-ziplist-value配置(默认 64 字节) 时,Redis 会使用 ziplist 作为哈希的内部实现,ziplist 使用更加紧凑的结构实现多个元素的连续存储,所以在节省内存方面比 hashtable 更加优秀。 - hashtable(哈希表):当哈希类型无法满足 ziplist 的条件时,Redis 会使用 hashtable 作为哈希的内部实现,因为此时 ziplist 的读写效率会下降,而 hashtable 的读写时间复杂度为 O(1)。
# 1、当field个数比较少且没有大的value时,内部编码为ziplist:
127.0.0.1:6379> hmset hashkey f1 v1 f2 v2
OK
127.0.0.1:6379> object encoding hashkey
"ziplist"
# 2、当有value大于64字节,内部编码会由ziplist变为hashtable:
127.0.0.1:6379> hset hashkey f3 "one string is bigger than 64 byte ...忽略..."
OK
127.0.0.1:6379> object encoding hashkey
"hashtable"
# 3、当field个数超过512,内部编码也会由ziplist变为hashtable:
127.0.0.1:6379> hset hashkey f1 v1 f2 v2 f3 v3 ...忽略... f513 v513
OK
127.0.0.1:6379> object encoding hashkey
"hashtable"
3)哈希使用场景
(1)用户信息缓存
相对于使用字符串序列化缓存用户信息,哈希类型变得更加直观,并且在更新操作上会更加便捷。可以将每个用户的 id 定义为键后缀,多对 field-value 对应每个用户的属性。
UserInfo getUserInfo(long id)
{
// 用户id作为key后缀
userRedisKey = "user:info:" + id;
// 使用hgetall获取所有用户信息映射关系
userInfoMap = redis.hgetAll(userRedisKey);
UserInfo userInfo;
if(userInfoMap != null) {
// 将映射关系转换为UserInfo
userInfo = transferMapToUserInfo(userInfoMap);
} else {
// 从MySQL中获取用户信息
userInfo = mysql.get(id);
// 将userInfo变为映射关系使用hmset保存到Redis中
redis.hmset(userRedisKey, transferUserInfoToMap(userInfo));
// 添加过期时间
redis.expire(userRedisKey, 3600);
}
return userInfo;
}
(2)三种缓存方案比较
1)原生字符串类型:每个属性一个键。
set user:1:name tom
set user:1:age 23
set user:1:city beijing
- 优点:简单直观,每个属性都支持更新操作。
- 缺点:占用过多的键,内存占用量较大,同时用户信息内聚性比较差,所以此种方案一般不会在生产环境使用。
2)序列化字符串类型:将用户信息序列化后用一个键保存。
set user:1 serialize(userInfo)
- 优点:简化编程,如果合理的使用序列化可以提高内存的使用效率。
- 缺点:序列化和反序列化有一定的开销,同时每次更新属性都需要把全部数据去除进行反序列化,更新后再序列化到 Redis 中。
3)哈希类型:每个用户属性使用一对 field-value,但是只用一个键保存。
hmset user:1 name tom age 23 city beijing
- 优点:简单直观,如果使用合理可以减少内存空间的使用。
- 缺点:要控制哈希在 ziplist 和 hashtable 两种内部编码的转换,hashtable 会消耗更多内存。
5、列表 List
1)列表概述
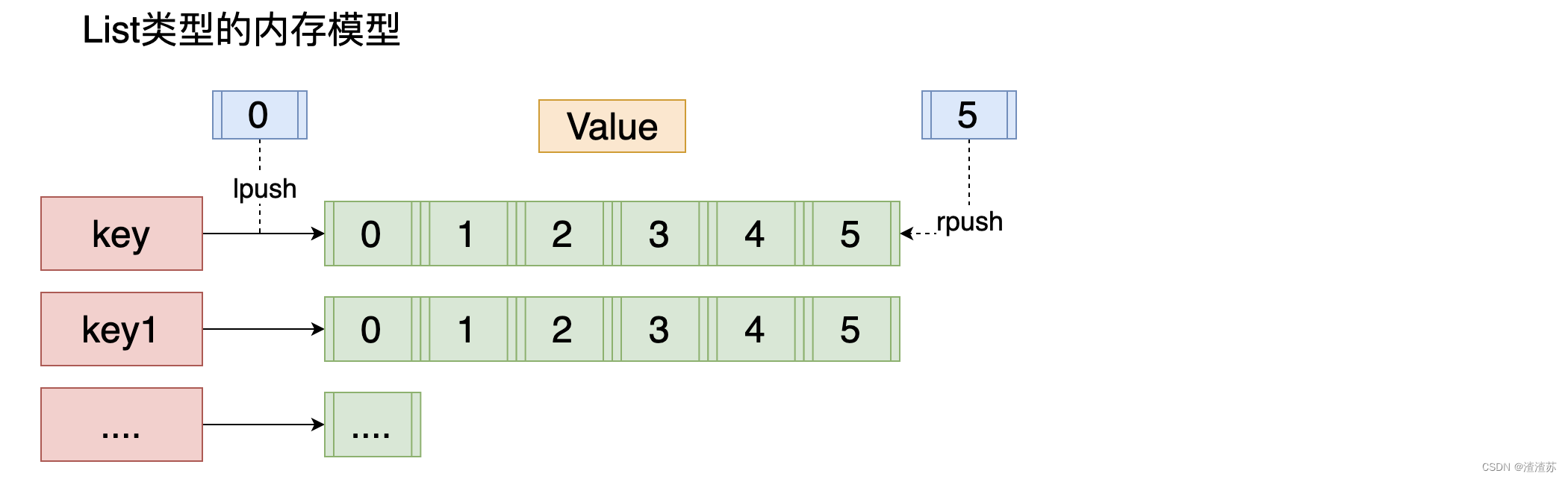
2)列表命令
| 命令 | 说明 |
|---|---|
| lpush | 将某个值加入到一个 key 列表头部 |
| lpushx | 同 lpush, 但是必须要保证这个 key 存在 |
| rpush | 将某个值加入到一个 key 列表末尾 |
| rpushx | 同 rpush, 但是必须要保证这个 key 存在 |
| lpop | 返回和移除列表左边的第一个元素 |
| rpop | 返回和移除列表右边的第一个元素 |
| lrange | 获取某一个下标区间内的元素 |
| llen | 获取列表元素个数 |
| lset | 设置某一个指定索引的值 (索引必须存在) |
| lindex | 获取某一个指定索引位置的元素 |
| lrem listname count value | 删除元素 (正数从左边开始删,负数从右边开始删除) |
| ltrim | 保留列表中特定区间内的元素 |
| linsert listname before/after pivot value | 在某一个元素之前,之后插入新元素 |
| blpop brpop | lpop 和 rpop 的阻塞版本 |
(1)添加操作
# ①从右边插入元素: rpush key value [value . . .]
127.0.0.1:6379> rpush listkey c b a # 从右向左插入元素c、b、a
(integer) 3
127.0.0.1:6379> lrange listkey 0 -1 # 从左到右获取列表的所有元素
1) "c"
2) "b"
3) "a"
# ②从左边插入元素: rpush key value [value . . .]
# ③向某个元素前或者后插入元素: linsert key before|after pivot value
# linsert 命令会从列表中找到等于 pivot 的元素,在其前 (before) 或者后 (after) 插入一个新的元素 value。
127.0.0.1:6379> linsert listkey before b java // 在列表的元素b前插入java。
(integer) 4 // 返回结果4,代表当前列表的长度。
127.0.0.1:6379> lrange listkey 0 -1
1) "c"
2) "java"
3) "b"
4) "a"
(2)查找
# ①获取指定范围内的元素列表: lrange key start end
# 第一,索引下标从左到右分别是 0 到 N-1 ,但是从右到左分别是 -1 到 -N;第二,lrange 中的 end 选项包含了自身
127.0.0.1:6379> lrange listkey 1 3 # 获取列表的第2到第4个元素。
1) "java"
2) "b"
3) "a"
# ②获取列表指定索引下标的元素: lindex key index
127.0.0.1:6379> lindex listkey -1 # 当前列表的最后一个元素为a
"a"
# ③获取列表长度: llen key
127.0.0.1:6379> llen listkey
(integer) 4
(3)删除
# ①从列表左侧弹出元素: lpop key
127.0.0.1:6379> lpop listkey
"c"
127.0.0.1:6379> lrange listkey 0 -1
1) "java"
2) "b"
3) "a"
# ②从列表右侧弹出:
rpop key
# ③删除指定元素:
lrem key count value
# ④按照索引范围修剪列表: ltrim key start end
127.0.0.1 :6379> lrange listkey 0 -1
1) "a"
2) "java"
3) "b"
4) "a"
127.0.0.1 :6379> ltrim listkey 1 3 # 只保留列表listkey的第2个到第4个元素。
OK
127.0.0.1 :6379> lrange listkey 0 -1
1) "java"
2) "b"
3) "a"
- lrem 命令会从列表中找到等于 value 的元素进行删除,根据 count 的不同 分为三种情况:
- count>0 ,从左到右,删除最多 count 个元素。
- count<0 ,从右到左,删除最多 count 绝对值个元素。
- count=0 ,删除所有。
(4)修改
# ①修改指定索引下标的元素: lset key index newValue
127.0.0.1:6379> lset listkey 2 python # 将列表listkey中的第3个元素设置为python
OK
127.0.0.1:6379> lrange listkey 0 -1
1) "java"
2) "b"
3) "python"
(5)阻塞操作
blpop key [key . . .] timeout
brpop key [key . . .] timeout
- blpop 和 brpop 是 lpop 和 rpop 的阻塞版本,它们除了弹出方向不同,使用方法基本相同。
- blpop/brpop 命令包含两个参数:
- key[key…]:多个列表的键。
- timeout:阻塞时间(单位:秒)。
- 列表为空:如果 timeout=3,那么客户端要等到 3 秒后返回;如果 timeout=0,那么客户端一直阻塞等下去,如果此期间添加了数据 element1 ,客户端立即返回。
- 列表不为空:客户端会立即返回。
- 在使用 blpop/brpop 时,有两点需要注意:
- 第一点,如果是多个键,那么 brpop 会从左至右遍历键,一旦有一个键能弹出元素,客户端立即返回。
- 第二点,如果多个客户端对同一个键执行 brpop,那么最先执行 brpop 命令的客户端可以获取到弹出的值。
3)列表的内部编码
列表类型的内部编码有两种。
- ziplist(压缩列表):当列表的元素个数小于
list-max-ziplist-entries配置 (默认 512 个),同时列表中每个元素的值都小于list-max-ziplist-value配置时 (默认 64 字节),Redis 会选用 ziplist 来作为列表的内部实现来减少内存的使用。 - linkedlist(链表) :当列表类型无法满足 ziplist 的条件时,Redis 会使用 linkedlist 作为列表的内部实现。
# 1、当元素个数较少且没有大元素时,内部编码为ziplist:
127.0.0.1:6379> rpush listkey e1 e2 e3
(integer) 3
127.0.0.1:6379> object encoding listkey
"ziplist"
# 2、当元素个数超过512个,内部编码变为linkedlist:
127.0.0.1:6379> rpush listkey e4 e5 . . .忽略 . . . e512 e513
(integer) 513
127.0.0.1:6379> object encoding listkey
"linkedlist"
# 3、当某个元素超过64字节,内部编码也会变为linkedlist:
127.0.0.1:6379> rpush listkey "one string is bigger than 64 byte . . . . . . . . . . . . . . .. . . . . . . . . . . . . . . . . "
(integer) 4
127.0.0.1:6379> object encoding listkey
"linkedlist"
- Redis3.2 版本提供了 quicklist 内部编码,简单地说它是以一个 ziplist 为节点的 linkedlist,它结合了 ziplist 和 linkedlist 两者的优势,为列表类型提供了一种更为优秀的内部编码实现。
4)List 使用场景
(1)消息队列
Redis 的 lpush+brpop 命令组合即可实现阻塞队列,生产者客户端使用 lrpush 从列表左侧插入元素,多个消费者客户端使用 brpop 命令阻塞式的 “抢” 列表尾部的元素,多个客户端保证了消费的负载均衡和高可用性。
(2)文章列表
每个用户有属于自己的文章列表,现需要分页展示文章列表。此时可以考虑使用列表,因为列表不但是有序的,同时支持按照索引范围获取元素。
使用列表类型保存和获取文章列表会存在两个问题。
- 第一,如果每次分页获取的文章个数较多,需要执行多次 hgetall 操作,此时可以考虑使用 Pipeline 批量获取,或者考虑将文章数据序列化为字符串类型,使用 mget 批量获取。
- 第二,分页获取文章列表时,lrange 命令在列表两端性能较好,但是如果列表较大,获取列表中间范围的元素性能会变差,此时可以考虑将列表做二级拆分,或者使用 Redis3.2 的 quicklist 内部编码实现,它结合 ziplist 和 linkedlist 的特点,获取列表中间范围的元素时也可以高效完成。
(3)实际上列表的使用场景很多,在选择时可以参考以下口诀:
- lpush+lpop=Stack(栈)
- lpush+rpop=Queue(队列)
- lpush+ltrim=Capped Collection(有限集合)
- lpush+brpop=Message Queue(消息队列)
6、集合 Set
1)集合概述
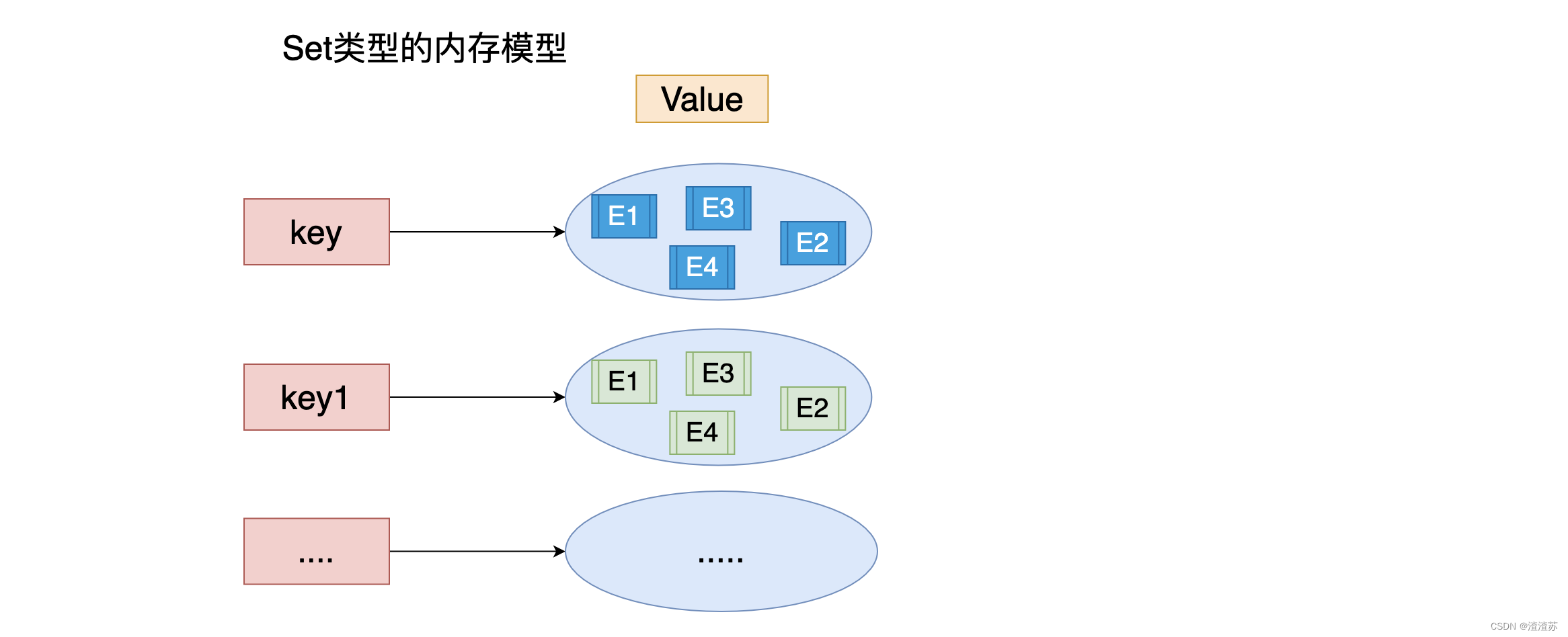
- 集合 (set) 中不允许有重复元素,并且集合中的元素是无序的。
- 一个集合最多可以存储 2^32-1 个元素。
- Redis 除了支持集合内的增删改查,同时还支持多个集合取交集、并集、差集。
2)集合命令
| 命令 | 说明 |
|---|---|
| sadd | 为集合添加元素 |
| smembers | 显示集合中所有元素 无序 |
| scard | 返回集合中元素的个数 |
| spop | 随机返回一个元素 并将元素在集合中删除 |
| smove (formset toset value) | 从一个集合中向另一个集合移动元素 必须是同一种类型 |
| srem | 从集合中删除一个元素 |
| sismember | 判断一个集合中是否含有这个元素 |
| srandmember | 随机返回元素 |
| sdiff | 去掉第一个集合中其它集合含有的相同元素 (第一个集合的补集) |
| sinter | 求交集 |
| sunion | 求和集 |
(1)集合内操作
# ①添加元素: sadd key element [element . . .]
# sadd 返回结果为添加成功的元素个数。
127.0.0.1:6379> exists myset
(integer) 0
127.0.0.1:6379> sadd myset a b c
(integer) 3
127.0.0.1:6379> sadd myset a b
(integer) 0
# ②删除元素: srem key element [element . . .]
# srem 返回结果为成功删除元素个数。
127.0.0.1:6379> srem myset a b
(integer) 2
127.0.0.1:6379> srem myset hello
(integer) 0
# ③计算元素个数: scard key
# scard 的时间复杂度为 O(1),它不会遍历集合所有元素,而是直接用 Redis 内部的变量。
127.0.0.1:6379> scard myset
(integer) 1
# ④判断元素是否在集合中: sismember key element
127.0.0.1:6379> sismember myset c
(integer) 1
# ⑤随机从集合返回指定个数元素: srandmember key [count]
# srandmember 中的 [count] 是可选参数,如果不写默认为 1。
127.0.0.1:6379> srandmember myset 2
1) "a"
2) "c"
127.0.0.1:6379> srandmember myset
"d"
# ⑥从集合随机弹出元素: spop key
# spop 操作可以从集合中随机弹出一个元素。
# 注意 Redis 从 3.2 版本开始,spop 也支持 [count] 参数。
# srandmember 和 spop 都是随机从集合选出元素,两者不同的是 spop 命令执行后,元素会从集合中删除,而 srandmember 不会。
127.0.0.1:6379> spop myset
"c"
127.0.0.1:6379> smembers myset
1) "d"
2) "b"
3) "a"
# ⑦获取所有元素: smembers key
# smembers返回结果是无序的。
127.0.0.1:6379> smembers myset
1) "d"
2) "b"
3) "a"
- smembers 和 lrange、hgetall 都属于比较重的命令,如果元素过多存在阻塞 Redis 的可能性,这时候可以使用 sscan 来完成。
(2)集合间操作
# ①求多个集合的交集: sinter key [key . . .]
127.0.0.1:6379> sinter user:1:follow user:2:follow
1) "sports"
2) "it"
# ②求多个集合的并集: suinon key [key . . .]
127.0.0.1:6379> sunion user:1:follow user:2:follow
1) "sports"
2) "it"
3) "his"
4) "news"
5) "music"
6) "ent"
# ③求多个集合的差集: sdiff key [key . . .]
127.0.0.1:6379> sdiff user:1:follow user:2:follow
1) "music"
2) "his"
# ④将交集、并集、差集的结果保存
sinterstore destination key [key . . .]
suionstore destination key [key . . .]
sdiffstore destination key [key . . .]
127.0.0.1:6379> sinterstore user:1_2:inter user:1:follow user:2:follow
(integer) 2
127.0.0.1:6379> type user:1_2:inter
set
127.0.0.1:6379> smembers user:1_2:inter
1) "it"
2) "sports"
- 集合间的运算在元素较多的情况下会比较耗时,所以 Redis 提供了上面三个命令 (原命令 + store) 将集合间交集、并集、差集的结果保存在 destination key 中。
3)集合的内部编码
集合类型的内部编码有两种:
- intset(整数集合):当集合中的元素都是整数且元素个数小于 set-max-intset-entries 配置 (默认 512 个) 时,Redis 会选用 intset 来作为集合的内部实现,从而减少内存的使用。
- hashtable(哈希表):当集合类型无法满足 intset 的条件时,Redis 会使用 hashtable 作为集合的内部实现。
# 1、当元素个数较少且都为整数时,内部编码为intset:
127.0.0.1:6379> sadd setkey 1 2 3 4
(integer) 4
127.0.0.1:6379> object encoding setkey
"intset"
# 2、当元素个数超过512个,内部编码变为hashtable:
127.0.0.1:6379> sadd setkey 1 2 3 4 5 6 ... 512 513
(integer) 509
127.0.0.1:6379> scard setkey
(integer) 513
127.0.0.1:6379> object encoding
"hashtable"
# 3、当某个元素不为整数时,内部编码也会变为hashtable:
127.0.0.1 :6379> sadd setkey a
(integer) 1
127.0.0.1 :6379> object encoding setkey
"hashtable"
4)集合的使用场景
(1)集合类型比较典型的使用场景是标签 (tag)。 例如给用户打上喜好的标签 (音乐、体育等等)。
下面使用集合类型实现标签功能的若干功能。
# 1、给用户添加标签
sadd user:1:tags tag1 tag2 tag5
sadd user:2:tags tag2 tag3 tag5
. . .
sadd user:k:tags tag1 tag2 tag4
. . .
# 2、给标签添加用户
sadd tag1:users user:1 user:3
sadd tag2:users user:1 user:2 user:3
...
sadd tagk:users user:1 user:2
# 3、删除用户下的标签
srem user:1:tags tag1 tag5
. . .
# 4、删除标签下的用户
srem tag1:users user:1
srem tag5:users user:1
. . .
# 5、计算用户共同感兴趣的标签(可以使用sinter命令,来计算用户共同感兴趣的标签)
sinter user:1:tags user:2:tags
- 用户和标签的关系维护应该在一个事务内执行,防止部分命令失败造成的数据不一致。例如上面的 1 和 2。
(2)集合类型的应用场景通常为以下几种:
- sadd=Tagging(标签)
- spop/srandmember=Random item(生成随机数,比如抽奖)
- sadd+sinter=Social Graph(社交需求)
7、有序集合 ZSet
1)ZSet 概述
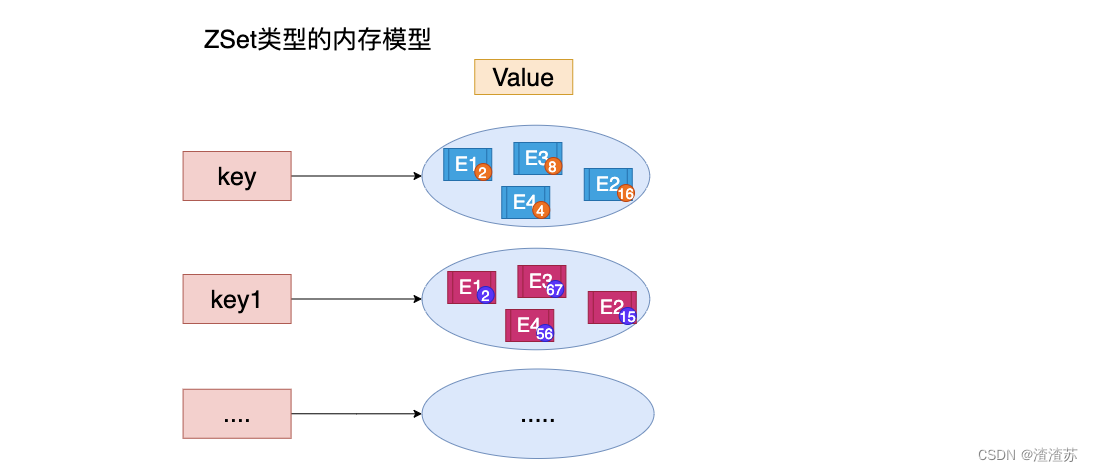
有序集合保留了集合不能有重复成员的特性,但不同的是,有序集合中的元素可以排序。但是它和列表使用索引下标作为排序依据不同的是,它给每个元素设置一个分数 (score) 作为排序的依据。
注意:有序集合中的元素不能重复,但是 score 可以重复,就和一个班里的同学学号不能重复,但是考试成绩可以相同。
下表为列表、集合、有序集合三者的异同点:
| 数据结构 | 是否允许重复元素 | 是否有序 | 有序实现方式 | 应用场景 |
|---|---|---|---|---|
| 列表 | 是 | 是 | 索引下标 | 时间轴、消息队列等 |
| 集合 | 否 | 否 | 无 | 标签、社交等 |
| 有序集合 | 否 | 是 | 分值 | 排行榜系统、社交等 |
2)有序结合命令
| 命令 | 说明 |
|---|---|
| zadd | 添加一个有序集合元素 |
| zcard | 返回集合的元素个数 |
| zrange 升序 | 返回一个范围内的元素 |
| zrevrange 降序 (reversal 反转) | 返回一个范围内的元素 |
| zrangebyscore | 按照分数查找一个范围内的元素 |
| zrank | 返回排名 |
| zrevrank | 倒序排名 |
| zscore | 显示某一个元素的分数 |
| zrem | 移除某一个元素 |
| zincrby | 给某个特定元素加分 |
(1)集合内
# ①添加成员: zadd key score member [score member . . .]
# zadd 返回结果代表成功添加成员的个数。
127.0.0.1:6379> zadd user:ranking 251 tom
(integer) 1
127.0.0.1:6379> zadd user:ranking 1 kris 91 mike 200 frank 220 tim 250 martin (integer) 5
# ②计算成员个数: zcard key
127.0.0.1:6379> zcard user:ranking
(integer) 5
# ③计算某个成员的分数: zscore key member
127.0.0.1:6379> zscore user:ranking tom
"251"
# zscore 如果成员不存在则返回 nil。
127.0.0.1:6379> zscore user:ranking test
(nil)
# ④计算成员的排名
zrank key member
zrevrank key member
# zrank 是从分数从低到高返回排名,zrevrank 反之。(排名从 0 开始计算)
127.0.0.1:6379> zrank user:ranking tom
(integer) 5
127.0.0.1:6379> zrevrank user:ranking tom
(integer) 0
# ⑤删除成员: zrem key member [member . . .]
# zrem 返回结果为成功删除的个数。
127.0.0.1:6379> zrem user:ranking mike
(integer) 1
# ⑥增加成员的分数: zincrby key increment member
# zincrby 返回增加后的分数。
127.0.0.1:6379> zincrby user:ranking 9 tom
"260"
# ⑦返回指定排名范围的成员
zrange key start end [withscores]
zrevrange key start end [withscores]
# 有序集合是按照分值排名的,zrange 是从低到高返回,zrevrange 反之。
127.0.0.1:6379> zrange user:ranking 0 2 withscores
1) "kris"
2) "1"
3) "frank"
4) "200"
5) "tim"
6) "220"
127.0.0.1:6379> zrevrange user:ranking 0 2 withscores
1) "tom"
2) "260"
3) "martin"
4) "250"
5) "tim"
6) "220"
# ⑧返回指定分数范围的成员
# zrangebyscore 按照分数从低到高返回,zrevrangebyscore 反之。
zrangebyscore key min max [withscores] [limit offset count]
zrevrangebyscore key max min [withscores] [limit offset count]
# 1. [limit offset count] 选项可以限制输出的起始位置和个数。
# 2. min 和 max 还支持开区间 (小括号) 和闭区间(中括号),-inf 和 + inf 分别代表无限小和无限大。
# withscores 选项会同时返回每个成员的分数。
127.0.0.1:6379> zrangebyscore user:ranking 200 221 withscores
1) "frank"
2) "200"
3) "tim"
4) "220"
127.0.0.1:6379> zrevrangebyscore user:ranking 221 200 withscores
1) "tim"
2) "220"
3) "frank"
4) "200"
127.0.0.1:6379> zrangebyscore user:ranking (200 +inf withscores
1) "tim"
2) "220"
3) "martin"
4) "250"
5) "tom"
6) "260"
# ⑨返回指定分数范围成员个数: zcount key min max
127.0.0.1:6379> zcount user:ranking 200 221 # 返回200到221分的成员的个数
(integer) 2
# ⑩删除指定排名内的升序元素: zremrangebyrank key start end
# zremrangebyrank 删除第 start 到第 end 名的成员,返回结果为成功删除的个数。
127.0.0.1:6379> zremrangebyrank user:ranking 0 2
(integer) 3
# ⑪删除指定分数范围的成员: zremrangebyscore key min max
127.0.0.1:6379> zremrangebyscore user:ranking (250 +inf # 将250分以上的成员全部删除
(integer) 2
- 有关 zadd 命令有两点需要注意:
- Redis3.2 为 zadd 命令添加了 nx、xx、ch、incr 四个选项:
- nx:member 必须不存在,才可以设置成功,用于添加。
- xx:member 必须存在,才可以设置成功,用于更新。
- ch:返回此次操作后,有序集合元素和分数发生变化的个数。
- incr:对 score 做增加,相当于后面介绍的 zincrby。
- 有序集合相比集合提供了排序字段,但是也产生了代价,zadd 的时间复杂度为 O(log (n)),sadd 的时间复杂度为 O(1)。
- Redis3.2 为 zadd 命令添加了 nx、xx、ch、incr 四个选项:
(2)集合外
# ①交集: zinterstore destination numkeys key [key . . .] [weights weight [weight . . .]] [aggregate sum|min|max]
# zinterstore 的命令参数:
# 1. destination:交集计算结果保存到这个键。
# 2. numkeys :需要做交集计算键的个数。
# 3. key[key…] :需要做交集计算的键。
# 4. weights weight[weight…]:每个键的权重,在做交集计算时,每个键中的每个 member 会将自己分数乘以这个权重,每个键的权重默认是 1。
# 5. aggregate sum|min|max:计算成员交集后,分值可以按照 sum(和) 、min(最小值) 、max(最大值) 做汇总,默认值是 sum。
127.0.0.1:6379> zinterstore user:ranking:1_inter_2 2 user:ranking:1 user:ranking:2
(integer) 3
127.0.0.1 :6379> zrange user:ranking:1_inter_2 0 -1 withscores
1) "mike"
2) "168"
3) "martin"
4) "875"
5) "tom"
6) "1139"
127.0.0.1:6379> zinterstore user:ranking:1_inter_2 2 user:ranking:1 user:ranking:2 weights 1 0.5 aggregate max # user:ranking:2的权重变为0.5,并且聚合效果使用max
(integer) 3
127.0.0.1 :6379> zrange user:ranking:1_inter_2 0 -1 withscores
1) "mike"
2) "91"
3) "martin"
4) "312.5"
5) "tom"
6) "444"
# ②并集
zunionstore destination numkeys key [key ...] [weights weight [weight ...] [aggregate sum|min|max]
127.0.0.1:6379> zunionstore user:ranking:1_union_2 2 user:ranking:1 user:ranking :2
(integer) 7
127.0.0.1:6379> zrange user:ranking:1_union_2 0 -1 withscores
1) "kris"
2) "1"
3) "james"
4) "8"
5) "mike"
6) "168"
7) "frank"
8) "200"
9) "tim"
10) "220"
11) "martin"
12) "875"
13) "tom"
14) "1139"
3)有序集合内部编码
有序集合类型的内部编码有两种:
- ziplist(压缩列表) :当有序集合的元素个数小于
zset-max-ziplist-entries配置 (默认 128 个),同时每个元素的值都小于zset-max-ziplist-value配置(默认 64 字节) 时,Redis 会用 ziplist 来作为有序集合的内部实现,ziplist 可以有效减少内存的使用。 - skiplist(跳跃表):当 ziplist 条件不满足时,有序集合会使用 skiplist 作为内部实现,因为此时 ziplist 的读写效率会下降。
# 1、当元素个数较少且每个元素较小时,内部编码为skiplist:
127.0.0.1:6379> zadd zsetkey 50 e1 60 e2 30 e3
(integer) 3
127.0.0.1:6379> object encoding zsetkey
"ziplist"
# 2、当元素个数超过128个,内部编码变为ziplist:
127.0.0.1:6379> zadd zsetkey 50 e1 60 e2 30 e3 12 e4 ...忽略... 84 e129
(integer) 129
127.0.0.1:6379> object encoding
"skiplist"
# 3、当某个元素大于64字节时,内部编码也会变为hashtable:
127.0.0.1:6379> zadd zsetkey 20 "one string is bigger than 64 byte . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . "
(integer) 1
127.0.0.1:6379> object encoding
"skiplist"
4)有序集合使用场景
有序集合比较典型的使用场景就是排行榜系统。
# 1、添加用户赞数
zadd user:ranking:2016_03_15 mike 3
# 2、取消用户赞数
zrem user:ranking:2016_03_15 mike
# 3、展示获取赞数最多的十个用户
zrevrangebyrank user:ranking:2016_03_15 0 9
# 4、展示用户信息以及用户分数
hgetall user:info:tom
zscore user:ranking:2016_03_15 mike // 用户分数
zrank user:ranking:2016_03_15 mike // 用户排名
8、单个键管理
3、键过期
127.0.0.1:6379> expireat hello 1469980800 # 将键hello在2016-08-01 00:00:00(秒级时间戳为1469980800)过期
(integer) 1
127.0.0.1:6379> expire not_exist_key 30
(integer) 0
127.0.0.1:6379> set hello world
OK
127.0.0.1:6379> expire hello -2
(integer) 1
127.0.0.1:6379> get hello
(nil)
127.0.0.1:6379> hset key f1 v1
(integer) 1
127.0.0.1:6379> expire key 50
(integer) 1
127.0.0.1:6379> ttl key
(integer) 46
127.0.0.1:6379> persist key
(integer) 1
127.0.0.1:6379> ttl key
(integer) -1
127.0.0.1:6379> expire hello 50
(integer) 1
127.0.0.1:6379> ttl hello
(integer) 46
127.0.0.1:6379> set hello world
OK
127.0.0.1:6379> ttl hello
(integer) -1
- 除了 expire、ttl 命令以外,Redis 还提供了 expireat、pexpire、pexpireat、pttl、persist 等一系列命令,下面分别进行说明:
- expire key seconds :键在 seconds 秒后过期。
- expireat key timestamp :键在秒级时间戳 timestamp 后过期。
- ttl 命令和 pttl 都可以查询键的剩余过期时间,但是 pttl 精度更高可以达到毫秒级别,有 3 种返回值:
- 大于等于 0 的整数:键剩余的过期时间(ttl 是秒,pttl 是毫秒)。
- -1:键没有设置过期时间。
- -2:键不存在。
- expireat 命令可以设置键的秒级过期时间戳。
- 除此之外,Redis2.6 版本后提供了毫秒级的过期方案:
- pexpire key milliseconds:键在 milliseconds 毫秒后过期。
- pexpireat key milliseconds-timestamp 键在毫秒级时间戳 timestamp 后过期。
- 注意:但无论是使用过期时间还是时间戳,秒级还是毫秒级,在 Redis 内部最终使用的都是 pexpireat。
- 在使用 Redis 相关过期命令时,需要注意以下几点:
- 如果 expire key 的键不存在,返回结果为 0。
- 如果过期时间为负值,键会立即被删除,犹如使用 del 命令一样。
- persist 命令可以将键的过期时间清除。
- 对于字符串类型键,执行 set 命令会去掉过期时间,这个问题很容易在开发中被忽视。
- Redis 不支持二级数据结构 (例如哈希、列表) 内部元素的过期功能,例如不能对列表类型的一个元素做过期时间设置。
- setex 命令作为 set+expire 的组合,不但是原子执行,同时减少了一次网络通讯的时间。
4、迁移键
# ①move key db
# ②dump key
restore key ttl value
# 第一步:在源Redis上执行dump:
redis-source> set hello world
OK
redis-source> dump hello "\x00\x05world\x06\x00\x8f<T\x04%\xfcNQ"
# 第二步:在目标Redis上执行restore:
redis-target> get hello
(nil)
redis-target> restore hello 0 "\x00\x05world\x06\x00\x8f<T\x04%\xfcNQ"
OK
redis-target> get hello
"world"
# 上面2步对应的伪代码如下:
Redis sourceRedis = new Redis ("sourceMachine", 6379);
Redis targetRedis = new Redis ("targetMachine", 6379);
targetRedis.restore("hello", 0, sourceRedis.dump(key));
# ③migrate
migrate host port key|"" destination-db timeout [copy] [replace] [keys key [key ...]]
127.0.0.1:6379> migrate 127.0.0.1 6379 hello 0 1000 replace
OK
127.0.0.1:6379> migrate 127.0.0.1 6380 "" 0 5000 keys key1 key2 key3
OK
- 迁移键功能非常重要,因为有时候我们只想把部分数据由一个 Redis 迁移到另一个 Redis(例如从生产环境迁移到测试环境),Redis 发展历程中提供了 move、dump+restore、migrate 三组迁移键的方法。
- move 命令用于在 Redis 内部进行数据迁移,Redis 内部可以有多个数据库,彼此在数据上是相互隔离的,move key db 就是把指定的键从源数据库移动到目标数据库中,但笔者认为多数据库功能不建议在生产环境使用。
- dump+restore 可以实现在不同的 Redis 实例之间进行数据迁移的功能,整个迁移的过程分为两步:
- 在源 Redis 上,dump 命令会将键值序列化,格式采用的是 RDB 格式。
- 在目标 Redis 上,restore 命令将上面序列化的值进行复原,其中 ttl 参数代表过期时间,如果 ttl=0 代表没有过期时间。
- 有关 dump+restore 有两点需要注意:第一,整个迁移过程并非原子性的,而是通过客户端分步完成的。第二,迁移过程是开启了两个客户端连接,所以 dump 的结果不是在源 Redis 和目标 Redis 之间进行传输。
- migrate 命令也是用于在 Redis 实例间进行数据迁移的,实际上 migrate 命令就是将 dump、restore、del 三个命令进行组合,从而简化了操作流程。migrate 命令具有原子性,而且从 Redis3.0.6 版本以后已经支持迁移多个键的功能,有效地提高了迁移效率,migrate 在水平扩容中起到重要作用。
- migrate 实现过程和 dump+restore 基本类似,但是有 3 点不太相同:第一,整个过程是原子执行的,不需要在多个 Redis 实例上开启客户端的,只需要在源 Redis 上执行 migrate 命令即可。第二,migrate 命令的数据传输直接在源 Redis 和目标 Redis 上完成的。第三,目标 Redis 完成 restore 后会发送 OK 给源 Redis,源 Redis 接收后会根据 migrate 对应的选项来决定是否在源 Redis 上删除对应的键。
- migrate 的参数进行的说明:
- host:目标 Redis 的 IP 地址。
- port:目标 Redis 的端口。
- key|“”:在 Redis3.0.6 版本之前,migrate 只支持迁移一个键,所以此处是要迁移的键,但 Redis3.0.6 版本之后支持迁移多个键,如果当前需要迁移多个键,此处为空字符串 “”。
- destination-db:目标 Redis 的数据库索引,例如要迁移到 0 号数据库,这里就写 0。
- timeout:迁移的超时时间 (单位为毫秒)。
- [copy]:如果添加此选项,迁移后并不删除源键。
- [replace]:如果添加此选项,migrate 不管目标 Redis 是否存在该键都会正常迁移进行数据覆盖。
- [keys key[key…]]:迁移多个键,例如要迁移 key1、key2、key3,此处填写 “keys key1 key2 key3”。
// 如下是Redis源码中,set命令的函数setKey,可以看到最后执行了removeExpire(db ,key)函数去掉了过期时间
void setKey (redisDb *db, robj *key, robj *val) {
if (lookupKeyWrite (db,key) == NULL) {
dbAdd (db,key,val);
} else {
dbOverwrite (db,key,val);
}
incrRefCount (val);
// 去掉过期时间
removeExpire (db,key);
signalModifiedKey (db,key);
}
笔者建议使用 migrate 命令进行键值迁移。
下表为 move、dump+restore、migrate 三种迁移方式的异同点:
| 命令 | 作用域 | 原子性 | 支持多个键 |
|---|---|---|---|
| move | Redis 实例内部 | 是 | 否 |
| dump+restore | Redis 实例之间 | 否 | 否 |
| migrate | Redis 实例之间 | 是 | 是 |
5、遍历键
Redis 提供了两个命令遍历所有的键,分别是 keys 和 scan。
1)全量遍历键
keys pattern
127.0.0.1:6379> dbsize
(integer) 0
127.0.0.1:6379> mset hello world redis best jedis best hill high
OK
127.0.0.1:6379> keys *
1) "hill"
2) "jedis"
3) "redis"
4) "hello"
127.0.0.1:6379> keys [j,r]edis # 匹配以j,r开头,紧跟edis字符串的所有键
1) "jedis"
2) "redis"
127.0.0.1:6379> keys hll*
1) "hill"
2) "hello"
redis-cli keys video* | xargs redis-cli del # 删除所有以video字符串开头的键
- 如果要获取所有的键,可以使用 keys pattern 命令。
- pattern 使用的是 glob 风格的通配符:
1.
* 代表匹配任意字符。
2. ? 代表匹配一个字符。
3. []代表匹配部分字符,例如 [1,3] 代表匹配 1,3 ,[1-10]代表匹配 1 到 10 的任意数字。
4. \x 用来做转义,例如要匹配星号、问号需要进行转义。 - 如果 Redis 包含了大量的键,执行 keys 命令很可能会造成 Redis 阻塞,所以一般建议不要生产环境下使用 keys 命令。但有时候确实有遍历键的需求该怎么办,可以在以下三种情况使用:
- 在一个不对外提供服务的 Redis 从节点上执行,这样不会阻塞到客户端的请求,但是会影响到主从复制。
- 如果确认键值总数确实比较少,可以执行该命令。
- 使用 scan 命令渐进式的遍历所有键,可以有效防止阻塞。
- Redis 从 2.8 版本后,提供了一个新的命令 scan,它能有效的解决 keys 命令存在的问题。和 keys 命令执行时会遍历所有键不同,scan 采用渐进式遍历的方式来解决 keys 命令可能带来的阻塞问题,每次 scan 命令的时间复杂度是 O(1),但是要真正实现 keys 的功能,需要执行多次 scan。Redis 存储键值对实际使用的是 hashtable 的数据结构。
2)渐进式遍历
scan cursor [match pattern] [count number]
# 第一次执行scan0,返回结果分为两个部分:第一个部分6就是下次scan需要的cursor,第二个部分是10个键:
127.0.0.1:6379> scan 0
1) "6"
2) 1) "w"
2) "i"
3) "e"
4) "x"
5) "j"
6) "q"
7) "y"
8) "u"
9) "b"
10) "o"
127.0.0.1:6379> scan 6
1) "11"
2) 1) "h"
2) "n"
3) "m"
4) "t"
5) "c"
6) "d"
7) "g"
8) "p"
9) "z"
10) "a"
127.0.0.1:6379> scan 11
1) "0"
2) 1) "s"
2) "f"
3) "r"
4) "v"
5) "k"
6) "l"
- scan 的参数进行的说明:
- cursor 是必需参数,实际上 cursor 是一个游标,第一次遍历从 0 开始,每次 scan 遍历完都会返回当前游标的值,直到游标值为 0,表示遍历结束。
- match pattern 是可选参数,它的作用的是做模式的匹配,这点和 keys 的模式匹配很像。
- count number 是可选参数,它的作用是表明每次要遍历的键个数,默认值是 10,此参数可以适当增大。
- 除了 scan 以外,Redis 提供了面向哈希类型、集合类型、有序集合的扫描遍历命令,解决诸如 hgetall、smembers、zrange 可能产生的阻塞问题,对应的命令分别是 hscan、sscan、zscan,它们的用法和 scan 基本类似。
- 渐进式遍历可以有效的解决 keys 命令可能产生的阻塞问题,但是 scan 并非完美无瑕,如果在 scan 的过程中如果有键的变化 (增加、删除、修改),那么遍历效果可能会碰到如下问题: 新增的键可能没有遍历到,遍历出了重复的键等情况,也就是说 scan 并不能保证完整的遍历出来所有的键,这些是我们在开发时需要考虑的。
// 以sscan为例子进行说明,当前集合有两种类型的元素,例如分别以old:user和new:user开头,先需要将old:user开头的元素全部删除:
String key = "myset";
// 定义pattern
String pattern = "old:user*";
// 游标每次从0开始
String cursor = "0";
while (true) {
// 获取扫描结果
ScanResult scanResult = redis.sscan (key, cursor, pattern);
List elements = scanResult.getResult ();
if (elements != null && elements.size () > 0) {
// 批量删除
redis.srem (key, elements);
}
// 获取新的游标
cursor = scanResult.getStringCursor ();
// 如果游标为0表示遍历结束
if ("0".equals (cursor)) {
break;
}
}
三、小功能大用处
1、慢查询
慢查询的两个配置参数
Redis 使用一个内存列表记录查询时间超过阀值的命令。
slowlog-log-slower-than
slowlog-log-slower-than超时阀值,它的单位是微秒 (1 秒 = 1000 毫秒 = 1000000 微秒),默认值是 10000 ,假如执行了一条“很慢” 的命令(例如keys*),如果它的执行时间超过了 10000 微秒,那么它将被记录在慢查询日志中。slowlog-log-slower-than配置建议: 默认值超过 10 毫秒判定为慢查询,需要根据 Redis 并发量调整该值。由于 Redis 采用单线程响应命令,对于高流量的场景,如果命令执行时间在 1 毫秒以上,那么 Redis 最多可支撑 OPS 不到 1000。因此对于高 OPS 场景的 Redis 建议设置为 1 毫秒。- 如果
slowlog-log-slower-than=0会记录所有的命令,slowlog-log-slower-than<0对于任何命令都不会进行记录。
slowlog-max-len
slowlog-max-len就是列表的最大长度。一个新的命令满足慢查询条件时被插入到这个列表中,当慢查询日志列表已处于其最大长度时,最早插入的一个命令将从列表中移出。slowlog-max-len配置建议: 线上建议调大慢查询列表,记录慢查询时 Redis 会对长命令做截断操作,并不会占用大量内存。增大慢查询列表可以减缓慢查询被剔除的可能,例如线上可设置为 1000 以上。
配置
在 Redis 中有两种修改配置的方法,一种是修改配置文件,另一种是使用 config set 命令动态修改。
# 将slowlog-log-slower-than设置为20000微秒,slowlog-max-len设置为1000:
config set slowlog-log-slower-than 20000
config set slowlog-max-len 1000
config rewrite # 将配置持久化到本地配置文件
慢查询使用
实现对慢查询日志的访问和管理的命令
# 1、获取慢查询日志
slowlog get [n] # 参数 n 指定条数
127.0.0.1:6379> slowlog get
1) 1) (integer) 666 # 慢查询日志的标识 id
2) (integer) 1456786500 # 发生时间戳
3) (integer) 11615 # 命令耗时
4) 1) "BGREWRITEAOF" # 执行命令和参数
2) 1) (integer) 665
2) (integer) 1456718400
3) (integer) 12006
4) 1) "SETEX"
2) "video_info_200"
3) "300"
4) "2"
...
# 2、获取慢查询日志列表当前的长度
slowlog len
127.0.0.1:6379> slowlog len
(integer) 45
# 3、慢查询日志重置(实际是对列表做清理操作)
slowlog reset
127.0.0.1:6379> slowlog len
(integer) 45
127.0.0.1:6379> slowlog reset
OK
127.0.0.1:6379> slowlog len
(integer) 0
慢查询注意事项
慢查询在实际使用过程中要注意以下几点:
- 慢查询只记录命令执行时间,并不包括命令排队和网络传输时间。因此客户端执行命令的时间会大于命令实际执行时间。因为命令执行排队机制,慢查询会导致其他命令级联阻塞,因此当客户端出现请求超时,需要检查该时间点是否有对应的慢查询,从而分析出是否为慢查询导致的命令级联阻塞。
- 由于慢查询日志是一个先进先出的队列,也就是说如果慢查询比较多的情况下,可能会丢失部分慢查询命令,为了防止这种情况发生,可以定期执行 slow get 命令将慢查询日志持久化到其他存储中 (例如 MySQL),然后可以制作可视化界面进行查询。
2、Pipeline
Pipeline 概念
Redis 客户端执行一条命令分为如下四个过程:
① 发送命令
② 命令排队
③ 命令执行
④ 返回结果
其中 ①+④ 称为 Round Trip Time (RTT, 往返时间)。
- Redis 提供了批量操作命令 (例如 mget、mset 等),有效地节约 RTT。大部分命令是不支持批量操作的,例如要执行 n 次 hgetall 命令,并没有 mhgetall 命令存在,需要消耗 n 次 RTT。
- Pipeline(流水线) 机制能改善上面这类问题,它能将一组 Redis 命令进行组装,通过一次 RTT 传输给 Redis,再将这组 Redis 命令的执行结果按顺序返回给客户端。
原生批量命令与 Pipeline 对比
- 原生批量命令是一个命令对应多个 key,它是原子的,Pipeline 是非原子的。
- 原生批量命令是 Redis 服务端支持实现的,而 Pipeline 需要服务端和客户端的共同实现。
Pipeline 最佳实践
- 每次 Pipeline 组装的命令个数不能没有节制,否则一次组装 Pipeline 数据量过大,一方面会增加客户端的等待时间,另一方面会造成一定的网络阻塞,可以将一次包含大量命令的 Pipeline 拆分成多次较小的 Pipeline 来完成。
- Pipeline 只能操作一个 Redis 实例,但是即使在分布式 Redis 场景中,也可以作为批量操作的重要优化手段。
3、事务
为了保证多条命令组合的原子性,Redis 提供了简单的事务功能以及集成 Lua 脚本来解决这个问题。
Redis 提供了简单的事务功能,将一组需要一起执行的命令放到 multi 和 exec 两个命令之间。multi 命令代表事务开始,exec 命令代表事务结束,它们之间的命令是原子顺序执行的。
// 用户关注的例子
127.0.0.1:6379> multi
OK
127.0.0.1:6379> sadd user:a:follow user:b
QUEUED
127.0.0.1:6379> sadd user:b:fans user:a
QUEUED
127.0.0.1:6379> sismember user:a:follow user:b
(integer) 0
127.0.0.1:6379> exec
1) (integer) 1
2) (integer) 1
127.0.0.1:6379> sismember user:a:follow user:b
(integer) 1
127.0.0.1:6379> discard
OK
127.0.0.1:6379> sismember user:a:follow user:b
(integer) 0
127.0.0.1:6379> multi
OK
127.0.0.1:6379> sadd user:a:follow user:b
QUEUED
127.0.0.1:6379> zadd user:b:fans 1 user:a
QUEUED
127.0.0.1:6379> exec
1) (integer) 1
2) (error) WRONGTYPE Operation against a key holding the wrong kind of value 127.0.0.1:6379> sismember user:a:follow user:b
(integer) 1
#T1:客户端1
127.0.0.1:6379> set key "java"
OK
#T2:客户端1
127.0.0.1:6379> watch key
OK
#T3:客户端1
127.0.0.1:6379> multi
OK
#T4:客户端2
127.0.0.1:6379> append key python
(integer) 11
#T5:客户端1
127.0.0.1:6379> append key jedis
QUEUED
#T6:客户端1
127.0.0.1:6379> exec
(nil)
#T7:客户端1
127.0.0.1:6379> get key
"javapython"
- sadd 命令此时的返回结果是 QUEUED,代表命令并没有真正执行,而是暂时保存在 Redis 中。只有当 exec 执行后,用户 A 关注用户 B 的行为才算完成。
- 如果要停止事务的执行,可以使用 discard 命令代替 exec 命令即可。
- 如果事务中的命令出现错误,Redis 的处理机制也不尽相同:
- 命令错误:
- 运行时错误:Redis 并不支持回滚功能,sadd user🅰️follow user:b 命令已经执行成功,开发人员需要自己修复这类问题。
- 有些应用场景需要在事务之前,确保事务中的 key 没有被其他客户端修改过,才执行事务,否则不执行 (类似乐观锁)。Redis 提供了 watch 命令来解决这类问题。
4、Lua
Lua 用法概述
Redis 将 Lua 作为脚本语言可帮助开发者定制自己的 Redis 命令,在这之前,必须修改源码。
1)数据类型及其逻辑处理
Lua 语言提供了如下几种数据类型: booleans(布尔)、numbers(数值)、strings(字符串)、tables(表格),和许多高级语言相比,相对简单。
1、字符串
-- local代表val是一个局部变量,如果没有local代表是全局变量。 print函数可以打印出变量的值
local strings val = "world";
-- 结果是"world"
print (hello)
2、数组
local tables myArray = {"redis", "jedis", true, 88.0}
-- true
print (myArray[3])
①for
local int sum = 0
for i = 1, 100
do
sum = sum + i
end
-- 输出结果为5050
print (sum)
for i = 1, #myArray
do
print (myArray [i])
end
for index,value in ipairs (myArray)
do
print (index)
print (value)
end
②while
local int sum = 0
local int i = 0
while i <= 100
do
sum = sum +i
i = i + 1
end
--输出结果为5050
print (sum)
③if else
local tables myArray = {"redis", "jedis", true, 88 .0}
for i = 1, #myArray
do
if myArray [i] == "jedis"
then
print ("true")
break
else
--do nothing
end
end
3、哈希
local tables user_1 = {age = 28, name = "tome"}
--user_1 age is 28
print ("user_1 age is " . . user_1 ["age"])
for key,value in pairs (user_1)
do print (key . . value)
end
- “–” 是 Lua 语言的注释。
- 在 Lua 中,如果要使用类似数组的功能,可以用 tables 类型。但和大多数编程语言不同的是,Lua 的数组下标从 1 开始计算。
- 关键字 for 以 end 作为结束符。
- 要遍历 myArray,首先需要知道 tables 的长度,只需要在变量前加一个 #号即可。
- 除此之外,Lua 还提供了内置函数 ipairs,使用 for index,value ipairs(tables) 可以遍历出所有的索引下标和值。
- while 循环同样以 end 作为结束符。
- if 以 end 结尾,if 后紧跟 then。
- 如果要使用类似哈希的功能,同样可以使用 tables 类型。
- strings 1…string2 是将两个字符串进行连接。
2)函数定义
在 Lua 中,函数以 function 开头,以 end 结尾,funcName 是函数名,中间部分是函数体。
function funcName ()
. . .
end
// contact函数将两个字符串拼接:
function contact (str1, str2)
return str1 . . str2
end
--"hello world"
print (contact ("hello ", "world"))
在 Redis 中使用 Lua
在 Redis 中执行 Lua 脚本有两种方法:eval 和 evalsha。
1)eval
# eval 脚本内容 key个数 key列表 参数列表
# 此时KEYS[1]="redis",ARGV[1]="world",所以最终的返回结果是"hello redisworld"。
127.0.0.1:6379> eval 'return "hello " . . KEYS [1] . . ARGV [1] ' 1 redis world
"hello redisworld"
2)evalsha
# ①加载脚本:script load命令可以将脚本内容加载到Redis内存中:
# 将lua_get.lua加载到Redis中,得到SHA1
# redis-cli script load "$ (cat lua_get.lua)"
"7413dc2440db1fea7c0a0bde841fa68eefaf149c"
# ②执行脚本:evalsha 的使用方法如下,参数使用SHA1值,执行逻辑和eval一致。
# evalsha 脚本SHA1值 key个数 key列表 参数列表
127.0.0.1 :6379> evalsha 7413dc2440db1fea7c0a0bde841fa68eefaf149c 1 redis world
"hello redisworld"
- 如果 Lua 脚本较长,还可以使用 redis-cli–eval 直接执行文件。
- eval 命令和–eval 参数本质是一样的,客户端如果想执行 Lua 脚本,首先在客户端编写好 Lua 脚本代码,然后把脚本作为字符串发送给服务端,服务端会将执行结果返回给客户端。
- evalsha 命令来执行 Lua 脚本:首先要将 Lua 脚本加载到 Redis 服务端,得到该脚本的 SHA1 校验和,evalsha 命令使用 SHA1 作为参数可以直接执行对应 Lua 脚本,避免每次发送 Lua 脚本的开销。这样客户端就不需要每次执行脚本内容,而脚本也会常驻在服务端,脚本功能得到了复用。
Lua 的 Redis API
Lua 可以使用 redis.call 函数实现对 Redis 的访问。
redis.call ("set", "hello", "world")
redis.call ("get", "hello")
# 放在Redis 的执行效果如下:
127.0.0.1 :6379> eval 'return redis.call ("get", KEYS [1]) ' 1 hello
"world"
- Lua 还可以使用 redis.pcall 函数实现对 Redis 的调用,redis.call 和 redis.pcall 的不同在于,如果 redis.call 执行失败,那么脚本执行结束会直接返回错误,而 redis.pcall 会忽略错误继续执行脚本。
- Lua 可以使用 redis.log 函数将 Lua 脚本的日志输出到 Redis 的日志文件中,但是一定要控制日志级别。
15、Lua 脚本功能为 Redis 开发和运维人员带来如下三个好处:
- Lua 脚本在 Redis 中是原子执行的,执行过程中间不会插入其他命令。
- Lua 脚本可以帮助开发和运维人员创造出自己定制的命令,并可以将这些命令常驻在 Redis 内存中,实现复用的效果。
- Lua 脚本可以将多条命令一次性打包,有效地减少网络开销。
Redis 如何管理 Lua 脚本
Redis 提供了 4 个命令实现对 Lua 脚本的管理:
# 1、script load 命令用于将 Lua 脚本加载到 Redis 内存中。
script load script
# 2、script exists 命令用于判断 sha1 是否已经加载到 Redis 内存中。
scripts exists sha1 [sha1 … ]
# 返回结果代表 sha1[sha 1 …] 被加载到 Redis 内存的个数。
127.0.0.1:6379> script exists a5260dd66ce02462c5b5231c727b3f7772c0bcc5
1) (integer) 1
# 3、script flush 命令用于清除 Redis 内存已经加载的所有 Lua 脚本。
127.0.0.1:6379> script exists a5260dd66ce02462c5b5231c727b3f7772c0bcc5
1) (integer) 1
127.0.0.1:6379> script flush
OK
127.0.0.1:6379> script exists a5260dd66ce02462c5b5231c727b3f7772c0bcc5
1) (integer) 0
# 4、script kill 命令用于杀掉正在执行的 Lua 脚本。如果 Lua 脚本比较耗时,甚至 Lua 脚本存在问题,那么此时 Lua 脚本的执行会阻塞 Redis,直到脚本执行完毕或者外部进行干预将其结束。
127.0.0.1:6379> eval 'while 1==1 do end ' 0 // 死循环,当前客户端会阻塞
127.0.0.1:6379> get hello
(error) BUSY Redis is busy running a script . You can only call SCRIPT KILL or
SHUTDOWN NOSAVE
127.0.0.1:6379> script kill
OK
127.0.0.1:6379> get hello
"world"
- Redis 提供了一个 lua-time-limit 参数,默认是 5 秒,它是 Lua 脚本的 “超时时间”,但这个超时时间仅仅是当 Lua 脚本时间超过 lua-time-limit 后,向其他命令调用发送 BUSY 的信号,但是并不会停止掉服务端和客户端的脚本执行,所以当达到 lua-time-limit 值之后,其他客户端在执行正常的命令时,将会收到“Busy Redis is busy running a script” 错误,并且提示使用 script kill 或者 shutdown nosave 命令来杀掉这个 busy 的脚本。
- 当 script kill 执行之后,客户端调用会恢复。
- 注意:如果当前 Lua 脚本正在执行写操作,那么 script kill 将不会生效。
5、Bitmaps
Bitmaps 数据结构模型
Bitmaps 本身不是一种数据结构,实际上它就是字符串,但是它可以对字符串的位进行操作。
Bitmaps 单独提供了一套命令,所以在 Redis 中使用 Bitmaps 和使用字符串的方法不太相同。可以把 Bitmaps 想象成一个以位为单位的数组,数组的每个单元只能存储 0 和 1,数组的下标在 Bitmaps 中叫做偏移量。
Bitmaps 命令
假设将每个独立用户是否访问过网站存放在 Bitmaps 中,将访问的用户记做 1,没有访问的用户记做 0,用偏移量作为用户的 id。
直接将用户 id 和 Bitmaps 的偏移量对应势必会造成一定的浪费,通常的做法是每次做 setbit 操作时将用户 id 减去这个指定数字。在第一次初始化 Bitmaps 时,假如偏移量非常大,那么整个初始化过程执行会比较慢,可能会造成 Redis 的阻塞 (由于要申请大量内存)。
# 1、设置值 : setbit key offset value
# 将第0、5、11位用户设置为1
127.0.0.1:6379> setbit unique:users:2016-04-05 0 1
(integer) 0
127.0.0.1:6379> setbit unique:users:2016-04-05 5 1
(integer) 0
127.0.0.1:6379> setbit unique:users:2016-04-05 11 1
(integer) 0
127.0.0.1:6379> setbit unique:users:2016-04-05 15 1
(integer) 0
127.0.0.1:6379> setbit unique:users:2016-04-05 19 1
(integer) 0
# 2、获取值 : getbit key offset
127.0.0.1:6379> getbit unique:users:2016-04-05 8
(integer) 0
127.0.0.1:6379> getbit unique:users:2016-04-05 5
(integer) 1
# 3、获取Bitmaps指定范围值为1的个数 : bitcount [start] [end]
# bitcount 的 [start] 和[end]代表起始和结束字节数。
127.0.0.1:6379> bitcount unique:users:2016-04-05
(integer) 5
# 计算用户id在第1个字节到第3个字节之间的独立访问用户数,对应的用户id是11,15,19
127.0.0.1:6379> bitcount unique:users:2016-04-05 1 3
(integer) 3
# 4、Bitmaps间的运算 : bitop op destkey key [key . . . .]
# bitop 是一个复合操作,它可以做多个 Bitmaps 的 and(交集)、or(并集)、not(非)、xor(异或) 操作并将结果保存在 destkey 中。
127.0.0.1:6379> bitop and unique:users:and:2016-04-04_03 unique:users:2016-04- unique:users:2016-04-03
(integer) 2
127.0.0.1:6379> bitcount unique:users:and:2016-04-04_03
(integer) 2
# 5、计算Bitmaps中第一个值为targetBit的偏移量 : bitpos key targetBit [start] [end]
# bitops 有两个选项 [start] 和[end],分别代表起始字节和结束字节。
# 计算2016-04-04当前访问网站的最小用户id:
127.0.0.1:6379> bitpos unique:users:2016-04-04 1
(integer) 1
# 计算第0个字节到第1个字节之间,第一个值为0的偏移量
127.0.0.1:6379> bitpos unique:users:2016-04-04 0 0 1
(integer) 0 # id=0的用户
Bitmaps 分析
当用户量很少的时候,对比用 set,用 Bitmaps 会占用更大的内存。因为 set 是随着用户量一个一个增长内存的,而 Bitmaps 是根据 id 的,因此一开始就是这么大的内存,此时使用 Bitmaps 也不太合适,因为大部分位都是 0。
6、HyperLogLog
- HyperLogLog 并不是一种新的数据结构 (实际类型为字符串类型),而是一种基数算法,通过 HyperLogLog 可以利用极小的内存空间完成独立总数的统计,数据集可以是 IP、Email、ID 等。
- HyperLogLog 内存占用量非常小,但是存在错误率,开发者在进行数据结构选型时只需要确认如下两条即可:
- 只为了计算独立总数,不需要获取单条数据。
- 可以容忍一定误差率,毕竟 HyperLogLog 在内存的占用量上有很大的优势。
- HyperLogLog 提供了 3 个命令:pfadd、pfcount、pfmerge。
# 1、添加 : pfadd key element [element … ]
# pfadd 用于向 HyperLogLog 添加元素,如果添加成功返回 1。
127.0.0.1:6379> pfadd 2016_03_06:unique:ids "uuid-1" "uuid-2" "uuid-3" "uuid-4"
(integer) 1
# 2、计算独立用户个数 : pfcount key [key … ]
# pfcount 用于计算一个或多个 HyperLogLog 的独立基数。
127.0.0.1:6379> pfcount 2016_03_06:unique:ids
(integer) 4
127.0.0.1:6379> pfadd 2016_03_06:unique:ids "uuid-1" "uuid-2" "uuid-3" "uuid-90"
(integer) 1
127.0.0.1:6379> pfcount 2016_03_06:unique:ids
(integer) 5 # 新增uuid-90
# HyperLogLog 内存占用量小得惊人,但是用如此小空间来估算如此巨大的数据,必然不是 100% 的正确,其中一定存在误差率。Redis 官方给出的数字是 0.81% 的失误率。
# 向HyperLogLog插入100万个id,插入前记录一下info memory:
127.0.0.1:6379> info memory
# Memory
used_memory:835144
used_memory_human:815.57K
# . . .向2016_05_01:unique:ids插入100万个用户,每次插入1000条:
elements=""
key="2016_05_01:unique:ids"
for i in `seq 1 1000000`
do
elements="${elements} uuid-"${i}
if [ [ $ ( (i%1000)) == 0 ]];
then
redis-cli pfadd ${key} ${elements}
elements=""
fi
done
127.0.0.1:6379> info memory
# Memory
used_memory :850616
used_memory_human :830.68K # 内存只增加了15K左右.
127.0.0.1:6379> pfcount 2016_05_01:unique:ids # pfcount的执行结果并不是100万
(integer) 1009838
# 如果使用集合,内存使用约84MB,但独立用户数为100万。
# 3、合并 : pfmerge destkey sourcekey [sourcekey . . .]
# pfmerge 可以求出多个 HyperLogLog 的并集并赋值给 destkey。
7、发布订阅
Redis 提供了基于 “发布 / 订阅” 模式的消息机制,此种模式下,消息发布者和订阅者不进行直接通信,发布者客户端向指定的频道(channel)发布消息,订阅该频道的每个客户端都可以收到该消息。
发布订阅的使用场景: 聊天室、公告牌、服务之间利用消息解耦都可以使用发布订阅模式。
Redis 主要提供了发布消息、订阅频道、取消订阅以及按照模式订阅和取消订阅等命令。
1、发布消息
publish channel message
# 向channel:sports频道发布一条消息“Tim won the championship”
# publish channel 返回结果为订阅者个数.
127.0.0.1:6379> publish channel:sports "Tim won the championship"
(integer) 0
2、订阅消息
- 订阅者可以订阅一个或多个频道.
- 有关订阅命令有两点需要注意:
- 客户端在执行订阅命令之后进入了订阅状态,只能接收 subscribe、psubscribe、unsubscribe、punsubscribe 的四个命令。
- 新开启的订阅客户端,无法收到该频道之前的消息,因为 Redis 不会对发布的消息进行持久化。
subscribe channel [channel . . .]
# (一客户端A)
127.0.0.1:6379> subscribe channel:sports
Reading messages . . . (press Ctrl-C to quit)
1) "subscribe"
2) "channel:sports"
3) (integer) 1
# (另一客户端B)
127.0.0.1:6379> publish channel:sports "James lost the championship"
(integer) 1
# (一客户端A)
127.0.0.1:6379> subscribe channel:sports
Reading messages . . . (press Ctrl-C to quit)
. . .
1) "message"
2) "channel:sports"
3) "James lost the championship"
3、取消订阅
客户端可以通过 unsubscribe 命令取消对指定频道的订阅,取消成功后,不会再收到该频道的发布消息。
unsubscribe [channel [channel . . .]]
127.0.0.1:6379> unsubscribe channel:sports
1) "unsubscribe"
2) "channel:sports"
3) (integer) 0
4、按照模式订阅和取消订阅
psubscribe pattern [pattern . . .]
punsubscribe [pattern [pattern . . .]]
127.0.0.1:6379> psubscribe it* // 订阅以it开头的所有频道
Reading messages . . . (press Ctrl-C to quit)
1) "psubscribe"
2) "it*"
3) (integer) 1
5、查询订阅
# ①查看活跃的频道
pubsub channels [pattern]
127.0.0.1:6379> pubsub channels
1) "channel:sports"
2) "channel:it"
3) "channel:travel"
127.0.0.1 :6379> pubsub channels channel:*r*
1) "channel:sports"
2) "channel:travel"
# ②查看频道订阅数
pubsub numsub [channel . . .]
127.0.0.1:6379> pubsub numsub channel:sports
1) "channel:sports"
2) (integer) 2
# ③查看模式订阅数
pubsub numpat
127.0.0.1:6379> pubsub numpat
(integer) 1 # 当前只有一个客户端通过模式来订阅
- 和很多专业的消息队列系统(例如 Kafka、RocketMQ)相比,Redis 的发布订阅略显粗糙,例如无法实现消息堆积和回溯。但胜在足够简单,如果当前场景可以容忍的这些缺点,也不失为一个不错的选择。
- 除了 subcribe 和 unsubscribe 命令,Redis 命令还支持 glob 风格的订阅命令 psubscribe 和取消订阅命令 punsubscribe。
- 所谓活跃的频道是指当前频道至少有一个订阅者,其中 [pattern] 是可以指定具体的模式。
8、GEO
Redis3.2 版本提供了 GEO(地理信息定位)功能,支持存储地理位置信息用来实现诸如附近位置、摇一摇这类依赖于地理位置信息的功能。
1、增加地理位置信息
# longitude、latitude、member 分别是该地理位置的经度、纬度、成员.
geoadd key longitude latitude member [longitude latitude member . . .]
127.0.0.1:6379> geoadd cities:locations 116.28 39.55 beijing
(integer) 1
# 如果需要更新地理位置信息,仍然可以使用 geoadd 命令,虽然返回结果为 0.
127.0.0.1:6379> geoadd cities:locations 116.28 39.55 beijing
(integer) 0
# geoadd 返回结果代表添加成功的个数,如果 cities:locations 没有包含 tianjin,那么返回结果为 1,如果已经存在则返回 0.
127.0.0.1:6379> geoadd cities:locations 117.12 39.08 tianjin 114.29 38.02 shijiazhuang 118.01 39.38 tangshan 115.29 38.51 baoding
(integer) 4
2、获取地理位置信息
geopos key member [member . . .]
127.0.0.1:6379> geopos cities:locations tianjin
1) 1) "117.12000042200088501"
2) "39.0800000535766543"
3、获取两个地理位置的距离
geodist 的参数 unit 代表返回结果的单位,包含以下四种:
- m(meters)代表米。
- km(kilometers)代表公里。
- mi(miles)代表英里。
- ft(feet)代表尺。
geodist key member1 member2 [unit]
127.0.0.1:6379> geodist cities:locations tianjin beijing km
"89.2061"
4、获取指定位置范围内的地理信息位置集合
- georadius 和 georadiusbymember 两个命令的作用是一样的,都是以一个地理位置为中心算出指定半径内的其他地理信息位置,不同的是 georadius 命令的中心位置给出了具体的经纬度,georadiusbymember 只需给出成员即可。
- georadius 的 radiusm|km|ft|mi 是必需参数,指定了半径(带单位),这两个命令有很多 可选参数,如下:
- withcoord:返回结果中包含经纬度。
- withdist:返回结果中包含离中心节点位置的距离。
- withhash:返回结果中包含 geohash。
- COUNT count:指定返回结果的数量。
- asc|desc:返回结果按照离中心节点的距离做升序或者降序。
- store key:将返回结果的地理位置信息保存到指定键。
- storedist key:将返回结果离中心节点的距离保存到指定键。
georadius key longitude latitude radiusm |km |ft |mi [withcoord] [withdist] [withhash] [COUNT count] [asc |desc] [store key] [storedist key]
georadiusbymember key member radiusm |km |ft |mi [withcoord] [withdist]
[withhash] [COUNT count] [asc |desc] [store key] [storedist key]
# 计算五座城市中,距离北京150公里以内的城市
127.0.0.1:6379> georadiusbymember cities:locations beijing 150 km
1) "beijing"
2) "tianjin"
3) "tangshan"
4) "baoding"
5、获取 geohash
- Redis 使用 geohash 将二维经纬度转换为一维字符串.
- geohash 有如下特点:
- GEO 的数据类型为 zset,Redis 将所有地理位置信息的 geohash 存放在 zset 中。
- 字符串越长,表示的位置更精确。下表给出了字符串长度对应的精度,例如 geohash 长度为 9 时,精度在 2 米左右。
- 两个字符串越相似,它们之间的距离越近,Redis 利用字符串前缀匹配算法实现相关的命令。
- geohash 编码和经纬度是可以相互转换的。、
- Redis 正是使用有序集合并结合 geohash 的特性实现了 GEO 的若干命令。
geohash key member [member . . .]
127.0.0.1:6379> geohash cities:locations beijing
1) "wx4ww02w070"
127.0.0.1:6379> type cities:locations
zset
geohash 长度与精度对应关系表
| geohash 长度 | 精确度 (km) |
|---|---|
| 1 | 2500 |
| 2 | 630 |
| 3 | 78 |
| 4 | 20 |
| 5 | 2.4 |
| 6 | 0.61 |
| 7 | 0.076 |
| 8 | 0.019 |
| 9 | 0.002 |
6、删除地理位置信息
GEO 没有提供删除成员的命令,但是因为 GEO 的底层实现是 zset,所以可以借用 zrem 命令实现对地理位置信息的删除。
zrem key member
四、客户端
1、客户端通信协议
- 客户端与服务端之间的通信协议是在 TCP 协议之上构建的。
- Redis 制定了 RESP(REdis Serialization Protocol,Redis 序列化协议)实现客户端与服务端的正常交互,这种协议简单高效,既能够被机器解析,又容易被人类识别。
// 客户端发送一条set hello world命令给服务端,按照RESP的标准,客户端需要将其封装为如下格式(每行用\r\n分隔) :
*3
$3
SET
$5
hello
$5
world
实际传输格式为如下代码:
*3\r\n$3\r\nSET\r\n$5\r\nhello\r\n$5\r\nworld\r\n
// 这样Redis服务端能够按照RESP将其解析为set hello world命令,执行后回复的格式如下:
+OK
下面对命令的一些格式进行说明:
1、发送命令格式
RESP的规定一条命令的格式如下,CRLF代表"\r\n"。
*<参数数量> CRLF
$<参数1的字节数量> CRLF
<参数1> CRLF
. . .
$<参数N的字节数量> CRLF
<参数N> CRLF
2、返回结果格式
Redis的返回结果类型分为以下五种:
· 状态回复: 在RESP中第一个字节为"+"。例如set。
· 错误回复: 在RESP中第一个字节为"-"。例如错误命令。
· 整数回复: 在RESP中第一个字节为":"。例如incr。
· 字符串回复: 在RESP中第一个字节为"$"。例如get。
· 多条字符串回复: 在RESP中第一个字节为"*"。例如mget。
redis-cli.c源码对命令结果的解析结构如下:
static sds cliFormatReplyTTY (redisReply *r, char *prefix) {
sds out = sdsempty ();
switch (r->type) {
case REDIS_REPLY_ERROR :
// 处理错误回复
case REDIS REPLY STATUS :
// 处理状态回复
case REDIS_REPLY_INTEGER :
// 处理整数回复
case REDIS_REPLY_STRING :
// 处理字符串回复
case REDIS_REPLY_NIL :
// 处理空
case REDIS_REPLY_ARRAY :
// 处理多条字符串回复
return out;
}
为了看到 Redis 服务端返回的 “真正” 结果,可以使用 nc 命令、telnet 命令、甚至写一个 socket 程序进行模拟。
以nc命令进行演示,首先使用 nc 127.0.0.1 6379连接到Redis:
nc 127.0.0.1 6379
状态回复:set hello world的返回结果为+OK:
set hello world
+OK
错误回复:由于sethx这条命令不存在,那么返回结果就是"-"号加上错误消息:
sethx
-ERR unknown command 'sethx '
整数回复:当命令的执行结果是整数时,返回结果就是整数回复:
incr counter
:1
字符串回复:当命令的执行结果是字符串时,返回结果就是字符串回复:
get hello
$5
world
多条字符串回复: 当命令的执行结果是多条字符串时,返回结果就是多条字符串回复:
mset java jedis python redis-py
+OK
mget java python
*2
$5
jedis
$8
redis-py
注意,无论是字符串回复还是多条字符串回复,如果有nil值,那么会返回$- 1。
get not_exist_key
$-1
如果批量操作中包含一条为nil值的结果,那么返回结果如下:
mget hello not_exist_key java
*3
$5
world
$-1
$5
jedis
有了 RESP 提供的发送命令和返回结果的协议格式,各种编程语言就可以利用其来实现相应的 Redis 客户端。
2、SpringBoot 整合 Redis
Spring Boot Data(数据) Redis 中提供了 RedisTemplate 和 StringRedisTemplate,其中 StringRedisTemplate 是 RedisTemplate 的子类,两个方法基本一致,不同之处主要体现在操作的数据类型不同,RedisTemplate 中的两个泛型都是 Object,意味着存储的 key 和 value 都可以是一个对象,而 StringRedisTemplate 的两个泛型都是 String,意味着 StringRedisTemplate 的 key 和 value 都只能是字符串。
1)环境准备
引入依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
配置 applicaiton.properties
spring.redis.host=localhost
spring.redis.port=6379
spring.redis.database=0
2)使用 Template
5 种数据结构的操作
(String)redisTemplate.opsForValue(); //操做字符串
(String)redisTemplate.opsForHash(); //操做hash
(String)redisTemplate.opsForList(); //操做list
(String)redisTemplate.opsForSet(); //操做set
(String)redisTemplate.opsForZSet(); //操做有序set
@Autowired
private StringRedisTemplate stringRedisTemplate; //对字符串支持比较友好,不能存储对象
@Autowired
private RedisTemplate redisTemplate; //存储对象
//key相关的操作
@Test
public void test(){
Set<String> keys = stringRedisTemplate.keys("*"); //查看所有key
Boolean name = stringRedisTemplate.hasKey("name"); //判断某个key是否存在
stringRedisTemplate.delete("age"); //根据指定key删除
stringRedisTemplate.rename("",""); //修改key的名称
stringRedisTemplate.expire("key",10, TimeUnit.HOURS);
//设置key超时时间 参数1:设置key名 参数2:时间 参数3:时间的单位
stringRedisTemplate.move("",1);//移动key
}
//String相关的操作 opsForValue
@Test
public void testString(){
stringRedisTemplate.opsForValue().set("name","小陈");
String s = stringRedisTemplate.opsForValue().get("name");
System.out.println(s);
stringRedisTemplate.opsForValue().set("code","235952", 60, TimeUnit.SECOUNDS);
stringRedisTemplate.opsForValue().append("name", "他是个好人");
Long size = stringRedisTemplate.opsForValue().size("name");
System.out.println(size);
}
//list相关的操作opsForList
@Test
public void testList(){
stringRedisTemplate.opsForList().leftPush("lists","张三");
stringRedisTemplate.opsForList().leftPushAll("lists","小陈","李四","王五");
List<String> lists = new ArrayList<>();
lists.add("小1");
lists.add("小2");
stringRedisTemplate.opsForList().leftPushAll("lists", lists);
List<String> lists = stringRedisTemplate.opsForList().range("lists", 0, -1);
lists.forEach(key -> System.out.println(key));
}
//set相关操作 opsForSet
@Test
public void testSet(){
stringRedisTemplate.opsForSet().add("sets","xiaosan","xiaosi","xiaowu");
Set<String> sets = stringRedisTemplate.opsForSet().members("sets");
sets.forEach(value-> System.out.println(value));
Long size = stringRedisTemplate.opsForSet().size("sets");
System.out.println("size="+size);
}
//zset相关操作 opsForZSet
@Test
public void testZSet(){
stringRedisTemplate.opsForZSet().add("zsets","小黑",10);
Set<String> zsets = stringRedisTemplate.opsForZSet().range("zsets", 0, -1);
zsets.forEach(value-> System.out.println(value));
Set<ZSetOperations.TypedTyple<String>> zsets1 = stringRedisTemplate.opsForZSet().rangeByScoreWithScores("zsets", 0, 1000); //获取指定元素以及分数
zsets1.forEach(typeTuple ->{
System.out.println(typedTuple.getValue());
System.out.println(typedTuple.getScore());
})
}
//hash相关操作 opsForHash
@Test
public void testHash(){
stringRedisTemplate.opsForHash().put("maps","name","小黑");
Object o = stringRedisTemplate.opsForHash().get("maps", "name");
System.out.println(o);
Map<String, String> map = new HashMap<String, String>();
map.put("age", "12");
map.put("bir", "2012-12-12");
stringRedisTemplate.opsForHash().putAll("maps", map);
List<Object> values = stringRedisTemplate.opsForHash().multiGet("maps", Arrays.asList("name", "age"));
values.forEach(value -> System.out.println(value));
String value = (String) stringRedisTemplate.opsForHash().get("maps", "name");
List<Object> vals = stringRedisTemplate.opsForHash().values("maps");
Set<Object> keys = stringRedisTemplate.opsForHash().keys("maps");
}
@Test
public void testRedisTemplate(){
// 修改key序列化方案
redisTemplate.setKeySerializer(new StringRedisSerializer());
// 修改hash key序列化方案
redisTemplate.setHashKeySerializer(new StringRedisSerializer());
User user = new User();
user.setId(UUID.randomUUID().toString().setName("xiaochen").setAge(23).setBir(new Date()));
redisTemplate.opsForValue().set("user",user);
User user1 = (User)redisTemplate.opsForValue().get("user");
System.out.println(user1);
redisTemplate.opsForList().leftPush("list", user);
redisTemplate.opsForSet().leftPush("set", user);
redisTemplate.opsForZSet().leftPush("zset", user, 10);
}
public class TestBoudAPI {
@Autowired
private RedisTemplate redisTemplate;
@Autowired
private StringRedisTemplate stringRedisTemplate;
public void testBound() {
redisTemplate.setKeySerializer(new StringRedisSerializer());
redisTemplate.setHashKeySerializer(new StringRedisSerializer());
// 对字符串类型key进行绑定,后续所有操作都是基于这个key进行的
BoundValueOperations<String, String> nameValueOperations = redisTemplate.boundValueOps(
"name"
);
nameValueOperations.set("zhagnsan");
nameValueOperations.append("是一个好人");
String name = nameValueOperations.get();
System.out.println(name);
// 对list set Zset hash等
BoundListOperations<String, String> listOperations = stringRedisTemplate.boundListOps(
"lists"
);
listOperations.leftPushAll("嗓散", "saw ", "we fww e");
List<String> lists = listOperations.range(0, -1);
lists.forEach(
list -> {
System.out.println(list);
}
);
}
}
3)小结
- 针对于日后处理 key value 都是 string 使用 stringRedisTemplate
- 针对于日后处理的 key value 存在对象,使用 RedisTemplate
- 针对于同一个 key 多次操作可以使用 boundxxxOps() Value List Set ZSet Hash 的 api
3、Python 客户端 redis-py
1)获取 redis-py。
redis-py 需要 Python2.7 以上版本。
如何获取安装 redis-py,方法有三种:
# 第一,使用pip进行安装:
pip install redis
# 第二,使用easy_install进行安装:
easy_install redis
# 第三,使用源码安装:
wget https://github.com/andymccurdy/redis-py/archive/2.10.5.zip
unzip redis-2.10.5.zip
cd redis-2.10.5
# 安装redis-py
python setup.py install
2)redis-py 的基本使用方法。
①导入依赖库:
import redis
②生成客户端连接:需要Redis的实例IP和端口两个参数:
client = redis.StrictRedis (host='127.0.0.1', port=6379)
③执行命令:redis-py的API保留了Redis API的原始风格:
# True
client.set (key, "python-redis")
# world
client.get (key)
import redis
client = redis.StrictRedis (host='127.0.0.1', port=6379)
key = "hello"
setResult = client.set (key, "python-redis")
print setResult
value = client.get (key)
print "key :" + key + ", value :" + value
3)redis-py 的 Pipeline 的使用。
①引入依赖,生成客户端连接:
import redis
client = redis.StrictRedis (host='127.0.0.1 ', port=6379)
②生成Pipeline:注意client.pipeline包含了一个参数,如果transaction=False代表不使用事务:
pipeline = client.pipeline (transaction=False)
③将命令封装到Pipeline中,此时命令并没有真正执行:
pipeline.set ("hello","world")
pipeline.incr ("counter")
④执行Pipeline:
# [True, 3]
result = pipeline.execute ()
4)redis-py 的 Lua 脚本使用。
redis-py 提供了三个重要的函数实现 Lua 脚本的执行:
eval (String script, int keyCount, String . . . params)
script_load (String script)
evalsha (String sha1, int keyCount, String . . . params)
import redis
client = redis.StrictRedis (host='127.0.0.1', port=6379)
script = "return redis.call ('get', KEYS [1])"
#输出结果为world
print client.eval (script,1,"hello")
script_load和evalsha 函数要一起使用,首先使用script_load将脚本加载到Redis中:
import redis
client = redis.StrictRedis (host='127.0.0.1', port=6379)
script = "return redis.call ('get ',KEYS [1])"
scriptSha = client.script_load (script)
print client.evalsha (scriptSha, 1, "hello");
- eval 函数有三个参数,分别是:
- script:Lua 脚本内容。
- keyCount:键的个数。
- params:相关参数 KEYS 和 ARGV。
- evalsha 函数用来执行脚本的哈希值,它需要三个参数:
- scriptSha:脚本的 SHA1。
- keyCount:键的个数。
- params:相关参数 KEYS 和 ARGV。
4、客户端 API
1)client list 命令能列出与 Redis 服务端相连的所有客户端连接信息。
// 在一个Redis实例上执行client list的结果:
127.0.0.1:6379> client list
id=254487 addr=10.2.xx.234:60240 fd=1311 name= age=8888581 idle=8888581 flags=N
db=0 sub=0 psub=0 multi=-1 qbuf=0 qbuf-free=0 obl=0 oll=0 omem=0 events=r cm
id=300210 addr=10.2.xx.215:61972 fd=3342 name= age=8054103 idle=8054103 flags=N
sub=0 psub=0 multi=-1 qbuf=0 qbuf-free=0 obl=0 oll=0 omem=0 events=r cm
...
127.0.0.1:6390> info memory
...
maxmemory_human:4.00G.
...
127.0.0.1:6390> info clients
···
connected clients:1414 // 当前Redis的连接数
client_longest_output_list:4869 // client_longest_output_list代表输出缓冲区列表最大对象数
client_biggest_input_buf:2097152
···
输出缓冲区对应的配置规则是:
client-output-buffer-limit <class> <hard limit> <soft limit> <soft seconds>
<class>:客户端类型,分为三种。a)normal:普通客户端;b)slave:slave客户端,用于复制;c)pubsub:发布订阅客户端。
<hard limit>:如果客户端使用的输出缓冲区大于<hard limit>,客户端会被立即关闭。
<soft limit>和<soft seconds>:如果客户端使用的输出缓冲区超过了<soft limit>并且持续了<soft limit>秒,客户端会被立即关闭。
Redis的默认配置是:
client-output-buffer-limit normal 0 0 0
client-output-buffer-limit slave 256mb 64mb 60
client-output-buffer-limit pubsub 32mb 8mb 60
通过过Redis源码中redis.h的redisClient结构体(Redis3.2版本变为Client)可以看到固定缓冲区和动态缓冲区的实现细节:
typedef struct redisClient {
// 动态缓冲区列表
list *reply;
// 动态缓冲区列表的长度 (对象个数)
unsigned long reply_bytes;
// 固定缓冲区已经使用的字节数
int bufpos;
// 字节数组作为固定缓冲区
char buf [REDIS_REPLY_CHUNK_BYTES];
} redisClient;
可以通过config set maxclients对最大客户端连接数进行动态设置:
127.0.0.1:6379> config get maxclients
1) "maxclients"
2) "10000"
127.0.0.1:6379> config set maxclients 50
OK
127.0.0.1:6379> config get maxclients
1) "maxclients"
2) "50"
#Redis默认的timeout是0,也就是不会检测客户端的空闲
127.0.0.1:6379> config set timeout 30
OK
- client list 输出结果的每一行代表一个客户端的信息,可以看到每行包含了十几个属性,它们是每个客户端的一些执行状态:
- 标识:id、addr、fd、name,这四个属性属于客户端的标识:
- id:客户端连接的唯一标识,这个 id 是随着 Redis 的连接自增的,重启 Redis 后会重置为 0。
- addr:客户端连接的 ip 和端口。
- fd:socket 的文件描述符,与 lsof 命令结果中的 fd 是同一个,如果 fd=-1 代表当前客户端不是外部客户端,而是 Redis 内部的伪装客户端。
- name:客户端的名字。
- 输入缓冲区:qbuf、qbuf-free
- Redis 为每个客户端分配了输入缓冲区,它的作用是将客户端发送的命令临时保存,同时 Redis 从会输入缓冲区拉取命令并执行,输入缓冲区为客户端发送命令到 Redis 执行命令提供了缓冲功能。client list 中 qbuf 和 qbuf-free 分别代表这个缓冲区的总容量和剩余容量。
- Redis 没有提供相应的配置来规定每个缓冲区的大小,输入缓冲区会根据输入内容大小的不同动态调整,只是要求每个客户端缓冲区的大小不能超过 1G,超过后客户端将被关闭。
- 输出缓冲区:obl、oll、omem
- Redis 为每个客户端分配了输出缓冲区,它的作用是保存命令执行的结果返回给客户端,为 Redis 和客户端交互返回结果提供缓冲。与输入缓冲区不同的是,输出缓冲区的容量可以通过参数 client-output-buffer-limit 来进行设置,并且输出缓冲区做得更加细致,按照客户端的不同分为三种:普通客户端、发布订阅客户端、slave 客户端。
- obl 代表固定缓冲区的长度,oll 代表动态缓冲区列表的长度,omem 代表使用的字节数。
- 客户端的存活状态:age 和 idle 分别代表当前客户端已经连接的时间和最近一次的空闲时间。当 age 等于 idle 时,说明连接一直处于空闲状态。
- 客户端的限制 maxclients 和 timeout
- Redis 提供了 maxclients 参数来限制最大客户端连接数,一旦连接数超过 maxclients,新的连接将被拒绝。maxclients 默认值是 10000,可以通过 info clients 来查询当前 Redis 的连接数。
- Redis 提供了 timeout(单位为秒)参数来限制连接的最大空闲时间,一旦客户端连接的 idle 时间超过了 timeout,连接将会被关闭。在实际开发和运维中,需要将 timeout 设置成大于 0,例如可以设置为 300 秒,同时在客户端使用上添加空闲检测和验证等等措施。
- flag 是用于标识当前客户端的类型,例如 flag=S 代表当前客户端是 slave 客户端、flag=N 代表当前是普通客户端,flag=O 代表当前客户端正在执行 monitor 命令。
- 其他参数
- db:当前客户端正在使用的数据库索引下标
- sub/psub:当前客户端订阅的频道或者模式数
- multi:当前事务中已执行命令个数
- events:文件描述符事作件 (r/w):r 和 w 分别代表客户端套接字可读和可写
- 标识:id、addr、fd、name,这四个属性属于客户端的标识:
- 输入缓冲使用不当会产生两个问题:
- 一旦某个客户端的输入缓冲区超过 1G,客户端将会被关闭。
- 输入缓冲区不受 maxmemory 控制,假设一个 Redis 实例设置了 maxmemory 为 4G,已经存储了 2G 数据,但是如果此时输入缓冲区使用了 3G,已经超过 maxmemory 限制,可能会产生数据丢失、键值淘汰、OOM 等情况。
- 输入缓冲区过大主要是因为 Redis 的处理速度跟不上输入缓冲区的输入速度,并且每次进入输入缓冲区的命令包含了大量 bigkey,从而造成了输入缓冲区过大的情况。还有一种情况就是 Redis 发生了阻塞,短期内不能处理命令,造成客户端输入的命令积压在了输入缓冲区,造成了输入缓冲区过大。
- 监控输入缓冲区异常的方法有两种:
- 通过定期执行 client list 命令,收集 qbuf 和 qbuf-free 找到异常的连接记录并分析,最终找到可能出问题的客户端。
- 通过 info 命令的 info clients 模块,找到最大的输入缓冲区。例如可以设置超过 10M 就进行报警。
- 和输入缓冲区相同的是,输出缓冲区也不会受到 maxmemory 的限制,如果使用不当同样会造成 maxmemory 用满产生的数据丢失、键值淘汰、OOM 等情况。
- 实际上输出缓冲区由两部分组成:固定缓冲区 (16KB) 和动态缓冲区,其中固定缓冲区返回比较小的执行结果,而动态缓冲区返回比较大的结果。
- 固定缓冲区使用的是字节数组,动态缓冲区使用的是列表。当固定缓冲区存满后会将 Redis 新的返回结果存放在动态缓冲区的队列中,队列中的每个对象就是每个返回结果。
- 监控输出缓冲区的方法依然有两种:
- 通过定期执行 client list 命令,收集 obl、oll、omem 找到异常的连接记录并分析,最终找到可能出问题的客户端。
- 通过 info 命令的 info clients 模块,找到输出缓冲区列表最大对象数。
- 输出缓冲区出现异常的方法:
- 进行上述监控,设置阀值,超过阀值及时处理。
- 限制普通客户端输出缓冲区的,把错误扼杀在摇篮中。例如设置 client-output-buffer-limit normal 20mb 10mb 120。
- 适当增大 slave 的输出缓冲区的,如果 master 节点写入较大,slave 客户端的输出缓冲区可能会比较大,一旦 slave 客户端连接因为输出缓冲区溢出被 kill ,会造成复制重连。
- 限制容易让输出缓冲区增大的命令,例如,高并发下的 monitor 命令就是一个危险的命令。
- 及时监控内存,一旦发现内存抖动频繁,可能就是输出缓冲区过大。
下表对比 client list 和 info clients 监控输入缓冲区的优劣势
| 命令 | 优点 | 缺点 |
|---|---|---|
| client list | 能精准分析每个客户端来定位问题 | 执行速度较慢 (尤其是连接数较多的情况下),频繁执行存在阻塞 Redis 的可能 |
| info clients | 执行速度比 client list 快,分析过程较为简单 | 不能精准定位到客户端;不能显示所有输入缓冲区的总量,只能显示最大量 |
客户端类型表
| 序号 | 客户端类 | 说明 |
|---|---|---|
| 1 | N | 普通客户端 |
| 2 | M | 当前客户端是 master 节点 |
| 3 | S | 当前客户端是 slave 节点 |
| 4 | O | 当前客户端正在执行 monitor 命令 |
| 5 | x | 当前客户端正在执行事务 |
| 6 | b | 当前客户端正在等待阻塞时间 |
| 7 | i | 当前客户端正在等待 VM I/O,但是此状态目前已经废弃不用 |
| 8 | d | 一个受监视的键已被修改,EXEC 命令将失败 |
| 9 | u | 客户端未被阻塞 |
| 10 | c | 回复完成输出后,关闭连接 |
| 11 | A | 尽可能快地关闭连接 |
2)client setName 和 client getName
client setName xx
client getName
- client setName 用于给客户端设置名字,这样比较容易标识出客户端的来源.
3)client kill
client kill ip:port
- client kill 命令用于杀掉指定 IP 地址和端口的客户端。
4)client pause
client pause timeout (毫秒)
- client pause 命令用于阻塞客户端 timeout 毫秒数,在此期间客户端连接将被阻塞。
- 该命令可以在如下场景起到作用:
- client pause 只对普通和发布订阅客户端有效,对于主从复制 (从节点内部伪装了一个客户端) 是无效的,也就是此期间主从复制是正常进行的,所以此命令可以用来让主从复制保持一致。
- client pause 可以用一种可控的方式将客户端连接从一个 Redis 节点切换到另一个 Redis 节点。
5)monitor
127.0.0.1:6379> monitor
OK
···
- monitor 命令用于监控 Redis 正在执行的命令。
- monitor 能监听到所有的命令,一旦 Redis 的并发量过大,monitor 客户端的输出缓冲会暴涨,可能瞬间会占用大量内存。
5、客户端相关配置
除了上面介绍的部分配置外,还有下面这些配置:
- imeout:检测客户端空闲连接的超时时间,一旦 idle 时间达到了 timeout,客户端将会被关闭,如果设置为 0 就不进行检测。
- maxclients:客户端最大连接数。但是这个参数会受到操作系统设置的限制。
- tcp-keepalive:检测 TCP 连接活性的周期,默认值为 0,也就是不进行检测,如果需要设置,建议为 60,那么 Redis 会每隔 60 秒对它创建的 TCP 连接进行活性检测,防止大量死连接占用系统资源。
- tcp-backlog:TCP 三次握手后,会将接受的连接放入队列中,tcp-backlog 就是队列的大小,它在 Redis 中的默认值是 511。通常来讲这个参数不需要调整,但是这个参数会受到操作系统的影响。例如在 Linux 操作系统中,如果 / proc/sys/net/core/somaxconn 小于 tcp-backlog,那么在 Redis 启动时会看到日志打印建议将 / proc/sys/net/core/somaxconn 设置更大。
6、客户端统计片段
127.0.0.1:6379> info clients
# Clients
connected_clients :1414
client_longest_output_list :0
client_biggest_input_buf :2097152
blocked clients :0
- connected_clients:代表当前 Redis 节点的客户端连接数,需要重点监控,一旦超过 maxclients,新的客户端连接将被拒绝。
- client_longest_output_list:当前所有输出缓冲区中队列对象个数的最大值。
- client_biggest_input_buf:当前所有输入缓冲区中占用的最大容量。
- blocked_clients:正在执行阻塞命令(例如 blpop、brpop、 brpoplpush)的客户端个数。
127.0.0.1:6379> info stats
# Stats
total_connections_received: 80
. . .
rejected_connections: 0
- total_connections_received:Redis 自启动以来处理的客户端连接数总数。
- rejected_connections:Redis 自启动以来拒绝的客户端连接数,需要重点监控。
7、Jedis 客户端常见异常
1)无法从连接池获取到连接
2)客户端读写超时
3)客户端连接超时
4)客户端缓冲区异常
5)Lua 脚本正在执行
6)Redis 正在加载持久化文件
7)Redis 使用的内存超过 maxmemory 配置
8)客户端连接数过大
7、客户端案例分析 - Redis 内存陡增
1)现象
- 服务端现象:Redis 主节点内存陡增,几乎用满 maxmemory,而从节点内存并没有变化.
- 客户端现象:客户端产生了 OOM 异常,也就是 Redis 主节点使用的内存 已经超过了 maxmemory 的设置,无法写入新的数据.
2)分析原因
①确实有大量写入,但是主从复制出现问题:查询了Redis复制的相关信息,复制是正常的,主从数据基本一致。
127.0.0.1:6379> dbsize // 主节点的键个数
(integer) 2126870
127.0.0.1:6380> dbsize // 从节点的键个数
(integer) 2126870
②其他原因造成主节点内存使用过大:排查是否由客户端缓冲区造成主节点内存陡增,使用info clients命令查询相关信息如下:
127.0.0.1:6379> info clients
# Clients
connected_clients :1891
client_longest_output_list :225698 // 输出缓冲区不太正常,最大的客户端输出缓冲区队列已经超过了20万个对象
client_biggest_input_buf :0
blocked clients :0
通过client list命令找到omem不正常的连接,一般来说大部分客户端的omem为0(因为处理速度会足够快)
redis-cli client list | grep -v "omem=0"
3)处理方法和后期处理
- 处理方法:只要使用 client kill 命令杀掉这个连接,让其他客户端恢复正常写数据即可。
- 后期处理:
- 从运维层面禁止 monitor 命令,例如使用 rename-command 命令重置 monitor 命令为一个随机字符串,除此之外,如果 monitor 没有做 rename-command ,也可以对 monitor 命令进行相应的监控(例如 client list)。
- 从开发层面进行培训,禁止在生产环境中使用 monitor 命令,因为有时候 monitor 命令在测试的时候还是比较有用的,完全禁止也不太现实。
- 限制输出缓冲区的大小。
- 使用专业的 Redis 运维工具 (例如 Cachecloud),收到相应的报警从而快速发现和定位问题。
8、客户端案例分析 - 客户端周期性的超时
1)现象
①客户端现象:客户端出现大量超时,经过分析发现超时是周期性出现的。
②服务端现象:服务端并没有明显的异常,只是有一些慢查询操作。
2)分析
- 网络原因:服务端和客户端之间的网络出现周期性问题,经过观察网络是正常的。
- Redis 本身:经过观察 Redis 日志统计,并没有发现异常。
- 客户端:由于是周期性出现问题,就和慢查询日志的历史记录对应了一下时间,发现只要慢查询出现,客户端就会产生大量连接超时,两个时间点基本一致。
3)处理方法和后期处理
- 处理方法:调整慢查询的原因。
- 后期处理:
- 从运维层面,监控慢查询,一旦超过阀值,就发出报警。
- 从开发层面,加强对于 Redis 的理解,避免不正确的使用方式。
- 使用专业的 Redis 运维工具。
五、持久化
1、持久化概述
Redis 支持 RDB 和 AOF 两种持久化机制,持久化功能有效地避免因进程退出造成的数据丢失问题,当下次重启时利用之前持久化的文件即可实现数据恢复。
- RDB 持久化是把当前进程数据生成快照保存到硬盘的过程,触发 RDB 持久化过程分为手动触发和自动触发。
- AOF(append only file) 持久化:以独立日志的方式记录每次写命令,重启时再重新执行 AOF 文件中的命令达到恢复数据的目的。AOF 的主要作用是解决了数据持久化的实时性,目前已经是 Redis 持久化的主流方式。
2、RDB
1)RDB 触发机制
手动触发分别对应 save 和 bgsave 命令:
- save 命令:阻塞当前 Redis 服务器,直到 RDB 过程完成为止,对于内存比较大的实例会造成长时间阻塞,线上环境不建议使用。
- bgsave 命令:Redis 进程执行 fork 操作创建子进程,RDB 持久化过程由子进程负责,完成后自动结束。阻塞只发生在 fork 阶段,一般时间很短。
- Redis 内部所有的涉及 RDB 的操作都采用 bgsave 的方式,而 save 命令已经废弃。
- 除了执行命令手动触发之外,Redis 内部还存在自动触发 RDB 的持久化机制,例如以下场景:
- 使用 save 相关配置,如 “save m n”。表示 m 秒内数据集存在 n 次修改时,自动触发 bgsave。
- 如果从节点执行全量复制操作,主节点自动执行 bgsave 生成 RDB 文件并发送给从节点。
- 执行 debug reload 命令重新加载 Redis 时,也会自动触发 save 操作。
- 默认情况下执行 shutdown 命令时,如果没有开启 AOF 持久化功能则自动执行 bgsave。
2)RDB 流程说明

- 执行 bgsave 命令,Redis 父进程判断当前是否存在正在执行的子进程,如 RDB/AOF 子进程,如果存在,bgsave 命令直接返回。
- 父进程执行 fork 操作创建子进程,fork 操作过程中父进程会阻塞,通过 info stats 命令查看 latest_fork_usec 选项,可以获取最近一个 fork 操作的耗时,单位为微秒。
- 父进程 fork 完成后,bgsave 命令返回 “Background saving started” 信息并不再阻塞父进程,可以继续响应其他命令。
- 子进程创建 RDB 文件,根据父进程内存生成临时快照文件,完成后对原有文件进行原子替换。执行 lastsave 命令可以获取最后一次生成 RDB 的时间,对应 info 统计的 rdb_last_save_time 选项。
- 进程发送信号给父进程表示完成,父进程更新统计信息,具体见 info Persistence 下的 rdb_* 相关选项。
3)RDB 文件的处理
1)保存
- RDB 文件保存在 dir 配置指定的目录下,文件名通过 dbfilename 配置指定。
- 可以通过执行
config set dir {newDir}和config set dbfilename{newFileName}运行期动态执行,当下次运行时 RDB 文件会保存到 新目录。 - 当遇到坏盘或磁盘写满等情况时,可以通过 config set dir {newDir} 在线修改文件路径到可用的磁盘路径,之后执行 bgsave 进行磁盘切换,同样适用于 AOF 持久化文件。
2)压缩
- Redis 默认采用 LZF 算法对生成的 RDB 文件做压缩处理,压缩后的文件远远小于内存大小,默认开启,可以通过参数 config set rdbcompression{yes|no} 动态修改。
- 虽然压缩 RDB 会消耗 CPU,但可大幅降低文件的体积,方便保存到硬盘或通过网络发送给从节点,因此线上建议开启。
3)校验
如果 Redis 加载损坏的 RDB 文件时拒绝启动,并打印日志如下:
# Short read or OOM loading DB. Unrecoverable error, aborting now.
这时可以使用 Redis 提供的 redis-check-dump 工具检测 RDB 文件并获取对应的错误报告。
4)RDB 的优缺点
1)RDB 的优点
- RDB 是一个紧凑压缩的二进制文件,代表 Redis 在某个时间点上的数据快照。非常适用于备份,全量复制等场景。
- Redis 加载 RDB 恢复数据远远快于 AOF 的方式。
2)RDB 的缺点
- RDB 方式数据没办法做到实时持久化 / 秒级持久化。因为 bgsave 每次运行都要执行 fork 操作创建子进程,属于重量级操作,频繁执行成本过高。
- RDB 文件使用特定二进制格式保存,Redis 版本演进过程中有多个格式的 RDB 版本,存在老版本 Redis 服务无法兼容新版 RDB 格式的问题。
RDB 使用一次性生成内存快照的方式,产生的文件紧凑压缩比更高,因此读取 RDB 恢复速度更快。由于每次生成 RDB 开销较大,无法做到实时持久化,一般用于数据冷备和复制传输。
3、AOF
1)使用 AOF
- 开启 AOF 功能需要设置配置:
appendonly yes,默认不开启。 - AOF 文件名通过 appendfilename 配置设置,默认文件名是 appendonly.aof。
- 保存路径同 RDB 持久化方式一致,通过 dir 配置指定。
- AOF 的工作流程操作:命令写入(append)、文件同步(sync)、文件重写(rewrite)、重启加载(load).
- 所有的写入命令会追加到 aof_buf(缓冲区)中。
- AOF 缓冲区根据对应的策略向硬盘做同步操作。
- 随着 AOF 文件越来越大,需要定期对 AOF 文件进行重写,达到压缩的目的。
- 当 Redis 服务器重启时,可以加载 AOF 文件进行数据恢复。

2)AOF 的命令写入
- AOF 命令写入的内容直接是文本协议格式。原因是:
- 文本协议具有很好的兼容性。
- 开启 AOF 后,所有写入命令都包含追加操作,直接采用协议格式,避免了二次处理开销。
- 文本协议具有可读性,方便直接修改和处理。
- AOF 为什么把命令追加到 aof_buf 中?Redis 使用单线程响应命令,如果每次写 AOF 文件命令都直接追加到硬盘,那么性能完全取决于当前硬盘负载。先写入缓冲区 aof_buf 中,还有另一个好处,Redis 可以提供多种缓冲区同步硬盘的策略,在性能和安全性方面做出平衡。
3)AOF 的文件同步
Redis 提供了多种 AOF 缓冲区同步文件策略,由参数 appendfsync 控制,不同值的含义如下表 (AOF 缓冲区同步文件策略):
| 可配置值 | 说明 |
|---|---|
| always | 命令写入 aof_buf 后调用 fsync 操作同步到 AOF 文件,fsync 完成后线程返回。每个 redis 写命令都要同步写入硬盘,严重降低 redis 速度【谨慎使用】 |
| everysec | 命令写入 aof_buf 后调用系统 write 操作,write 完成后线程返回。fsync 同步文件操作由专门线程每秒调用一次。每秒执行一次同步显式的将多个写命令同步到磁盘【推荐】 |
| no | 命令写入 aof_buf 后调用 write 操作,不对 AOF 文件做 fsync 同步,同步硬盘操作由操作系统负责,通常同步周期最长 30 秒。【不推荐】 |
系统调用 write 和 fsync 说明:
- write 操作会触发延迟写(delayed write)机制。Linux 在内核提供页缓冲区用来提高硬盘 IO 性能。write 操作在写入系统缓冲区后直接返回。同步硬盘操作依赖于系统调度机制,例如:缓冲区页空间写满或达到特定时间周期。同步文件之前,如果此时系统故障宕机,缓冲区内数据将丢失。
- fsync 针对单个文件操作(比如 AOF 文件),做强制硬盘同步,fsync 将阻塞直到写入硬盘完成后返回,保证了数据持久化。
- 配置为 always 时,每次写入都要同步 AOF 文件,在一般的 SATA 硬盘上,Redis 只能支持大约几百 TPS 写入,显然跟 Redis 高性能特性背道而驰,不建议配置。
- 配置为 no,由于操作系统每次同步 AOF 文件的周期不可控,而且会加大每次同步硬盘的数据量,虽然提升了性能,但数据安全性无法保证。
- 配置为 everysec,是建议的同步策略,也是默认配置,做到兼顾性能和数据安全性。理论上只有在系统突然宕机的情况下丢失 1 秒的数据。
4)AOF 的重写机制
AOF 带来的问题
AOF 的方式也同时带来了另一个问题。持久化文件会变的越来越大。例如我们调用 incr test 命令 100 次,文件中必须保存全部的 100 条命令,其实有 99 条都是多余的。因为要恢复数据库的状态其实文件中保存一条 set test 100 就够了。为了压缩 aof 的持久化文件 Redis 提供了 AOF 重写 (ReWriter) 机制,用来在一定程度上减小 AOF 文件的体积。
触发重写方式
- 客户端方式触发重写
执行 BGREWRITEAOF 命令,不会阻塞 redis 的服务
- 服务器配置方式自动触发
配置 redis.conf 中的 auto-aof-rewrite-percentage 选项 参加下图 ↓↓↓
如果设置 auto-aof-rewrite-percentage 值为 100 和 auto-aof-rewrite-min-size 64mb,并且启用的 AOF 持久化时,那么当 AOF 文件体积大于 64M,并且 AOF 文件的体积比上一次重写之后体积大了至少一倍(100%)时,会自动触发,如果重写过于频繁,用户可以考虑将 auto-aof-rewrite-percentage 设置为更大。
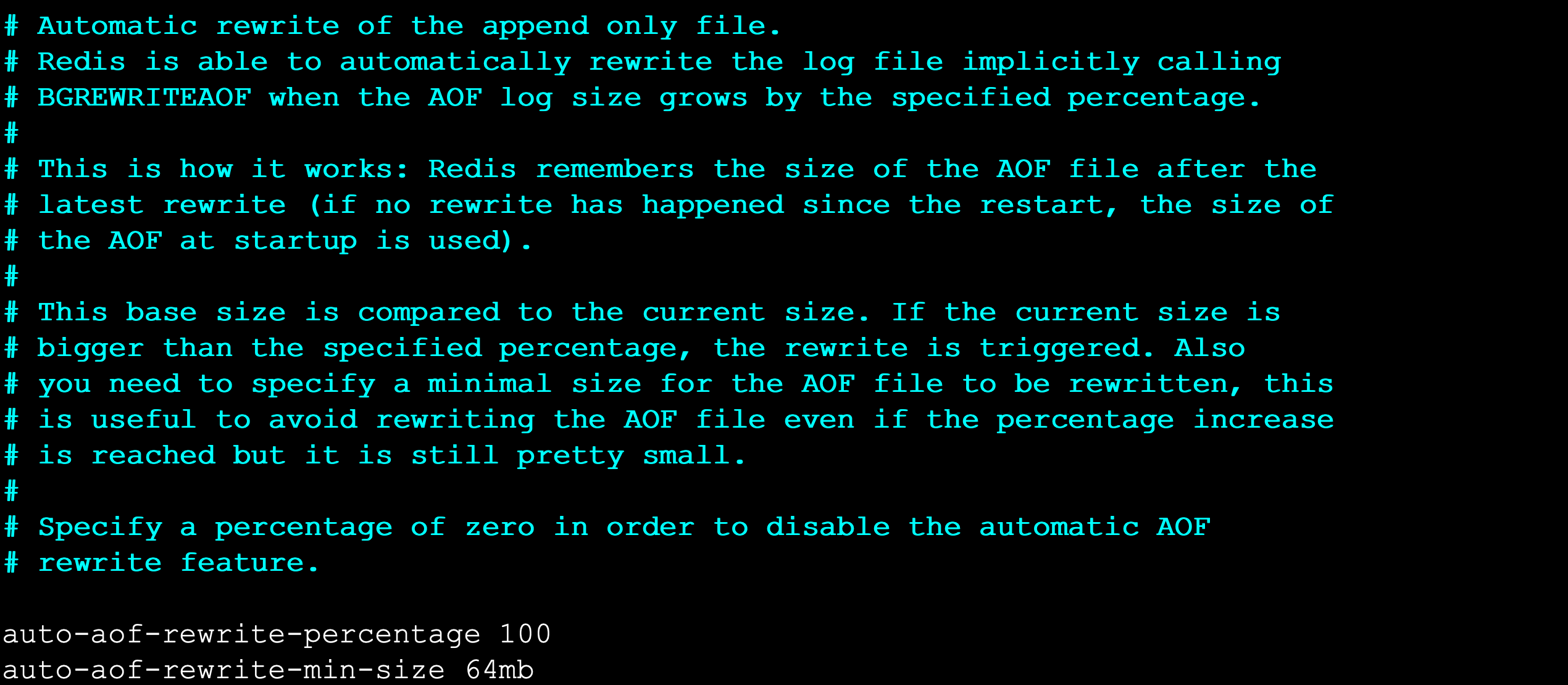
重写原理
注意:重写 aof 文件的操作,并没有读取旧的 aof 文件,而是将整个内存中的数据库内容用命令的方式重写了一个新的 aof 文件,替换原有的文件这点和快照有点类似。
重写流程
- redis 调用 fork ,现在有父子两个进程 子进程根据内存中的数据库快照,往临时文件中写入重建数据库状态的命令
- 父进程继续处理 client 请求,除了把写命令写入到原来的 aof 文件中。同时把收到的写命令缓存起来。这样就能保证如果子进程重写失败的话并不会出问题。
- 当子进程把快照内容写入已命令方式写到临时文件中后,子进程发信号通知父进程。然后父进程把缓存的写命令也写入到临时文件。
- 现在父进程可以使用临时文件替换老的 aof 文件,并重命名,后面收到的写命令也开始往新的 aof 文件中追加。
- 重写后的 AOF 文件为什么可以变小? 有如下原因:
- 进程内已经超时的数据不再写入文件。
- 旧的 AOF 文件含有无效命令,如 del key1 、hdel key2、srem keys、set a 111、set a222 等。重写使用进程内数据直接生成,这样新的 AOF 文件只保留最终数据的写入命令。
- 多条写命令可以合并为一个,如:lpush list a、lpush list b、lpush list c 可以转化为:lpush list a b c。为了防止单条命令过大造成客户端缓冲区溢出,对于 list、set、hash、zset 等类型操作,以 64 个元素为界拆分为多条。
- AOF 重写降低了文件占用空间,除此之外,另一个目的是:更小的 AOF 文件可以更快地被 Redis 加载。
5)AOF 的重启加载
AOF 和 RDB 文件都可以用于服务器重启时的数据恢复。
Redis 持久化文件加载流程如下:
no yes no yes no yes yes no redis 启动 开启 AOF? 存在 RDB? 存在 AOF? 加载 AOF 启动成功 加载 RDB 成功? 加载失败
1)AOF 持久化开启且存在 AOF 文件时,优先加载 AOF 文件。日志打印:
DB loaded from append only file: 5.841 seconds
2)AOF 关闭或者 AOF 文件不存在时,加载 RDB 文件。日志打印:
* DB loaded from disk: 5.586 seconds
3)加载 AOF/RDB 文件成功后,Redis 启动成功。
4)AOF/RDB 文件存在错误时,Redis 启动失败并打印错误信息。
6)AOF 的文件校验
1)加载损坏的 AOF 文件时会拒绝启动,并打印如下日志:
# Bad file format reading the append only file: make a backup of your AOF file, then use ./redis-check-aof --fix <filename>
2)对于错误格式的 AOF 文件,先进行备份,然后采用 redis-check-aof–fix 命令进行修复,修复后使用 diff-u 对比数据的差异,找出丢失的数据,有些可以人工修改补全。
3)AOF 文件可能存在结尾不完整的情况,比如机器突然掉电导致 AOF 尾部文件命令写入不全。Redis 为我们提供了 aof-load-truncated 配置来兼容这种情况,默认开启。加载 AOF 时,当遇到此问题时会忽略并继续启动,同时打印如下警告日志:
# ! ! ! Warning: short read while loading the AOF file ! ! !
# ! ! ! Truncating the AOF at offset 397856725 ! ! !
# AOF loaded anyway because aof-load-truncated is enabled
4、Redis 4.0 混合持久化
Redis 4.0 带来了一个新的持久化选项——混合持久化。将 rdb 文件的内容和增量的 AOF 日志文件存在一起。这里的 AOF 日志不再是全量的日志,而是 自持久化开始到持久化结束 的这段时间发生的增量 AOF 日志,通常这部分 AOF 日志很小:

于是在 Redis 重启的时候,可以先加载 rdb 的内容,然后再重放增量 AOF 日志就可以完全替代之前的 AOF 全量文件重放,重启效率因此大幅得到提升。
5、问题定位与优化 - fork 操作
持久化阻塞主线程场景有:fork 阻塞和 AOF 追加阻塞。fork 阻塞时间跟内存量和系统有关,AOF 追加阻塞说明硬盘资源紧张。
当 Redis 做 RDB 或 AOF 重写时,一个必不可少的操作就是执行 fork 操作创建子进程,对于大多数操作系统来说 fork 是个重量级错误。虽然 fork 创建的子进程不需要拷贝父进程的物理内存空间,但是会复制父进程的空间内存页表。例如对于 10GB 的 Redis 进程,需要复制大约 20MB 的内存页表,因此 fork 操作耗时跟进程总内存量息息相关,如果使用虚拟化技术,特别是 Xen 虚拟机,fork 操作会更耗时。
fork 耗时问题定位:对于高流量的 Redis 实例 OPS 可达 5 万以上,如果 fork 操作耗时在秒级别将拖慢 Redis 几万条命令执行,对线上应用延迟影响非常明显。正常情况下 fork 耗时应该是每 GB 消耗 20 毫秒左右。可以在 info stats 统计中查 latest_fork_usec 指标获取最近一次 fork 操作耗时,单位微秒。
如何改善 fork 操作的耗时:
- 优先使用物理机或者高效支持 fork 操作的虚拟化技术,避免使用 Xen。
- 控制 Redis 实例最大可用内存,fork 耗时跟内存量成正比,线上建议每个 Redis 实例内存控制在 10GB 以内。
- 合理配置 Linux 内存分配策略,避免物理内存不足导致 fork 失败。
- 降低 fork 操作的频率,如适度放宽 AOF 自动触发时机,避免不必要的全量复制等。
6、问题定位与优化 - 子进程开销监控和优化
子进程负责 AOF 或者 RDB 文件的重写,它的运行过程主要涉及 CPU、内存、硬盘三部分的消耗。
1)CPU
- CPU 开销分析。子进程负责把进程内的数据分批写入文件,这个过程属于 CPU 密集操作,通常子进程对单核 CPU 利用率接近 90%.
- CPU 消耗优化。Redis 是 CPU 密集型服务,不要做绑定单核 CPU 操作。由于子进程非常消耗 CPU,会和父进程产生单核资源竞争。
- 不要和其他 CPU 密集型服务部署在一起,造成 CPU 过度竞争。
- 如果部署多个 Redis 实例,尽量保证同一时刻只有一个子进程执行重写工作。
2)内存
- 内存消耗分析。子进程通过 fork 操作产生,占用内存大小等同于父进程,理论上需要两倍的内存来完成持久化操作,但 Linux 有写时复制机制(copy-on-write)。父子进程会共享相同的物理内存页,当父进程处理写请求时会把要修改的页创建副本,而子进程在 fork 操作过程中共享整个父进程内存快照。
- 内存消耗监控。如果重写过程中存在内存修改操作,父进程负责创建所修改内存页的副本。
- 父进程维护页副本消耗同 RDB 重写过程类似,不同之处在于 AOF 重写需要 AOF 重写缓冲区。
- 内存消耗优化:
- 同 CPU 优化一样,如果部署多个 Redis 实例,尽量保证同一时刻只有一个子进程在工作。
- 避免在大量写入时做子进程重写操作,这样将导致父进程维护大量页副本,造成内存消耗。
- Linux kernel 在 2.6.38 内核增加了 Transparent Huge Pages(THP),支持 huge page(2MB)的页分配,默认开启。当开启时可以降低 fork 创建子进程的速度,但执行 fork 之后,如果开启 THP,复制页单位从原来 4KB 变为 2MB,会大幅增加重写期间父进程内存消耗。建议设置 “sudo echo never>/sys/kernel/mm/transparent_hugepage/enabled” 关闭 THP。
3)硬盘
- 硬盘开销分析。子进程主要职责是把 AOF 或者 RDB 文件写入硬盘持久化。势必造成硬盘写入压力。根据 Redis 重写 AOF/RDB 的数据量,结合系统 工具如 sar 、iostat、iotop 等,可分析出重写期间硬盘负载情况。
- 硬盘开销优化。优化方法如下:
- 不要和其他高硬盘负载的服务部署在一起。如:存储服务、消息队列服务等。
- AOF 重写时会消耗大量硬盘 IO,可以开启配置 no-appendfsync-on-rewrite,默认关闭。表示在 AOF 重写期间不做 fsync 操作。
- 当开启 AOF 功能的 Redis 用于高流量写入场景时,如果使用普通机械磁盘,写入吞吐一般在 100MB/s 左右,这时 Redis 实例的瓶颈主要在 AOF 同步硬盘上。
- 对于单机配置多个 Redis 实例的情况,可以配置不同实例分盘存储 AOF 文件,分摊硬盘写入压力。
- 配置 no-appendfsync-on-rewrite=yes 时,在极端情况下可能丢失整个 AOF 重写期间的数据,需要根据数据安全性决定是否配置。
7、问题定位与优化 - AOF 追加阻塞
- 当开启 AOF 持久化时,常用的同步硬盘的策略是 everysec,用于平衡性能和数据安全性。对于这种方式,Redis 使用另一条线程每秒执行 fsync 同步硬盘。当系统硬盘资源繁忙时,会造成 Redis 主线程阻塞。
- 阻塞流程分析:
- 主线程负责写入 AOF 缓冲区。
- AOF 线程负责每秒执行一次同步磁盘操作,并记录最近一次同步时间。
- 主线程负责对比上次 AOF 同步时间:
- 如果距上次同步成功时间在 2 秒内,主线程直接返回。
- 如果距上次同步成功时间超过 2 秒,主线程将会阻塞,直到同步操作完成。
- 通过对 AOF 阻塞流程可以发现两个问题:
- everysec 配置最多可能丢失 2 秒数据,不是 1 秒。
- 如果系统 fsync 缓慢,将会导致 Redis 主线程阻塞影响效率。
- AOF 阻塞问题定位:
- 发生 AOF 阻塞时,Redis 会输出日志,用于记录 AOF fsync 阻塞导致拖慢 Redis 服务的行为。
- 每当发生 AOF 追加阻塞事件发生时,在 info Persistence 统计中,aof_delayed_fsync 指标会累加,查看这个指标方便定位 AOF 阻塞问题。
- AOF 同步最多允许 2 秒的延迟,当延迟发生时说明硬盘存在高负载问题,可以通过监控工具如 iotop,定位消耗硬盘 IO 资源的进程。
8、多实例部署
Redis 单线程架构导致无法充分利用 CPU 多核特性,通常的做法是在一台机器上部署多个 Redis 实例。当多个实例开启 AOF 重写后,彼此之间会
产生对 CPU 和 IO 的竞争。
单机下部署多个实例时,为了防止出现多个子进程执行重写操作,建议做隔离控制,避免 CPU 和 IO 资源竞争。
Redis 在 info Persistence 中为我们提供了监控子进程运行状况的度量指标,如下表:
| 属性名 | 属性值 |
|---|---|
| rdb_bgsave_in_progress | bgsave 子进程是否正在运行 |
| rdb_current_bgsave_time_sec | 当前运行 bgsave 的时间,-1 表示未运行 |
| aof_enabled | 是否开启 AOF 功能 |
| aof_rewrite_in_progress | AOF 重写子进程是否正在运行 |
| aof_rewrite_scheduled | 在 bgsave 结束后是否运行 AOF 重写 |
| aof_current_rewrite_time_sec | 当前运行 AOF 重写的时间,-1 表示未运行 |
| aof_current_size | AOF 文件当前字节数 |
| aof_base_size | AOF 上次重写 rewrite 的字节数 |
我们基于以上指标,可以通过外部程序轮询控制 AOF 重写操作的执行。流程说明:
- 外部程序定时轮询监控机器(machine)上所有 Redis 实例。
- 对于开启 AOF 的实例,查看 (aof_current_size-aof_base_size)/aof_base_size 确认增长率。
- 当增长率超过特定阈值(如 100%),执行 bgrewriteaof 命令手动触发当前实例的 AOF 重写。
- 运行期间循环检查 aof_rewrite_in_progress 和 aof_current_rewrite_time_sec 指标,直到 AOF 重写结束。
- 确认实例 AOF 重写完成后,再检查其他实例并重复 2)~4)步操作。从而保证机器内每个 Redis 实例 AOF 重写串行化执行。
六、复制
1、复制功能是高可用 Redis 的基础,哨兵和集群都是在复制的基础上实现高可用的。
2、建立复制
- 参与复制的 Redis 实例划分为主节点(master)和从节点(slave)。默认情况下,Redis 都是主节点。
- 每个从节点只能有一个主节点,而主节点可以同时具有多个从节点。
- 复制的数据流是单向的,只能由主节点复制到从节点。
配置复制的方式有以下三种:
- 在配置文件中加入 slaveof{masterHost}{masterPort} 随 Redis 启动生效。
- 在 redis-server 启动命令后加入–slaveof{masterHost}{masterPort} 生效。
- 直接使用命令:slaveof{masterHost}{masterPort} 生效。
slaveof 配置都是在从节点发起。
// 6379作为主节点,6380作为从节点
127.0.0.1:6380> slaveof 127.0.0.1 6379
127.0.0.1:6379> set hello redis
OK
127.0.0.1:6379> get hello
"redis"
127.0.0.1:6380> get hello
"redis"
// 主节点6379复制状态信息
127.0.0.1:6379> info replication
# Replication
role:master
connected_slaves:1
slave0:ip=127.0.0.1,port=6379,state=online,offset=43,lag=0
. . . .
// 从节点6380复制状态信息
127.0.0.1:6380> info replication
# Replication
role:slave
master_host:127.0.0.1
master_port:6380
master_link_status:up
master_last_io_seconds_ago: 4
master_sync_in_progress:0
. . . .
- slaveof 本身是异步命令,执行 slaveof 命令时,节点只保存主节点信息后返回,后续复制流程在节点内部异步执行。
- 主从节点复制成功建立后,可以使用 info replication 命令查看复制相关状态。
3、断开复制
1)通过在从节点执行 slaveof no one 来断开与主节点复制关系。
断开复制主要流程:
- 断开与主节点复制关系。
- 从节点晋升为主节点。
从节点断开复制后并不会抛弃原有数据,只是无法再获取主节点上的数据变化。
2)通过 slaveof 命令还可以实现切主操作,所谓切主是指把当前从节点对主节点的复制切换到另一个主节点。执行 slaveof{newMasterIp} {newMasterPort} 命令即可。
切主操作流程如下:
- 断开与旧主节点复制关系。
- 与新主节点建立复制关系。
- 删除从节点当前所有数据。
- 对新主节点进行复制操作。
切主后从节点会清空之前所有的数据,线上人工操作时小心 slaveof 在错误的节点上执行或者指向错误的主节点。
4、配置的安全性
- 对于数据比较重要的节点,主节点会通过设置 requirepass 参数进行密码验证,这时所有的客户端访问必须使用 auth 命令实行校验。
- 从节点与主节点的复制连接是通过一个特殊标识的客户端来完成,因此需要配置从节点的 masterauth 参数与主节点密码保持一致,这样从节点才可以正确地连接到主节点并发起复制流程。
5、配置只读
- 默认情况下,从节点使用 slave-read-only=yes 配置为只读模式。
- 由于复制只能从主节点到从节点,对于从节点的任何修改主节点都无法感知,修改从节点会造成主从数据不一致。
- 因此建议线上不要修改从节点的只读模式。
6、传输延迟
Redis 为我们提供了 repl-disable-tcp-nodelay 参数用于控制是否关闭 TCP_NODELAY,默认关闭。
- 当关闭时,主节点产生的命令数据无论大小都会及时地发送给从节点,这样主从之间延迟会变小,但增加了网络带宽的消耗。适用于主从之间的网络环境良好的场景,如同机架或同机房部署。
- 当开启时,主节点会合并较小的 TCP 数据包从而节省带宽。默认发送时间间隔取决于 Linux 的内核,一般默认为 40 毫秒。这种配置节省了带宽但增大主从之间的延迟。适用于主从网络环境复杂或带宽紧张的场景,如跨机房部署。
- 部署主从节点时需要考虑网络延迟、带宽使用率、防灾级别等因素,如要求低延迟时,建议同机架或同机房部署并关闭 repl-disable-tcp-nodelay;如果考虑高容灾性,可以同城跨机房部署并开启 repl-disable-tcp-nodelay。
7、拓扑
Redis 的复制拓扑结构可以支持单层或多层复制关系,根据拓扑复杂性可以分为以下三种:一主一从、一主多从、树状主从结构。
1)一主一从结构
- 当应用写命令并发量较高且需要持久化时,可以只在从节点上开启 AOF,这样既保证数据安全性同时也避免了持久化对主节点的性能干扰。
- 但需要注意的是,当主节点关闭持久化功能时,如果主节点脱机要避免自动重启操作。因为主节点之前没有开启持久化功能,自动重启后数据集为空,这时从节点如果继续复制主节点会导致从节点数据也被清空的情况,丧失了持久化的意义。
- 安全的做法是在从节点上执行 slaveof no one 断开与主节点的复制关系,再重启主节点从而避免这一问题。
2)一主多从结构
- 一主多从结构(又称为星形拓扑结构)使得应用端可以利用多个从节点实现读写分离。
- 对于读占比较大的场景,可以把读命令发送到从节点来分担主节点压力。同时在日常开发中如果需要执行一些比较耗时的读命令,如:keys、sort 等,可以在其中一台从节点上执行,防止慢查询对主节点造成阻塞从而影响线上服务的稳定性。
- 对于写并发量较高的场景,多个从节点会导致主节点写命令的多次发送从而过度消耗网络带宽,同时也加重了主节点的负载影响服务稳定性。
3)树状主从结构
- 树状主从结构(又称为树状拓扑结构)使得从节点不但可以复制主节点数据,同时可以作为其他从节点的主节点继续向下层复制。
- 通过引入复制中间层,可以有效降低主节点负载和需要传送给从节点的数据量。
- 当主节点需要挂载多个从节点时为了避免对主节点的性能干扰,可以采用树状主从结构降低主节点压力。
8、复制过程的原理
在从节点执行 slaveof 命令后,复制过程便开始运作,复制过程大致分为 6 个过程:
1)保存主节点(master)信息。
- 执行 slaveof 后从节点只保存主节点的地址信息便直接返回,这时建立复制流程还没有开始。
2)主从建立 socket 连接。
- 从节点(slave)内部通过每秒运行的定时任务维护复制相关逻辑,当定时任务发现存在新的主节点后,会尝试与该节点建立网络连接。
- 如果从节点无法建立连接,定时任务会无限重试直到连接成功或者执行 slaveof no one 取消复制。
- 关于连接失败,可以在从节点执行 info replication 查看 master_link_down_since_seconds 指标,它会记录与主节点连接失败的系统时 间。从节点连接主节点失败时也会每秒打印日志,方便运维人员发现问题。
3)发送 ping 命令。
- 连接建立成功后从节点发送 ping 请求进行首次通信,ping 请求主要目的如下:
- 检测主从之间网络套接字是否可用。
- 检测主节点当前是否可接受处理命令。
- 如果发送 ping 命令后,从节点没有收到主节点的 pong 回复或者超时,比如网络超时或者主节点正在阻塞无法响应命令,从节点会断开复制连接,下次定时任务会发起重连。
4)权限验证。
- 如果主节点设置了 requirepass 参数,则需要密码验证,从节点必须配置 masterauth 参数保证与主节点相同的密码才能通过验证;如果验证失败复制将终止,从节点重新发起复制流程。
5)同步数据集。
- 主从复制连接正常通信后,对于首次建立复制的场景,主节点会把持有的数据全部发送给从节点,这部分操作是耗时最长的步骤。
- Redis 在 2.8 版本以后采用新复制命令 psync 进行数据同步,原来的 sync 命令依然支持,保证新旧版本的兼容性。新版同步划分两种情况: 全量同步和部分同步。
6)命令持续复制。
- 当主节点把当前的数据同步给从节点后,便完成了复制的建立流程。接下来主节点会持续地把写命令发送给从节点,保证主从 数据一致性。
9、数据同步的原理
Redis 在 2.8 及以上版本使用 psync 命令完成主从数据同步,同步过程分为:全量复制和部分复制。
- 全量复制:一般用于初次复制场景,Redis 早期支持的复制功能只有全量复制,它会把主节点全部数据一次性发送给从节点,当数据量较大时,会对主从节点和网络造成很大的开销。
- 部分复制:用于处理在主从复制中因网络闪断等原因造成的数据丢失场景,当从节点再次连上主节点后,如果条件允许,主节点会补发丢失数据给从节点。因为补发的数据远远小于全量数据,可以有效避免全量复制的过高开销。
部分复制是对老版复制的重大优化,有效避免了不必要的全量复制操作。因此当使用复制功能时,尽量采用 2.8 以上版本的 Redis。
psync 命令运行需要以下组件支持:
- 主从节点各自复制偏移量。
- 主节点复制积压缓冲区。
- 主节点运行 id。
1)复制偏移量
- 参与复制的主从节点都会维护自身复制偏移量。主节点(master)在处理完写入命令后,会把命令的字节长度做累加记录,统计信息在 info relication 中的 master_repl_offset 指标中。
- 从节点(slave)每秒钟上报自身的复制偏移量给主节点,因此主节点也会保存从节点的复制偏移量。
- 从节点在接收到主节点发送的命令后,也会累加记录自身的偏移量。统计信息在 info relication 中的 slave_repl_offset 指标中。
- 通过对比主从节点的复制偏移量,可以判断主从节点数据是否一致。
- 可以通过主节点的统计信息,计算出 master_repl_offset-slave_offset 字节量,判断主从节点复制相差的数据量,根据这个差值判定当前复制的健康度。如果主从之间复制偏移量相差较大,则可能是网络延迟或命令阻塞等原因引起。
2)复制积压缓冲区
- 复制积压缓冲区是保存在主节点上的一个固定长度的队列,默认大小为 1MB,当主节点有连接的从节点(slave)时被创建,这时主节点(master)响应写命令时,不但会把命令发送给从节点,还会写入复制积压缓冲区。
- 由于缓冲区本质上是先进先出的定长队列,所以能实现保存最近已复制数据的功能,用于部分复制和复制命令丢失的数据补救。
- 根据统计指标,可算出复制积压缓冲区内的可用偏移量范围:[repl_backlog_first_byte_offset, repl_backlog_first_byte_offset+repl_backlog_histlen]。
复制缓冲区相关统计信息保存在主节点的info replication中:
127.0.0.1:6379> info replication
# Replication
role :master
. . .
repl_backlog_active :1 // 开启复制缓冲区
repl_backlog_size :1048576 // 缓冲区最大长度
repl_backlog_first_byte_offset :7479 // 起始偏移量,计算当前缓冲区可用范围
repl_backlog_histlen :1048576 // 已保存数据的有效长度。
3)主节点运行 ID
- 每个 Redis 节点启动后都会动态分配一个 40 位的十六进制字符串作为运行 ID。
- 运行 ID 的主要作用是用来唯一识别 Redis 节点,比如从节点保存主节点的运行 ID 识别自己正在复制的是哪个主节点。
- 如果只使用 ip+port 的方式识别主节点,那么主节点重启变更了整体数据集(如替换 RDB/AOF 文件),从节点再基于偏移量复制数据将是不安全的,因此当运行 ID 变化后从节点将做全量复制。
- 可以运行 info server 命令查看当前节点的运行 ID(run_id)。
- Redis 关闭再启动后,运行 ID 会随之改变.
- 在不改变运行 ID 的情况下重启的方法:当需要调优一些内存相关配置,例如:hash-max-ziplist-value 等,这些配置需要 Redis 重新加载才能优化已存在的数据,这时可以使用 debug reload 命令重新加载 RDB 并保持运行 ID 不变,从而有效避免不必要的全量复制。
- debug reload 命令会阻塞当前 Redis 节点主线程,阻塞期间会生成本地 RDB 快照并清空数据之后再加载 RDB 文件。因此对于大数据量的主节点和无法容忍阻塞的应用场景,谨慎使用。
- psync 命令
- 从节点使用 psync 命令完成部分复制和全量复制功能,命令格式:psync {runId}{offset},参数含义如下:
- runId:从节点所复制主节点的运行 id。
- offset:当前从节点已复制的数据偏移量。
- psync 命令运行流程说明:
- 从节点(slave)发送 psync 命令给主节点,参数 runId 是当前从节点保存的主节点运行 ID,如果没有则默认值为?,参数 offset 是当前从节点保存的复制偏移量,如果是第一次参与复制则默认值为 - 1。
- 主节点(master)根据 psync 参数和自身数据情况决定响应结果:
- 如果回复 + FULLRESYNC{runId}{offset} ,那么从节点将触发全量复制流程。
- 如果回复 + CONTINUE,从节点将触发部分复制流程。
- 如果回复 + ERR,说明主节点版本低于 Redis2.8,无法识别 psync 命令,从节点将发送旧版的 sync 命令触发全量复制流程。
10、全量复制的原理
触发全量复制的命令是 sync 和 psync。
psync 全量复制的完整运行流程 (与 2.8 以前的 sync 全量复制机制基本一致):
- 发送 psync 命令进行数据同步,由于是第一次进行复制,从节点没有复制偏移量和主节点的运行 ID,所以发送 psync ? -1。
- 主节点根据 psync ? -1 解析出当前为全量复制,回复 + FULLRESYNC 响应。
- 从节点接收主节点的响应数据保存运行 ID 和偏移量 offset。
- 主节点执行 bgsave 保存 RDB 文件到本地。
M * Full resync requested by slave 127.0.0.1:6380 - 主节点发送 RDB 文件给从节点,从节点把接收的 RDB 文件保存在本地并直接作为从节点的数据文件,接收完 RDB 后从节点打印相关日志,可以在日志中查看主节点发送的数据量。
16:24:03.057 * MASTER <-> SLAVE sync : receiving 24777842 bytes from master - 对于从节点开始接收 RDB 快照到接收完成期间,主节点仍然响应读写命令,因此主节点会把这期间写命令数据保存在复制客户端缓冲区内,当从节点加载完 RDB 文件后,主节点再把缓冲区内的数据发送给从节点,保证主从之间数据一致性。如果主节点创建和传输 RDB 的时间过长,对于高流量写入场景非常容易造成主节点复制客户端缓冲区溢出。默认配置为 client-output-buffer-limit slave 256MB 64MB 60 ,如果 60 秒内缓冲区消耗持续大于 64MB 或者直接超过 256MB 时,主节点将直接关闭复制客户端连接,造成全量同步失败。
- 从节点接收完主节点传送来的全部数据后会清空自身旧数据,该步骤对应如下日志:
16:24:02.234 * MASTER <-> SLAVE sync : Flushing old data - 从节点清空数据后开始加载 RDB 文件,对于较大的 RDB 文件,这一步操作依然比较耗时,可以通过计算日志之间的时间差来判断加载 RDB 的总耗时,对应如下日志:
16:24:03.578 * MASTER <-> SLAVE sync : Loading DB in memory
16:24:06.756 * MASTER < > SLAVE sync : Finished with success - 从节点成功加载完 RDB 后,如果当前节点开启了 AOF 持久化功能,它会立刻做 bgrewriteaof 操作,为了保证全量复制后 AOF 持久化文件立刻可用。
- Redis3.0 之后在输出的日志开头会有 M、S、C 等标识,对应的含义是:M = 当前为主节点日志,S = 当前为从节点日志,C = 子进程日志,我们可以根据日志标识快速识别出每行日志的角色信息。
- 对于数据量较大的主节点,比如生成的 RDB 文件超过 6GB 以上时要格外小心。传输文件这一步操作非常耗时,速度取决于主从节点之间网络带宽,通过细致分析 Full resync 和 MASTER<->SLAVE 这两行日志的时间差,可以算出 RDB 文件从创建到传输完毕消耗的总时间。如果总时间超过 repl-timeout 所配置的值(默认 60 秒),从节点将放弃接受 RDB 文件并清理已经下载的临时文件,导致全量复制失败,此时从节点打印如下日志:
M 27 May 12:10:31.169 # Timeout receiving bulk data from MASTER . . . - 针对数据量较大的节点,建议调大 repl-timeout 参数防止出现全量同步数据超时。
- 关于无盘复制:为了降低主节点磁盘开销,Redis 支持无盘复制,生成的 RDB 文件不保存到硬盘而是直接通过网络发送给从节点,通过 repl-diskless-sync 参数控制,默认关闭。无盘复制适用于主节点所在机器磁盘性能较差但网络带宽较充裕的场景。注意无盘复制目前依然处于试验阶段,线上使用需要做好充分测试。
- 运维人员需要根据主节点数据量和写命令并发量调整 client-output-buffer-limit slave 配置,避免全量复制期间客户端缓冲区溢出。
- 对于主节点,当发送完所有的数据后就认为全量复制完成,打印成功日志:Synchronization with slave127.0.0.1:6380 succeeded,但是对于从节点全量复制依然没有完成,还有后续步骤需要处理。
- 对于线上做读写分离的场景,从节点也负责响应读命令。如果此时从节点正出于全量复制阶段或者复制中断,那么从节点在响应读命令可能拿到过期或错误的数据。对于这种场景,Redis 复制提供了 slave-serve-stale-data 参数,默认开启状态。如果开启则从节点依然响应所有命令。对于无法容忍不一致的应用场景可以设置 no 来关闭命令执行,此时从节点除了 info 和 slaveof 命令之外所有的命令只返回 “SYNC with master in progress” 信息。
- 全量复制是一个非常耗时费力的操作。它的时间开销主要包括:
- 主节点 bgsave 时间。
- RDB 文件网络传输时间。
- 从节点清空数据时间。
- 从节点加载 RDB 的时间。
- 可能的 AOF 重写时间。
- 除了第一次复制时采用全量复制在所难免之外,对于其他场景应该规避全量复制的发生。
11、部分复制的原理
- 部分复制主要是 Redis 针对全量复制的过高开销做出的一种优化措施,使用 psync {runId}{offset} 命令实现。
- 当从节点(slave)正在复制主节点(master)时,如果出现网络闪断或者命令丢失等异常情况时,从节点会向主节点要求补发丢失的命令数据,如果主节点的复制积压缓冲区内存在这部分数据则直接发送给从节点,这样就可以保持主从节点复制的一致性。
- 补发的这部分数据一般远远小于全量数据,所以开销很小。
部分复制的流程:
- 当主从节点之间网络出现中断时,如果超过 repl-timeout 时间,主节点会认为从节点故障并中断复制连接。
- 主从连接中断期间主节点依然响应命令,但因复制连接中断命令无法发送给从节点,不过主节点内部存在的复制积压缓冲区,依然可以保存最近一段时间的写命令数据,默认最大缓存 1MB。
- 当主从节点网络恢复后,从节点会再次连上主节点。
- 当主从连接恢复后,由于从节点之前保存了自身已复制的偏移量和主节点的运行 ID。因此会把它们当作 psync 参数发送给主节点,要求进行部分复制操作。
- 主节点接到 psync 命令后首先核对参数 runId 是否与自身一致,如果一致,说明之前复制的是当前主节点;之后根据参数 offset 在自身复制积压缓冲区查找,如果偏移量之后的数据存在缓冲区中,则对从节点发送 + CONTINUE 响应,表示可以进行部分复制。
- 主节点根据偏移量把复制积压缓冲区里的数据发送给从节点,保证主从复制进入正常状态。
12、心跳的原理
主从节点在建立复制后,它们之间维护着长连接并彼此发送心跳命令。
主从心跳判断机制:
-
主从节点彼此都有心跳检测机制,各自模拟成对方的客户端进行通信,通过 client list 命令查看复制相关客户端信息,主节点的连接状态为 flags=M,从节点连接状态为 flags=S。
-
主节点默认每隔 10 秒对从节点发送 ping 命令,判断从节点的存活性和连接状态。可通过参数 repl-ping-slave-period 控制发送频率。
-
从节点在主线程中每隔 1 秒发送 replconf ack{offset} 命令,给主节点上报自身当前的复制偏移量。replconf 命令主要作用如下:
- 实时监测主从节点网络状态。
- 上报自身复制偏移量,检查复制数据是否丢失,如果从节点数据丢失,再从主节点的复制缓冲区中拉取丢失数据。
- 实现保证从节点的数量和延迟性功能,通过 min-slaves-to-write、min-slaves-max-lag 参数配置定义。
- 主节点根据 replconf 命令判断从节点超时时间,体现在 info replication 统计中的 lag 信息中,lag 表示与从节点最后一次通信延迟的秒数,正常延迟应该在 0 和 1 之间。如果超过 repl-timeout 配置的值(默认 60 秒),则判定从节点下线并断开复制客户端连接。
- 即使主节点判定从节点下线后,如果从节点重新恢复,心跳检测会继续进行。
- 为了降低主从延迟,一般把 Redis 主从节点部署在相同的机房 / 同城机房,避免网络延迟和网络分区造成的心跳中断等情况。
13、异步复制的原理
主节点不但负责数据读写,还负责把写命令同步给从节点。写命令的发送过程是异步完成,也就是说主节点自身处理完写命令后直接返回给客户端,并不等待从节点复制完成。
主节点复制流程:
- 主节点 6379 接收处理命令。
- 命令处理完之后返回响应结果。
- 对于修改命令异步发送给 6380 从节点,从节点在主线程中执行复制的命令。
由于主从复制过程是异步的,就会造成从节点的数据相对主节点存在延迟。具体延迟多少字节,我们可以在主节点执行 info replication 命令查看相关指标获得。如下:
// offset表示当前从节点的复制偏移量,master_repl_offset表示当前主节点的复制偏移量,两者的差值就是当前从节点复制延迟量。
slave0:ip=127.0.0.1,port=6380,state=online,offset=841,lag=1
master_repl_offset:841
Redis 的复制速度取决于主从之间网络环境,repl-disable-tcp-nodelay,命令处理速度等。正常情况下,延迟在 1 秒以内。
14、开发与运维中的问题 - 读写分离
对于读占比较高的场景,可以通过把一部分读流量分摊到从节点(slave)来减轻主节点(master)压力,同时需要注意永远只对主节点执行写操作。
当使用从节点响应读请求时,业务端可能会遇到如下问题:
1)数据延迟
- Redis 复制数据的延迟由于异步复制特性是无法避免的,延迟取决于网络带宽和命令阻塞情况。
- 需要业务场景允许短时间内的数据延迟。对于无法容忍大量延迟场景,可以编写外部监控程序监听主从节点的复制偏移量,当延迟较大时 触发报警或者通知客户端避免读取延迟过高的从节点。
2)读到过期数据
-
当主节点存储大量设置超时的数据时,如缓存数据,Redis 内部需要维护过期数据删除策略。
-
删除策略主要有两种:惰性删除和定时删除。
- 惰性删除:主节点每次处理读取命令时,都会检查键是否超时,如果超时则执行 del 命令删除键对象,之后 del 命令也会异步发送给从节点。需要注意的是为了保证复制的一致性,从节点自身永远不会主动删除超时数据。
- 定时删除:Redis 主节点在内部定时任务会循环采样一定数量的键,当发现采样的键过期时执行 del 命令,之后再同步给从节点。
-
定时删除:如果此时数据大量超时,主节点采样速度跟不上过期速度且主节点没有读取过期键的操作,那么从节点将无法收到 del 命令。这时在从节点上可以读取到已经超时的数据。Redis 在 3.2 版本解决了这个问题,从节点读取数据之前会检查键的过期时间来决定是否返回数据,可以升级到 3.2 版本来规避这个问题。
3)从节点故障问题
- 对于从节点的故障问题,需要在客户端维护可用从节点列表,当从节点故障时立刻切换到其他从节点或主节点上。这个过程类似上文提到的针对延迟过高的监控处理,需要开发人员改造客户端类库。
笔者建议大家在做读写分离之前,可以考虑使用 Redis Cluster 等分布式解决方案,这样不止扩展了读性能还可以扩展写性能和可支撑数据规模,并且一致性和故障转移也可以得到保证,对于客户端的维护逻辑也相对容易。
15、开发与运维中的问题 - 主从配置不一致
对于有些配置主从之间是可以不一致,比如:主节点关闭 AOF 在从节点开启。但对于内存相关的配置必须要一致,比如 maxmemory,hash-max-ziplist-entries 等参数。
16、开发与运维中的问题 - 规避全量复制
对需要进行全量复制的场景逐个分析:
- 第一次建立复制: 由于是第一次建立复制,从节点不包含任何主节点数据,因此必须进行全量复制才能完成数据同步。对于这种情况全量复制无法避免。当对数据量较大且流量较高的主节点添加从节点时,建议在低峰时进行操作,或者尽量规避使用大数据量的 Redis 节点。
- 节点运行 ID 不匹配:当主从复制关系建立后,从节点会保存主节点的运行 ID,如果此时主节点因故障重启,那么它的运行 ID 会改变,从节点发现主节点运行 ID 不匹配时,会认为自己复制的是一个新的主节点从而进行全量复制。对于这种情况应该从架构上规避,比如提供故障转移功能。当主节点发生故障后,手动提升从节点为主节点或者采用支持自动故障转移的哨兵或集群方案。
- 复制积压缓冲区不足:当主从节点网络中断后,从节点再次连上主节点时会发送 psync {offset}{runId} 命令请求部分复制,如果请求的偏移量不在主节点的积压缓冲区内,则无法提供给从节点数据,因此部分复制会退化为全量复制。针对这种情况需要根据网络中断时长,写命令数据量分析出合理的积压缓冲区大小。网络中断一般有闪断、机房割接、网络分区等情况。这时网络中断的时长一般在分钟级(net_break_time)。写命令数据量可以统计高峰期主节点每秒 info replication 的 master_repl_offset 差值获取(write_size_per_minute)。积压缓冲区默认为 1MB,对于大流量场景显然不够,这时需要增大积压缓冲区,保证 repl_backlog_size>net_break_time*write_size_per_minute ,从而避免因复制积压缓冲区不足造成的全量复制。
17、开发与运维中的问题 - 规避复制风暴
复制风暴是指大量从节点对同一主节点或者对同一台机器的多个主节点短时间内发起全量复制的过程。
1)单主节点复制风暴
- 单主节点复制风暴一般发生在主节点挂载多个从节点的场景。当主节点重启恢复后,从节点会发起全量复制流程,这时主节点就会为从节点创建 RDB 快照,如果在快照创建完毕之前,有多个从节点都尝试与主节点进行全量同步,那么其他从节点将共享这份 RDB 快照。这点 Redis 做了优化,有效避免了创建多个快照。但是,同时向多个从节点发送 RDB 快照,可能使主节点的网络带宽消耗严重,造成主节点的延迟变大,极端情况会发生主从节点连接断开,导致复制失败。
- 解决方案首先可以减少主节点(master)挂载从节点(slave)的数量,或者采用树状复制结构,加入中间层从节点用来保护主节点。
- 从节点采用树状树非常有用,网络开销交给位于中间层的从节点,而不必消耗顶层的主节点。但是这种树状结构也带来了运维的复杂性,增加了手动和自动处理故障转移的难度。
2)单机器复制风暴
由于 Redis 的单线程架构,通常单台机器会部署多个 Redis 实例。如果这台机器出现故障或网络长时间中断,当它重启恢复后,会有大量 从节点(slave)针对这台机器的主节点进行全量复制,会造成当前机器网络带宽耗尽。
避免的方法如下:
- 应该把主节点尽量分散在多台机器上,避免在单台机器上部署过多的主节点。
- 当主节点所在机器故障后提供故障转移机制,避免机器恢复后进行密集的全量复制。
七、Redis 的噩梦:阻塞
1、发现阻塞
- 常见的做法是在应用方加入异常统计并通过邮件 / 短信 / 微信报警,以便及时发现通知问题。
- 在实现异常统计时要注意,由于 Redis 调用 API 会分散在项目的多个地方,每个地方都监听异常并加入监控代码必然难以维护。这时可以借助于日志系统,如 Java 语言可以使用 logback 或 log4j 。
- 借助日志系统统计异常的前提是,需要项目必须使用日志 API 进行异常统一输出,比如所有的异常都通过 logger.error 打印,这应该作为开发规范推广。其他编程语言也可以采用类似的日志系统实现异常统计报警。
2、内在原因 - API 或数据结构使用不合理
对于高并发的场景我们应该尽量避免在大对象上执行算法复杂度超过 O(n) 的命令。
1)如何发现慢查询
- Redis 原生提供慢查询统计功能,执行 slowlog get{n} 命令可以获取最近的 n 条慢查询命令,默认对于执行超过 10 毫秒的命令都会记录到一个定长队列中,线上实例建议设置为 1 毫秒便于及时发现毫秒级以上的命令。
- 如果命令执行时间在毫秒级,则实例实际 OPS 只有 1000 左右。
- 慢查询队列长度默认 128,可适当调大。
发现慢查询后,可以按照以下两个方向去调整:
- 修改为低算法度的命令,如 hgetall 改为 hmget 等,禁用 keys、sort 等命令。
- 调整大对象:缩减大对象数据或把大对象拆分为多个小对象,防止一次命令操作过多的数据。大对象拆分过程需要视具体的业务决定,如用户好友集合存储在 Redis 中,有些热点用户会关注大量好友,这时可以按时间或其他维度拆分到多个集合中。
2)如何发现大对象
- Redis 本身提供发现大对象的工具,对应命令: redis-cli -h{ip} -p{port} bigkeys 。内部原理采用分段进行 scan 操作,把历史扫描过的最大对象统计出来便于分析优化。
3、内在原因 - CPU 饱和
- 单线程的 Redis 处理命令时只能使用一个 CPU。CPU 饱和是指 Redis 把单核 CPU 使用率跑到接近 100%。
- 使用 top 命令很容易识别出对应 Redis 进程的 CPU 使用率。
- 对于这种情况,首先判断当前 Redis 的并发量是否达到极限,建议使用统计命令 redis-cli -h{ip} -p{port} --stat 获取当前 Redis 使用情况,该命令每秒输出一行统计信息。
- 还有一种情况是过度的内存优化,这种情况有些隐蔽,需要我们根据 info commandstats 统计信息分析出命令不合理开销时间。
4、内在原因 - 持久化阻塞
1)fork 阻塞
- fork 操作发生在 RDB 和 AOF 重写时,Redis 主线程调用 fork 操作产生共享内存的子进程,由子进程完成持久化文件重写工作。如果 fork 操作本身耗时过长,必然会导致主线程的阻塞。
- 可以执行 info stats 命令获取到 latest_fork_usec 指标,表示 Redis 最近一次 fork 操作耗时,如果耗时很大,比如超过 1 秒,则需要做出优化调整,如避免使用过大的内存实例和规避 fork 缓慢的操作系统等。
2)AOF 刷盘阻塞
- 当我们开启 AOF 持久化功能时,文件刷盘的方式一般采用每秒一次,后台线程每秒对 AOF 文件做 fsync 操作。
- 当硬盘压力过大时,fsync 操作需要等待,直到写入完成。如果主线程发现距离上一次的 fsync 成功超过 2 秒,为了数据安全性它会阻塞直到后台线程执行 fsync 操作完成。这种阻塞行为主要是硬盘压力引起,可以查看 Redis 日志识别出这种情况,当发生这种阻塞行为时,会打印如下日志:
Asynchronous AOF fsync is taking too long (disk is busy) . Writing the AOF buffer without waiting for fsync to complete, this may slow down Redis . - 也可以查看 info persistence 统计中的 aof_delayed_fsync 指标,每次发生 fdatasync 阻塞主线程时会累加。
- 硬盘压力可能是 Redis 进程引起的,也可能是其他进程引起的,可以使用 iotop 查看具体是哪个进程消耗过多的硬盘资源。
3)HugePage 写操作阻塞
- 子进程在执行重写期间利用 Linux 写时复制技术降低内存开销,因此只有写操作时 Redis 才复制要修改的内存页。
- 对于开启 Transparent HugePages 的操作系统,每次写命令引起的复制内存页单位由 4K 变为 2MB,放大了 512 倍,会拖慢写操作的执行时间,导致大量写操作慢查询。
5、外在原因 - CPU 竞争
CPU 竞争问题如下:
- 进程竞争:Redis 是典型的 CPU 密集型应用,不建议和其他多核 CPU 密集型服务部署在一起。当其他进程过度消耗 CPU 时,将严重影响 Redis 吞吐量。可以通过 top、sar 等命令定位到 CPU 消耗的时间点和具体进程。
- 绑定 CPU:部署 Redis 时为了充分利用多核 CPU,通常一台机器部署多个实例。常见的一种优化是把 Redis 进程绑定到 CPU 上,用于降低 CPU 频繁上下文切换的开销。这个优化技巧正常情况下没有问题,但是存在例外情况,
- 当 Redis 父进程创建子进程进行 RDB/AOF 重写时,如果做了 CPU 绑定,会与父进程共享使用一个 CPU。子进程重写时对单核 CPU 使用率通常在 90% 以上,父进程与子进程将产生激烈 CPU 竞争,极大影响 Redis 稳定性。因此对于开启了持久化或参与复制的主节点不建议绑定 CPU。
6、外在原因 - 内存交换
内存交换(swap)对于 Redis 来说是非常致命的,Redis 保证高性能的一个重要前提是所有的数据在内存中。如果操作系统把 Redis 使用的部分内存换出到硬盘,由于内存与硬盘读写速度差几个数量级,会导致发生交换后的 Redis 性能急剧下降。
识别 Redis 内存交换的检查方法如下:
1、查询Redis进程号:
# redis cli p 6383 info server | grep process_id
process_id :4476
2、根据进程号查询内存交换信息:
# cat /proc/4476/smaps | grep Swap
Swap : 0 kB
Swap : 0 kB
Swap : 4 kB
Swap : 0 kB
Swap : 0 kB
......
如果交换量都是 0KB 或者个别的是 4KB,则是正常现象,说明 Redis 进程内存没有被交换。
预防内存交换的方法有:
- 保证机器充足的可用内存。
- 确保所有 Redis 实例设置最大可用内存(maxmemory),防止极端情况下 Redis 内存不可控的增长。
- 降低系统使用 swap 优先级,如 echo 10>/proc/sys/vm/swappiness,
7、外在原因 - 网络问题
1)连接拒绝
当出现网络闪断或者连接数溢出时,客户端会出现无法连接 Redis 的情况。我们需要区分这三种情况:网络闪断、Redis 连接拒绝、连接溢出。
- 网络闪断。一般发生在网络割接或者带宽耗尽的情况,对于网络闪断的识别比较困难,常见的做法可以通过 sar-n DEV 查看本机历史流量是否正常,或者借助外部系统监控工具(如 Ganglia)进行识别。
- Redis 连接拒绝。Redis 通过 maxclients 参数控制客户端最大连接数,默认 10000。当 Redis 连接数大于 maxclients 时会拒绝新的连接进入,info stats 的 rejected_connections 统计指标记录所有被拒绝连接的数量。
- Redis 使用多路复用 IO 模型可支撑大量连接,但是不代表可以无限连接。客户端访问 Redis 时尽量采用 NIO 长连接或者连接池的方式。
- 当 Redis 用于大量分布式节点访问且生命周期比较短的场景时,如比较典型的在 Map/Reduce 中使用 Redis。因为客户端服务存在频繁启动和销毁的情况且默认 Redis 不会主动关闭长时间闲置连接或检查关闭无效的 TCP 连接,因此会导致 Redis 连接数快速消耗且无法释放的问题。这种场景下建议设置 tcp-keepalive 和 timeout 参数让 Redis 主动检查和关闭无效连接。
- 连接溢出。这是指操作系统或者 Redis 客户端在连接时的问题。
- 进程限制:
- 操作系统一般会对进程使用的资源做限制,其中一项是对进程可打开最大文件数控制,通过 ulimit-n 查看,通常默认 1024。
- 由于 Linux 系统对 TCP 连接也定义为一个文件句柄,因此对于支撑大量连接的 Redis 来说需要增大这个值,如设置 ulimit-n65535 ,防止 Too many open files 错误。
- backlog 队列溢出:
- 系统对于特定端口的 TCP 连接使用 backlog 队列保存。Redis 默认的长度为 511,通过 tcp-backlog 参数设置。
- 如果 Redis 用于高并发场景为了防止缓慢连接占用,可适当增大这个设置,但必须大于操作系统允许值才能生效。
- 系统的 backlog 默认值为 128,使用 echo 511>/proc/sys/net/core/somaxconn 命令进行修改。
- 可以通过 netstat -s 命令获取因 backlog 队列溢出造成的连接拒绝统计。
- 如果怀疑是 backlog 队列溢出,线上可以使用 cron 定时执行 netstat -s | grep overflowed 统计,查看是否有持续增长的连接拒绝情况。
- 进程限制:
# netstat -s | grep overflowed
663 times the listen queue of a socket overflowed
2)网络延迟
- 常见的物理拓扑按网络延迟由快到慢可分为:同物理机 > 同机架 > 跨机架 > 同机房 > 同城机房 > 异地机房。
- 但它们容灾性正好相反,同物理机容灾性最低而异地机房容灾性最高。
- Redis 提供了测量机器之间网络延迟的工具,在 redis-cli -h{host} -p{port} 命令后面加入如下参数进行延迟测试:
- –latency:持续进行延迟测试,分别统计:最小值、最大值、平均值、采样次数。
- –latency-history:统计结果同–latency,但默认每 15 秒完成一行统计,可通过 - i 参数控制采样时间。
- –latency-dist:使用统计图的形式展示延迟统计,每 1 秒采样一次。
3)网卡软中断
- 网卡软中断是指由于单个网卡队列只能使用一个 CPU,高并发下网卡数据交互都集中在同一个 CPU,导致无法充分利用多核 CPU 的情况。
- 网卡软中断瓶颈一般出现在网络高流量吞吐的场景,如下使用 “top + 数字 1” 命令可以很明显看到 CPU1 的软中断指标(si)过高。
- Linux 在内核 2.6.35 以后支持 Receive Packet Steering(RPS),实现了在软件层面模拟硬件的多队列网卡功能。
八、理解内存
1、内存使用统计
可通过执行 info memory 命令获取内存相关指标。
下表为 info memory 详细解释
| 属性名 | 属性说明 |
|---|---|
| used_memory | Redis 分配器分配的内存总量,也就是内部存储的所有数据内存占用量 |
| used_memory_human | 以可读的格式返回 used_memory |
| used_memory_rss | 从操作系统的角度显示 Redis 进程占用的物理内存总量 |
| used_memory_peak | 内存使用是最大值,表示 used_memory 的峰值 |
| used_memory_peak_human | 以可读的格式返回 used_memory_peak |
| used_memory_lua | Lua 引擎所消耗的内存大小 |
| mem_fragmentation_ratio | used_memory_rss/used_memory 比值,表示内存碎片率 |
| mem_allocator | Redis 所使用的内存分配器。默认为 jemalloc |
- 重点关注的指标有:used_memory_rss 和 used_memory 以及它们的比值 mem_fragmentation_ratio:
- 当 mem_fragmentation_ratio>1 时,说明 used_memory_rss-used_memory 多出的部分内存并没有用于数据存储,而是被内存碎片所消耗,如果两者相差很大,说明碎片率严重。
- 当 mem_fragmentation_ratio<1 时,这种情况一般出现在操作系统把 Redis 内存交换(Swap)到硬盘导致,出现这种情况时要格外关注,由于硬盘速度远远慢于内存,Redis 性能会变得很差,甚至僵死。
2、内存消耗划分
Redis 进程内消耗主要包括:自身内存 + 对象内存 + 缓冲内存 + 内存碎片,其中 Redis 空进程自身内存消耗非常少,通常 used_memory_rss 在 3MB 左右,used_memory 在 800KB 左右,一个空的 Redis 进程消耗内存可以忽略不计。
另外三种内存消耗:
1)对象内存
- 对象内存是 Redis 内存占用最大的一块,存储着用户所有的数据。
- Redis 所有的数据都采用 key-value 数据类型,每次创建键值对时,至少创建两个类型对象:key 对象和 value 对象。
- 对象内存消耗可以简单理解为 sizeof(keys)+sizeof(values)。
- 键对象都是字符串,在使用 Redis 时很容易忽略键对内存消耗的影响,应当避免使用过长的键。
- 每种 value 对象类型根据使用规模不同,占用内存不同。在使用时一定要合理预估并监控 value 对象占用情况,避免内存溢出。
2)缓存内存
- 缓冲内存主要包括:客户端缓冲、复制积压缓冲区、AOF 缓冲区。
- 客户端缓冲指的是所有接入到 Redis 服务器 TCP 连接的输入输出缓冲。输入缓冲无法控制,最大空间为 1G,如果超过将断开连接。输出缓冲通过参数 client-output-buffer-limit 控制。
- 普通客户端:除了复制和订阅的客户端之外的所有连接,Redis 的默认配置是:client-output-buffer-limit normal 0 0 0,Redis 并没有对普通客户端的输出缓冲区做限制,一般普通客户端的内存消耗可以忽略不计,但是当有大量慢连接客户端接入时这部分内存消耗就不能忽略了,可以设置 maxclients 做限制。特别是当使用大量数据输出的命令且数据无法及时推送给客户端时, 如 monitor 命令,容易造成 Redis 服务器内存突然飙升。
- 从客户端:主节点会为每个从节点单独建立一条连接用于命令复制,默认配置是:client-output-buffer-limit slave 256mb 64mb 60 。当主从节点之间网络延迟较高或主节点挂载大量从节点时这部分内存消耗将占用很大一部分,建议主节点挂载的从节点不要多于 2 个,主从节点不要部署在较差的网络环境下,防止复制客户端连接缓慢造成溢出。
- 当使用发布订阅功能时,连接客户端使用单独的输出缓冲区,默认配置为:client-output-buffer-limit pubsub 32mb 8mb 60,当订阅服务的消息生产快于消费速度时,输出缓冲区会产生积压造成输出缓冲区空间溢出。
- 复制积压缓冲区: Redis 在 2.8 版本之后提供了一个可重用的固定大小缓冲区用于实现部分复制功能,根据 repl-backlog-size 参数控制,默认 1MB。对于复制积压缓冲区整个主节点只有一个,所有的从节点共享此缓冲区,因此可以设置较大的缓冲区空间,如 100MB,这部分内存投入是有价值的,可以有效避免全量复制。
- AOF 缓冲区:这部分空间用于在 Redis 重写期间保存最近的写入命令。AOF 缓冲区空间消耗用户无法控制,消耗的内存取决于 AOF 重写时间和写入命令量,这部分空间占用通常很小。
- 客户端缓冲指的是所有接入到 Redis 服务器 TCP 连接的输入输出缓冲。输入缓冲无法控制,最大空间为 1G,如果超过将断开连接。输出缓冲通过参数 client-output-buffer-limit 控制。
3)内存碎片
- Redis 默认的内存分配器采用 jemalloc,可选的分配器还有:glibc(就是 GNU C Library 的 malloc 吧?)、tcmalloc。内存分配器为了更好地管理和重复利用内存,分配内存策略一般 采用固定范围的内存块进行分配。
- jemalloc 针对碎片化问题专门做了优化,一般不会存在过度碎片化的问题,正常的碎片率(mem_fragmentation_ratio)在 1.03 左右。
出现高内存碎片问题时常见的解决方式如下:
- 数据对齐:在条件允许的情况下尽量做数据对齐。
- 安全重启:重启节点可以做到内存碎片重新整理,因此可以利用高可用架构,如 Sentinel 或 Cluster,将碎片率过高的主节点转换为从节点,进行安全重启。
3、子进程内存消耗
- 子进程内存消耗主要指执行 AOF/RDB 重写时 Redis 创建的子进程内存消耗。
- Redis 执行 fork 操作产生的子进程内存占用量对外表现为与父进程相同,理论上需要一倍的物理内存来完成重写操作。但 Linux 具有写时复制技术(copy-on-write),父子进程会共享相同的物理内存页,当父进程处理写请求时会对需要修改的页复制出一份副本完成写操作,而子进程依然读取 fork 时整个父进程的内存快照。
- 如果在高并发写的场景下开启 THP ,子进程内存消耗可能是父进程的数倍,极易造成机器物理内存溢出,从而触发 SWAP 或 OOM killer。
子进程内存消耗总结如下:
- Redis 产生的子进程并不需要消耗 1 倍的父进程内存,实际消耗根据期间写入命令量决定,但是依然要预留出一些内存防止溢出。
- 需要设置 sysctl vm.overcommit_memory=1 允许内核可以分配所有的物理内存,防止 Redis 进程执行 fork 时因系统剩余内存不足而失败。
- 排查当前系统是否支持并开启 THP,如果开启建议关闭,防止 copy-on-write 期间内存过度消耗。
4、设置内存上限
Redis 主要通过控制内存上限和回收策略实现内存管理。
Redis 使用 maxmemory 参数限制最大可用内存。限制内存的目的主要有:
- 用于缓存场景,当超出内存上限 maxmemory 时使用 LRU 等删除策略释放空间。
- 防止所用内存超过服务器物理内存。
需要注意,maxmemory 限制的是 Redis 实际使用的内存量,也就是 used_memory 统计项对应的内存。由于内存碎片率的存在,实际消耗的内存可能会比 maxmemory 设置的更大,实际使用时要小心这部分内存溢出。
通过设置内存上限可以非常方便地实现一台服务器部署多个 Redis 进程的内存控制。
得益于 Redis 单线程架构和内存限制机制,即使没有采用虚拟化,不同的 Redis 进程之间也可以很好地实现 CPU 和内存的隔离性。
5、动态调整内存上限
Redis 的内存上限可以通过 config set maxmemory 进行动态修改,即修改最大可用内存。
Redis-1> config set maxmemory 6GB
Redis-2> config set maxmemory 2GB
- 通过动态修改 maxmemory,可以实现在当前服务器下动态伸缩 Redis 内存的目的。
- 当超出系统物理内存限制而不能简单的通过调整 maxmemory 来达到扩容的目的时,需要采用在线迁移数据或者通过复制切换服务器来达到扩容的目的。
- Redis 默认无限使用服务器内存,为防止极端情况下导致系统内存耗尽,建议所有的 Redis 进程都要配置 maxmemory。
- 在保证物理内存可用的情况下,系统中所有 Redis 实例可以调整 maxmemory 参数来达到自由伸缩内存的目的。
6、内存回收策略
Redis 的内存回收机制主要体现在以下两个方面:
1)删除到达过期时间的键对象。
2)内存使用达到 maxmemory 上限时触发内存溢出控制策略。
- 删除过期键对象
- 惰性删除:惰性删除用于当客户端读取带有超时属性的键时,如果已经超过键设置的过期时间,会执行删除操作并返回空,这种策略是出于节省 CPU 成本考虑,不需要单独维护 TTL 链表来处理过期键的删除。但是单独用这种方式存在内存泄露的问题,当过期键一直没有访问将无法得到及时删除,从而导致内存不能及时释放。
- 定时任务删除:Redis 内部维护一个定时任务,默认每秒运行 10 次(通过配置 hz 控制)。定时任务中删除过期键逻辑采用了自适应算法,根据键的过期比例、使用快慢两种速率模式回收键。流程说明如下:
- 定时任务在每个数据库空间随机检查 20 个键,当发现过期时删除对应的键。
- 如果超过检查数 25% 的键过期,循环执行回收逻辑直到不足 25% 或运行超时为止,慢模式下超时时间为 25 毫秒。
- 如果之前回收键逻辑超时,则在 Redis 触发内部事件之前再次以快模式运行回收过期键任务,快模式下超时时间为 1 毫秒且 2 秒内只能运行 1 次。
- 快慢两种模式内部删除逻辑相同,只是执行的超时时间不同。
- 内存溢出控制策略
- 当 Redis 所用内存达到 maxmemory 上限时会触发相应的溢出控制策略。具体策略受 maxmemory-policy 参数控制,Redis 支持 6 种策略:
- noeviction:默认策略,不会删除任何数据,拒绝所有写入操作并返回客户端错误信息(error)OOM command not allowed when used memory,此时 Redis 只响应读操作。
- volatile-lru:根据 LRU 算法删除设置了超时属性(expire)的键,直到腾出足够空间为止。如果没有可删除的键对象,回退到 noeviction 策略。
- allkeys-lru:根据 LRU 算法删除键,不管数据有没有设置超时属性,直到腾出足够空间为止。
- allkeys-random:随机删除所有键,直到腾出足够空间为止。
- volatile-random:随机删除过期键,直到腾出足够空间为止。
- volatile-ttl:根据键值对象的 ttl 属性,删除最近将要过期数据。如果没有,回退到 noeviction 策略。
- 当 Redis 所用内存达到 maxmemory 上限时会触发相应的溢出控制策略。具体策略受 maxmemory-policy 参数控制,Redis 支持 6 种策略:
- Redis 所有的键都可以设置过期属性,内部保存在过期字典中。由于进程内保存大量的键,维护每个键精准的过期删除机制会导致消耗大量的 CPU,对于单线程的 Redis 来说成本过高,因此 Redis 采用惰性删除和定时任务删除机制实现过期键的内存回收。
- 内存溢出控制策略可以采用 config set maxmemory-policy{policy} 动态配置。当 Redis 因为内存溢出删除键时,可以通过执行 info stats 命令查看 evicted_keys 指标找出当前 Redis 服务器已剔除的键数量。
- 每次 Redis 执行命令时如果设置了 maxmemory 参数,都会尝试执行回收内存操作。当 Redis 一直工作在内存溢出(used_memory>maxmemory)的状态下且设置非 noeviction 策略时,会频繁地触发回收内存的操作,影响 Redis 服务器的性能。
- 如果当前 Redis 有从节点,回收内存操作对应的删除命 令会同步到从节点,导致写放大的问题。
- 建议线上 Redis 内存工作在 maxmemory>used_memory 状态下,避免频繁内存回收开销。
- 对于需要收缩 Redis 内存的场景,可以通过调小 maxmemory 来实现快速回收。比如对一个实际占用 6GB 内存的进程设置 maxmemory=4GB,之后第一次执行命令时,如果使用非 noeviction 策略,它会一次性回收到 maxmemory 指定的内存量,从而达到快速回收内存的目的。注意,此操作会导致数据丢失和短暂的阻塞问题,一般在缓存场景下使用。
7、内存优化 - redisObject 对象
- Redis 存储的所有值对象在内部定义为 redisObject 结构体。
- Redis 存储的数据都使用 redisObject 来封装,包括 string、hash、list、set、zset 在内的所有数据类型。
- redisObject 结构体每个字段的详细说明如下:
- type 字段:表示当前对象使用的数据类型,Redis 主要支持 5 种数据类型:string、hash、list、set、zset。可以使用 type {key} 命令查看对象所属类型,type 命令返回的是值对象类型,键都是 string 类型。
- encoding 字段:表示 Redis 内部编码类型,encoding 在 Redis 内部使用,代表当前对象内部采用哪种数据结构实现。
- lru 字段:记录对象最后一次被访问的时间,当配置了 maxmemory 和 maxmemory-policy=volatile-lru 或者 allkeys-lru 时,用于辅助 LRU 算法删除键数据。可以使用 object idletime{key} 命令在不更新 lru 字段情况下查看当前键的空闲时间。
- refcount 字段:记录当前对象被引用的次数,用于通过引用次数回收内存,当 refcount=0 时,可以安全回收当前对象空间。使用 object refcount{key}获取当前对象引用。当对象为整数且范围在 [0-9999] 时,Redis 可以使用共享对象的方式来节省内存。
- *ptr 字段: 与对象的数据内容相关,如果是整数,直接存储数据;否则表示指向数据的指针。Redis 在 3.0 之后对值对象是字符串且长度 <=39 字节的数据,内部编码为 embstr 类型,字符串 sds(simple dynamic string,简单动态字符串) 和 redisObject 一起分配,从而只要一次内存操作即可。
- 可以使用 scan+object idletime 命令批量查询哪些键长时间未被访问,找出长时间不访问的键进行清理,可降低内存占用。
- 高并发写入场景中,在条件允许的情况下,建议字符串长度控制在 39 字节以内,减少创建 redisObject 内存分配次数,从而提高性能。
8、内存优化 - 缩减键值对象
降低 Redis 内存使用最直接的方式就是缩减键(key)和值(value)的长度。
- key 长度: 如在设计键时,在完整描述业务情况下,键值越短越好。如 user:{uid}:friends:notify:{fid} 可以简化为 u:{uid}:fs:nt:{fid}。
- value 长度:值对象缩减比较复杂,常见需求是把业务对象序列化成二进制数组放入 Redis。
- 值对象除了存储二进制数据之外,通常还会使用通用格式存储数据,比如:json、xml 等作为字符串存储在 Redis 中。这种方式优点是方便调试和跨语言,但是同样的数据相比字节数组所需的空间更大,在内存紧张的情况下,可以使用通用压缩算法压缩 json、xml 后再存入 Redis,从而降低内存占用,例如使用 GZIP 压缩后的 json 可降低约 60% 的空间。
- 当频繁压缩解压 json 等文本数据时,开发人员需要考虑压缩速度和计算开销成本,这里推荐使用 Google 的 Snappy 压缩工具,在特定的压缩率情况下效率远远高于 GZIP 等传统压缩工具,且支持所有主流语言环境。
9、内存优化 - 共享对象池
- 共享对象池是指 Redis 内部维护 [0-9999] 的整数对象池。
- 创建大量的整数类型 redisObject 存在内存开销,每个 redisObject 内部结构至少占 16 字节,甚至超过了整数自身空间消耗。- 所以 Redis 内存维护一个 [0-9999] 的整数对象池,用于节约内存。
- 除了整数值对象,其他类型如 list、hash、set、zset 内部元素也可以使用整数对象池。
- 因此开发中在满足需求的前提下,尽量使用整数对象以节省内存。
整数对象池在 Redis 中通过变量 REDIS_SHARED_INTEGERS 定义,不能通过配置修改。可以通过 object refcount 命令查看对象引用数验证是否启用整数对象池技术。
// 设置键foo等于100时,直接使用共享池内整数对象,因此引用数是2,再设置键bar等于100时,引用数又变为3
redis> set foo 100
OK
redis> object refcount foo
(integer) 2
redis> set bar 100
OK
redis> object refcount bar
(integer) 3
需要注意的是对象池并不是只要存储 [0-9999] 的整数就可以工作。当设置 maxmemory 并启用 LRU 相关淘汰策略如:volatile-lru,allkeys-lru 时,Redis 禁止使用共享对象池。
-
为什么开启 maxmemory 和 LRU 淘汰策略后对象池无效?
- LRU 算法需要获取对象最后被访问时间,以便淘汰最长未访问数据,每个对象最后访问时间存储在 redisObject 对象的 lru 字段。对象共享意味着多个引用共享同一个 redisObject,这时 lru 字段也会被共享,导致无法获取每个对象的最后访问时间。如果没有设置 maxmemory,直到内存被用尽 Redis 也不会触发内存回收,所以共享对象池可以正常工作。
- 综上所述,共享对象池与 maxmemory+LRU 策略冲突,使用时需要注意。对于 ziplist 编码的值对象,即使内部数据为整数也无法使用共享对象池,因为 ziplist 使用压缩且内存连续的结构,对象共享判断成本过高,
-
为什么只有整数对象池?
- 首先整数对象池复用的几率最大,其次对象共享的一个关键操作就是判断相等性,Redis 之所以只有整数对象池,是因为整数比较算法时间复杂度为 O(1),只保留一万个整数为了防止对象池浪费。如果是字符串判断相等性,时间复杂度变为 O(n),特别是长字符串更消耗性能(浮点数在 Redis 内部使用字符串存储)。对于更复杂的数据结构如 hash、list 等,相等性判断需要 O(n^2)。对于单线程的 Redis 来说,这样的开销显然不合理,因此 Redis 只保留整数共享对象池。
10、内存优化 - 字符串优化
所有的键都是字符串类型,值对象数据除了整数之外都使用字符串存储。
1)字符串结构
- Redis 没有采用原生 C 语言的字符串类型而是自己实现了字符串结构,内部简单动态字符串(simple dynamic string,SDS)。
- Redis 自身实现的字符串结构有如下特点:
- O(1)时间复杂度获取:字符串长度、已用长度、未用长度。
- 可用于保存字节数组,支持安全的二进制数据存储。
- 内部实现空间预分配机制,降低内存再分配次数。
- 惰性删除机制,字符串缩减后的空间不释放,作为预分配空间保留。、
2)预分配机制
- 因为字符串(SDS)存在预分配机制,日常开发中要小心预分配带来的内存浪费。
- 字符串之所以采用预分配的方式是防止修改操作需要不断重分配内存和字节数据拷贝。但同样也会造成内存的浪费。字符串预分配每次并不都是翻倍扩容,空间预分配规则如下:
- 第一次创建 len 属性等于数据实际大小,free 等于 0 ,不做预分配。
- 修改后如果已有 free 空间不够且数据小于 1M,每次预分配一倍容量。如原有 len=60byte,free=0,再追加 60byte ,预分配 120byte,总占用空间:60byte+60byte+120byte+1byte。
- 修改后如果已有 free 空间不够且数据大于 1MB,每次预分配 1MB 数据。如原有 len=30MB,free=0,当再追加 100byte ,预分配 1MB,总占用空间:1MB+100byte+1MB+1byte。
- 尽量减少字符串频繁修改操作如 append、setrange,改为直接使用 set 修改字符串,降低预分配带来的内存浪费和内存碎片化。
3)字符串重构
- 字符串重构: 指不一定把每份数据作为字符串整体存储,像 json 这样的数据可以使用 hash 结构,使用二级结构存储也能帮我们节省内存。同时可以使用 hmget、hmset 命令支持字段的部分读取修改,而不用每次整体存取。
11、内存优化 - 编码优化
1)了解编码
- 编码不同将直接影响数据的内存占用和读写效率。使用 object encoding{key} 命令获取编码类型。
- type 和 encoding 对应关系如下表:
| 类型 | 编码方式 | 数据结构 |
|---|---|---|
| string | raw | 动态字符串编码 |
| string | embstr | 优化内存分配的字符串编码 |
| string | int | 整数编码 |
| hash | hashtable | 散列表编码 |
| hash | ziplist | 压缩列表编码 |
| list | linkedlist | 双向链表编码 |
| list | ziplist | 压缩列表编码 |
| list | quicklist | 3.2 版本新的列表编码 |
| set | hashtable | 散列表编码 |
| set | intset | 整数集合编码 |
| zset | skiplist | 跳跃表编码 |
| zset | ziplist | 压缩列表编码 |
2)控制编码类型
- 编码类型转换在 Redis 写入数据时自动完成,这个转换过程是不可逆的,转换规则只能从小内存编码向大内存编码转换。
- Redis 之所以不支持编码回退,主要是数据增删频繁时,数据向压缩编码转换非常消耗 CPU,得不偿失。
- hash、list、set、zset 内部编码配置如下表:
| 类型 | 编码 | 决定条件 |
|---|---|---|
| hash | ziplist | 满足所有条件:value 最大空间 (字节)<=hash-max-ziplist-valuefield 个数 <=hash-max-ziplist-entries |
| hash | hashtable | 满足任意条件:value 最大空间 (字节)>hash-max-ziplist-valuefield 个数 > hash-max-ziplist-entries |
| list | ziplist | 满足所有条件:value 最大空间 (字节)<=list-max-ziplist-value 链表长度 <=list-max-ziplist-entries |
| list | linkedlist | 满足任意条件:value 最大空间 (字节)>list-max-ziplist-value 链表长度 > list-max-ziplist-entries |
| list | quicklist | 3.2 版本新编码:废弃 list-max-ziplist-entries 和 list-max-ziplist-entries 配置使用新配置:list-max-ziplist-size:表示最大压缩空间或长度最大空间使用 [-5-1] 范围配置,默认 - 2 表示 8KB 正整数表示最大压缩长度 list-compress-depth:表示最大压缩深度,默认 = 0 不压缩 |
| set | intset | 满足所有条件:元素必须为整数集合长度 <=set-max-intlist-entries |
| set | hashtable | 满足任意条件:元素非整数类型集合长度 > hash-max-ziplist-entries |
| zset | ziplist | 满足所有条件:value 最大空间 (字节)<=zset-max-ziplist-value 有序集合长度 <=zset-max-ziplist-entries |
| zset | skiplist | 满足任意条件:value 最大空间 (字节)>zset-max-ziplist-value 有序集合长度 > zset-max-ziplist-entries |
- 可以使用 config set 命令设置编码相关参数来满足使用压缩编码的条件。
- 对于已经采用非压缩编码类型的数据如 hashtable、linkedlist 等,设置参数后即使数据满足压缩编码条件,Redis 也不会做转换,需要重启 Redis 重新加载数据才能完成转换。
3)ziplist 编码
-
ziplist 编码主要目的是为了节约内存,因此所有数据都是采用线性连续的内存结构。
-
ziplist 编码是应用范围最广的一种,可以分别作为 hash、list、zset 类型的底层数据结构实现。
-
首先从 ziplist 编码结构开始分析,它的内部结构类似这样: <…> 。
-
一个 ziplist 可以包含多个 entry(元素),每个 entry 保存具体的数据(整数或者字节数组)。
-
ziplist 结构字段含义:
- zlbytes:记录整个压缩列表所占字节长度,方便重新调整 ziplist 空间。类型是 int-32,长度为 4 字节。
- zltail:记录距离尾节点的偏移量,方便尾节点弹出操作。类型是 int-32,长度为 4 字节。
- zllen:记录压缩链表节点数量,当长度超过 216-2 时需要遍历整个列表获取长度,一般很少见。类型是 int-16,长度为 2 字节。
- entry:记录具体的节点,长度根据实际存储的数据而定。
- prev_entry_bytes_length:记录前一个节点所占空间,用于快速定位上一个节点,可实现列表反向迭代。
- encoding:标示当前节点编码和长度,前两位表示编码类型:字符串 / 整数,其余位表示数据长度。
- contents:保存节点的值,针对实际数据长度做内存占用优化。
- zlend:记录列表结尾,占用一个字节。
-
ziplist 数据结构的特点:
- 内部表现为数据紧凑排列的一块连续内存数组。
- 可以模拟双向链表结构,以 O(1)时间复杂度入队和出队。
- 新增删除操作涉及内存重新分配或释放,加大了操作的复杂性。
- 读写操作涉及复杂的指针移动,最坏时间复杂度为 O(n^2)。
- 适合存储小对象和长度有限的数据。
-
使用 ziplist 可以分别作为 hash、list、zset 数据类型实现。使用 ziplist 编码类型可以大幅降低内存占用。ziplist 实现的数据类型相比原生结构,命令操作更加耗时,不同类型耗时排序:list<hash<zset。
-
ziplist 压缩编码的性能表现跟值长度和元素个数密切相关,正因为如此 Redis 提供了 {type}-max-ziplist-value 和 {type}-max-ziplist-entries 相关参数来做控制 ziplist 编码转换。最后再次强调使用 ziplist 压缩编码的原则:追求空间和时间的平衡。
-
针对性能要求较高的场景使用 ziplist,建议长度不要超过 1000 ,每个元素大小控制在 512 字节以内。
-
命令平均耗时使用 info Commandstats 命令获取,包含每个命令调用次数、总耗时、平均耗时,单位为微秒。
3)intset 编码
-
intset 编码是集合(set)类型编码的一种,内部表现为存储有序、不重复的整数集。当集合只包含整数且长度不超过 set-max-intset-entries 配置时被启用。
-
intset 的字段结构含义:
- encoding:整数表示类型,根据集合内最长整数值确定类型,整数类型划分为三种: int-16 、int-32 、int-64。
- length:表示集合元素个数。
- contents:整数数组,按从小到大顺序保存。
-
intset 保存的整数类型根据长度划分,当保存的整数超出当前类型时,将会触发自动升级操作且升级后不再做回退。升级操作将会导致重新申请内存空间,把原有数据按转换类型后拷贝到新数组。
-
使用 intset 编码的集合时,尽量保持整数范围一致,如都在 int-16 范围内。防止个别大整数触发集合升级操作,产生内存浪费。
-
当使用整数集合时尽量使用 intset 编码。
-
使用 ziplist 编码的 hash 类型依然 比使用 hashtable 编码的集合节省大量内存。
12、内存优化 - 控制键的数量
当使用 Redis 存储大量数据时,通常会存在大量键,过多的键同样会消耗大量内存。Redis 本质是一个数据结构服务器,它为我们提供多种数据结构,如 hash、list、set、zset 等。使用 Redis 时不要进入一个误区,大量使用 get/set 这样的 API,把 Redis 当成 Memcached 使用。对于存储相同的数据内容利用 Redis 的数据结构降低外层键的数量,也可以节省大量内存。
hash 结构降低键数量分析:
- 根据键规模在客户端通过分组映射到一组 hash 对象中,如存在 100 万个键,可以映射到 1000 个 hash 中,每个 hash 保存 1000 个元素。
- hash 的 field 可用于记录原始 key 字符串,方便哈希查找。
- hash 的 value 保存原始值对象,确保不要超过 hash-max-ziplist-value 限制。
同样的数据使用 ziplist 编码的 hash 类型存储比 string 类型节约内存。节省内存量随着 value 空间的减少越来越明显。hash-ziplist 类型比 string 类型写入耗时,但随着 value 空间的减少,耗时逐渐降低。
使用 hash 重构后节省内存量这种内存优化技巧的关键点:
- hash 类型节省内存的原理是使用 ziplist 编码,如果使用 hashtable 编码方式反而会增加内存消耗。
- ziplist 长度需要控制在 1000 以内,否则由于存取操作时间复杂度在 O(n)到 O(n^2)之间,长列表会导致 CPU 消耗严重,得不偿失。
- ziplist 适合存储小对象,对于大对象不但内存优化效果不明显还会增加命令操作耗时。
- 需要预估键的规模,从而确定每个 hash 结构需要存储的元素数量。
- 根据 hash 长度和元素大小,调整 hash-max-ziplist-entries 和 hash-max-ziplist-value 参数,确保 hash 类型使用 ziplist 编码。
关于 hash 键和 field 键的设计:
- 当键离散度较高时,可以按字符串位截取,把后三位作为哈希的 field,之前部分作为哈希的键。如:key=1948480 哈希 key=group#️⃣1948,哈希 field=480。
- 当键离散度较低时,可以使用哈希算法打散键,如:使用 crc32(key)&10000 函数把所有的键映射到 “0-9999” 整数范围内,哈希 field 存储键的原始值。
- 尽量减少 hash 键和 field 的长度,如使用部分键内容。
- 客户端需要预估键的规模并设计 hash 分组规则,加重客户端开发成本。
- hash 重构后所有的键无法再使用超时(expire)和 LRU 淘汰机制自动删除,需要手动维护删除。
- 对于大对象,如 1KB 以上的对象,使用 hash-ziplist 结构控制键数量反而得不偿失。
- 对于大量小对象的存储场景,非常适合使用 ziplist 编码的 hash 类型控制键的规模来降低内存。
- 使用 ziplist+hash 优化 keys 后,如果想使用超时删除功能,开发人员可以存储每个对象写入的时间,再通过定时任务使用 hscan 命令扫描数据,找出 hash 内超时的数据项删除即可。
13、【汇总】内存优化的思路包括:
- 精简键值对大小,键值字面量精简,使用高效二进制序列化工具。
- 使用对象共享池优化小整数对象。
- 数据优先使用整数,比字符串类型更节省空间。
- 优化字符串使用,避免预分配造成的内存浪费。
- 使用 ziplist 压缩编码优化 hash、list 等结构,注重效率和空间的平衡。
- 使用 intset 编码优化整数集合。
- 使用 ziplist 编码的 hash 结构降低小对象链规模。
九、哨兵
1、Redis Sentinel 相关名词解释
Redis 从 2.8 开始正式提供了 Redis Sentinel(哨兵)架构。
| 名词 | 逻辑结构 | 物理结构 |
|---|---|---|
| 主节点 (master) | Redis 主服务 / 数据库 | 一个独立的 Redis 进程 |
| 从节点 (slave) | Redis 从服务 / 数据库 | 一个独立的 Redis 进程 |
| Redis 数据节点 | 主节点和从节点 | 主节点和从节点的进程 |
| Sentinel 节点 | 监控 Redis 数据节点 | 一个独立的 Sentinel 进程 |
| Sentinel 节点集合 | 若干 Sentinel 节点的抽象组合 | 若干 Sentinel 节点进程 |
| Redis Sentinel | Redis 高可用实现方案 | Sentinel 节点集合和 Redis 数据节点进程 |
| 应用方 | 泛指一个或多个客户端 | 一个或者多个客户端进程或者线程 |
2、主从复制的问题
- (高可用问题) 一旦主节点出现故障,需要手动将一个从节点晋升为主节点,同时需要修改应用方的主节点地址,还需要命令其他从节点去复制新的主节点,整个过程都需要人工干预。
- (分布式问题) 主节点的写能力受到单机的限制。
- (分布式问题) 主节点的存储能力受到单机的限制。
3、Redis Sentinel 的高可用性
- 当主节点出现故障时,Redis Sentinel 能自动完成故障发现和故障转移,并通知应用方,从而实现真正的高可用。
- Redis2.6 版本提供 Redis Sentinel v1 版本,但是功能性和健壮性都有一些问题,如果想使用 Redis Sentinel 的话,建议使用 2.8 以上版本,也就是 v2 版本的 Redis Sentinel。
- Redis Sentinel 是一个分布式架构,其中包含若干个 Sentinel 节点和 Redis 数据节点,每个 Sentinel 节点会对数据节点和其余 Sentinel 节点进行监控,当它发现节点不可达时,会对节点做下线标识。如果被标识的是主节点,它还会和其他 Sentinel 节点进行 “协商”,当大多数 Sentinel 节点都认为主节点不可达时,它们会选举出一个 Sentinel 节点来完成自动故障转移的工作,同时会将这个变化实时通知给 Redis 应用方。整个过程完全是自动的,不需要人工来介入,所以这套方案很有效地解决了 Redis 的高可用问题。
这里的分布式是指:Redis 数据节点、Sentinel 节点集合、客户端分布在多个物理节点的架构,不要与 Redis Cluster 分布式混淆。
Redis Sentinel 与 Redis 主从复制模式只是多了若干 Sentinel 节点,所以 Redis Sentinel 并没有针对 Redis 节点做了特殊处理。从逻辑架构上看,Sentinel 节点集合会定期对所有节点进行监控,特别是对主节点的故障实现自动转移。
Redis Sentinel 具有以下几个功能:
- 监控:Sentinel 节点会定期检测 Redis 数据节点、其余 Sentinel 节点是否可达。
- 通知:Sentinel 节点会将故障转移的结果通知给应用方。
- 主节点故障转移:实现从节点晋升为主节点并维护后续正确的主从关系。
- 配置提供者:在 Redis Sentinel 结构中,客户端在初始化的时候连接的是 Sentinel 节点集合,从中获取主节点信息。
Redis Sentinel 包含了若个 Sentinel 节点,这样做也带来了两个好处:
- 对于节点的故障判断是由多个 Sentinel 节点共同完成,这样可以有效地防止误判。
- Sentinel 节点集合是由若干个 Sentinel 节点组成的,这样即使个别 Sentinel 节点不可用,整个 Sentinel 节点集合依然是健壮的。
但是 Sentinel 节点本身就是独立的 Redis 节点,只不过它们有一些特殊,它们不存储数据,只支持部分命令。
4、部署 Redis 数据节点
1、启动主节点
配置:
redis-6379.conf
port 6379
daemonize yes
logfile "6379.log"
dbfilename "dump-6379.rdb"
dir "/opt/soft/redis/data/"
启动主节点:
redis-server redis-6379.conf
确认是否启动:
$ redis-cli -h 127.0.0.1 -p 6379 ping
PONG
2、启动两个从节点
配置:
redis-6380.conf
port 6380
daemonize yes
logfile "6380.log"
dbfilename "dump-6380.rdb"
dir "/opt/soft/redis/data/"
slaveof 127.0.0.1 6379
启动两个从节点:
redis-server redis-6380.conf
redis-server redis-6381.conf
验证:
$ redis-cli -h 127.0.0.1 -p 6380 ping
PONG
$ redis-cli -h 127.0.0.1 -p 6381 ping
PONG
3、确认主从关系
主节点的视角:
$ redis-cli -h 127.0.0.1 -p 6379 info replication
# Replication
role:master
connected_slaves:2
slave0:ip=127.0.0.1,port=6380,state-online,offset=281,lag=1
slave1:ip=127.0.0.1,port=6381,state-online,offset=281,lag=1
从节点的视角:
info replication
role:slave
master_host:127.0.0.1
master_port:6379
master_link_status:up
. . . . . . . . . . . . . . . . .
5、部署 Sentinel 节点
1、配置Sentinel节点(以配置sentinel-1节点为例)
redis-sentinel-26379.conf
port 26379
daemonize yes
logfile "26379.log"
dir /opt/soft/redis/data
sentinel monitor mymaster 127.0.0.1 6379 2
sentinel down-after-milliseconds mymaster 30000
sentinel parallel-syncs mymaster 1
sentinel failover-timeout mymaster 180000
2、启动Sentinel节点
Sentinel节点的启动方法有两种(两种方法本质上是一样的):
方法一,使用redis-sentinel命令:
redis-sentinel redis-sentinel-26379.conf
方法二,使用redis-server命令加--sentinel参数:
redis-server redis-sentinel-26379.conf --sentinel
3、确认
// 从下面info的Sentinel片段来看,Sentinel节点找到了主节点127.0.0.1:6379,发现了它的两个从节点,同时发现Redis Sentinel一共有3个Sentinel节点。
$ redis-cli -h 127.0.0.1 -p 26379 info Sentinel
# Sentinel
sentinel_masters:1
sentinel_tilt:0
sentinel_running_scripts:0
sentinel_scripts_queue_length:0
master0:name=mymaster,status=ok,address=127.0.0.1:6379,slaves=2,sentinels=3
- Sentinel 节点的默认端口是 26379。
- sentinel monitor mymaster 127.0.0.1 6379 2 配置代表 sentinel- 1 节点需要监控 127.0.0.1:6379 这个主节点,2 代表判断主节点失败至少需要 2 个 Sentinel 节点同意,mymaster 是主节点的别名。
- Sentinel 节点本质上是一个特殊的 Redis 节点,所以也可以通过 info 命令来查询它的相关信息.
- Sentinel 节点能够彼此感知到对方,同时能够感知到 Redis 数据节点。
- 生产环境中建议 Redis Sentinel 的所有节点应该分布在不同的物理机上。
- Redis Sentinel 中的数据节点和普通的 Redis 数据节点在配置上没有任何区别,只不过是添加了一些 Sentinel 节点对它们进行监控。
6、配置优化
Redis 安装目录下有一个 sentinel.conf,是默认的 Sentinel 节点配置文件。
1)配置说明和优化
port 26379
dir /opt/soft/redis/data
sentinel monitor mymaster 127.0.0.1 6379 2
sentinel down-after-milliseconds mymaster 30000
sentinel parallel-syncs mymaster 1
sentinel failover-timeout mymaster 180000
#sentinel auth-pass <master-name> <password>
#sentinel notification-script <master-name> <script-path>
#sentinel client-reconfig-script <master-name> <script-path>
1、sentinel monitor
// 本配置说明Sentinel节点要监控的是一个名字叫做<master-name>,ip地址和端口为<ip><port>的主节点。<quorum>代表要判定主节点最终不可达所需要的票数。
sentinel monitor <master-name> <ip> <port> <quorum>
2、sentinel down-after-milliseconds
sentinel down-after-milliseconds <master-name> <times>
3、sentinel parallel-syncs
sentinel parallel-syncs <master-name> <nums>
4、sentinel failover-timeout
sentinel failover-timeout <master-name> <times>
5、sentinel auth-pass
sentinel auth-pass <master-name> <password>
6、sentinel notification-script
sentinel notification-script <master-name> <script-path>
7、sentinel client-reconfig-script
sentinel client-reconfig-script <master-name> <script-path>
当故障转移结束,每个Sentinel节点会将故障转移的结果发送给对应的脚本,具体参数如下:
<master-name> <role> <state> <from-ip> <from-port> <to-ip> <to-port>
- <master-name>:主节点名。
- <role>:Sentinel节点的角色,分别是leader和observer,leader代表当前Sentinel节点是领导者,是它进行的故障转移; observer是其余Sentinel节点。
- <from-ip>:原主节点的ip地址。
- <from-port>:原主节点的端口。
- <to-ip>:新主节点的ip地址。
- <to-port>:新主节点的端口。
- port 和 dir 分别代表 Sentinel 节点的端口和工作目录。
- 实际上 Sentinel 节点会对所有节点进行监控,但是在 Sentinel 节点的配置中没有看到有关从节点和其余 Sentinel 节点的配置,那是因为 Sentinel 节点会从主节点中获取有关从节点以及其余 Sentinel 节点的相关信息。
- 当所有节点启动后,配置文件中的内容发生了变化,体现在三个方面:
- Sentinel 节点自动发现了从节点、其余 Sentinel 节点。
- 去掉了默认配置,例如 parallel-syncs、failover-timeout 参数。
- 添加了配置纪元相关参数。
- 参数用于故障发现和判定,例如将 quorum 配置为 2,代表至少有 2 个 Sentinel 节点认为主节点不可达,那么这个不可达的判定才是客观的。对于设置的越小,那么达到下线的条件越宽松,反之越严格。一般建议将其设置为 Sentinel 节点的一半加 1。
- 同时还与 Sentinel 节点的领导者选举有关,至少要有 max(quorum,num(sentinels)/2+1)个 Sentinel 节点参与选举,才能选出领导者 Sentinel ,从而完成故障转移。
- 每个 Sentinel 节点都要通过定期发送 ping 命令来判断 Redis 数据节点和其余 Sentinel 节点是否可达,如果超过了 down-after-milliseconds 配置的时间且没有有效的回复,则判定节点不可达,(单位为毫秒)就是超时时间。这个配置是对节点失败判定的重要依据。
- down-after-milliseconds 越大,代表 Sentinel 节点对于节点不可达的条件越宽松,反之越严格。条件宽松有可能带来的问题是节点确实不可达了,那么应用方需要等待故障转移的时间越长,也就意味着应用方故障时间可能越长。条件严格虽然可以及时发现故障完成故障转移,但是也存在一定的误判率。
- down-after-milliseconds 虽然以为参数,但实际上对 Sentinel 节点、主节点、从节点的失败判定同时有效。
- 当 Sentinel 节点集合对主节点故障判定达成一致时,Sentinel 领导者节点会做故障转移操作,选出新的主节点,原来的从节点会向新的主节点发起复制操作,parallel-syncs 就是用来限制在一次故障转移之后,每次向新的主节点发起复制操作的从节点个数。如果这个参数配置的比较大,那么多个从节点会向新的主节点同时发起复制操作,尽管复制操作通常不会阻塞主节点,但是同时向主节点发起复制,必然会对主节点所在的机器造成一定的网络和磁盘 IO 开销。
- failover-timeout 通常被解释成故障转移超时时间,但实际上它作用于故障转移的各个阶段:
- 选出合适从节点。
- 晋升选出的从节点为主节点。
- 命令其余从节点复制新的主节点。
- 等待原主节点恢复后命令它去复制新的主节点。
- failover-timeout 的作用具体体现在四个方面:
- 如果 Redis Sentinel 对一个主节点故障转移失败,那么下次再对该主节点做故障转移的起始时间是 failover-timeout 的 2 倍。
- 在上述第二阶段时,如果 Sentinel 节点向上述第一阶段选出来的从节点执行 slaveof no one 一直失败(例如该从节点此时出现故障),当此过程超过 failover-timeout 时,则故障转移失败。
- 在上述第二阶段如果执行成功,Sentinel 节点还会执行 info 命令来确认上述第一阶段选出来的节点确实晋升为主节点,如果此过程执行时间超过 failover-timeout 时,则故障转移失败。
- 如果上述第三阶段执行时间超过了 failover-timeout(不包含复制时间),则故障转移失败。注意即使超过了这个时间,Sentinel 节点也会最终配置从节点去同步最新的主节点。
- 如果 Sentinel 监控的主节点配置了密码,sentinel auth-pass 配置通过添加主节点的密码,防止 Sentinel 节点对主节点无法监控。
- sentinel notification-script 的作用是在故障转移期间,当一些警告级别的 Sentinel 事件发生(指重要事件,例如 - sdown:客观下线、-odown:主观下线)时,会触发对应路径的脚本,并向脚本发送相应的事件参数。
- sentinel client-reconfig-script 的作用是在故障转移结束后,会触发对应路径的脚本,并向脚本发送故障转移结果的相关参数。
- 有关 sentinel notification-script 和 sentinel client-reconfig-script 有几点需要 注意:
- 必须有可执行权限。
- 开头必须包含 shell 脚本头(例如 #!/bin/sh),否则事件发生时 Redis 将无法执行脚本产生错误。
- Redis 规定脚本的最大执行时间不能超过 60 秒,超过后脚本将被杀掉。
- 如果 shell 脚本以 exit 1 结束,那么脚本稍后重试执行。如果以 exit 2 或者更高的值结束,那么脚本不会重试。正常返回值是 exit 0。
- 如果需要运维的 Redis Sentinel 比较多,建议不要使用这种脚本的形式来进行通知,这样会增加部署的成本。
2)如何监控多个主节点
Redis Sentinel 可以同时监控多个主节点。只需要指定多个 masterName 来区分不同的主节点即可。
3)调整配置
和普通的 Redis 数据节点一样,Sentinel 节点也支持动态地设置参数,而且和普通的 Redis 数据节点一样并不是支持所有的参数:
sentinel set <param> <value>
sentinel set 命令支持的参数如下表:
| 参数 | 使用方法 |
|---|---|
| quorum | sentinel set mymaster quorum 2 |
| down-after-milliseconds | sentinel set mymaster down-after-milliseconds 30000 |
| failover-timout | sentinel set mymaster failover-timout 360000 |
| parellel-syncs | sentinel set mymaster parellel-syncs 2 |
| notification-script | sentinel set mymaster notification-script /opt/xx.sh |
| client-reconfig-script | sentinel set mymaster client-reconfig-script /opt/yy.sh |
| auth-pass | sentinel set mymaster auth-pass masterPassword |
- sentinel set 命令只对当前 Sentinel 节点有效。
- sentinel set 命令如果执行成功会立即刷新配置文件,这点和 Redis 普通数据节点设置配置需要执行 config rewrite 刷新到配置文件不同。
- 建议所有 Sentinel 节点的配置尽可能一致,这样在故障发现和转移时比较容易达成一致。
- 上表中为 sentinel set 支持的参数,具体可以参考源码中的 sentinel.c 的 sentinelSetCommand 函数。
- Sentinel 对外不支持 config 命令。
7、部署技巧
- Sentinel 节点不应该部署在一台物理 “机器” 上。
- 部署至少三个且奇数个的 Sentinel 节点。
- 3 个以上是通过增加 Sentinel 节点的个数提高对于故障判定的准确性,因为领导者选举需要至少一半加 1 个节点,奇数个节点可以在满足该条件的基础上节省一个节点。
- 只有一套 Sentinel,还是每个主节点配置一套 Sentinel?
- 方案一:一套 Sentinel,很明显这种方案在一定程度上降低了维护成本,因为只需要维护固定个数的 Sentinel 节点,集中对多个 Redis 数据节点进行管理就可以了。但是这同时也是它的缺点,如果这套 Sentinel 节点集合出现异常,可能会对多个 Redis 数据节点造成影响。还有如果监控的 Redis 数据节点较多,会造成 Sentinel 节点产生过多的网络连接,也会有一定的影响。
- 方案二:多套 Sentinel,显然这种方案的优点和缺点和上面是相反的,每个 Redis 主节点都有自己的 Sentinel 节点集合,会造成资源浪费。但是优点也很明显,每套 Redis Sentinel 都是彼此隔离的。
- 如果 Sentinel 节点集合监控的是同一个业务的多个主节点集合,那么使用方案一、否则一般建议采用方案二。
8、API
下面以Sentinel节点集合监控着两组主从模式的Redis数据节点为例进行说明:
1、sentinel masters:展示所有被监控的主节点状态以及相关的统计信息。
127.0.0.1:26379> sentinel masters
1) 1) "name"
2) "mymaster-2"
3) "ip"
4) "127.0.0.1"
5) "port"
6) "6382"
. . . . . . . . .忽略 . . . . . . . . . . . .
2) 1) "name"
2) "mymaster-1"
3) "ip"
4) "127.0.0.1"
5) "port"
6) "6379"
. . . . . . . . .忽略 . . . . . . . . . . . .
2、sentinel master<master name>:展示指定<master name>的主节点状态以及相关的统计信息。
127.0.0.1:26379> sentinel master mymaster-1
1) "name"
2) "mymaster-1"
3) "ip"
4) "127.0.0.1"
5) "port"
6) "6379"
. . . . . . . . .忽略 . . . . . . . . . . . .
3、sentinel slaves<master name>:展示指定<master name>的从节点状态以及相关的统计信息。
127.0.0.1:26379> sentinel slaves mymaster-1
1) 1) "name"
2) "127.0.0.1:6380"
3) "ip"
4) "127.0.0.1"
5) "port"
6) "6380"
. . . . . . . . .忽略 . . . . . . . . . . . .
2) 1) "name"
2) "127.0.0.1:6381"
3) "ip"
4) "127.0.0.1"
5) "port"
6) "6381"
. . . . . . . . .忽略 . . . . . . . . . . . .
4、sentinel sentinels<master name>:展示指定<master name>的Sentinel节点集合(不包含当前Sentinel节点)
127.0.0.1:26379> sentinel sentinels mymaster-1
1) 1) "name"
2) "127.0.0.1:26380"
3) "ip"
4) "127.0.0.1"
5) "port"
6) "26380"
. . . . . . . . .忽略 . . . . . . . . . . . .
2) 1) "name"
2) "127.0.0.1:26381"
3) "ip"
4) "127.0.0.1"
5) "port"
6) "26381"
. . . . . . . . .忽略 . . . . . . . . . . . .
5、sentinel get-master-addr-by-name <master name>:返回指定<master name>主节点的IP地址和端口
127.0.0.1:26379> sentinel get-master-addr-by-name mymaster-1
1) "127.0.0.1"
2) "6379"
6、sentinel reset <pattern>:当前Sentinel节点对符合<pattern>(通配符风格)主节点的配置进行重置,包含清除主节点的相关状态(例如故障转移),重新发现从节点和Sentinel节点。
127.0.0.1:26379> sentinel reset mymaster-1 // sentinel-1节点对mymaster-1节点重置状态
(integer) 1
7、sentinel failover <master name>:对指定<master name>主节点进行强制故障转移(没有和其他Sentinel节点“协商”),当故障转移完成后,其他Sentinel节点按照故障转移的结果更新自身配置。
8、sentinel ckquorum <master name>:检测当前可达的Sentinel节点总数是否达到<quorum>的个数
127.0.0.1:26379> sentinel ckquorum mymaster-1
OK 3 usable Sentinels. Quorum and failover authorization can be reached
9、sentinel flushconfig:将Sentinel节点的配置强制刷到磁盘上
10、sentinel remove <master name>:取消当前Sentinel节点对于指定<master name>主节点的监控。这个命令仅仅对当前Sentinel节点有效。
11、sentinel monitor <master name> <ip> <port> <quorum>:这个命令和配置文件中的含义是完全一样的,只不过是通过命令的形式来完成Sentinel节点对主节点的监控。
12、sentinel set <master name>:动态修改Sentinel节点配置选项
13、sentinel is-master-down-by-addr:Sentinel节点之间用来交换对主节点是否下线的判断,根据参数的不同,还可以作为Sentinel领导者选举的通信方式。
9、Redis Sentinel 的客户端
Sentinel 节点集合具备了监控、通知、自动故障转移、配置提供者若干功能,也就是说实际上最了解主节点信息的就是 Sentinel 节点集合,而各个主节点可以通过进行标识的,所以,无论是哪种编程语言的客户端,如果需要正确地连接 Redis Sentinel,必须有 Sentinel 节点集合和 masterName 两个参数。
10、Redis Sentinel 客户端基本实现原理
实现一个 Redis Sentinel 客户端的基本步骤如下:
- 遍历 Sentinel 节点集合获取一个可用的 Sentinel 节点,后面会介绍 Sentinel 节点之间可以共享数据,所以从任意一个 Sentinel 节点获取主节点信息都是可以的。
- 通过 sentinel get-master-addr-by-name master-name 这个 API 来获取对应主节点的相关信息。
- 验证当前获取的 “主节点” 是真正的主节点,这样做的目的是为了防止故障转移期间主节点的变化。
- 保持和 Sentinel 节点集合的 “联系” ,时刻获取关于主节点的相关 “信息” 。
从上面的模型可以看出,Redis Sentinel 客户端只有在初始化和切换主节点时需要和 Sentinel 节点集合进行交互来获取主节点信息,所以在设计客户端时需要将 Sentinel 节点集合考虑成配置(相关节点信息和变化)发现服务。
11、Java 操作 Redis Sentinel
略。
12、Redis Sentinel 的基本实现原理之一——Redis Sentinel 的三个定时任务
Redis Sentinel 通过三个定时监控任务完成对各个节点发现和监控:
- 每隔 10 秒,每个 Sentinel 节点会向主节点和从节点发送 info 命令获取最新的拓扑结构。这个定时任务的作用具体可以表现在三个方面:
- 通过向主节点执行 info 命令,获取从节点的信息,这也是为什么 Sentinel 节点不需要显式配置监控从节点。
- 当有新的从节点加入时都可以立刻感知出来。
- 节点不可达或者故障转移后,可以通过 info 命令实时更新节点拓扑信息。
- 每隔 2 秒,每个 Sentinel 节点会向 Redis 数据节点的sentinel:hello 频道上发送该 Sentinel 节点对于主节点的判断以及当前 Sentinel 节点的信息,同时每个 Sentinel 节点也会订阅该频道,来了解其他 Sentinel 节点以及它们对主节点的判断,所以这个定时任务可以完成以下两个工作:
- 发现新的 Sentinel 节点:通过订阅主节点的sentinel:hello 了解其他的 Sentinel 节点信息,如果是新加入的 Sentinel 节点,将该 Sentinel 节点信息保存起来,并与该 Sentinel 节点创建连接。
- Sentinel 节点之间交换主节点的状态,作为后面客观下线以及领导者选举的依据。
- 每隔 1 秒,每个 Sentinel 节点会向主节点、从节点、其余 Sentinel 节点发送一条 ping 命令做一次心跳检测,来确认这些节点当前是否可达。这个定时任务是节点失败判定的重要依据。
13、Redis Sentinel 的基本实现原理之二——主观下线和客观下线
1)主观下线
- 上面第三个定时任务,每个 Sentinel 节点会每隔 1 秒对主节点、从节点、其他 Sentinel 节点发送 ping 命令做心跳检测,当这些节点超过 down-after-milliseconds 没有进行有效回复,Sentinel 节点就会对该节点做失败判定,这个行为叫做主观下线。
2)客观下线
- 当 Sentinel 主观下线的节点是主节点时,该 Sentinel 节点会通过 sentinel is-master-down-by-addr 命令向其他 Sentinel 节点询问对主节点的判断,当超过个数,Sentinel 节点认为主节点确实有问题,这时该 Sentinel 节点会做出客观下线的决定,这样客观下线的含义是比较明显了,也就是大部分 Sentinel 节点都对主节点的下线做了同意的判定,那么这个判定就是客观的。
- 从节点、Sentinel 节点在主观下线后,没有后续的故障转移操作。
sentinel is-master-down-by-addr 命令的使用方法如下:
sentinel is-master-down-by-addr <ip> <port> <current_epoch> <runid>
- 请求参数:
- ip:主节点 IP。
- port:主节点端口。
- current_epoch:当前配置纪元。
- runid:此参数有两种类型,不同类型决定了此 API 作用的不同。
- 当 runid 等于 “*” 时,作用是 Sentinel 节点直接交换对主节点下线的判定。
- 当 runid 等于当前 Sentinel 节点的 runid 时,作用是当前 Sentinel 节点希望目标 Sentinel 节点同意自己成为领导者的请求。
- 返回结果:
- down state:目标 Sentinel 节点对于主节点的下线判断,1 是下线,0 是在线。
- leader_runid:当 leader_runid 等于 “*” 时,代表返回结果是用来做主节点是否不可达,当 leader_runid 等于具体的 runid,代表目标节点同意 runid 成为领导者。
- leader_epoch:领导者纪元。
14、Redis Sentinel 的基本实现原理之三——领导者 Sentinel 节点选举
Redis 使用了 Raft 算法实现领导者选举,因为 Raft 算法相对比较抽象和复杂,所以这里给出一个 Redis Sentinel 进行领导者选举的大致思路:
- 每个在线的 Sentinel 节点都有资格成为领导者,当它确认主节点主观下线时候,会向其他 Sentinel 节点发送 sentinel is-master-down-by-addr 命令,要求将自己设置为领导者。
- 收到命令的 Sentinel 节点,如果没有同意过其他 Sentinel 节点的 sentinel is-master-down-by-addr 命令,将同意该请求,否则拒绝。
- 如果该 Sentinel 节点发现自己的票数已经大于等于 max(quorum,num(sentinels)/2+1),那么它将成为领导者。
- 如果此过程没有选举出领导者,将进入下一次选举。
15、故障转移
领导者选举出的 Sentinel 节点负责故障转移,具体步骤如下:
- 在从节点列表中选出一个节点作为新的主节点,选择方法如下:
- 过滤:“不健康” (主观下线、断线)、5 秒内没有回复过 Sentinel 节点 ping 响应、与主节点失联超过 down-after-milliseconds*10 秒。
- 选择 slave-priority(从节点优先级)最高的从节点列表,如果存在则返回,不存在则继续。
- 选择复制偏移量最大的从节点(复制的最完整),如果存在则返回,不存在则继续。
- 选择 runid 最小的从节点。
- Sentinel 领导者节点会对第一步选出来的从节点执行 slaveof no one 命令让其成为主节点。
- Sentinel 领导者节点会向剩余的从节点发送命令,让它们成为新主节点的从节点,复制规则和 parallel-syncs 参数有关。
- Sentinel 节点集合会将原来的主节点更新为从节点,并保持着对其关注,当其恢复后命令它去复制新的主节点。
16、故障转移日志分析
模拟故障的方法有很多,比较典型的方法有以下几种:
- 方法一,强制杀掉对应节点的进程号,这样可以模拟出宕机的效果。
- 方法二,使用 Redis 的 debug sleep 命令,让节点进入睡眠状态,这样可以模拟阻塞的效果。
- 方法三,使用 Redis 的 shutdown 命令,模拟正常的停掉 Redis。
下表记录了 Redis Sentinel 在故障转移一些重要的事件消息对应的频道。
| 状态 | 说明 |
|---|---|
| +reset-master | 主节点被重置 |
| +slave | 一个新的从节点被发现并关联 |
| +failover-state-reconf-slaves | 故障转移进入 reconf-slaves 状态 |
| +slave-reconf-sent | 领导者 Sentinel 节点命令其他从节点复制新的主节点 |
| +slave-reconf-inprog | 从节点正在重新配置主节点的 slave,但是同步过程尚未完成 |
| +slave-reconf-done | 其余从节点完成了和新节点的同步 |
| +sentinel | 一个新的 sentinel 节点被发现并关联 |
| +sdown | 添加对某个节点被主观下线 |
| -sdown | 撤销对某个节点被主观下线 |
| +odown | 添加对某个节点被客观下线 |
| -odown | 撤销对某个节点被客观下线 |
| +new-epoch | 当前纪元被更新 |
| +try-failover | 故障转移开始 |
| +elected-leader | 选出了故障转移的 Sentinel 节点 |
| +failover-state-select-slave | 故障转移进入 select-slave 状态 (寻找合适的从节点) |
| no-good-slave | 没有找到合适的从节点 |
| selected-slave | 找到了合适的从节点 |
| failover-state-send-slaveof-noone | 故障转移进入 failover-state-send-slaveof-noone 状态 (对找到的从节点执行 slaveof no one) |
| failover-end-for-timeout | 故障转移由于超时而终止 |
| failover-end | 故障转移顺利完成 |
| switch-master | 更新主节点信息,这个是许多客户端重点关注的 |
格式如下:
<instance-type> <name> <ip> <port> @ <master-name> <master-ip> <master-port>
部署各个节点的机器时间尽量要同步,否则日志的时序性会混乱,例如可以给机器添加 NTP 服务来同步时间。
17、节点运维
1)节点下线
- 临时下线: 暂时将节点关掉,之后还会重新启动,继续提供服务。
- 永久下线: 将节点关掉后不再使用,需要做一些清理工作,如删除配置文件、持久化文件、日志文件。
- Redis Sentinel 存在多个从节点时,如果想将指定从节点晋升为主节点,可以将其他从节点的 slavepriority 配置为 0 ,但是需要注意 failover 后,将 slave-priority 调回原值。
- 需要注意的是,Sentinel 节点依然会对这些下线节点进行定期监控,这是由 Redis Sentinel 的设计思路所决定的。
2)节点上线
- 添加从节点的方法:添加 slaveof{masterIp}{masterPort} 的配置,使用 redis-server 启动即可,它将被 Sentinel 节点自动发现。
- 添加 Sentinel 节点的方法:添加 sentinel monitor 主节点的配置,使用 redis-sentinel 启动即可,它将被其余 Sentinel 节点自动发现。
- 添加主节点:因为 Redis Sentinel 中只能有一个主节点,所以不需要添加主节点,如果需要替换主节点,可以使用 Sentinel failover 手动故障转移。
3)节点配置
- Sentinel 节点配置尽可能一致,这样在判断节点故障时会更加准确。
- Sentinel 节点支持的命令非常有限,例如 config 命令是不支持的,而 Sentinel 节点也需要 dir、loglevel 之类的配置,所以尽量在一开始规划好,不过所幸 Sentinel 节点不存储数据,如果需要修改配置,重新启动即可。
- Sentinel 节点只支持如下命令:ping、sentinel、subscribe、unsubscribe、 psubscribe、punsubscribe、publish、info、role 、client、shutdown。
18、Redis Sentinel 读写分离设计思路
Redis Sentinel 在对各个节点的监控中,如果有对应事件的发生,都会发出相应的事件消息,其中和从节点变动的事件有以下几个:
- +switch-master:切换主节点(原来的从节点晋升为主节点),说明减少了某个从节点。
- +convert-to-slave:切换从节点(原来的主节点降级为从节点),说明添加了某个从节点。
- +sdown:主观下线,说明可能某个从节点可能不可用(因为对从节点不会做客观下线),所以在实现客户端时可以采用自身策略来实现类似主观下线的功能。
- +reboot:重新启动了某个节点,如果它的角色是 slave,那么说明添加了某个从节点。
所以在设计 Redis Sentinel 的从节点高可用时,只要能够实时掌握所有从节点的状态,把所有从节点看做一个资源池,无论是上线还是下线从节点,客户端都能及时感知到(将其从资源池中添加或者删除),这样从节点的高可用目标就达到了。
19、汇总
- Redis Sentinel 从 Redis2.8 版本开始才正式生产可用,之前版本生产不可用。
- 尽可能在不同物理机上部署 Redis Sentinel 所有节点。
- Redis Sentinel 中的 Sentinel 节点个数应该为大于等于 3 且最好为奇数。
- Redis Sentinel 中的数据节点与普通数据节点没有区别。
- 客户端初始化时连接的是 Sentinel 节点集合,不再是具体的 Redis 节点,但 Sentinel 只是配置中心不是代理。
- Redis Sentinel 实现读写分离高可用可以依赖 Sentinel 节点的消息通知,获取 Redis 数据节点的状态变化。
十、集群
1、概述
Redis Cluster 是 Redis 的分布式解决方案,在 3.0 版本正式推出,有效地解决了 Redis 分布式方面的需求。
Redis 在 3.0 版本之前分布式方案一般有两种:
- 客户端分区方案,优点是分区逻辑可控,缺点是需要自己处理数据路由、高可用、故障转移等问题。
- 代理方案,优点是简化客户端分布式逻辑和升级维护便利,缺点是加重架构部署复杂度和性能损耗。
现在官方为我们提供了专有的集群方案: Redis Cluster,它非常优雅地解决了 Redis 集群方面的问题。
2、数据分布理论
- 分布式数据库首先要解决把整个数据集按照分区规则映射到多个节点的问题,即把数据集划分到多个节点上,每个节点负责整体数据的一个子集。
- 常见的分区规则有哈希分区和顺序分区两种。
- Redis Cluster 采用哈希分区规则。
| 分区方式 | 特点 | 代表产品 |
|---|---|---|
| 哈希分区 | - 离散度好- 数据分布业务无关- 无法顺序访问 | Redis ClusterCassandraDynamo |
| 顺序访问 | - 离散度易倾斜- 数据分布业务相关- 可顺序访问 | BigtableHBaseHypertable |
常见的哈希分区规则有几种:
1)节点取余分区
- 使用特定的数据,如 Redis 的键或用户 ID,再根据节点数量 N 使用公式:hash(key)%N 计算出哈希值,用来决定数据映射到哪一个节点上。
- 缺点:当节点数量变化时,如扩容或收缩节点,数据节点映射关系需要重新计算,会导致数据的重新迁移。
- 优点:简单性,常用于数据库的分库分表规则,一般采用预分区的方式,提前根据数据量规划好分区数,比如划分为 512 或 1024 张表,保证可支撑未来一段时间的数据量,再根据负载情况将表迁移到其他数据库中。
- 扩容时通常采用翻倍扩容,避免数据映射全部被打乱导致全量迁移的情况。
2)一致性哈希分区
- 一致性哈希分区(Distributed Hash Table)实现思路是为系统中每个节点分配一个 token,范围一般在 0~2^32,这些 token 构成一个哈希环。数据读写执行节点查找操作时,先根据 key 计算 hash 值,然后顺时针找到第一个大于等于该哈希值的 token 节点。
- 相比节点取余最大的好处在于加入和删除节点只影响哈希环中相邻的节点,对其他节点无影响。
- 一致性哈希分区存在几个问题:
- 加减节点会造成哈希环中部分数据无法命中,需要手动处理或者忽略这部分数据,因此一致性哈希常用于缓存场景。
- 当使用少量节点时,节点变化将大范围影响哈希环中数据映射,因此这种方式不适合少量数据节点的分布式方案。
- 普通的一致性哈希分区在增减节点时需要增加一倍或减去一半节点才能保证数据和负载的均衡。
- 正因为一致性哈希分区的这些缺点,一些分布式系统采用虚拟槽对一致性哈希进行改进,比如 Dynamo 系统。
3)虚拟槽分区
- 虚拟槽分区巧妙地使用了哈希空间,使用分散度良好的哈希函数把所有数据映射到一个固定范围的整数集合中,整数定义为槽(slot)。这个范围一般远远大于节点数,比如 Redis Cluster 槽范围是 0~16383。
- 槽是集群内数据管理和迁移的基本单位。采用大范围槽的主要目的是为了方便数据拆分和集群扩展。每个节点会负责一定数量的槽。
- Redis Cluster 就是采用虚拟槽分区。
3、Redis 数据分区
数据分区是分布式存储的核心。
Redis Cluser 采用虚拟槽分区,所有的键根据哈希函数映射到 0~16383 整数槽内,计算公式:slot=CRC16(key)&16383。每一个节点负责维护一部分槽以及槽所映射的键值数据。
Redis 虚拟槽分区的特点:
- 解耦数据和节点之间的关系,简化了节点扩容和收缩难度。
- 节点自身维护槽的映射关系,不需要客户端或者代理服务维护槽分区元数据。
- 支持节点、槽、键之间的映射查询,用于数据路由、在线伸缩等场景。
4、集群功能限制
Redis 集群相对单机在功能上存在一些限制,限制如下:
- key 批量操作支持有限。如 mset、mget,目前只支持具有相同 slot 值的 key 执行批量操作。对于映射为不同 slot 值的 key 由于执行 mget、mget 等操作可能存在于多个节点上因此不被支持。
- key 事务操作支持有限。同理只支持多 key 在同一节点上的事务操作,当多个 key 分布在不同的节点上时无法使用事务功能。
- key 作为数据分区的最小粒度,因此不能将一个大的键值对象如 hash、list 等映射到不同的节点。
- 不支持多数据库空间。单机下的 Redis 可以支持 16 个数据库,集群模式下只能使用一个数据库空间,即 db0。
- 复制结构只支持一层,从节点只能复制主节点,不支持嵌套树状复制结构。
5、搭建集群
搭建集群工作需要以下三个步骤:
- 准备节点。
- 节点握手。
- 分配槽。
6、搭建集群步骤一:准备节点
集群相关配置如下,其他配置和单机模式一致即可,配置文件命名规则redis-{port}.conf
#节点端口
port 6379
# 开启集群模式
cluster enabled yes
# 节点超时时间,单位毫秒
cluster-node-timeout 15000
# 集群内部配置文件
cluster config file "nodes 6379.conf"
#cat data/nodes-6379.conf
cfb28ef1deee4e0fa78da86abe5d24566744411e 127.0.0.1:6379 myself,master - 0 0 0 co vars currentEpoch 0 lastVoteEpoch 0
127.0.0.1:6380> cluster nodes // 每个节点目前只能识别出自己的节点信息(要通过节点握手才能建立联系)。
8e41673d59c9568aa9d29fb174ce733345b3e8f1 127.0.0.1:6380 myself,master - 0 0 0 co
- Redis 集群一般由多个节点组成,节点数量至少为 6 个才能保证组成完整高可用的集群。
- 每个节点需要开启配置 cluster-enabled yes,让 Redis 运行在集群模式下。
- 建议为集群内所有节点统一目录,一般划分三个目录:conf、data、log,分别存放配置、数据和日志相关文件。把 6 个节点配置统一放在 conf 目录下。
- 第一次启动时如果没有集群配置文件,它会自动创建一份,文件名称采用 cluster-config-file 参数项控制,建议采用 node-{port}.conf 格式定义,通过使用端口号区分不同节点,防止同一机器下多个 节点彼此覆盖,造成集群信息异常。
- 如果启动时存在集群配置文件,节点会使用配置文件内容初始化集群信息。
- 集群模式的 Redis 除了原有的配置文件之外又加了一份集群配置文件。当集群内节点信息发生变化,如添加节点、节点下线、故障转移等。节点会自动保存集群状态到配置文件中。
- 需要注意的是,Redis 自动维护集群配置文件,不要手动修改,防止节点重启时产生集群信息错乱。
- 集群配置文件内容记录了集群初始状态,这里最重要的是节点 ID,它是一个 40 位 16 进制字符串,用于唯一标识集群内一个节点,之后很多集群操作都要借助于节点 ID 来完成。需要注意是,节点 ID 不同于运行 ID。节点 ID 在集群初始化时只创建一次,节点重启时会加载集群配置文件进行重用,而 Redis 的运行 ID 每次重启都会变化。
7、搭建集群步骤二:节点握手
- 节点握手是指一批运行在集群模式下的节点通过 Gossip 协议彼此通信,达到感知对方的过程。
- 节点握手是集群彼此通信的第一步,由客户端发起命令:cluster meet {ip} {port}
- cluster meet 命令是一个异步命令,执行之后立刻返回。内部发起与目标节点进行握手通信。
- cluster meet 127.0.0.1 6380 让节点 6379 和 6380 节点进行握手通信:
- 节点 6379 本地创建 6380 节点信息对象,并发送 meet 消息。
- 节点 6380 接受到 meet 消息后,保存 6379 节点信息并回复 pong 消息。
- 之后节点 6379 和 6380 彼此定期通过 ping/pong 消息进行正常的节点通信。
- 这里的 meet、ping、pong 消息是 Gossip 协议通信的载体,它的主要作用是节点彼此交换状态数据信息。
- 对节点 6379 和 6380 分别执行 cluster nodes 命令,可以看到它们彼此已经感知到对方的存在。
- 我们只需要在集群内任意节点上执行 cluster meet 命令加入新节点,握手状态会通过消息在集群内传播,这样其他节点会自动发现新节点并发起握手 流程。
- 节点建立握手之后集群还不能正常工作,这时集群处于下线状态,所有的数据读写都被禁止。
- 通过 cluster info 命令可以获取集群当前状态。
- 被分配的槽(cluster_slots_assigned)是 0 ,由于目前所有的槽没有分配到节点,因此集群无法完成槽到节点的映射。只有当 16384 个槽全部分配给节点后,集群才进入在线状态。
127.0.0.1:6379> set hello redis
(error) CLUSTERDOWN The cluster is down
127.0.0.1:6379> cluster info
cluster_state:fail
cluster_slots_assigned:0
cluster_slots_ok:0
cluster_slots_pfail:0
cluster_slots_fail:0
cluster_known_nodes:6
cluster_size:0
8、搭建集群步骤三:分配槽
// 利用bash特性批量设置槽(slots),命令如下:
redis-cli -h 127.0.0.1 p 6379 cluster addslots {0 . . .5461}
redis-cli -h 127.0.0.1 -p 6380 cluster addslots {5462 . . .10922}
redis-cli -h 127.0.0.1 -p 6381 cluster addslots {10923 . . .16383}
// 执行cluster info查看集群状态
127.0.0.1 :6379> cluster info
cluster_state:ok
cluster_slots_assigned:16384
cluster_slots_ok:16384
cluster_slots_pfail:0
cluster_slots_fail:0
cluster_known_nodes:6
cluster_size:3
cluster_current_epoch:5
cluster_my_epoch:0
cluster_stats_messages_sent:4874
cluster_stats_messages_received:4726
- Redis 集群把所有的数据映射到 16384 个槽中。每个 key 会映射为一个固定的槽,只有当节点分配了槽,才能响应和这些槽关联的键命令。
- 通过 cluster addslots 命令为节点分配槽。
- 当前集群状态是 OK,集群进入在线状态。
- 所有的槽都已经分配给节点,执行 cluster nodes 命令可以看到节点和槽的分配关系。
- 作为一个完整的集群,每个负责处理槽的节点应该具有从节点,保证当它出现故障时可以自动进行故障转移。
- 集群模式下,Reids 节点角色分为主节点和从节点。首次启动的节点和被分配槽的节点都是主节点,从节点负责复制主节点槽信息和相关的数据。
- 使用 cluster replicate {nodeId} 命令让一个节点成为从节点。其中命令执行必须在对应的从节点上执行,nodeId 是要复制主节点的节点 ID。
- 通过 cluster nodes 命令查看集群状态和复制关系。
- Redis 官方提供了 redis-trib.rb 工具方便我们快速搭建集群。
9、用 redis-trib.rb 搭建集群
redis-trib.rb 是采用 Ruby 实现的 Redis 集群管理工具。内部通过 Cluster 相关命令帮我们简化集群创建、检查、槽迁移和均衡等常见运维操作,使用之前需要安装 Ruby 依赖环境。
1)Ruby 环境准备
1、安装Ruby:
-- 下载ruby
wget https://cache.ruby-lang.org/pub/ruby/2.3/ruby-2.3.1.tar.gz
-- 安装ruby
tar xvf ruby-2.3.1.tar.gz
./configure -prefix=/usr/local/ruby
make
make install
cd /usr/local/ruby
sudo cp bin/ruby /usr/local/bin
sudo cp bin/gem /usr/local/bin
2、安装rubygem redis依赖:
wget http://rubygems.org/downloads/redis-3.3.0.gem
gem install -l redis-3.3.0.gem
gem list --check redis gem
3、安装redis-trib.rb:
sudo cp /{redis_home}/src/redis-trib.rb /usr/local/bin
4、执行redis-trib.rb命令确认环境是否正确:
# redis-trib.rb
Usage: redis-trib <command> <options> <arguments . . .>
create host1:port1 . . . hostN:portN
--replicas <arg>
check host:port
info host:port
fix host:port
--timeout <arg>
reshard host:port
--from <arg>
--to <arg>
--slots <arg>
--yes
--timeout <arg>
--pipeline <arg>
. . .忽略 . . .
- 从 redis-trib.rb 的提示信息可以看出,它提供了集群创建、检查、修复、均衡等命令行工具。
- 使用 redis-trib.rb create 命令可快速搭建集群。
2)准备节点
// 准备好节点配置并启动:
redis-server conf/redis-6481.conf
redis-server conf/redis-6482.conf
redis-server conf/redis-6483.conf
redis-server conf/redis-6484.conf
redis-server conf/redis-6485.conf
redis-server conf/redis-6486.conf
3)创建集群
# 使用redis-trib.rb create命令完成节点握手和槽分配过程,命令如下:
redis-trib.rb create --replicas 1 127.0.0.1:6481 127.0.0.1:6482 127.0.0.1:6483 127.0.0.1:6484 127.0.0.1:6485 127.0.0.1:6486
- –replicas 参数指定集群中每个主节点配备几个从节点,这里设置为 1。
- 如果部署节点使用不同的 IP 地址,redis-trib.rb 会尽可能保证主从节点不分配在同一机器下。
- 节点列表顺序用于确定主从角色,先主节点之后是从节点。
- 需要注意给 redis-trib.rb 的节点地址必须是不包含任何槽 / 数据的节点,否则会拒绝创建集群。
4)集群完整性检查
redis-trib.rb check 127.0.0.1:6481
- 集群完整性指所有的槽都分配到存活的主节点上,只要 16384 个槽中有一个没有分配给节点则表示集群不完整。
- 可以使用 redis-trib.rb check 命令检测创建的集群是否成功,check 命令只需要给出集群中任意一个节点地址就可以完成整个集群的检查工作。
10、节点通信流程
- 在分布式存储中需要提供维护节点元数据信息的机制,所谓元数据是指:节点负责哪些数据,是否出现故障等状态信息。
- 常见的元数据维护方式分为:集中式和 P2P 方式。Redis 集群采用 P2P 的 Gossip(流言)协议,Gossip 协议工作原理就是节点彼此不断通信交换信息,一段时间后所有的节点都会知道集群完整的信息。
- 通信过程说明:
- 集群中的每个节点都会单独开辟一个 TCP 通道,用于节点之间彼此通信,通信端口号在基础端口上加 10000。
- 每个节点在固定周期内通过特定规则选择几个节点发送 ping 消息。
- 接收到 ping 消息的节点用 pong 消息作为响应。
- 集群中每个节点通过一定规则挑选要通信的节点,每个节点可能知道全部节点,也可能仅知道部分节点,只要这些节点彼此可以正常通信,最终它们会达到一致的状态。当节点出故障、新节点加入、主从角色变化、槽信息变更等事件发生时,通过不断的 ping/pong 消息通信,经过一段时间后所有的节点都会知道整个集群全部节点的最新状态,从而达到集群状态同步的目的。
11、Gossip 消息
- Gossip 协议的主要职责就是信息交换。信息交换的载体就是节点彼此发送的 Gossip 消息。
- 常用的 Gossip 消息可分为: ping 消息、pong 消息、meet 消息、fail 消息等。
- meet 消息:用于通知新节点加入。消息发送者通知接收者加入到当前集群,meet 消息通信正常完成后,接收节点会加入到集群中并进行周期性的 ping、pong 消息交换。
- ping 消息:集群内交换最频繁的消息,集群内每个节点每秒向多个其他节点发送 ping 消息,用于检测节点是否在线和交换彼此状态信息。ping 消息发送封装了自身节点和部分其他节点的状态数据。
- pong 消息:当接收到 ping、meet 消息时,作为响应消息回复给发送方确认消息正常通信。pong 消息内部封装了自身状态数据。节点也可以向集群内广播自身的 pong 消息来通知整个集群对自身状态进行更新。
- fail 消息:当节点判定集群内另一个节点下线时,会向集群内广播一个 fail 消息,其他节点接收到 fail 消息之后把对应节点更新为下线状态。
- 所有的消息格式划分为:消息头和消息体。消息头包含发送节点自身状态数据,接收节点根据消息头就可以获取到发送节点的相关数据。
- 集群内所有的消息都采用相同的消息头结构 clusterMsg,它包含了发送节点关键信息,如节点 id 、槽映射、节点标识(主从角色,是否下线)等。消息体在 Redis 内部采用 clusterMsgData 结构声明。
- 消息体 clusterMsgData 定义发送消息的数据,其中 ping、meet、pong 都采用 cluster MsgDataGossip 数组作为消息体数据,实际消息类型使用消息头的 type 属性区分。每个消息体包含该节点的多个 clusterMsgDataGossip 结构数据,用于信息交换。
- 当接收到 ping、meet 消息时,接收节点会解析消息内容并根据自身的识别情况做出相应处理。
12、节点选择
- Redis 集群内节点通信采用固定频率(定时任务每秒执行 10 次)。因此节点每次选择需要通信的节点列表变得非常重要。通信节点选择过多虽然可以做到信息及时交换但成本过高。节点选择过少会降低集群内所有节点彼此信息交换频率,从而影响故障判定、新节点发现等需求的速度。因此 Redis 集群的 Gossip 协议需要兼顾信息交换实时性和成本开销。
- 消息交换的成本主要体现在单位时间选择发送消息的节点数量和每个消息携带的数据量。
1)选择发送消息的节点数量
- 集群内每个节点维护定时任务默认每秒执行 10 次,每秒会随机选取 5 个节点找出最久没有通信的节点发送 ping 消息,用于保证 Gossip 信息交换的随机性。
- 每 100 毫秒都会扫描本地节点列表,如果发现节点最近一次接受 pong 消息的时间大于 cluster_node_timeout/2 ,则立刻发送 ping 消息,防止该节点信息太长时间未更新。
- 根据以上规则得出每个节点每秒需要发送 ping 消息的数量 = 1+10*num(node.pong_received>cluster_node_timeout/2),因此 cluster_node_timeout 参数对消息发送的节点数量影响非常大。当我们的带宽资源紧张时,可以适当调大这个参数,如从默认 15 秒改为 30 秒来降低带宽占用率。过度调大 cluster_node_timeout 会影响消息交换的频率从而影响故障转移、槽信息更新、新节点发现的速度。因此需要根据业务容忍度和资源消耗进行平衡。
- 同时整个集群消息总交换量也跟节点数成正比。
2)消息数据量
- 每个 ping 消息的数据量体现在消息头和消息体中,其中消息头主要占用空间的字段是 myslots[CLUSTER_SLOTS/8],占用 2KB,这块空间占用相对固定。消息体会携带一定数量的其他节点信息用于信息交换。
- 消息体携带数据量跟集群的节点数息息相关,更大的集群每次消息通信的成本也就更高。
13、集群伸缩原理
- Redis 集群可以实现对节点的灵活上下线控制。其中原理可抽象为槽和对应数据在不同节点之间灵活移动。
- 如果希望加入 1 个节点实现集群扩容时,需要通过相关命令把一部分槽和数据迁移给新节点,因此每个节点负责的槽和数据相比之前变少了,从而达到了集群扩容的目的。
14、扩容集群
1)准备新节点
- 需要提前准备好新节点并运行在集群模式下,新节点建议跟集群内的节点配置保持一致,便于管理统一。
redis-server conf/redis-6385.conf
redis-server conf/redis-6386.conf
2)加入集群
- 新节点依然采用 cluster meet 命令加入到现有集群中。在集群内任意节点执行 cluster meet 命令让 6385 和 6386 节点加入进来。
- 集群内新旧节点经过一段时间的 ping/pong 消息通信之后,所有节点会发现新节点并将它们的状态保存到本地。
- 新节点刚开始都是主节点状态,但是由于没有负责的槽,所以不能接受任何读写操作。对于新节点的后续操作我们一般有两种选择:
- 为它迁移槽和数据实现扩容。
- 作为其他主节点的从节点负责故障转移。
- redis-trib.rb 工具也实现了为现有集群添加新节点的命令,还实现了直接添加为从节点的支持,命令见下方。内部同样采用 cluster meet 命令实现加入集群功能。
- 正式环境建议使用 redis-trib.rb add-node 命令加入新节点,该命令内部会执行新节点状态检查,如果新节点已经加入其他集群或者包含数据,则放弃集群加入操作并打印相关信息。如果我们手动执行 cluster meet 命令加入已经存在于其他集群的节点,会造成被加入节点的集群合并到现有集群的情况,从而造成数据丢失和错乱,后果非常严重,线上谨慎操作。
127.0.0.1:6379> cluster meet 127.0.0.1 6385
127.0.0.1:6379> cluster meet 127.0.0.1 6386
redis-trib.rb add-node new_host:new_port existing_host:existing_port --slave --master-id <arg>
redis-trib.rb add-node 127.0.0.1:6385 127.0.0.1:6379
redis-trib.rb add-node 127.0.0.1:6386 127.0.0.1:6379
3)迁移槽和数据
- 加入集群后需要为新节点迁移槽和相关数据,槽在迁移过程中集群可以正常提供读写服务,迁移过程是集群扩容最核心的环节。
- 槽迁移计划:槽是 Redis 集群管理数据的基本单位,首先需要为新节点制定槽的迁移计划,确定原有节点的哪些槽需要迁移到新节点。迁移计划需要确保每个节点负责相似数量的槽,从而保证各节点的数据均匀。
- 迁移数据:数据迁移过程是逐个槽进行的,每个槽数据迁移的流程说明如下:
- 对目标节点发送 cluster setslot {slot} importing {sourceNodeId} 命令,让目标节点准备导入槽的数据。
- 对源节点发送 cluster setslot {slot} migrating {targetNodeId} 命令,让源节点准备迁出槽的数据。
- 源节点循环执行 cluster getkeysinslot {slot} {count}命令,获取 count 个属于槽 {slot} 的键。
- 在源节点上执行 migrate {targetIp}{targetPort}""0{timeout}keys {keys…} 命令,把获取的键通过流水线(pipeline)机制批量迁移到目标节点,批量迁移版本的 migrate 命令在 Redis3.0.6 以上版本提供,之前的 migrate 命令只能单个键迁移。对于大量 key 的场景,批量键迁移将极大降低节点之间网络 IO 次数。
- 重复执行步骤 3)和步骤 4)直到槽下所有的键值数据迁移到目标节点。
- 向集群内所有主节点发送 cluster setslot {slot} node {targetNodeId} 命令,通知槽分配给目标节点。为了保证槽节点映射变更及时传播,需要遍历发送给所有主节点更新被迁移的槽指向新节点。
- 添加从节点:使用 cluster replicate {masterNodeId} 命令为主节点添加对应从节点,注意在集群模式下 slaveof 添加从节点操作不再支持。从节点内部除了对主节点发起全量复制之外,还需要更新本地节点的集群相关状态。
根据以上迁移数据流程,手动使用命令把源节点6379负责的槽4096迁移到目标节点6385中,流程如下:
1、目标节点准备导入槽4096数据:
127.0.0.1:6385> cluster setslot 4096 importing cfb28ef1deee4e0fa78da86abe5d24566
OK
确认槽4096导入状态开启:
127.0.0.1:6385> cluster nodes
1a205dd8b2819a00dd1e8b6be40a8e2abe77b756 127.0.0.1:6385 myself,master - 0 0 7 co [4096 < cfb28ef1deee4e0fa78da86abe5d24566744411e]
2、源节点准备导出槽4096数据:
127.0.0.1:6379>cluster setslot 4096 migrating 1a205dd8b2819a00dd1e8b6be40a8e2abe
OK
确认槽4096导出状态开启:
127.0.0.1:6379> cluster nodes
cfb28ef1deee4e0fa78da86abe5d24566744411e 127.0.0.1:6379 myself,master - 0 0 0 co 0-5461 [4096->-1a205dd8b2819a00dd1e8b6be40a8e2abe77b756]
3、批量获取槽4096对应的键,这里我们获取到3个处于该槽的键:
127.0.0.1:6379> cluster getkeysinslot 4096 100
1) "key:test:5028"
2) "key:test:68253"
3) "key:test:79212"
确认这三个键是否存在于源节点:
127.0.0.1:6379>mget key:test:5028 key:test:68253 key:test:79212
1) "value:5028"
2) "value:68253"
3) "value:79212"
批量迁移这3个键,migrate命令保证了每个键迁移过程的原子性:
127.0.0.1:6379> migrate 127.0.0.1 6385 "" 0 5000 keys key:test:5028 key:test:682 key:test:79212
继续查询这三个键,发现已经不在源节点中,Redis返回ASK转向错误,ASK转向负责引导客户端找到数据所在的节点:
127.0.0.1:6379> mget key:test:5028 key:test:68253 key:test:79212
(error) ASK 4096 127.0 .0.1:6385
通知所有主节点槽4096指派给目标节点6385:
127.0.0.1:6379> cluster setslot 4096 1a205dd8b2819a00dd1e8b6be40a8e2abe77b7
127.0.0.1:6380> cluster setslot 4096 1a205dd8b2819a00dd1e8b6be40a8e2abe77b7
127.0.0.1:6381> cluster setslot 4096 1a205dd8b2819a00dd1e8b6be40a8e2abe77b7
127.0.0.1:6385> cluster setslot 4096 1a205dd8b2819a00dd1e8b6be40a8e2abe77b7
确认源节点6379不再负责槽4096改为目标节点6385负责:
127.0.0.1:6379> cluster nodes
cfb28ef1deee4e0fa78da86abe5d24566744411e 127.0.0.1:6379 myself,master - 0 0 0 co
0-4095 4097-5461
1a205dd8b2819a00dd1e8b6be40a8e2abe77b756 127.0.0.1:6385 master - 0 146971801107
connected 4096
实际操作槽迁移过程时肯定涉及大量槽并且每个槽对应非常多的键。因此 redis-trib 提供了槽重分片功能,命令如下:
redis-trib.rb reshard host:port --from <arg> --to <arg> --slots <arg> --yes --t <arg> --pipeline <arg>
参数说明:
- host:port:必传参数,集群内任意节点地址,用来获取整个集群信息。
- –from:制定源节点的 id,如果有多个源节点,使用逗号分隔,如果是 all 源节点变为集群内所有主节点,在迁移过程中提示用户输入。
- –to:需要迁移的目标节点的 id,目标节点只能填写一个,在迁移过程中提示用户输入。
- –slots:需要迁移槽的总数量,在迁移过程中提示用户输入。
- –yes:当打印出 reshard 执行计划时,是否需要用户输入 yes 确认后再执行 reshard。
- –timeout:控制每次 migrate 操作的超时时间,默认为 60000 毫秒。
- –pipeline:控制每次批量迁移键的数量,默认为 10。
reshard 命令简化了数据迁移的工作量,其内部针对每个槽的数据迁移同样使用之前的流程。
由于槽用于 hash 运算本身顺序没有意义,因此无须强制要求节点负责槽的顺序性。迁移之后建议使用 redis-trib.rb rebalance 命令检查节点之间槽的均衡性。
15、收缩集群
安全下线节点的流程说明:
- 首先需要确定下线节点是否有负责的槽,如果是,需要把槽迁移到其他节点,保证节点下线后整个集群槽节点映射的完整性。
- 当下线节点不再负责槽或者本身是从节点时,就可以通知集群内其他节点忘记下线节点,当所有的节点忘记该节点后可以正常关闭。
1)下线迁移槽
- 下线节点需要把自己负责的槽迁移到其他节点,原理与之前节点扩容的迁移槽过程一致。
- 收缩正好和扩容迁移方向相反。
- 下线节点槽迁出完成后,剩下的步骤需要让集群忘记该节点。
2)忘记节点
- 由于集群内的节点不停地通过 Gossip 消息彼此交换节点状态,因此需要通过一种健壮的机制让集群内所有节点忘记下线的节点。也就是说让其他节点不再与要下线节点进行 Gossip 消息交换。Redis 提供了 cluster forget{downNodeId} 命令实现该功能。
- 当节点接收到 cluster forget{down NodeId} 命令后,会把 nodeId 指定的节点加入到禁用列表中,在禁用列表内的节点不再发送 Gossip 消息。
- 禁用列表有效期是 60 秒,超过 60 秒节点会再次参与消息交换。也就是说当第一次 forget 命令发出后,我们有 60 秒的时间让集群内的所有节点忘记下线节点。
- 线上操作不建议直接使用 cluster forget 命令下线节点,需要跟大量节点命令交互,实际操作起来过于繁琐并且容易遗漏 forget 节点。建议使用 redis-trib.rb del-node {host:port}{downNodeId} 命令。
- 当下线主节点具有从节点时需要把该从节点指向到其他主节点,因此对于主从节点都下线的情况,建议先下线从节点再下线主节点,防止不必要的全量复制。
16、请求路由——请求重定向
- Redis 集群对客户端通信协议做了比较大的修改,为了追求性能最大化,并没有采用代理的方式而是采用客户端直连节点的方式。因此对于希望从单机切换到集群环境的应用需要修改客户端代码。
- 在集群模式下,Redis 接收任何键相关命令时首先计算键对应的槽,再根据槽找出所对应的节点,如果节点是自身,则处理键命令;否则回复 MOVED 重定向错误,通知客户端请求正确的节点。这个过程称为 MOVED 重定向。
- 可以借助 cluster keyslot{key} 命令返回 key 所对应的槽。
- 重定向信息包含了键所对应的槽以及负责该槽的节点地址,根据这些信息客户端就可以向正确的节点发起请求。
- 使用 redis-cli 命令时,可以加入 - c 参数支持自动重定向,简化手动发起重定向操作。
- redis-cli 自动帮我们连接到正确的节点执行命令,这个过程是在 redis-cli 内部维护,实质上是 client 端接到 MOVED 信息之后再次发起请求,并不在 Redis 节点中完成请求转发。
- 节点对于不属于它的键命令只回复重定向响应,并不负责转发。
- 正因为集群模式下把解析发起重定向的过程放到客户端完成,所以集群客户端协议相对于单机有了很大的变化。
- 键命令执行步骤主要分两步:计算槽,查找槽所对应的节点。
127.0.0.1:6379> cluster keyslot key:test:1
(integer) 5191
127.0.0.1:6379> cluster nodes
cfb28ef1deee4e0fa78da86abe5d24566744411e 127.0.0.1:6379 myself,master
1366-4095 4097-5461 12288-13652
127.0.0.1:6379> set key:test:2 value-2
(error) MOVED 9252 127.0.0.1:6380
127.0.0.1:6379> cluster keyslot key:test:2
(integer) 9252
1)计算槽
- Redis 首先需要计算键所对应的槽。根据键的有效部分使用 CRC16 函数计算出散列值,再取对 16383 的余数,使每个键都可以映射到 0~16383 槽范围内。
- 如果键内容包含 {和} 大括号字符,则计算槽的有效部分是括号内的内容;否则采用键的全内容计算槽。其中键内部使用大括号包含的内容又叫做 hash_tag,它提供不同的键可以具备相同 slot 的功能,常用于 Redis IO 优化。例如在集群模式下使用 mget 等命令优化批量调用时,键列表必须具有相同的 slot,否则会报错。这时可以利用 hash_tag 让不同的键具有相同的 slot 达到优化的目的。
- Pipeline 同样可以受益于 hash_tag,由于 Pipeline 只能向一个节点批量发送执行命令,而相同 slot 必然会对应到唯一的节点,降低了集群使用 Pipeline 的门槛。
2)槽节点查找
- Redis 计算得到键对应的槽后,需要查找槽所对应的节点。集群内通过消息交换每个节点都会知道所有节点的槽信息,内部保存在 clusterState 结构中。
- 根据 MOVED 重定向机制,客户端可以随机连接集群内任一 Redis 获取键所在节点,这种客户端又叫 Dummy(傀儡)客户端,它优点是代码实现简单,对客户端协议影响较小,只需要根据重定向信息再次发送请求即可。但是它的弊端很明显,每次执行键命令前都要到 Redis 上进行重定向才能找到要执行命令的节点,额外增加了 IO 开销,这不是 Redis 集群高效的使用方式。正因为如此通常集群客户端都采用另一种实现:Smart(智能)客户端。
17、请求路由——Smart 客户端
1)Smart 客户端原理
- 大多数开发语言的 Redis 客户端都采用 Smart 客户端支持集群协议。
- Smart 客户端通过在内部维护 slot→node 的映射关系,本地就可实现键到节点的查找,从而保证 IO 效率的最大化,而 MOVED 重定向负责协助 Smart 客户端更新 slot→node 映射。
- Smart 客户端操作集群的流程:略。
2)Smart 客户端——JedisCluster
- Redis Cluster 虽然提供了分布式的特性,但是有些命令或者操作,诸如 keys、flushall、删除指定模式的键,需要遍历所有节点才可以完成。
- Redis Cluster 中,由于 key 分布到各个节点上,会造成无法实现 mget、mset 等功能。但是可以利用 CRC16 算法计算出 key 对应的 slot,以及 Smart 客户端保存了 slot 和节点对应关系的特性,将属于同一个 Redis 节点的 key 进行归档,然后分别对每个节点对应的子 key 列表执行 mget 或者 pipeline 操作。
- Lua 和事务需要所操作的 key,必须在一个节点上,不过 Redis Cluster 提供了 hashtag,如果开发人员确实要使用 Lua 或者事务,可以将所要操作的 key 使用一个 hashtag。
18、请求路由——ASK 重定向
1)客户端 ASK 重定向流程
- Redis 集群支持在线迁移槽(slot)和数据来完成水平伸缩,当 slot 对应的数据从源节点到目标节点迁移过程中,客户端需要做到智能识别,保证键命令可正常执行。
- 当一个 slot 数据从源节点迁移到目标节点时,期间可能出现一部分数据在源节点,而另一部分在目标节点的情况时,客户端键命令执行流程将发生变化:
- 客户端根据本地 slots 缓存发送命令到源节点,如果存在键对象则直接执行并返回结果给客户端。
- 如果键对象不存在,则可能存在于目标节点,这时源节点会回复 ASK 重定向异常。格式如下:(error)ASK{slot}{targetIP} :{targetPort}。
- 客户端从 ASK 重定向异常提取出目标节点信息,发送 asking 命令到目标节点打开客户端连接标识,再执行键命令。如果存在则执行,不存在则返回不存在信息。
- ASK 与 MOVED 虽然都是对客户端的重定向控制,但是有着本质区别。ASK 重定向说明集群正在进行 slot 数据迁移,客户端无法知道什么时候迁移完成,因此只能是临时性的重定向,客户端不会更新 slots 缓存。但是 MOVED 重定向说明键对应的槽已经明确指定到新的节点,因此需要更新 slots 缓存。
2)节点内部处理
- 为了支持 ASK 重定向,源节点和目标节点在内部的 clusterState 结构中维护当前正在迁移的槽信息,用于识别槽迁移情况。
- 节点每次接收到键命令时,都会根据 clusterState 内的迁移属性进行命令处理,如下所示:
- 如果键所在的槽由当前节点负责,但键不存在则查找 migrating_slots_to 数组查看槽是否正在迁出,如果是返回 ASK 重定向。
- 如果客户端发送 asking 命令打开了 CLIENT_ASKING 标识,则该客户端下次发送键命令时查找 importing_slots_from 数组获取 clusterNode ,如果指向自身则执行命令。
- 需要注意的是,asking 命令是一次性命令,每次执行完后客户端标识都会修改回原状态,因此每次客户端接收到 ASK 重定向后都需要发送 asking 命令。
- 批量操作。ASK 重定向对单键命令支持得很完善,但是,在开发中我们经常使用批量操作,如 mget 或 pipeline。当槽处于迁移状态时,批量操作会受到影响。
- 当在集群环境下使用 mget、mset 等批量操作时,slot 迁移数据期间由于键列表无法保证在同一节点,会导致大量错误。
- 使用 smart 客户端批量操作集群时,需要评估 mget/mset、Pipeline 等方式在 slot 迁移场景下的容错性,防止集群迁移造成大量错误和数据丢失的情况。
- 集群环境下对于使用批量操作的场景,建议优先使用 Pipeline 方式,在客户端实现对 ASK 重定向的正确处理,这样既可以受益于批量操作的 IO 优化,又可以兼容 slot 迁移场景。
19、故障转移之故障发现
- Redis 集群内节点通过 ping/pong 消息实现节点通信,消息不但可以传播节点槽信息,还可以传播其他状态如:主从状态、节点故障等。因此故障发现也是通过消息传播机制实现的,主要环节包括:主观下线(pfail)和客观下线(fail)。
- 主观下线:指某个节点认为另一个节点不可用,即下线状态,这个状态并不是最终的故障判定,只能代表一个节点的意见,可能存在误判情况。
- 客观下线:指标记一个节点真正的下线,集群内多个节点都认为该节点不可用,从而达成共识的结果。如果是持有槽的主节点故障,需要为该节点进行故障转移。
- 主观下线:集群中每个节点都会定期向其他节点发送 ping 消息,接收节点回复 pong 消息作为响应。如果在 cluster-node-timeout 时间内通信一直失败,则发送节点会认为接收节点存在故障,把接收节点标记为主观下线(pfail)状态。流程说明如下:
- 节点 a 发送 ping 消息给节点 b,如果通信正常将接收到 pong 消息,节点 a 更新最近一次与节点 b 的通信时间。
- 如果节点 a 与节点 b 通信出现问题则断开连接,下次会进行重连。如果一直通信失败,则节点 a 记录的与节点 b 最后通信时间将无法更新。
- 节点 a 内的定时任务检测到与节点 b 最后通信时间超高 cluster-node-timeout 时,更新本地对节点 b 的状态为主观下线(pfail)。
- 主观下线简单来讲就是,当 cluster-note-timeout 时间内某节点无法与另一个节点顺利完成 ping 消息通信时,则将该节点标记为主观下线状态。每个节点内的 cluster State 结构都需要保存其他节点信息,用于从自身视角判断其他节点的状态。结构关键属性中最重要的属性是 flags,用于标示该节点对应状态。
- 当某个节点判断另一个节点主观下线后,相应的节点状态会跟随消息在集群内传播。ping/pong 消息的消息体会携带集群 1/10 的其他节点状态数据,当接受节点发现消息体中含有主观下线的节点状态时,会在本地找到故障节点的 ClusterNode 结构,保存到下线报告链表中。通过 Gossip 消息传播,集群内节点不断收集到故障节点的下线报告。当半数以上持有槽的主节点都标记某个节点是主观下线时,触发客观下线流程。流程说明如下:
- 当消息体内含有其他节点的 pfail 状态会判断发送节点的状态,如果发送节点是主节点则对报告的 pfail 状态处理,从节点则忽略。
- 找到 pfail 对应的节点结构,更新 clusterNode 内部下线报告链表。
- 根据更新后的下线报告链表告尝试进行客观下线。
- 为什么必须是负责槽的主节点参与故障发现决策?因为集群模式下只有处理槽的主节点才负责读写请求和集群槽等关键信息维护,而从节点只进行主节点数据和状态信息的复制。
- 为什么半数以上处理槽的主节点?必须半数以上是为了应对网络分区等原因造成的集群分割情况,被分割的小集群因为无法完成从主观下线到客观下线这一关键过程,从而防止小集群完成故障转移之后继续对外提供服务。
- 每个节点 ClusterNode 结构中都会存在一个下线链表结构,保存了其他主节点针对当前节点的下线报告。下线报告中保存了报告故障的节点结构和最近收到下线报告的时间,当接收到 fail 状态时,会维护对应节点的下线上报链表。每个下线报告都存在有效期,每次在尝试触发客观下线时,都会检测下线报告是否过期,对于过期的下线报告将被删除。如果在 cluster-node-time_2 的时间内该下线报告没有得到更新则过期并删除。下线报告的有效期限是 server.cluster_node_timeout_2 ,主要是针对故障误报的情况。
- 如果在 cluster-node-time*2 时间内无法收集到一半以上槽节点的下线报告,那么之前的下线报告将会过期,也就是说主观下线上报的速度追赶不上下线报告过期的速度,那么故障节点将永远无法被标记为客观下线从而导致故障转移失败。因此不建议将 cluster-node-time 设置得过小。
- 集群中的节点每次接收到其他节点的 pfail 状态,都会尝试触发客观下线,流程说明如下:
- 首先统计有效的下线报告数量,如果小于集群内持有槽的主节点总数的一半则退出。
- 当下线报告大于槽主节点数量一半时,标记对应故障节点为客观下线状态。
- 向集群广播一条 fail 消息,通知所有的节点将故障节点标记为客观下线,fail 消息的消息体只包含故障节点的 ID。
- 广播 fail 消息是客观下线的最后一步,它承担着非常重要的职责:
- 通知集群内所有的节点标记故障节点为客观下线状态并立刻生效。
- 通知故障节点的从节点触发故障转移流程。
- 网络分区会导致分割后的小集群无法收到大集群的 fail 消息,因此如果故障节点所有的从节点都在小集群内将导致无法完成后续故障转移,因此部署主从结构时需要根据自身机房 / 机架拓扑结构,降低主从被分区的可能性。
20、故障转移之故障恢复
- 故障节点变为客观下线后,如果下线节点是持有槽的主节点则需要在它的从节点中选出一个替换它,从而保证集群的高可用。下线主节点的所有从 节点承担故障恢复的义务,当从节点通过内部定时任务发现自身复制的主节点进入客观下线时,将会触发故障恢复流程。流程说明如下:
- 资格检查:每个从节点都要检查最后与主节点断线时间,判断是否有资格替换故障的主节点。如果从节点与主节点断线时间超过 cluster-node-time*cluster-slave-validity-factor,则当前从节点不具备故障转移资格。参数 cluster-slave-validity-factor 用于从节点的有效因子,默认为 10。
- 准备选举时间:当从节点符合故障转移资格后,更新触发故障选举的时间,只有到达该时间后才能执行后续流程。之所以采用延迟触发机制,主要是通过对多个从节点使用不同的延迟选举时间来支持优先级问题。复制偏移量越大说明从节点延迟越低,那么它应该具有更高的优先级来替换故障主节点。所有的从节点中复制偏移量最大的将提前触发故障选举流程。
- 发起选举:当从节点定时任务检测到达故障选举时间(failover_auth_time)到达后,发起选举流程如下:
- 更新配置纪元:配置纪元是一个只增不减的整数,每个主节点自身维护一个配置纪元(clusterNode.configEpoch)标示当前主节点的版本,所有主节点的配置纪元都不相等,从节点会复制主节点的配置纪元。整个集群又维护一个全局的配置纪元(clusterState.current Epoch),用于记录集群内所有主节点配置纪元的最大版本。
- 广播选举消息:在集群内广播选举消息(FAILOVER_AUTH_REQUEST),并记录已发送过消息的状态,保证该从节点在一个配置纪元内只能发起一次选举。消息内容如同 ping 消息只是将 type 类型变为 FAILOVER_AUTH_REQUEST。
- 选举投票:只有持有槽的主节点才会处理故障选举消息(FAILOVER_AUTH_REQUEST),因为每个持有槽的节点在一个配置纪元内都有唯一的一张选票,当接到第一个请求投票的从节点消息时回复 FAILOVER_AUTH_ACK 消息作为投票,之后相同配置纪元内其他从节点的选举消息将忽略。
- 替换主节点:当从节点收集到足够的选票之后,触发替换主节点操作:
- 当前从节点取消复制变为主节点。
- 执行 clusterDelSlot 操作撤销故障主节点负责的槽,并执行 clusterAddSlot 把这些槽委派给自己。
- 向集群广播自己的 pong 消息,通知集群内所有的节点当前从节点变为主节点并接管了故障主节点的槽信息。
- 执行 cluster info 命令可以查看配置纪元信息。
- 配置纪元会跟随 ping/pong 消息在集群内传播,当发送方与接收方都是主节点且配置纪元相等时代表出现了冲突,nodeId 更大的一方会递增全局配置纪元并赋值给当前节点来区分冲突。
- 配置纪元的主要作用:
- 标示集群内每个主节点的不同版本和当前集群最大的版本。
- 每次集群发生重要事件时,这里的重要事件指出现新的主节点(新加入的或者由从节点转换而来),从节点竞争选举。都会递增集群全局的配置纪元并赋值给相关主节点,用于记录这一关键事件。
- 主节点具有更大的配置纪元代表了更新的集群状态,因此当节点间进行 ping/pong 消息交换时,如出现 slots 等关键信息不一致时,以配置纪元更大的一方为准,防止过时的消息状态污染集群。
- 配置纪元的应用场景有:
- 新节点加入。
- 槽节点映射冲突检测。
- 从节点投票选举冲突检测。
- 之前在通过 cluster setslot 命令修改槽节点映射时,需要确保执行请求的主节点本地配置纪元(configEpoch)是最大值,否则修改后的槽信息在消息传播中不会被拥有更高的配置纪元的节点采纳。由于 Gossip 通信机制无法准确知道当前最大的配置纪元在哪个节点,因此在槽迁移任务最后的 cluster setslot {slot} node {nodeId} 命令需要在全部主节点中执行一遍。
- 从节点每次发起投票时都会自增集群的全局配置纪元,并单独保存在 clusterState.failover_auth_epoch 变量中用于标识本次从节点发起选举的版本。
- 投票过程其实是一个领导者选举的过程,如集群内有 N 个持有槽的主节点代表有 N 张选票。由于在每个配置纪元内持有槽的主节点只能投票给一个从节点,因此只能有一个从节点获得 N/2+ 1 的选票,保证能够找出唯一的从节点。
- Redis 集群没有直接使用从节点进行领导者选举,主要因为从节点数必须大于等于 3 个才能保证凑够 N/2+1 个节点,将导致从节点资源浪费。使用集群内所有持有槽的主节点进行领导者选举,即使只有一个从节点也可以完成选举过程。当从节点收集到 N/2+ 1 个持有槽的主节点投票时,从节点可以执行替换主节点操作。
- 故障主节点也算在投票数内,假设集群内节点规模是 3 主 3 从,其中有 2 个主节点部署在一台机器上,当这台机器宕机时,由于从节点无法收集到 3/2+1 个主节点选票将导致故障转移失败。这个问题也适用于故障发现环节。因此部署集群时所有主节点最少需要部署在 3 台物理机上才能避免单点问题。
- 投票作废:每个配置纪元代表了一次选举周期,如果在开始投票之后的 cluster-node-timeout*2 时间内从节点没有获取足够数量的投票,则本次选举作废。从节点对配置纪元自增并发起下一轮投票,直到选举成功为止。
21、故障转移之故障转移时间
- 估算出故障转移时间:
- 主观下线(pfail)识别时间 = cluster-node-timeout。
- 主观下线状态消息传播时间 <=cluster-node-timeout/2。消息通信机制对超过 cluster-node-timeout/2 未通信节点会发起 ping 消息,消息体在选择包含哪些节点时会优先选取下线状态节点,所以通常这段时间内能够收集到半数以上主节点的 pfail 报告从而完成故障发现。
- 从节点转移时间 <=1000 毫秒。由于存在延迟发起选举机制,偏移量最大的从节点会最多延迟 1 秒发起选举。通常第一次选举就会成功,所以从节点执行转移时间在 1 秒以内。
根据以上分析可以预估出故障转移时间,如下:
failover-time (毫秒) ≤ cluster-node-timeout + cluster-node-timeout/2 + 1000
因此,故障转移时间跟 cluster-node-timeout 参数息息相关,默认 15 秒。配置时可以根据业务容忍度做出适当调整,但不是越小越好。
22、集群运维——集群完整性
- 为了保证集群完整性,默认情况下当集群 16384 个槽任何一个没有指派到节点时整个集群不可用。执行任何键命令返回(error)CLUSTERDOWN Hash slot not served 错误。
- 当持有槽的主节点下线时,从故障发现到自动完成转移期间整个集群是不可用状态,对于大多数业务无法容忍这种情况, 因此建议将参数 cluster-require-full-coverage 配置为 no,当主节点故障时只影响它负责槽的相关命令执行,不会影响其他主节点的可用性。
23、集群运维——带宽消耗
- 集群内 Gossip 消息通信本身会消耗带宽,官方建议集群最大规模在 1000 以内,也是出于对消息通信成本的考虑,因此单集群不适合部署超大规模的节点。
- 节点间消息通信对带宽的消耗体现在以下几个方面:
- 消息发送频率:跟 cluster-node-timeout 密切相关,当节点发现与其他节点最后通信时间超过 cluster-node-timeout/2 时会直接发送 ping 消息。
- 消息数据量:每个消息主要的数据占用包含:slots 槽数组(2KB 空间)和整个集群 1/10 的状态数据(10 个节点状态数据约 1KB)。
- 节点部署的机器规模:机器带宽的上线是固定的,因此相同规模的集群分布的机器越多每台机器划分的节点越均匀,则集群内整体的可用带宽越高。
- 集群带宽消耗主要分为:读写命令消耗 + Gossip 消息消耗。因此搭建 Redis 集群时需要根据业务数据规模和消息通信成本做出合理规划:
- 在满足业务需要的情况下尽量避免大集群。同一个系统可以针对不同业务场景拆分使用多套集群。这样每个集群既满足伸缩性和故障转移要求,还可以规避大规模集群的弊端。
- 适度提高 cluster-node-timeout 降低消息发送频率,同时 cluster-node-timeout 还影响故障转移的速度,因此需要根据自身业务场景兼顾二者的平衡。
- 如果条件允许集群尽量均匀部署在更多机器上。避免集中部署,如集群有 60 个节点,集中部署在 3 台机器上每台部署 20 个节点,这时机器带宽消耗将非常严重。
24、集群运维——Pub/Sub 广播问题
- Redis 在 2.0 版本提供了 Pub/Sub(发布 / 订阅)功能,用于针对频道实现消息的发布和订阅。但是在集群模式下内部实现对所有的 publish 命令都会向所有的节点进行广播,造成每条 publish 数据都会在集群内所有节点传播一次,加重带宽负担。
- 当频繁应用 Pub/Sub 功能时应该避免在大量节点的集群内使用,否则会严重消耗集群内网络带宽。针对这种情况建议使用 sentinel 结构专门用于 Pub/Sub 功能,从而规避这一问题。
25、集群运维——集群倾斜
- 集群倾斜指不同节点之间数据量和请求量出现明显差异。
1)数据倾斜
- 数据倾斜主要分为以下几种:
- 节点和槽分配严重不均。
- 针对每个节点分配的槽不均的情况,可以使用 redis-trib.rb info {host:ip} 进行定位,会列举出每个节点负责的槽和键总量以及每个槽平均键数量。
- 当节点对应槽数量不均匀时,可以使用 redis-trib.rb rebalance 命令进行平衡。
- 不同槽对应键数量差异过大。
- 键通过 CRC16 哈希函数映射到槽上,正常情况下槽内键数量会相对均匀。但当大量使用 hash_tag 时,会产生不同 的键映射到同一个槽的情况。特别是选择作为 hash_tag 的数据离散度较差时,将加速槽内键数量倾斜情况。
- 通过命令:cluster countkeysinslot{slot} 可以获取槽对应的键数量,识别出哪些槽映射了过多的键。再通过命令 cluster getkeysinslot{slot}{count} 循环迭代出槽下所有的键。从而发现过度使用 hash_tag 的键。
- 集合对象包含大量元素。
- 对于大集合对象的识别可以使用 redis-cli-- bigkeys 命令识别。找出大集合之后可以根据业务场景进行拆分。
- 同时集群槽数据迁移是对键执行 migrate 操作完成,过大的键集合如几百兆,容易造成 migrate 命令超时导致数据迁移失败。
- 内存相关配置不一致。
- 内存相关配置指 hash-max-ziplist-value、set-max-intset-entries 等压缩数据结构配置。当集群大量使用 hash、set 等数据结构时,如果内存压缩数据结构配置不一致,极端情况下会相差数倍的内存,从而造成节点内存量倾斜。
- 节点和槽分配严重不均。
2)请求倾斜
- 集群内特定节点请求量 / 流量过大将导致节点之间负载不均,影响集群均衡和运维成本。常出现在热点键场景,当键命令消耗较低时如小对象的 get、set、incr 等,即使请求量差异较大一般也不会产生负载严重不均。
- 但是当热点键对应高算法复杂度的命令或者是大对象操作如 hgetall、smembers 等,会导致对应节点负载过高的情况。避免方式如下:
- 合理设计键,热点大集合对象做拆分或使用 hmget 替代 hgetall 避免整体读取。
- 不要使用热键作为 hash_tag,避免映射到同一槽。
- 对于一致性要求不高的场景,客户端可使用本地缓存减少热键调用。
26、集群运维——集群读写分离
1)只读连接
- 集群模式下从节点不接受任何读写请求,发送过来的键命令会重定向到负责槽的主节点上(其中包括它的主节点)。
- 当需要使用从节点分担主节点读压力时,可以使用 readonly 命令打开客户端连接只读状态。之前的复制配置 slave-read-only 在集群模式下无效。当开启只读状态时,从节点接收读命令处理流程变为:如果对应的槽属于自己正在复制的主节点则直接执行读命令,否则返回重定向信息。
- readonly 命令是连接级别生效,因此每次新建连接时都需要执行 readonly 开启只读状态。执行 readwrite 命令可以关闭连接只读状态。
2)读写分离
- 针对从节点故障问题,客户端需要维护可用节点列表,集群提供了 cluster slaves {nodeId} 命令,返回 nodeId 对应主节点下所有从节点信息,数据格式同 cluster nodes。解析从节点列表信息,排除 fail 状态节点,这样客户端对从节点的故障判定可以委托给集群处理,简化维护可用从节点列表难度。
- 集群模式下读写分离涉及对客户端修改如下:
- 维护每个主节点可用从节点列表。
- 针对读命令维护请求节点路由。
- 从节点新建连接开启 readonly 状态。
- 集群模式下读写分离成本比较高,可以直接扩展主节点数量提高集群性能,一般不建议集群模式下做读写分离。
- 集群读写分离有时用于特殊业务场景如:
- 利用复制的最终一致性使用多个从节点做跨机房部署降低读命令网络延迟。
- 主节点故障转移时间过长,业务端把读请求路由给从节点保证读操作可用。
- 以上场景也可以在不同机房独立部署 Redis 集群解决,通过客户端多写来维护,读命令直接请求到最近机房的 Redis 集群,或者当一个集群节点故障时客户端转向另一个集群。
27、集群运维——手动故障转移
- Redis 集群提供了手动故障转移功能:指定从节点发起转移流程,主从节点角色进行切换,从节点变为新的主节点对外提供服务,旧的主节点变为它的从节点。
- 在从节点上执行 cluster failover 命令发起转移流程,默认情况下转移期间客户端请求会有短暂的阻塞,但不会丢失数据,流程如下:
- 从节点通知主节点停止处理所有客户端请求。
- 主节点发送对应从节点延迟复制的数据。
- 从节点接收处理复制延迟的数据,直到主从复制偏移量一致为止,保证复制数据不丢失。
- 从节点立刻发起投票选举(这里不需要延迟触发选举)。选举成功后断开复制变为新的主节点,之后向集群广播主节点 pong 消息。
- 旧主节点接受到消息后更新自身配置变为从节点,解除所有客户端请求阻塞,这些请求会被重定向到新主节点上执行。
- 旧主节点变为从节点后,向新的主节点发起全量复制流程。
- 主从节点转移后,新的从节点由于之前没有缓存主节点信息无法使用部分复制功能,所以会发起全量复制,当节点包含大量数据时会严重消耗 CPU 和网络资源,线上不要频繁操作。Redis4.0 的 Psync2 将有效改善这一问题。
- 手动故障转移的应用场景主要如下:
- 主节点迁移:运维 Redis 集群过程中经常遇到调整节点部署的问题,如节点所在的老机器替换到新机器等。由于从节点默认不响应请求可以安全下线关闭,但直接下线主节点会导致故障自动转移期间主节点无法对外提供服务,影响线上业务的稳定性。这时可以使用手动故障转移,把要下线的主节点安全的替换为从节点后,再做下线操作操作。
- 强制故障转移。当自动故障转移失败时,只要故障的主节点有存活的从节点就可以通过手动转移故障强制让从节点替换故障的主节点,保证集群的可用性。
- 自动故障转移失败的场景有:
- 主节点和它的所有从节点同时故障。这个问题需要通过调整节点机器部署拓扑做规避,保证主从节点不在同一机器 / 机架上。除非机房内大面积故障,否则两台机器 / 机架同时故障概率很低。
- 所有从节点与主节点复制断线时间超过 cluster-slave-validity-factor*cluster-node-tineout+repl-ping-slave-period,导致从节点被判定为没有故障转移资格,手动故障转移从节点不做中断超时检查。
- 由于网络不稳定等问题,故障发现或故障选举时间无法在 cluster-node-timeout*2 内完成,流程会不断重试,最终从节点复制中断时间超时,失去故障转移资格无法完成转移。
- 集群内超过一半以上的主节点同时故障。
- 根据以上情况,cluster failover 命令提供了两个参数 force/takeover 提供支持:、
- cluster failover force——用于当主节点宕机且无法自动完成故障转移情况。从节点接到 cluster failover force 请求时,从节点直接发起选举,不再跟主节点确认复制偏移量(从节点复制延迟的数据会丢失),当从节点选举成功后替换为新的主节点并广播集群配置。
- cluster failover takeover——用于集群内超过一半以上主节点故障的场景,因为从节点无法收到半数以上主节点投票,所以无法完成选举过程。可以执行 cluster failover takeover 强制转移,接到命令的从节点不再进行选举流程而是直接更新本地配置纪元并替换主节点。takeover 故障转移由于没有通过领导者选举发起故障转移,会导致配置纪元存在冲突的可能。当冲突发生时,集群会以 nodeId 字典序更大的一方配置为准。因此要小心集群分区后,手动执行 takeover 导致的集群冲突问题。
- 在集群可以自动完成故障转移的情况下,不要使用 cluster failover takeover 强制干扰集群选举机制,该操作主要用于半数以上主节点故障时采取的强制措施,请慎用。
- 手动故障转移时,在满足当前需求的情况下建议优先级:cluster failver>cluster failover force>cluster failover takeover。
28、集群运维——数据迁移
- 应用 Redis 集群时,常需要把单机 Redis 数据迁移到集群环境。redis-trib.rb 工具提供了导入功能,用于数据从单机向集群环境迁移的场景。
redis-trib .rb import host :port --from <arg> --copy --replace - redis-trib.rb import 命令内部采用批量 scan 和 migrate 的方式迁移数据。这种迁移方式存在以下缺点:
- 迁移只能从单机节点向集群环境导入数据。
- 不支持在线迁移数据,迁移数据时应用方必须停写,无法平滑迁移数据。
- 迁移过程中途如果出现超时等错误,不支持断点续传只能重新全量导入。
- 使用单线程进行数据迁移,大数据量迁移速度过慢。
- 唯品会开发的 redis-migrate-tool(https://github.com/vipshop/redis-migrate-tool),该工具可满足大多数 Redis 迁移需求,特点如下:
- 支持单机、Twemproxy、Redis Cluster 、RDB/AOF 等多种类型的数据迁移。
- 工具模拟成从节点基于复制流迁移数据,从而支持在线迁移数据,业务方不需要停写。
- 采用多线程加速数据迁移过程且提供数据校验和查看迁移状态等功能。
十一、缓存设计
1、缓存的收益和成本
- 缓存加入后带来的收益:
- 加速读写:因为缓存通常都是全内存的(例如 Redis、Memcache),而存储层通常读写性能不够强悍(例如 MySQL),通过缓存的使用可以有效地加速读写,优化用户体验。
- 降低后端负载:帮助后端减少访问量和复杂计算(例如很复杂的 SQL 语句),在很大程度降低了后端的负载。
- 缓存加入后带来的成本:
- 数据不一致性:缓存层和存储层的数据存在着一定时间窗口的不一致性,时间窗口跟更新策略有关。
- 代码维护成本:加入缓存后,需要同时处理缓存层和存储层的逻辑,增大了开发者维护代码的成本。
- 运维成本:以 Redis Cluster 为例,加入后无形中增加了运维成本。
- 缓存的使用场景基本包含如下两种:
- 开销大的复杂计算:以 MySQL 为例子,一些复杂的操作或者计算(例如大量联表操作、一些分组计算),如果不加缓存,不但无法满足高并发量,同时也会给 MySQL 带来巨大的负担。
- 加速请求响应:即使查询单条后端数据足够快(例如 select*from table where id=),那么依然可以使用缓存,以 Redis 为例子,每秒可以完成数万次读写,并且提供的批量操作可以优化整个 IO 链的响应时间。
2、缓存更新策略
1)LRU/LFU/FIFO 算法剔除
- 使用场景:剔除算法通常用于缓存使用量超过了预设的最大值时候,如何对现有的数据进行剔除。例如 Redis 使用 maxmemory-policy 这个配置作为内存最大值后对于数据的剔除策略。
- 一致性:要清理哪些数据是由具体算法决定,开发人员只能决定使用哪种算法,所以数据的一致性是最差的。
- 维护成本:算法不需要开发人员自己来实现,通常只需要配置最大 maxmemory 和对应的策略即可。开发人员只需要知道每种算法的含义,选择适合自己的算法即可。
2)超时剔除
- 使用场景:超时剔除通过给缓存数据设置过期时间,让其在过期时间后自动删除,例如 Redis 提供的 expire 命令。如果业务可以容忍一段时间内,缓存层数据和存储层数据不一致,那么可以为其设置过期时间。在数据过期后,再从真实数据源获取数据,重新放到缓存并设置过期时间。
- 一致性:一段时间窗口内(取决于过期时间长短)存在一致性问题,即缓存数据和真实数据源的数据不一致。
- 维护成本:维护成本不是很高,只需设置 expire 过期时间即可,当然前提是应用方允许这段时间可能发生的数据不一致。
3)主动更新
- 使用场景:应用方对于数据的一致性要求高,需要在真实数据更新后,立即更新缓存数据。
- 一致性:一致性最高,但如果主动更新发生了问题,那么这条数据很可能很长时间不会更新,所以建议结合超时剔除一起使用效果会更好。
- 维护成本:维护成本会比较高,开发者需要自己来完成更新,并保证更新操作的正确性。
下表为缓存的三种常见更新策略的对比:
| 策略 | 一致性 | 维护成本 |
|---|---|---|
| LRU/LFU/FIFO 算法剔除 | 最差 | 低 |
| 超时剔除 | 较差 | 较低 |
| 主动更新 | 强 | 高 |
4)最佳实践建议
- 低一致性业务建议配置最大内存和淘汰策略的方式使用。
- 高一致性业务可以结合使用超时剔除和主动更新,这样即使主动更新出了问题,也能保证数据过期时间后删除脏数据。
3、 缓存粒度控制
从通用性、空间占用、代码维护三个角度进行说明:
- 通用性。缓存全部数据比部分数据更加通用,但从实际经验看,很长时间内应用只需要几个重要的属性。
- 空间占用。缓存全部数据要比部分数据占用更多的空间,可能存在以问题:
- 全部数据会造成内存的浪费。
- 全部数据可能每次传输产生的网络流量会比较大,耗时相对较大,在极端情况下会阻塞网络。
- 全部数据的序列化和反序列化的 CPU 开销更大。
- 代码维护。全部数据的优势更加明显,而部分数据一旦要加新字段需要修改业务代码,而且修改后通常还需要刷新缓存数据。
4、穿透优化
- 缓存穿透是指查询一个根本不存在的数据,缓存层和存储层都不会命中,通常出于容错的考虑,如果从存储层查不到数据则不写入缓存层,整个过程分为如下 3 步:
- 缓存层不命中。
- 存储层不命中,不将空结果写回缓存。
- 返回空结果。
- 缓存穿透将导致不存在的数据每次请求都要到存储层去查询,失去了缓存保护后端存储的意义。
- 缓存穿透问题可能会使后端存储负载加大,由于很多后端存储不具备高并发性,甚至可能造成后端存储宕掉。通常可以在程序中分别统计总调用数、缓存层命中数、存储层命中数,如果发现大量存储层空命中,可能就是出现了缓存穿透问题。
- 造成缓存穿透的基本原因有两个。第一,自身业务代码或者数据出现问题,第二,一些恶意攻击、爬虫等造成大量空命中。
- 如何解决缓存穿透问题:
- 缓存空对象:
- 存储层不命中后,仍然将空对象保留到缓存层中,之后再访问这个数据将会从缓存中获取,这样就保护了后端数据源。
- 缓存空对象会有两个问题:第一,空值做了缓存,意味着缓存层中存了更多的键,需要更多的内存空间(如果是攻击,问题更严重),比较有效的方法是针对这类数据设置一个较短的过期时间,让其自动剔除。第二,缓存层和存储层的数据会有一段时间窗口的不一致,可能会对业务有一定影响。例如过期时间设置为 5 分钟,如果此时存储层添加了这个数据,那此段时间就会出现缓存层和存储层数据的不一致,此时可以利用消息系统或者其他方式清除掉缓存层中的空对象。
- 布隆过滤器拦截
- 在访问缓存层和存储层之前,将存在的 key 用布隆过滤器提前保存起来,做第一层拦截。例如: 一个推荐系统有 4 亿个用户 id,每个小时算法工程师会根据每个用户之前历史行为计算出推荐数据放到存储层中,但是最新的用户由于没有历史行为,就会发生缓存穿透的行为,为此可以将所有推荐数据的用户做成布隆过滤器。如果布隆过滤器认为该用户 id 不存在,那么就不会访问存储层,在一定程度保护了存储层。
- 可以利用 Redis 的 Bitmaps 实现布隆过滤器。
- 这种方法适用于数据命中不高、数据相对固定、实时性低(通常是数据集较大)的应用场景,代码维护较为复杂,但是缓存空间占用少。
- 缓存空对象:
下表为缓存空对象和布隆过滤器方案对比:
| 解决缓存穿透 | 使用场景 | 维护成本 |
|---|---|---|
| 缓存空对象 | - 数据命中不高- 数据频繁变化实时性高 | - 代码维护简单- 需要过多的缓存空间- 数据不一致 |
| 布隆过滤器 | - 数据命中不高- 数据相对固定实时性低 | - 代码维护复杂- 缓存空间占用少 |
5、无底洞优化
- 通常来说添加节点使得 Memcache 集群性能应该更强了,但事实并非如此。键值数据库由于通常采用哈希函数将 key 映射到各个节点上,造成 key 的分布与业务无关,但是由于数据量和访问量的持续增长,造成需要添加大量节点做水平扩容,导致键值分布到更多的节点上,所以无论是 Memcache 还是 Redis 的分布式,批量操作通常需要从不同节点上获取,相比于单机批量操作只涉及一次网络操作,分布式批量操作会涉及多次网络时间。
- 无底洞问题分析:
- 客户端一次批量操作会涉及多次网络操作,也就意味着批量操作会随着节点的增多,耗时会不断增大。
- 网络连接数变多,对节点的性能也有一定影响。
- 更多的节点不代表更高的性能,所谓 “无底洞” 就是说投入越多不一定产出越多。但是分布式又是不可以避免的,因为访问量和数据量越来越大,一个节点根本抗不住。
- 常见的 IO 优化思路:
- 命令本身的优化,例如优化 SQL 语句等。
- 减少网络通信次数。
- 降低接入成本,例如客户端使用长连 / 连接池、NIO 等。
- 结合 Redis Cluster 的一些特性对四种分布式的批量操作方式进行说明:、
- 串行命令:由于 n 个 key 是比较均匀地分布在 Redis Cluster 的各个节点上,因此无法使用 mget 命令一次性获取,所以通常来讲要获取 n 个 key 的值,最简单的方法就是逐次 n 个 get 命令,这种操作时间复杂度较高,它的操作时间 = n 次网络时间 + n 次命令时间,网络次数是 n。很显然这种方案不是最优的,但是实现起来比较简单。
- 串行 IO:Redis Cluster 使用 CRC16 算法计算出散列值,再取对 16383 的余数就可以算出 slot 值,同时 Smart 客户端会保存 slot 和节点的对应关系,有了这两个数据就可以将属于同一个节点的 key 进行归档,得到每个节点的 key 子列表,之后对每个节点执行 mget 或者 Pipeline 操作,它的操作时间 = node 次网络时间 + n 次命令时间,网络次数是 node 的个数。很明显这种方案比第一种要好很多,但是如果节点数太多,还是有一定的性能问题。
- 并行 IO:此方案是将方案 2 中的最后一步改为多线程执行,网络次数虽然还是节点个数,但由于使用多线程网络时间变为 O(1),这种方案会增加编程的复杂度。
- hash_tag 实现:它可以将多个 key 强制分配到一个节点上,它的操作时间 = 1 次网络时间 + n 次命令时间。
下表为四种批量操作解决方案对比:
| 方案 | 优点 | 缺点 | 网络 IO |
|---|---|---|---|
| 串行命令 | 1)编程简单2)如果少量 keys,性能可以满足要求 | 大量 keys 请求延迟严重 | O(keys) |
| 串行 IO | 1)编程简单2)少量节点,性能满足要求 | 大量 node 延迟严重 | O(nodes) |
| 并行 IO | 利用并行特性,延迟取决于最慢的节点 | 1)编程复杂2)由于多线程,问题定位可能较难 | O(max_slow(nodes)) |
| hash_tag | 性能最高 | 1)业务维护成本较高2)容易出现数据倾斜 | O(1) |
6、雪崩优化
- 缓存雪崩:由于缓存层承载着大量请求,有效地保护了存储层,但是如果缓存层由于某些原因不能提供服务,于是所有的请求都会达到存储层,存储层的调用量会暴增,造成存储层也会级联宕机的情况。缓存雪崩的英文原意是 stampeding herd(奔逃的野牛),指的是缓存层宕掉后,流量会像奔逃的野牛一样,打向后端存储。
- 预防和解决缓存雪崩问题,可以从以下三个方面进行着手:
- 保证缓存层服务高可用性
- 依赖隔离组件为后端限流并降级:作为并发量较大的系统,假如有一个资源不可用,可能会造成线程全部阻塞(hang)在这个资源上,造成整个系统不可用。在实际项目中,我们需要对重要的资源(例如 Redis、MySQL、HBase、外部接口)都进行隔离,让每种资源都单独运行在自己的线程池中,即使个别资源出现了问题,对其他服务没有影响。
- 提前演练。
7、热点 key 重建优化
- 开发人员使用 “缓存 + 过期时间” 的策略既可以加速数据读写,又保证数据的定期更新,这种模式基本能够满足绝大部分需求。但是有两个问题如果同时出现,可能就会对应用造成致命的危害:
- 当前 key 是一个热点 key(例如一个热门的娱乐新闻),并发量非常大。
- 重建缓存不能在短时间完成,可能是一个复杂计算,例如复杂的 SQL、多次 IO、多个依赖等。
- 在缓存失效的瞬间,有大量线程来重建缓存,造成后端负载加大,甚至可能会让应用崩溃。
1)互斥锁
- 此方法只允许一个线程重建缓存,其他线程等待重建缓存的线程执行完,重新从缓存获取数据即可。(可以通过 setnx 命令实现)
2)永远不过期
-
“永远不过期” 包含两层意思:
- 从缓存层面来看,确实没有设置过期时间,所以不会出现热点 key 过期后产生的问题,也就是 “物理” 不过期。
- 从功能层面来看,为每个 value 设置一个逻辑过期时间,当发现超过逻辑过期时间后,会使用单独的线程去构建缓存。
-
从实战看,此方法有效杜绝了热点 key 产生的问题,但唯一不足的就是重构缓存期间,会出现数据不一致的情况,这取决于应用方是否容忍这种不一致。
-
互斥锁(mutex key):这种方案思路比较简单,但是存在一定的隐患,如果构建缓存过程出现问题或者时间较长,可能会存在死锁和线程池阻塞的风险,但是这种方法能够较好地降低后端存储负载,并在一致性上做得比较好。
-
“永远不过期” :这种方案由于没有设置真正的过期时间,实际上已经不存在热点 key 产生的一系列危害,但是会存在数据不一致的情况,同时代码复杂度会增大。
下表为两种热点 key 的解决方法:
| 解决方案 | 优点 | 缺点 |
|---|---|---|
| 简单分布式锁 | - 思路简单- 保证一致性 | - 代码复杂度增大- 存在死锁的风险- 存在线程池阻塞的风险 |
| “永远不过期” | 基本杜绝热点 key 问题 | - 不保证一致性- 逻辑过期时间增加代码维护成本和内存成本 |
8、汇总
- 比较推荐的缓存更新策略是结合剔除、超时、主动更新三种方案共同完成。
- 穿透问题:使用缓存空对象和布隆过滤器来解决,注意它们各自的使用场景和局限性。
- 无底洞问题:分布式缓存中,有更多的机器不保证有更高的性能。有四种批量操作方式:串行命令、串行 IO、并行 IO、hash_tag。
- 雪崩问题:缓存层高可用、客户端降级、提前演练是解决雪崩问题的重要方法。
- 热点 key 问题:互斥锁、“永远不过期” 能够在一定程度上解决热点 key 问题,开发人员在使用时要了解它们各自的使用成本。
本文由 简悦 SimpRead 转码, 原文地址 blog.csdn.net
十二、开发运维的 “陷阱”
1、Linux 配置优化之内存分配控制
1)vm.overcommit_memory
- Linux 操作系统对大部分申请内存的请求都回复 yes,以便能运行更多的程序。因为申请内存后,并不会马上使用内存,这种技术叫做 overcommit。
- 本节的可用内存代表物理内存与 swap 之和。
- 日志中的 Background save 代表的是 bgsave 和 bgrewriteaof,如果当前可用内存不足,操作系统应该如何处理 fork 操作。如果 vm.overcommit_memory=0,代表如果没有可用内存,就申请内存失败,对应到 Redis 就是执行 fork 失败,Redis 建议把这个值设置为 1,是为了让 fork 操作能够在低内存下也执行成功。
vm.overcommit_memory 用来设置内存分配策略,有三个可选值,如下表:
| 值 | 含义 |
|---|---|
| 0 | 表示内核将检查是否有足够的可用内存,如果有足够的可用内存,内存申请通过,否则内存申请失败,并把错误返回给应用进程。 |
| 1 | 表示内核允许超量使用内存直到用完为止 |
| 2 | 表示内核决不过量的 (“never overcommit”) 使用内存,即系统整个内存地址空间不能超过 swap+50% 的 RAM 值,50% 是 overcommit_ratio 默认值,此参数同样支持修改。 |
2)获取和设置
// 获取
# cat /proc/sys/vm/overcommit_memory
0
// 设置
echo "vm.overcommit_memory=1" >> /etc/sysctl.conf
sysctl vm.overcommit_memory=1
3)最佳实践
- Redis 设置合理的 maxmemory,保证机器有 20%~30% 的闲置内存。
- 集中化管理 AOF 重写和 RDB 的 bgsave。
- 设置 vm.overcommit_memory= 1,防止极端情况下会造成 fork 失败。
2、Linux 配置优化之 swappiness
1)参数说明
- swap 对于操作系统来比较重要,当物理内存不足时,可以将一部分内存页进行 swap 操作,已解燃眉之急。但世界上没有免费午餐,swap 空间由硬盘提供,对于需要高并发、高吞吐的应用来说,磁盘 IO 通常会成为系统瓶颈。在 Linux 中,并不是要等到所有物理内存都使用完才会使用到 swap,系统参数 swppiness 会决定操作系统使用 swap 的倾向程度。swappiness 的取值范围是 0~100,swappiness 的值越大,说明操作系统可能使用 swap 的概率越高,swappiness 值越低,表示操作系统更加倾向于使用物理内存。swap 的默认值是 60。
- OOM(Out Of Memory)killer 机制是指 Linux 操作系统发现可用内存不足时,强制杀死一些用户进程(非内核进程),来保证系统有足够的可用内存进行分配。
- swappiness 参数在 Linux3.5 版本前后的表现并不完全相同,Redis 运维人员在设置这个值需要关注当前操作系统的内核版本。
swapniess 重要值策略说明如下表:
| 值 | 策略 |
|---|---|
| 0 | Linux3.5 以及以上:宁愿用 OOM killer 也不用 swap Linux3.4 以及更早:宁愿 swap 也不用 OOM killer |
| 1 | Linux3.5 以及以上:宁愿 swap 也不用 OOM killer |
| 60 | 默认值 |
| 100 | 操作系统会主动地使用 swap |
2)设置方法
echo {bestvalue} > /proc/sys/vm/swappiness
// 但是上述方法在系统重启后就会失效,为了让配置在重启Linux操作系统后立即生效,只需要在/etc/sysctl.conf追加vm.swappiness={bestvalue}即可。
echo vm.swappiness={bestvalue} >> /etc/sysctl.conf
- /proc/sys/vm/swappiness 是设置操作,/etc/sysctl.conf 是追加操作。
3)如何监控 swap
- 查看 swap 的总体情况:Linux 提供了 free 命令来查询操作系统的内存使用情况,其中也包含了 swap 的相关使用情况。
- 实时查看 swap 的使用:Linux 提供了 vmstat 命令查询系统的相关性能指标,其中包含负载、CPU、内存、swap、IO 的相关属性。但其中和 swap 有关的指标是 si 和 so,它们分别代表操作系统的 swap in 和 swap out。si 和 so 都为 0,代表当前没有使用 swap。
- 查看指定进程的 swap 使用情况:Linux 操作系统中,/proc/{pid} 目录是存储指定进程的相关信息,其中 / proc/{pid}/smaps 记录了当前进程所对应的内存映像信息,这个信息对于查询指定进程的 swap 使用情况很有帮助。
// 通过info server获取Redis的进程号process_id:
redis-cli -h ip -p port info server | grep process_id
process_id:986
// 通过cat/proc/986/smaps查询Redis的smaps信息,会输出多个内存块信息。其中Swap字段代表该内存块存在swap分区的数据大小。
// 通过执行如下命令,就可以找到每个内存块镜像信息中,这个进程使用到的swap量,通过求和就可以算出总的swap用量:
cat /proc/986/smaps | grep Swap
- 如果 Linux>3.5,vm.swapniess=1,否则 vm.swapniess=0,从而实现如下两个目标:
- 物理内存充足时候,使 Redis 足够快。
- 物理内存不足时候,避免 Redis 死掉(如果当前 Redis 为高可用,死掉比阻塞更好) 。
3、Linux 配置优化之 THP
- Redis 建议修改 Transparent Huge Pages(THP)的相关配置,Linux kernel 在 2.6.38 内核增加了 THP 特性,支持大内存页(2MB)分配,默认开启。当开启时可以降低 fork 子进程的速度,但 fork 操作之后,每个内存页从原来 4KB 变为 2MB,会大幅增加重写期间父进程内存消耗。同时每次写命令引起的复制内存页单位放大了 512 倍,会拖慢写操作的执行时间,导致大量写操作慢查询。因此 Redis 日志中建议将此特性进行禁用。
- 在设置 THP 配置时需要注意:有些 Linux 的发行版本没有将 THP 放到 / sys/kernel/mm/transparent_hugepage/enabled 中,例如 Red Hat6 以上的 THP 配置放到 / sys/kernel/mm/redhat_transparent_hugepage/enabled 中。而 Redis 源码中 检查 THP 时,把 THP 位置写死 / sys/kernel/mm/transparent_hugepage/enabled。所以在发行版中,虽然没有 THP 的日志提示,但是依然存在 THP 所带来的问题。
禁用方法如下:
echo never > /sys/kernel/mm/transparent_hugepage/enabled
为了使机器重启后THP配置依然生效,可以在/etc/rc.local中追加echo never>/sys/kernel/mm/transparent_hugepage/enabled。
echo never > /sys/kernel/mm/redhat_transparent_hugepage/enabled
4、Linux 配置优化之 OOM killer
- OOM killer 会在可用内存不足时选择性地杀掉用户进程。
- OOM killer 进程会为每个用户进程设置一个权值,这个权值越高,被 “下手” 的概率就越高,反之概率越低。每个进程的权值存放在 / proc/{progress_id}/oom_score 中,这个值是受 / proc/{progress_id}/oom_adj 的控制,oom_adj 在不同的 Linux 版本中最小值不同,可以参考 Linux 源码中 oom.h(从 - 15 到 - 17)。当 oom_adj 设置为最小值时,该进程将不会被 OOM killer 杀掉。
- 对于 Redis 所在的服务器来说,可以将所有 Redis 的 oom_adj 设置为最低值或者稍小的值,降低被 OOM killer 杀掉的概率。
- 笔者认为 oom_adj 参数只能起到辅助作用,合理地规划内存更为重要。
- 通常在高可用情况下,被杀掉比僵死更好,因此不要过多依赖 oom_adj 配置。
设置方法如下:
echo {value} > /proc/${process_id}/oom_adj
// 将所有Redis的oom_adj设置为最低值
for redis_pid in $ (pgrep -f "redis-server")
do
echo -17 > /proc/${redis_pid}/oom_adj
done
5、Linux 配置优化之使用 NTP
- NTP(Network Time Protocol,网络时间协议)是一种保证不同机器时钟一致性的服务。
- 集群的时间不一致不会影响集群功能,集群节点依赖各自时钟。
- 可以每天定时去同步一次系统时间,从而使得集群中的时间保持统一。
6、Linux 配置优化之 ulimit
- 在 Linux 中,可以通过 ulimit 查看和设置系统当前用户进程的资源数。其中 ulimit-a 命令包含的 open files 参数,是单个用户同时打开的最大文件个数。
- Redis 允许同时有多个客户端通过网络进行连接,可以通过配置 maxclients 来限制最大客户端连接数。对 Linux 操作系统来说,这些网络连接都是文件句柄。
- Redis 建议把 open files 至少设置成 10032,因为 maxclients 默认是 10000,这些是用来处理客户端连接的,除此之外,Redis 内部会使用最多 32 个文件描述符,所以这里的 10032=10000+32。
- Redis 不能将 open files 设置成 10032,因为它没有权限设置。
- open files 的限制优先级比 maxclients 大。
Open files的设置方法如下:
ulimit –Sn {max-open-files}
7、Linux 配置优化之 TCP backlog
- Redis 默认的 tcp-backlog 值为 511,可以通过修改配置 tcp-backlog 进行调整,如果 Linux 的 tcp-backlog 小于 Redis 设置的 tcp-backlog,那么在 Redis 启动时会看到相关日志。
查看方法:
# cat /proc/sys/net/core/somaxconn
128
修改方法:
echo 511 > /proc/sys/net/core/somaxconn
8、flushall/flushdb 误操作之缓存与存储
- 被误操作 flush 后,根据当前 Redis 是缓存还是存储使用策略有所不同:
- 缓存:对于业务数据的正确性可能造成损失还小一点,因为缓存中的数据可以从数据源重新进行构建。
- 存储:对业务方可能会造成巨大的影响,也许 flush 操作后的数据是重要配置,也可能是一些基础数据,也可能是业务上的重要一环,如果没有提前做业务降级操作,那么最终反馈到用户的应用可能就是报错或者空白页面等,其后果不堪设想。即使做了相应的降级或者容错处理,对于用户体验也有一定的影响。
9、flushall/flushdb 误操作之借助 AOF 机制恢复
- Redis 执行了 flush 操作后,对 AOF 持久化文件的影响如下:
- appendonly no:对 AOF 持久化没有任何影响,因为根本就不存在 AOF 文件。
- appendonly yes:只不过是在 AOF 文件中追加了一条记录 (flush 操作记录)。
- 虽然 Redis 中的数据被清除掉了,但是 AOF 文件还保存着 flush 操作之前完整的数据,这对恢复数据是很有帮助的。
- 如果发生了 AOF 重写,Redis 遍历所有数据库重新生成 AOF 文件,并会覆盖之前的 AOF 文件。所以如果 AOF 重写发生了,也就意味着之前的数据就丢掉了,那么利用 AOF 文件来恢复的办法就失效了。所以当误操作后,需要考虑如下两件事。
- 调大 AOF 重写参数 auto-aof-rewrite-percentage 和 auto-aof-rewrite-min-size ,让 Redis 不能产生 AOF 自动重写。
- 拒绝手动 bgrewriteaof。
- 如果要用 AOF 文件进行数据恢复,那么必须要将 AOF 文件中的 flushall 相关操作去掉,为了更加安全,可以在去掉之后使用 redis-check-aof 这个工具去检验和修复一下 AOF 文件,确保 AOF 文件格式正确,保证数据恢复正常。
10、flushall/flushdb 误操作之 RDB 变化
- 如果没有开启 RDB 的自动策略,那么除非手动执行过 save、bgsave 或者发生了主从的全量复制,否则 RDB 文件也会保存 flush 操作之前的数据,可以作为恢复数据的数据源。
- 防止手动执行 save、bgsave ,如果此时执行 save、bgsave,新的 RDB 文件就不会包含 flush 操作之前的数据,被老的 RDB 文件进行覆盖。
- RDB 文件中的数据可能没有 AOF 实时性高,也就是说,RDB 文件很可能很久以前主从全量复制生成的,或者之前用 save、bgsave 备份的。
- 如果开启了 RDB 的自动策略,由于 flush 涉及键值数量较多,RDB 文件会被清除,意味着使用 RDB 恢复基本无望。
- 如果 AOF 已经开启了,那么用 AOF 来恢复是比较合理的方式,但是如果 AOF 关闭了,那么 RDB 虽然数据不是很实时,但是也能恢复部分数据,完全取决于 RDB 是什么时候备份的。当然 RDB 并不是一无是处,它的恢复速度要比 AOF 快很多,但是总体来说对于 flush 操作之后不是最好的恢复数据源。
11、flushall/flushdb 误操作之从节点变化
- Redis 从节点同步了主节点的 flush 命令,所以从节点的数据也是被清除了,从节点的 RDB 和 AOF 的变化与主节点没有任何区别。
12、flushall/flushdb 误操作之快速恢复数据
下面使用AOF作为数据源进行恢复演练:
1、防止AOF重写。快速修改Redis主从的auto-aof-rewrite-percentage和auto-aof-rewrite-min-size变为一个很大的值,从而防止了AOF重写的发生,例如:
config set auto-aof-rewrite-percentage 1000
config set auto-aof-rewrite-min-size 100000000000
2、去掉主从AOF文件中的flush相关内容:
*1
$8
flushall
3、重启Redis主节点服务器,恢复数据。
13、安全的 Redis 概述
- 被攻击的 Redis 有如下特点:
- Redis 所在的机器有外网 IP。
- Redis 以默认端口 6379 为启动端口,并且是对外网开放的。
- Redis 是以 root 用户启动的。
- Redis 没有设置密码。
- Redis 的 bind 设置为 0.0.0.0 或者 “”。
14、安全的 Redis 之 Redis 密码机制
1)简单的密码机制
- Redis 提供了 requirepass 配置为 Redis 提供密码功能,如果添加这个配置,客户端就不能通过 redis-cli–h{ip}–p {port} 来执行命令。
- Redis 提供了两种方式访问配置了密码的 Redis:
- redis-cli -a 参数。使用 redis-cli 连接 Redis 时,添加 - a 加密码的参数,如果密码正确就可以正常访问 Redis 了。
- auth 命令。通过 redis-cli 连接后,执行 auth 加密码命令,如果密码正确就可以正常访问访问 Redis 了。
- 这种密码机制能在一定程度上保护 Redis 的安全,但是在使用 requirepass 时候要注意一下几点:
- 密码要足够复杂(64 个字节以上),因为 Redis 的性能很高,如果密码比较简单,完全是可以在一段时间内通过暴力破解来破译密码。
- 如果是主从结构的 Redis,不要忘记在从节点的配置中加入 masterauth(master 的密码)配置,否则会造成主从节点同步失效。
- auth 是通过明文进行传输的,所以也不是 100% 可靠,如果被攻击者劫持也相当危险。
15、安全的 Redis 之伪装危险命令
- Redis 中包含了很多 “危险” 的命令,一旦错误使用或者误操作,后果不堪设想,例如如下命令:(Redis 提供了 rename-command 配置解决这个问题。管理员可以对认为比较危险的命令做 rename-command 处理。)
- keys:如果键值较多,存在阻塞 Redis 的可能性。
- flushall/flushdb:数据全部被清除。
- save:如果键值较多,存在阻塞 Redis 的可能性。
- debug:例如 debug reload 会重启 Redis。
- config:config 应该交给管理员使用。
- shutdown:停止 Redis。
- 使用了 rename-command 时可能会带来如下麻烦:
- 管理员要对自己的客户端进行修改,例如 jedis.flushall() 操作内部使用的是 flushall 命令,如果用 rename-command 后需要修改为新的命令,有一定的开发和维护成本。
- rename-command 配置不支持 config set,所以在启动前一定要确定哪些命令需要使用 rename-command。
- 如果 AOF 和 RDB 文件包含了 rename-command 之前的命令,Redis 将无法启动,因为此时它识别不了 rename-command 之前的命令。
- Redis 源码中有一些命令是写死的,rename-command 可能造成 Redis 无法正常工作。例如 Sentinel 节点在修改配置时直接使用了 config 命令,如果对 config 使用 rename-command,会造成 Redis Sentinel 无法正常工作。
- 在使用 rename-command 的相关配置时,需要注意以下几点:
- 对于一些危险的命令(例如 flushall),不管是内网还是外网,一律使用 rename-command 配置。
- 建议第一次配置 Redis 时,就应该配置 rename-command,因为 rename-command 不支持 config set。
- 如果涉及主从关系,一定要保持主从节点配置的一致性,否则存在主从数据不一致的可能性。
16、安全的 Redis 之防火墙
- 可以使用防火墙限制输入和输出的 IP 或者 IP 范围、端口或者端口范围,在比较成熟的公司都会对有外网 IP 的服务器做一些端口的限制,例如只允许 80 端口对外开放。因为一般来说,开放外网 IP 的服务器中 Web 服务器比较多,但通常存储服务器的端口无需对外开放,防火墙是一个限制外网访问 Redis 的必杀技。
17、安全的 Redis 之 bind
- bind 指定的是 Redis 和哪个网卡进行绑定,和客户端是什么网段没有关系。
- Redis3.0 中 bind 默认值 “”,也就是不限制网卡的访问,但是在 Redis3.2 中必须显示的配置 bind0.0.0.0 才可以达到这种效果。
- 建议:
- 如果机器有外网 IP,但部署的 Redis 是给内部使用的,建议去掉外网网卡或者使用 bind 配置限制流量从外网进入。
- 如果客户端和 Redis 部署在一台服务器上,可以使用回环地址(127.0.0.1)。
- bind 配置不支持 config set,所以尽可能在第一次启动前配置好。
- Redis3.2 提供了 protected-mode 配置(默认开启),如果当前 Redis 没有配置密码,没有配置 bind,那么只允许来自本机的访问,也就是相当于配置了 bind 127.0.0.1。
18、安全的 Redis 之定期备份数据
- 定期备份持久化数据是一个比较好的习惯。
19、安全的 Redis 之不使用默认端口
- Redis 的默认端口是 6379,不使用默认端口从一定程度上可降低被入侵者发现的可能性,因为入侵者通常本身也是一些攻击程序,对目标服务器进行端口扫描,例如 MySQL 的默认端口 3306、Memcache 的默认端口 11211、Jetty 的默认端口 8080 等都会被设置成攻击目标,Redis 作为一款较为知名的 NoSQL 服务,6379 必然也在端口扫描的列表中,虽然不设置默认端口还是有可能被攻击者入侵,但是能够在一定程度上降低被攻击的概率。
20、安全的 Redis 之使用非 root 用户启动
- 建议在启动 Redis 服务的时候使用非 root 用户启动。事实上许多服务,例如 Resin、Jetty、HBase、Hadoop 都建议使用非 root 启动。
21、处理 bigkey
- bigkey 是指 key 对应的 value 所占的内存空间比较大,例如一个字符串类型的 value 可以最大存到 512MB,一个列表类型的 value 最多可以存储 2^32-1 个元素。如果按照数据结构来细分的话,一般分为字符串类型 bigkey 和非字符串类型 bigkey。
- 字符串类型:体现在单个 value 值很大,一般认为超过 10KB 就是 bigkey,但这个值和具体的 OPS 相关。
- 非字符串类型:哈希、列表、集合、有序集合,体现在元素个数过多。
22、bigkey 的危害
- bigkey 的危害体现在三个方面:
- 内存空间不均匀(平衡):例如在 Redis Cluster 中,bigkey 会造成节点的内存空间使用不均匀。
- 超时阻塞:由于 Redis 单线程的特性,操作 bigkey 比较耗时,也就意味着阻塞 Redis 可能性增大。
- 网络拥塞:每次获取 bigkey 产生的网络流量较大。
23、如何发现 bigkey
- redis-cli–bigkeys 可以命令统计 bigkey 的分布。
- 判断一个 key 是否为 bigkey,只需要执行 debug object key 查看 serializedlength 属性即可,它表示 key 对应的 value 序列化之后的字节数。
- serializedlength 不代表真实的字节大小,它返回对象使用 RDB 编码序列化后的长度,值会比 strlen 的结果偏小,但是对于排查 bigkey 有一定辅助作用,因为不是每种数据结构都有类似 strlen 这样的方法。
- 在实际生产环境中发现 bigkey 的两种方式如下:
- 被动收集:建议修改 Redis 客户端,当抛出异常时打印出所操作的 key,方便排查 bigkey 问题。
- 主动检测:scan+debug object:如果怀疑存在 bigkey,可以使用 scan 命令渐进的扫描出所有的 key,分别计算每个 key 的 serializedlength,找到对应 bigkey 进行相应的处理和报警,这种方式是比较推荐的方式。
- 如果键值个数比较多,scan+debug object 会比较慢,可以利用 Pipeline 机制完成。
- 对于元素个数较多的数据结构,debug object 执行速度比较慢,存在阻塞 Redis 的可能。
- 如果有从节点,可以考虑在从节点上执行。
24、如何删除 bigkey
- 无论是什么数据结构,del 命令都将其删除。但不建议这样做,因为删除 bigkey 通常来说会阻塞 Redis 服务。
- 除了 string 类型,其他四种数据结构删除的速度有可能很慢,这样增大了阻塞 Redis 的可能性。
- 以 hash 为例子,可以使用 hscan 命令,每次获取部分(例如 100 个)field-value,再利用 hdel 删除每个 field(为了快速可以使用 Pipeline)。
25、bigkey 最佳实践思路
- 例如出现了 bigkey,要思考一下可不可以做一些优化(例如拆分数据结构)尽量让这些 bigkey 消失在业务中,如果 bigkey 不可避免,也要思考一下要不要每次把所有元素都取出来(例如有时候仅仅需要 hmget,而不是 hgetall)。
- Redis 将在 4.0 版本支持 lazy delete free 的模式,那时删除 bigkey 不会阻塞 Redis。
26、寻找热点 key
1)客户端
- 客户端其实是距离 key“最近” 的地方,因为 Redis 命令就是从客户端发出的,例如在客户端设置全局字典(key 和调用次数),每次调用 Redis 命令时,使用这个字典进行记录。
- 使用客户端进行热点 key 的统计非常容易实现,但是同时问题也非常多:
- 无法预知 key 的个数,存在内存泄露的危险。
- 对于客户端代码有侵入,各个语言的客户端都需要维护此逻辑,维护成本较高。
- 只能了解当前客户端的热点 key,无法实现规模化运维统计。
2)代理端
- 此架构是最适合做热点 key 统计的,因为代理是所有 Redis 客户端和服务端的桥梁。但并不是所有 Redis 都是采用此种架构。
3)Redis 服务端
- 使用 monitor 命令统计热点 key 是很多开发和运维人员首先想到,monitor 命令可以监控到 Redis 执行的所有命令。
- 为了减少网络开销以及加快输出缓冲区的消费速度,monitor 尽可能在本机执行。
- monitor 命令在高并发条件下,会存在内存暴增和影响 Redis 性能的隐患,所以此种方法适合在短时间内使用。
- 只能统计一个 Redis 节点的热点 key,对于 Redis 集群需要进行汇总统计。
4)机器
- Redis 客户端使用 TCP 协议与服务端进行交互,通信协议采用的是 RESP。如果站在机器的角度,可以通过对机器上所有 Redis 端口的 TCP 数据包进行抓取完成热点 key 的统计。
- 需要一定的开发成本,但是一些开源方案实现了该功能,例如 ELK(ElasticSearch Logstash Kibana)体系下的 packetbeat 插件,可以实现对 Redis、MySQL 等众多主流服务的数据包抓取、分析、报表展示。
- 由于是以机器为单位进行统计,要想了解一个集群的热点 key,需要进行后期汇总。
| 方案 | 优点 | 缺点 |
|---|---|---|
| 客户端 | 实现简单 | - 内存泄漏隐患- 维护成本高- 只能统计单个客户端 |
| 代理 | 代理是客户端和服务端的桥梁,实现最方案最系统 | 增加代理端的开发部署成本 |
| 服务端 | 实现简单 | - Monitor 本身的使用成本和危害,只能短时间使用- 只能统计单个 Redis 节点 |
| 机器 | 对于客户端和服务端无侵入和影响 | 需要专业的运维团队开发,并且增加了机器的部署成本 |
下面是三种方案的思路:
- 拆分复杂数据结构:如果当前 key 的类型是一个二级数据结构,例如哈希类型。如果该哈希元素个数较多,可以考虑将当前 hash 进行拆分,这样该热点 key 可以拆分为若干个新的 key 分布到不同 Redis 节点上,从而减轻压力。
- 迁移热点 key:以 Redis- Cluster 为例,可以将热点 key 所在的 slot 单独迁移到一个新的 Redis 节点上,但此操作会增加运维成本。
- 本地缓存加通知机制:可以将热点 key 放在业务端的本地缓存中,因为是在业务端的本地内存中,处理能力要高出 Redis 数十倍,但当数据更新时,此种模式会造成各个业务端和 Redis 数据不一致,通常会使用发布订阅机制来解决类似问题。
27、汇总
- bigkey 的危害不容忽视:数据倾斜、超时阻塞、网络拥塞,可能是 Redis 生产环境中的一颗定时炸弹,删除 bigkey 时通常使用渐进式遍历的方式,防止出现 Redis 阻塞的情况。
- 通过客户端、代理、monitor、机器抓包四种方式找到热点 key,这几种方式各具优势,具体使用哪种要根据当前场景来决定。
本文由 简悦 SimpRead 转码, 原文地址 blog.csdn.net
十三、Redis 配置统计字典
1、info 系统状态说明
- info 命令的使用方法有以下三种:
- info:部分 Redis 系统状态统计信息。
- info all:全部 Redis 系统状态统计信息。
- info section:某一块的系统状态统计信息,其中 section 可以忽略大小写。
- 例如,只对 Redis 的内存相关统计比较感兴趣,可以执行 info memory,此时 section=memory。
- info all 命令包含 Redis 最全的系统状态信息。
- info Server 模块的统计信息,包含了 Redis 服务本身的一些信息,例如版本号、运行模式、操作系统的版本、TCP 端口等。
- info Clients 模块的统计信息,包含了连接数、阻塞命令连接数、输入输出缓冲区等相关统计信息。
- info Memory 模块的统计信息,包含了 Redis 内存使用、系统内存使用、碎片率、内存分配器等相关统计信息。
- info Persistence 模块的统计信息,包含了 RDB 和 AOF 两种持久化的一些统计信息。
- info Stats 模块的统计信息,是 Redis 的基础统计信息,包含了:连接、命令、网络、过期、同步等很多统计信息。
- info Replication 模块的统计信息,包含了 Redis 主从复制的一些统计信息,根据主从节点,统计信息也略有不同。
- info CPU 模块的统计信息,包含了 Redis 进程和子进程对于 CPU 消耗的一些统计信息。
- info Commandstats 模块的统计信息,是 Redis 命令统计信息,包含各个命令的命令名、总次数、总耗时、平均耗时。
- info Cluster 模块的统计信息,目前只有一个统计信息,标识当前 Redis 是否为 Cluster 模式。
- info Keyspace 模块的统计信息,包含了每个数据库的键值统计信息。
info 命令所有的 section(info all 命令涉及的所有 section,其中每个模块名就是我们上面提到的 section):
| 模块名 | 模块含义 |
|---|---|
| Server | 服务器信息 |
| Clients | 客户端信息 |
| Memory | 内存信息 |
| Persistence | 持久化信息 |
| Stats | 全局统计信息 |
| Replication | 复制信息 |
| CPU | CPU 消耗信息 |
| Commandstats | 命令统计信息 |
| Cluster | 集群信息 |
| Keyspace | 数据库键统计信息 |
1)info Server 模块统计信息
| 属性名 | 属性值 | 属性描述 |
|---|---|---|
| redis_version | 3.0.7 | Redis 服务版本 |
| redis_git_sha1 | 00000000 | Git SHA1 |
| redis_git_dirty | 0 | Git dirty flag |
| redis_build_id | 186eba9451cf9390 | Redis build id |
| redis_mode | cluster | 运行模式,分为:Cluster、Sentinel、Standalone |
| os | Linux 2.6.18-274.el5 x86_64 | Redis 所在机器的操作系统 |
| arch_bits | 64 | 架构 (32 或 64 位) |
| multiplexing_api | epoll | Redis 所使用的事件处理机制 |
| gcc_version | 4.1.2 | 编译 Redis 时所使用的 GCC 版本 |
| process_id | 31524 | Redis 服务进程的 PID |
| run_id | fd8b97739c469526f640b8895a5084d669ed151f | Redis 服务的标识符 |
| tcp_port | 6384 | 监听端口 |
| uptime_in_seconds | 9753347 | 自 Redis 服务启动以来,运行的秒数 |
| uptime_in_days | 112 | 自 Redis 服务启动以来,运行的天数 |
| hz | 10 | serverCron 每秒运行次数 |
| lru_clock | 16388503 | 以分钟为单位进行自增的时钟,用于 LRU 管理 |
| config_file | /opt/cachecloud/conf/redis-cluster-6384.conf | Redis 的配置文件 |
2)info Clients 模块统计信息
| 属性名 | 属性值 | 属性描述 |
|---|---|---|
| connected_clients | 262 | 当前客户端连接数 |
| client_longest_output_list | 0 | 当前所有输出缓冲区中队列对象个数的最大值 |
| client_biggest_input_buf | 0 | 当前所有输入缓冲区中占有的最大容量 |
| blocked_clients | 0 | 正在等待阻塞命令 (例如 BLPOP 等) 的客户端数量 |
3)info Memory 模块统计信息
| 属性名 | 属性值 | 属性描述 |
|---|---|---|
| used_memory | 183150904 | Redis 分配器分配的内存总量,也就是内部存储的所有数据内存占用量 |
| used_memory_human | 174.67M | 以可读的格式返回 used_memory |
| used_memory_rss | 428621824 | 从操作系统的角度,Redis 进程占用的物理内存总量 |
| used_memory_peak | 522768352 | 内存使用的最大值,表示 used_memory 的峰值 |
| used_memory_peak_human | 498.55M | 以可读的格式返回 used_memory_peak |
| used_memory_lua | 35840 | Lua 引擎所消耗的内存大小 |
| mem_fragmentation_ratio | 2.34 | used_memory_rss/used_memory 比值,表示内存碎片率 |
| mem_allocator | jemalloc-3.6.0 | Redis 所使用的内存分配器。默认为:jemalloc |
4)info Persistence 模块统计信息
| 属性名 | 属性值 | 属性描述 |
|---|---|---|
| loading | 0 | 是否在加载持久化文件。0 否,1 是 |
| rdb_changes_since_last_save | 53308858 | 自上次 RDB 后,Redis 数据改动条数 |
| rdb_bgsave_in_progress | 0 | 标识 RDB 的 bgsave 操作是否进行中。0 否,1 是 |
| rdb_last_save_time | 1456376460 | 上次 bgsave 操作的时间戳 |
| rdb_last_bgsave | ok | 上次 bgsave 操作状态 |
| rdb_last_bgsave_time_sec | 3 | 上次 bgsave 操作使用的时间 (单位是秒) |
| rdb_current_bgsave_time_sec | -1 | 如果 bgsva 操作正在进行,则记录当前 bgsave 操作使用的时间 (单位是秒) |
| aof_enabled | 1 | 是否开启了 AOF 功能。0 否,1 是 |
| aof_rewrite_in_progress | 0 | 标识 AOF 的 rewrite 操作是否在进行中。0 否,1 是 |
| aof_rewrite_scheduled | 0 | 标识是否将要在 RDB 的 bgsave 操作结束后执行 AOF rewrite 操作 |
| aof_last_rewrite_time_sec | 0 | 上次 AOF rewrite 操作使用的时间 (单位是秒) |
| aof_current_rewrite_time_sec | -1 | 如果 rewrite 操作正在进行,则记录当前 AOF rewrite 所使用的时间 (单位是秒) |
| aof_last_bgrewrite_status | ok | 上次 AOF 重写操作的状态 |
| aof_last_write_status | ok | 上次 AOF 写磁盘的结果 |
| aof_current_size | 186702421 | AOF 当前尺寸 (单位是字节) |
| aof_base_size | 134279710 | AOF 上次启动或 rewrite 的尺寸 (单位是字节) |
| aof_buffer_length | 0 | AOF buffer 的大小 |
| aof_rewrite_buffer_length | 0 | AOF rewrite buffer 的大小 |
| aof_pending_bio_fsync | 0 | 后台 IO 队列中等待 fsync 任务的个数 |
| aof_delayed_fsync | 64 | 延迟的 fsync 计数器 |
5)info Stats 模块统计信息
| 属性名 | 属性值 | 属性描述 |
|---|---|---|
| total_connections_received | 495967 | 连接过的客户端总数 |
| total_commands_processed | 5139857171 | 执行过的命令总数 |
| instantaneous_ops_per_sec | 511 | 每秒处理命令总数 |
| total_net_input_bytes | 282961395316 | 输入总网络流量 (以字节为单位) |
| total_net_output_bytes | 1760503612586 | 输出总网络流量 (以字节为单位) |
| instantaneous_input_kbps | 28.24 | 每秒输入的字节数 |
| instantaneous_output_kbps | 234.90 | 每秒输出的字节数 |
| rejected_connections | 0 | 拒绝的连接个数 |
| sync_full | 4 | 主从完全同步成功次数 |
| sync_partial_ok | 0 | 主从部分同步成功次数 |
| sync_partial_err | 0 | 主从部分同步失败次数 |
| expired_keys | 45534039 | 过期的 key 数量 |
| evicted_keys | 0 | 剔除 (超过了 maxmemory 后) 的 key 数量 |
| keyspace_hits | 3923837939 | 命中次数 |
| keyspace_misses | 1078922155 | 不命中次数 |
| pubsub_channels | 0 | 当前使用中的频道数量 |
| pubsub_patterns | 0 | 当前使用中的模式数量 |
| latest_fork_usec | 16194 | 最近一次 fork 操作消耗的时间 (微秒) |
| migrate_cached_sockets | 0 | 记录当前 Redis 正在进行 migrate 操作的目标 Redis 个数。例如 Redis A 分别向 Redis B 和 C 执行 migrate 操作,那么这个值就是 2 |
6)info Replication 模块统计信息
| 角色 | 属性名 | 属性值 | 属性描述 |
|---|---|---|---|
| 通用配置 | role | master | slave |
| 主节点 | connected_slaves | 1 | 连接的从节点个数 |
| 主节点 | slave0 | slabe0:op=10.10.xx.169,port=6382,state=online,offset=426978948465,lag=1 | 连接的从节点信息 |
| 主节点 | master_repl_offset | 426978955146 | 主节点偏移量 |
| 从节点 | master_host | 10.10.xx.64 | 主节点 IP |
| 从节点 | master_port | 6387 | 主节点端口 |
| 从节点 | master_link_status | up | 与主节点的连接状态 |
| 从节点 | master_last_io_seconds_ago | 0 | 主节点最后与从节点的通信时间间隔,单位为秒 |
| 从节点 | master_sync_in_progress | 0 | 从节点是否正在全量同步主节点 RDB 文件 |
| 从节点 | slave_repl_offset | 426978956171 | 复制偏移量 |
| 从节点 | slave_priority | 100 | 从节点优先级 |
| 从节点 | slave_read_only | 1 | 从节点是否只读 |
| 从节点 | connected_slaves | 0 | 连接从节点个数 |
| 从节点 | master_repl_offset | 0 | 当前从节点作为其他节点的主节点时的复制偏移量 |
| 通用配置 | repl_backlog_active | 1 | 复制缓冲区状态 |
| 通用配置 | repl_backlog_size | 10000000 | 复制缓冲区尺寸 (单位: 字节) |
| 通用配置 | repl_backlog_first_byte_offset | 426968955147 | 复制缓冲区起始偏移量,标识当前缓冲区可用范围 |
| 通用配置 | repl_backlog_histlen | 10000000 | 标识复制缓冲区已存有效数据长度 |
7)info CPU 模块统计信息
| 属性名 | 属性值 | 属性描述 |
|---|---|---|
| used_cpu_sys | 31957.30 | Redis 主进程在内核态所占用的 CPU 时钟总和 |
| used_cpu_user | 72484.27 | Redis 主进程在用户态所占用的 CPU 时钟总和 |
| used_cpu_sys_children | 121.49 | Redis 子进程在内核态所占用的 CPU 时钟总和 |
| used_cput_user_children | 195.13 | Redis 子进程在用户态所占用的 CPU 时钟总和 |
8)info Commandstats 模块统计信息
| 属性名 | 属性值 | 属性描述 |
|---|---|---|
| cmdstat_get | calls=3738730699,usec=11054972404,usec_per_call=2.96 | get 命令调用总次数、总耗时、平均耗时 (单位: 微秒) |
| cmdstat_set | calls=50174458,usec=323143686,usec_per_call=6.44 | set 命令调用总次数、总耗时、平均耗时 (单位: 微秒) |
9)info Cluster 模块统计信息
| 属性名 | 属性值 | 属性描述 |
|---|---|---|
| cluster_enabled | 1 | 节点是否为 cluster 模式。1 是,0 否 |
10)info Keyspace 模块统计信息
| 属性名 | 属性值 | 属性描述 |
|---|---|---|
| db0 | db0:keys=106430,expires=56107,avg_ttl=60283952 | 当前数据库 key 总数,带有过期时间的 key 总数,平均存活时间 |
2、standalone 配置说明和分析 (Redis 单机模式)
1)Redis 的一些总体配置,例如端口、 日志、数据库等。
| 配置名 | 含义 | 默认值 | 可选值 | 可否支持 config set 配置热生效 |
|---|---|---|---|---|
| daemonize | 是否是守护进程 | no | yes | no |
| port | 端口号 | 6379 | 整数 | 不可以 |
| loglevel | 日志级别 | notice | debug | verbose |
| logfile | 日志文件名 | 空 | 自定义,建议以端口号为名 | 不可以 |
| databases | 可用的数据库数 | 16 | 整数 | 不可以 |
| unixsocket | unix 套接字 | 空 (不通过 unix 套接字来监听) | 指定套接字文件 | 不可以 |
| unixsocketperm | unix 套接字权限 | 0 | Linux 三位数权限 | 不可以 |
| pidfile | Redis 运行的进程 pid 文件 | /var/run/redis.pid | /var/run/redis-{port}.pid | 不可以 |
| lua-time-limit | Lua 脚本 “超时时间”(单位: 毫秒) | 5000 | 整数,但是此超时不会真正停止脚本运行 | 可以 |
| tcp-backlog | tcp-backlog | 511 | 整数 | 不可以 |
| watchdog-period | 看门狗,用于诊断 Redis 的延迟问题,此参数是检查周期。(此参数需要在运行时配置才能生效) | 0 | 整数 | 可以 |
| activerehashing | 指定是否激活重置哈希 | yes | yes | no |
| dir | 工作目录 (aof、rdb、日志文件都存放在此目录) | ./(当前目录) | 自定义 | 可以 |
2)Redis 内存相关配置。
| 配置名 | 含义 | 默认值 | 可选值 | 可否支持 config set 配置热生效 |
|---|---|---|---|---|
| maxmemory | 最大可用内存 (单位字节) | 0(没有限制) | 整数 | 可以 |
| maxmemory-policy | 内存不够时,淘汰策略 | noeviction | volatile-lru -> 用 lru 算法删除过期的键值allkeys-lru -> 用 lru 算法删除所有键值volatile-random -> 随机删除过期的键值allkeys-random -> 随机删除任何键值volatile-ttl -> 删除最近要到期的键值noeviction -> 不删除键 | 可以 |
| maxmemory-samples | 检测 LRU 采样数 | 5 | 整数 | 可以 |
3)AOF 方式持久化相关配置
| 配置名 | 含义 | 默认值 | 可选值 | 可否支持 config set 配置热生效 |
|---|---|---|---|---|
| appendonly | 是否开启 AOF 持久化模式 | no | no | yes |
| appendfsync | AOF 同步磁盘频率 | everysec | always | everysec |
| appendfilename | AOF 文件名 | appendonly.aof | appendonly-{port}.aof | 不可以 |
| aof-load-truncated | 加载 AOF 文件时,是否忽略 AOF 文件不完整的情况,让 Redis 正常启动 | yes | no | 可以 |
| no-appendfsync-on-rewrite | 设置为 yes 表示 rewrite 期间对新写操作不 fsync,暂时存在缓冲区中,等 rewrite 完成后再写入 | no | no | yes |
| auto-aof-rewrite-min-size | 触发 rewrite 的 AOF 文件最小阈值 (单位: 兆) | 64m | 整数 + m(代表兆) | 可以 |
| auto-aof-rewrite-percentage | 触发 rewrite 的 AOF 文件的增长比例条件 | 100 | 整数 | 可以 |
| aof-rewrite-incremental-fsync | AOF 重写过程中,是否采取增量文件同步策略 | yes | yes | no |
4)RDB 方式持久化相关配置
| 配置名 | 含义 | 默认值 | 可选值 | 可否支持 config set 配置热生效 |
|---|---|---|---|---|
| save | RDB 保存条件 | save 900 1save 300 10save 60 10000 | 如果没有该配置,代表不使用自动 RDB 策略 | 可以 |
| dbfilename | RDB 文件名 | dump.rdb | dump-{port}.rdb | 可以 |
| rdbcompression | RDB 文件是否压缩 | yes | yes | no |
| rdbchecksum | RDB 文件是否使用校验和 | yes | yes | no |
| stop-write-on-bgsave-error | bgsave 执行错误,是否停止 Redis 接受写请求 | yes | yes | no |
5)Redis 慢查询相关配置
| 配置名 | 含义 | 默认值 | 可选值 | 可否支持 config set 配置热生效 |
|---|---|---|---|---|
| slow-log-slower-than | 慢查询被记录的阀值 (单位微妙) | 10000 | 整数 | 可以 |
| slowlog-max-len | 最多记录慢查询的条数 | 128 | 整数 | 可以 |
| latency-monitor-threshold | Redis 服务内存延迟监控 | 0(关闭) | 整数 | 可以 |
6)Redis 数据结构优化的相关配置
| 配置名 | 含义 | 默认值 | 可选值 | 可否支持 config set 配置热生效 |
|---|---|---|---|---|
| hash-max-ziplist-entries | hash 数据结构优化参数 | 512 | 整数 | 可以 |
| hash-max-ziplist-value | hash 数据结构优化参数 | 64 | 整数 | 可以 |
| list-max-ziplist-entries | list 数据结构优化参数 | 512 | 整数 | 可以 |
| list-max-ziplist-value | list 数据结构优化参数 | 64 | 整数 | 可以 |
| set-max-intset-entries | set 数据结构优化参数 | 512 | 整数 | 可以 |
| zset-max-ziplist-entries | zset 数据结构优化参数 | 128 | 整数 | 可以 |
| zset-max-ziplist-value | zset 数据结构优化参数 | 64 | 整数 | 可以 |
| hll-sparse-max-bytes | HyperLogLog 数据结构优化参数 | 3000 | 整数 | 可以 |
7)Redis 复制相关的配置
| 配置名 | 含义 | 默认值 | 可选值 | 可否支持 config set 配置热生效 |
|---|---|---|---|---|
| slaveof | 指定当前从节点复制哪个主节点,参数:主节点的 ip 和 port | 空 | ip 和端口 | 不可以,但可以用 slaveof 命令设置 |
| repl-ping-slave-period | 主节点定期向从节点发送 ping 命令的周期,用于判定从节点是否存活。(单位: 秒) | 10 | 整数 | 可以 |
| repl-timeout | 主从节点复制超时时间 (单位: 秒) | 60 | 整数 | 可以 |
| repl-backlog-size | 复制积压缓存区大小 | 1M | 整数 | 可以 |
| repl-backlog-ttl | 主节点在没有从节点的情况下多长时间后释放复制积压缓存区空间 | 3600 | 整数 | 可以 |
| slave-priority | 从节点的优先级 | 100 | 0-100 | 可以 |
| min-slaves-to-write | 当主节点发现从节点数量小于 min-slaves-to-write 且延迟小于等于 min-slaves-max-lag 时,master 停止写入操作 | 0 | 整数 | 可以 |
| min-slaves-max-lag | 当主节点发现从节点数量小于 min-slaves-to-write 且延迟小于等于 min-slaves-max-lag 时,master 停止写入操作 | 10 | 整数 | 可以 |
| slave-serve-stale-data | 当从节点与主节点连接中断时,如果此参数值设置为 “yes”,从节点可以继续处理客户端的请求。否则除 info 和 slaveof 命令之外,拒绝的所有请求并统一回复 “SYNC with master in process” | yes | yes | no |
| slave-read-only | 从节点是否开启只读模式,集群架构下从节点默认读写都不可用,需要调用 readonly 命令开启只读模式 | yes | yes | no |
| repl-disble-tcp-nodelay | 是否开启主从复制 socket 的 NO_DELAY 选项:yes:Redis 会合并小的 TCP 包来节省带宽,但是这样增加同步延迟,造成主从数据不一致no: 主节点会立即发送同步数据,没有延迟 | no | yes | no |
| repl-diskless-sync | 是否开启无盘复制 | no | yes | no |
| repl-diskless-sync-delay | 开启无盘复制后,需要延迟多少秒后进行创建 RDB 操作,一般用于同时加入多个从节点时,保证多个从节点可共享 RDB | 5 | 整数 | 可以 |
8)Redis 客户端的相关配置
| 配置名 | 含义 | 默认值 | 可选值 | 可否支持 config set 配置热生效 |
|---|---|---|---|---|
| maxclients | 最大客户端连接数 | 10000 | 整数 | 可以 |
| client-output-buffer-limit | 客户端输出缓冲区限制 | normal 0 0 0 slave 268435456 67108864 60 pubsub 33554432 8388608 60 | 整数 | 可以 |
| timeout | 客户端闲置多少秒后关闭连接 (单位: 秒) | 0(永不关闭) | 整数 | 可以 |
| tcp-keepalive | 检测 TCP 连接活性的周期 (单位: 秒) | 0(不检测) | 整数 | 可以 |
9)Redis 安全的相关配置
| 配置名 | 含义 | 默认值 | 可选值 | 可否支持 config set 配置热生效 |
|---|---|---|---|---|
| requirepass | 密码 | 空 | 自定义 | 可以 |
| bind | 绑定 IP | 空 | 自定义 | 不可以 |
| masterauth | 从节点需要配置的主节点密码 | 空 | 主节点的密码 | 可以 |
3、Sentinel 配置说明和分析
1)Sentinel 节点是特殊的 Redis 节点,有几个特殊的配置
Redis Sentinel 节点配置说明
| 参数名 | 含义 | 默认值 | 可选值 | 可否支持 sentinel set 配置热生效 |
|---|---|---|---|---|
| sentinel monitor | 定义监控的主节点名、ip、port、主观下线票数 | sentinel monitor mymaster 127.0.0.1 6379 2 | 自定义 masterName、实际的 ip:port、票数 | 支持 |
| sentinel down-after-milliseconds | Sentinel 判定节点不可达的毫秒数 | sentinel down-after-milliseconds mymaster 30000 | 整数 | 支持 |
| sentinel parallel-sync | 在执行故障转移时,最多有多少个从服务器同时对新的主服务器进行同步 | sentinel parallel-sync mymaster 1 | 大于 0,不超过从服务器个数 | 支持 |
| sentinel failover-timeout | 故障迁移超时时间 | sentinel failover-timeout mymaster 180000 | 整数 | 支持 |
| sentinel auth-pass | 主节点密码 | 空 | 主节点密码 | 支持 |
| sentinel notification-script | 故障转移期间脚本通知 | 空 | 脚本文件路径 | 支持 |
| sentinel client-reconfig-script | 故障转移成功后脚本通知 | 空 | 脚本文件路径 | 支持 |
4、Cluster 配置说明和分析
1)Cluster 节点是特殊的 Redis 节点,有几个特殊的配置
Redis Cluster 配置说明
| 参数名 | 含义 | 默认值 | 可选值 | 可否支持 config set 配置热生效 |
|---|---|---|---|---|
| cluster-node-timeout | 集群节点超时时间 (单位: 毫秒) | 15000 | 整数 | 可以 |
| cluster-migration-barrier | 主从节点切换需要的从节点数最小个数 | 1 | 整数 | 可以 |
| cluster-slave-validity-factor | 从节点有效性判断因子,当从节点与主节点最后通行时间超过 (cluster-node-timeout*slave-validity-factor)+repl-ping-slave-period 时,对应从节点不具备故障转移资格,防止断线时间过长的从节点进行故障转移。设置为 0 标叔从节点永不过期。 | 10 | 整数 | 可以 |
| cluster-require-full-converage | 集群是否需要所有的 slot 都分配给在线节点,才能正常访问 | yes | yes | no |
| cluster-enabled | 是否开启集群模式 | yes | yes | no |
| cluster-config-file | 集群配置文件名称 | node.conf | nodes-{port}.conf | 不可以 |















 4755
4755

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









