







引言
quratz是目前最为成熟,使用最广泛的java任务调度框架,功能强大配置灵活.在企业应用中占重要地位.quratz在集群环境中的使用方式是每个企业级系统都要考虑的问题.早在2006年,在ITeye上就有一篇关于quratz集群方案的讨论:http://www.iteye.com/topic/40970 ITeye创始人@Robbin在8楼给出了自己对quartz集群应用方案的意见.
后来有人总结了三种quratz集群方案:http://www.iteye.com/topic/114965
1.单独启动一个Job Server来跑job,不部署在web容器中.其他web节点当需要启动异步任务的时候,可以通过种种方式(DB, JMS, Web Service, etc)通知Job Server,而Job Server收到这个通知之后,把异步任务加载到自己的任务队列中去。
2.独立出一个job server,这个server上跑一个spring+quartz的应用,这个应用专门用来启动任务。在jobserver上加上hessain,得到业务接口,这样jobserver就可以调用web container中的业务操作,也就是正真执行任务的还是在cluster中的tomcat。在jobserver启动定时任务之后,轮流调用各地址上的业务操作(类似apache分发tomcat一样),这样可以让不同的定时任务在不同的节点上运行,减低了一台某个node的压力
3.quartz本身事实上也是支持集群的。在这种方案下,cluster上的每一个node都在跑quartz,然后也是通过数据中记录的状态来判断这个操作是否正在执行,这就要求cluster上所有的node的时间应该是一样的。而且每一个node都跑应用就意味着每一个node都需要有自己的线程池来跑quartz.
总的来说,第一种方法,在单独的server上执行任务,对任务的适用范围有很大的限制,要访问在web环境中的各种资源非常麻烦.但是集中式的管理容易从架构上规避了分布式环境的种种同步问题.第二种方法在在第一种方法的基础上减轻了jobserver的重量,只发送调用请求,不直接执行任务,这样解决了独立server无法访问web环境的问题,而且可以做到节点的轮询.可以有效地均衡负载.第三种方案是quartz自身支持的集群方案,在架构上完全是分布式的,没有集中的管理,quratz通过数据库锁以及标识字段保证多个节点对任务不重复获取,并且有负载平衡机制和容错机制,用少量的冗余,换取了高可用性(high avilable HA)和高可靠性.(个人认为和git的机制有异曲同工之处,分布式的冗余设计,换取可靠性和速度).
本文旨在研究quratz为解决分布式任务调度中存在的防止重复执行和负载均衡等问题而建立的机制.以调度流程作为顺序,配合源码理解其中原理.
quratz的配置,及具体应用请参考CRM项目组的另一篇文章:CRM使用Quartz集群总结分享
quartz集群架构
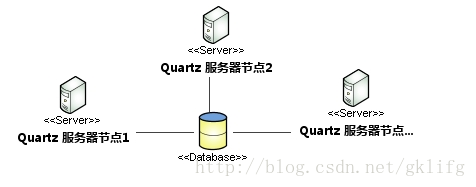
quartz的分布式架构如上图,可以看到数据库是各节点上调度器的枢纽.各个节点并不感知其他节点的存在,只是通过数据库来进行间接的沟通.
实际上,quartz的分布式策略就是一种以数据库作为边界资源的并发策略.每个节点都遵守相同的操作规范,使得对数据库的操作可以串行执行.而不同名称的调度器又可以互不影响的并行运行.
组件间的通讯图如下:(*注:主要的sql语句附在文章最后)
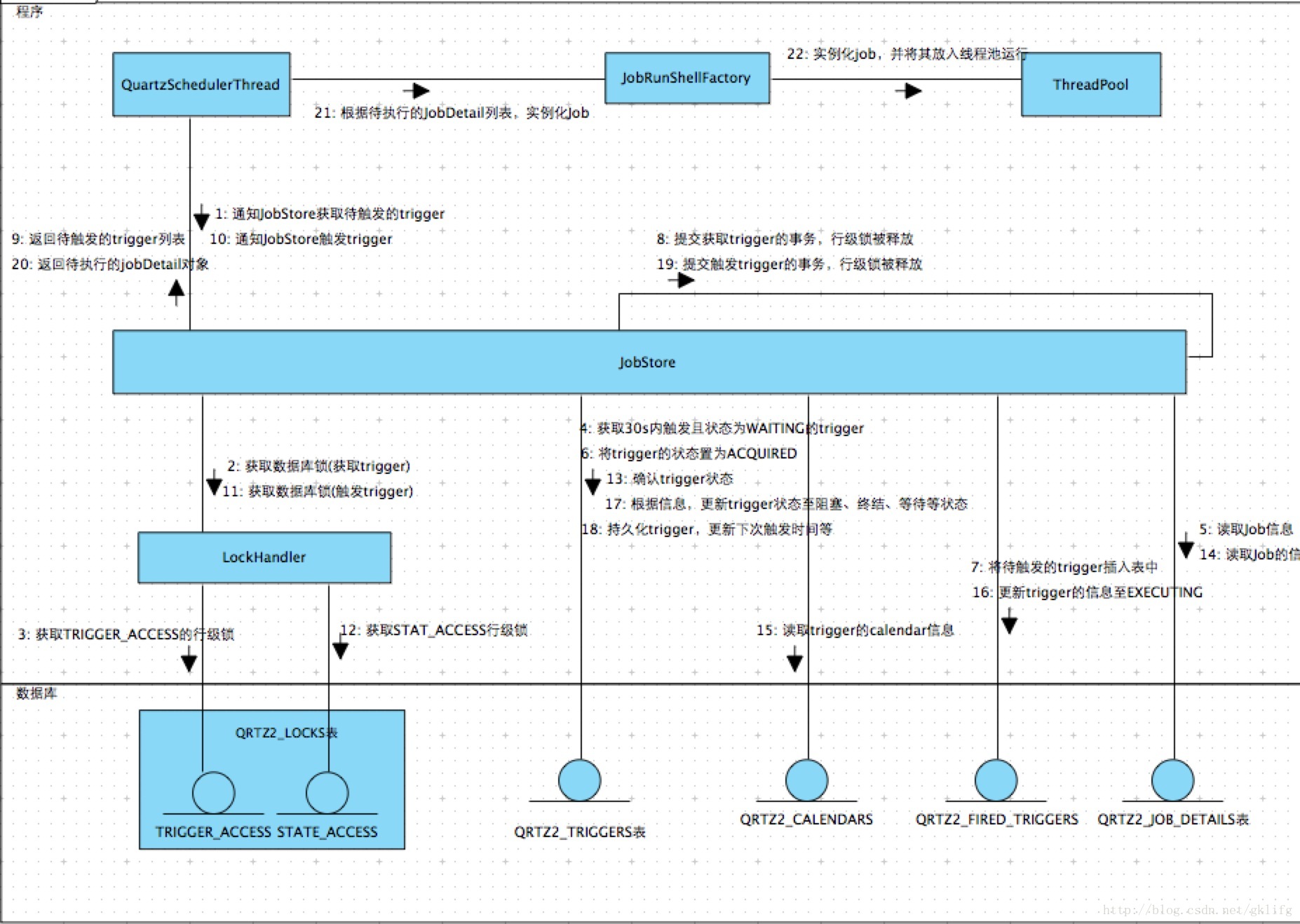
quartz运行时由QuartzSchedulerThread类作为主体,循环执行调度流程。JobStore作为中间层,按照quartz的并发策略执行数据库操作,完成主要的调度逻辑。JobRunShellFactory负责实例化JobDetail对象,将其放入线程池运行。LockHandler负责获取LOCKS表中的数据库锁。
整个quartz对任务调度的时序大致如下:
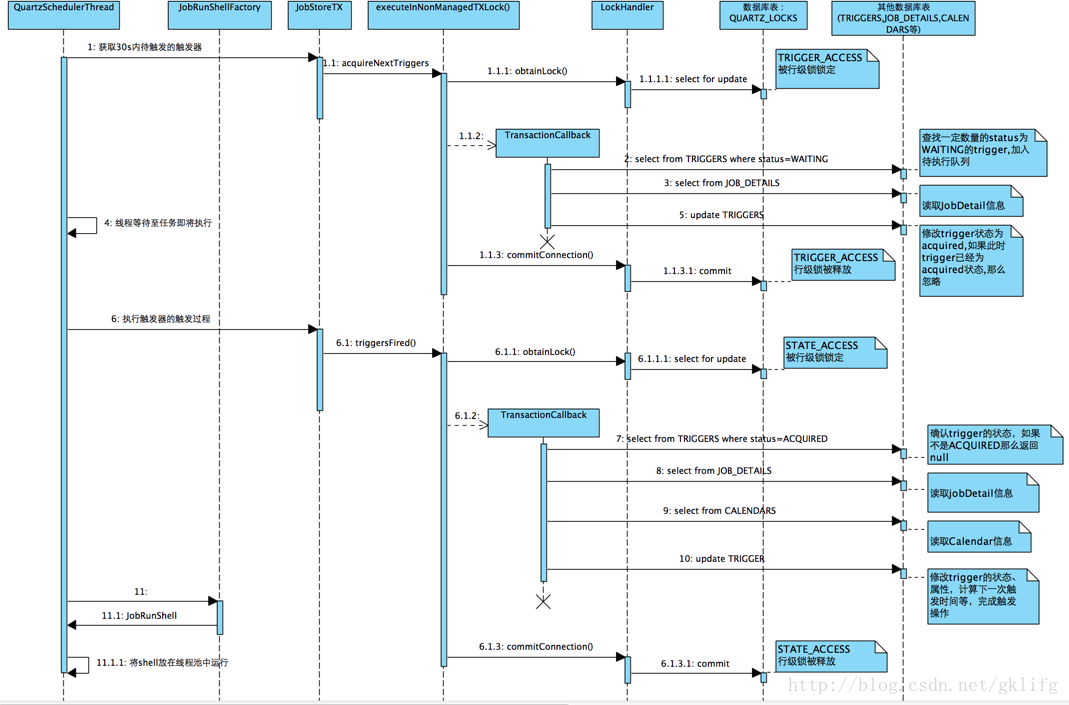
梳理一下其中的流程,可以表示为:
0.调度器线程run()
1.获取待触发trigger
1.1数据库LOCKS表TRIGGER_ACCESS行加锁
1.2读取JobDetail信息
1.3读取trigger表中触发器信息并标记为"已获取"
1.4commit事务,释放锁
2.触发trigger
2.1数据库LOCKS表STATE_ACCESS行加锁
2.2确认trigger的状态
2.3读取trigger的JobDetail信息
2.4读取trigger的Calendar信息
2.3更新trigger信息
2.3commit事务,释放锁
3实例化并执行Job
3.1从线程池获取线程执行JobRunShell的run方法
可以看到,这个过程中有两个相似的过程:同样是对数据表的更新操作,同样是在执行操作前获取锁 操作完成后释放锁.这一规则可以看做是quartz解决集群问题的核心思想.
规则流程图:
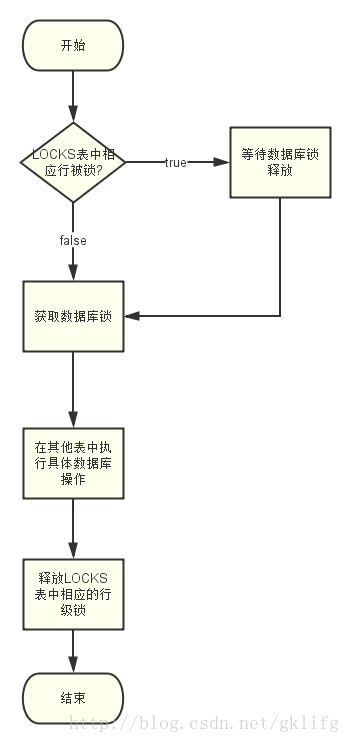
进一步解释这条规则就是:一个调度器实例在执行涉及到分布式问题的数据库操作前,首先要获取QUARTZ2_LOCKS表中对应当前调度器的行级锁,获取锁后即可执行其他表中的数据库操作,随着操作事务的提交,行级锁被释放,供其他调度器实例获取.
集群中的每一个调度器实例都遵循这样一种严格的操作规程,那么对于同一类调度器来说,每个实例对数据库的操作只能是串行的.而不同名的调度器之间却可以并行执行.
下面我们深入源码,从微观上观察quartz集群调度的细节
调度器实例化
一个最简单的quartz helloworld应用如下:
public
class
HelloWorldMain {
Log log = LogFactory.getLog(HelloWorldMain.
class
);
public
void
run() {
try
{
//取得Schedule对象
SchedulerFactory sf =
new
StdSchedulerFactory();
Scheduler sch = sf.getScheduler();
JobDetail jd =
new
JobDetail(
"HelloWorldJobDetail"
,Scheduler.DEFAULT_GROUP,HelloWorldJob.
class
);
Trigger tg = TriggerUtils.makeMinutelyTrigger(
1
);
tg.setName(
"HelloWorldTrigger"
);
sch.scheduleJob(jd, tg);
sch.start();
}
catch
( Exception e ) {
e.printStackTrace();
}
}
public
static
void
main(String[] args) {
HelloWorldMain hw =
new
HelloWorldMain();
hw.run();
}
}
|
我们看到初始化一个调度器需要用工厂类获取实例:
SchedulerFactory sf =
new
StdSchedulerFactory();
Scheduler sch = sf.getScheduler();
|
然后启动:
sch.start();
|
下面跟进StdSchedulerFactory的getScheduler()方法:
public
Scheduler getScheduler()
throws
SchedulerException {
if
(cfg ==
null
) {
initialize();
}
SchedulerRepository schedRep = SchedulerRepository.getInstance();
//从"调度器仓库"中根据properties的SchedulerName配置获取一个调度器实例
Scheduler sched = schedRep.lookup(getSchedulerName());
if
(sched !=
null
) {
if
(sched.isShutdown()) {
schedRep.remove(getSchedulerName());
}
else
{
return
sched;
}
}
//初始化调度器
sched = instantiate();
return
sched;
}
|
跟进初始化调度器方法sched = instantiate();发现是一个700多行的初始化方法,涉及到
- 读取配置资源,
- 生成QuartzScheduler对象,
- 创建该对象的运行线程,并启动线程;
- 初始化JobStore,QuartzScheduler,DBConnectionManager等重要组件,
至此,调度器的初始化工作已完成,初始化工作中quratz读取了数据库中存放的对应当前调度器的锁信息,对应CRM中的表QRTZ2_LOCKS,中的STATE_ACCESS,TRIGGER_ACCESS两个LOCK_NAME.
public
void
initialize(ClassLoadHelper loadHelper,
SchedulerSignaler signaler)
throws
SchedulerConfigException {
if
(dsName ==
null
) {
throw
new
SchedulerConfigException(
"DataSource name not set."
);
}
classLoadHelper = loadHelper;
if
(isThreadsInheritInitializersClassLoadContext()) {
log.info(
"JDBCJobStore threads will inherit ContextClassLoader of thread: "
+ Thread.currentThread().getName());
initializersLoader = Thread.currentThread().getContextClassLoader();
}
this
.schedSignaler = signaler;
// If the user hasn't specified an explicit lock handler, then
// choose one based on CMT/Clustered/UseDBLocks.
if
(getLockHandler() ==
null
) {
// If the user hasn't specified an explicit lock handler,
// then we *must* use DB locks with clustering
if
(isClustered()) {
setUseDBLocks(
true
);
}
if
(getUseDBLocks()) {
if
(getDriverDelegateClass() !=
null
&& getDriverDelegateClass().equals(MSSQLDelegate.
class
.getName())) {
if
(getSelectWithLockSQL() ==
null
) {
//读取数据库LOCKS表中对应当前调度器的锁信息
String msSqlDflt =
"SELECT * FROM {0}LOCKS WITH (UPDLOCK,ROWLOCK) WHERE "
+ COL_SCHEDULER_NAME +
" = {1} AND LOCK_NAME = ?"
;
getLog().info(
"Detected usage of MSSQLDelegate class - defaulting 'selectWithLockSQL' to '"
+ msSqlDflt +
"'."
);
setSelectWithLockSQL(msSqlDflt);
}
}
getLog().info(
"Using db table-based data access locking (synchronization)."
);
setLockHandler(
new
StdRowLockSemaphore(getTablePrefix(), getInstanceName(), getSelectWithLockSQL()));
}
else
{
getLog().info(
"Using thread monitor-based data access locking (synchronization)."
);
setLockHandler(
new
SimpleSemaphore());
}
}
}
|
当调用sch.start();方法时,scheduler做了如下工作:
1.通知listener开始启动
2.启动调度器线程
3.启动plugin
4.通知listener启动完成
public
void
start()
throws
SchedulerException {
if
(shuttingDown|| closed) {
throw
new
SchedulerException(
"The Scheduler cannot be restarted after shutdown() has been called."
);
}
// QTZ-212 : calling new schedulerStarting() method on the listeners
// right after entering start()
//通知该调度器的listener启动开始
notifySchedulerListenersStarting();
if
(initialStart ==
null
) {
initialStart =
new
Date();
//启动调度器的线程
this
.resources.getJobStore().schedulerStarted();
//启动plugins
startPlugins();
}
else
{
resources.getJobStore().schedulerResumed();
}
schedThread.togglePause(
false
);
getLog().info(
"Scheduler "
+ resources.getUniqueIdentifier() +
" started."
);
//通知该调度器的listener启动完成
notifySchedulerListenersStarted();
}
|
调度过程
调度器启动后,调度器的线程就处于运行状态了,开始执行quartz的主要工作–调度任务.
前面已介绍过,任务的调度过程大致分为三步:
1.获取待触发trigger
2.触发trigger
3.实例化并执行Job
下面分别分析三个阶段的源码.
QuartzSchedulerThread是调度器线程类,调度过程的三个步骤就承载在run()方法中,分析见代码注释:
public
void
run() {
boolean
lastAcquireFailed =
false
;
//
while
(!halted.get()) {
try
{
// check if we're supposed to pause...
synchronized
(sigLock) {
while
(paused && !halted.get()) {
try
{
// wait until togglePause(false) is called...
sigLock.wait(1000L);
}
catch
(InterruptedException ignore) {
}
}
if
(halted.get()) {
break
;
}
}
/获取当前线程池中线程的数量
int
availThreadCount = qsRsrcs.getThreadPool().blockForAvailableThreads();
if
(availThreadCount >
0
) {
// will always be true, due to semantics of blockForAvailableThreads...
List<OperableTrigger> triggers =
null
;
long
now = System.currentTimeMillis();
clearSignaledSchedulingChange();
try
{
//调度器在trigger队列中寻找30秒内一定数目的trigger准备执行调度,
//参数1:nolaterthan = now+3000ms,参数2 最大获取数量,大小取线程池线程剩余量与定义值得较小者
//参数3 时间窗口 默认为0,程序会在nolaterthan后加上窗口大小来选择trigger
triggers = qsRsrcs.getJobStore().acquireNextTriggers(
now + idleWaitTime, Math.min(availThreadCount, qsRsrcs.getMaxBatchSize()), qsRsrcs.getBatchTimeWindow());
//上一步获取成功将失败标志置为false;
lastAcquireFailed =
false
;
if
(log.isDebugEnabled())
log.debug(
"batch acquisition of "
+ (triggers ==
null
?
0
: triggers.size()) +
" triggers"
);
}
catch
(JobPersistenceException jpe) {
if
(!lastAcquireFailed) {
qs.notifySchedulerListenersError(
"An error occurred while scanning for the next triggers to fire."
,
jpe);
}
//捕捉到异常则值标志为true,再次尝试获取
lastAcquireFailed =
true
;
continue
;
}
catch
(RuntimeException e) {
if
(!lastAcquireFailed) {
getLog().error(
"quartzSchedulerThreadLoop: RuntimeException "
+e.getMessage(), e);
}
lastAcquireFailed =
true
;
continue
;
}
if
(triggers !=
null
&& !triggers.isEmpty()) {
now = System.currentTimeMillis();
long
triggerTime = triggers.get(
0
).getNextFireTime().getTime();
long
timeUntilTrigger = triggerTime - now;
//计算距离trigger触发的时间
while
(timeUntilTrigger >
2
) {
synchronized
(sigLock) {
if
(halted.get()) {
break
;
}
//如果这时调度器发生了改变,新的trigger添加进来,那么有可能新添加的trigger比当前待执行的trigger
//更急迫,那么需要放弃当前trigger重新获取,然而,这里存在一个值不值得的问题,如果重新获取新trigger
//的时间要长于当前时间到新trigger出发的时间,那么即使放弃当前的trigger,仍然会导致xntrigger获取失败,
//但我们又不知道获取新的trigger需要多长时间,于是,我们做了一个主观的评判,若jobstore为RAM,那么
//假定获取时间需要7ms,若jobstore是持久化的,假定其需要70ms,当前时间与新trigger的触发时间之差小于
// 这个值的我们认为不值得重新获取,返回false
//这里判断是否有上述情况发生,值不值得放弃本次trigger,若判定不放弃,则线程直接等待至trigger触发的时刻
if
(!isCandidateNewTimeEarlierWithinReason(triggerTime,
false
)) {
try
{
// we could have blocked a long while
// on 'synchronize', so we must recompute
now = System.currentTimeMillis();
timeUntilTrigger = triggerTime - now;
if
(timeUntilTrigger >=
1
)
sigLock.wait(timeUntilTrigger);
}
catch
(InterruptedException ignore) {
}
}
}
//该方法调用了上面的判定方法,作为再次判定的逻辑
//到达这里有两种情况1.决定放弃当前trigger,那么再判定一次,如果仍然有放弃,那么清空triggers列表并
// 退出循环 2.不放弃当前trigger,且线程已经wait到trigger触发的时刻,那么什么也不做
if
(releaseIfScheduleChangedSignificantly(triggers, triggerTime)) {
break
;
}
now = System.currentTimeMillis();
timeUntilTrigger = triggerTime - now;
//这时触发器已经即将触发,值会<2
}
// this happens if releaseIfScheduleChangedSignificantly decided to release triggers
if
(triggers.isEmpty())
continue
;
// set triggers to 'executing'
List<TriggerFiredResult> bndles =
new
ArrayList<TriggerFiredResult>();
boolean
goAhead =
true
;
synchronized
(sigLock) {
goAhead = !halted.get();
}
if
(goAhead) {
try
{
//触发triggers,结果付给bndles,注意,从这里返回后,trigger在数据库中已经经过了锁定,解除锁定,这一套过程
//所以说,quratz定不是等到job执行完才释放trigger资源的占有,而是读取完本次触发所需的信息后立即释放资源
//然后再执行jobs
List<TriggerFiredResult> res = qsRsrcs.getJobStore().triggersFired(triggers);
if
(res !=
null
)
bndles = res;
}
catch
(SchedulerException se) {
qs.notifySchedulerListenersError(
"An error occurred while firing triggers '"
+ triggers +
"'"
, se);
//QTZ-179 : a problem occurred interacting with the triggers from the db
//we release them and loop again
for
(
int
i =
0
; i < triggers.size(); i++) {
qsRsrcs.getJobStore().releaseAcquiredTrigger(triggers.get(i));
}
continue
;
}
}
//迭代trigger的信息,分别跑job
for
(
int
i =
0
; i < bndles.size(); i++) {
TriggerFiredResult result = bndles.get(i);
TriggerFiredBundle bndle = result.getTriggerFiredBundle();
Exception exception = result.getException();
if
(exception
instanceof
RuntimeException) {
getLog().error(
"RuntimeException while firing trigger "
+ triggers.get(i), exception);
qsRsrcs.getJobStore().releaseAcquiredTrigger(triggers.get(i));
continue
;
}
// it's possible to get 'null' if the triggers was paused,
// blocked, or other similar occurrences that prevent it being
// fired at this time... or if the scheduler was shutdown (halted)
//在特殊情况下,bndle可能为null,看triggerFired方法可以看到,当从数据库获取trigger时,如果status不是
//STATE_ACQUIRED,那么会直接返回空.quratz这种情况下本调度器启动重试流程,重新获取4次,若仍有问题,
// 则抛出异常.
if
(bndle ==
null
) {
qsRsrcs.getJobStore().releaseAcquiredTrigger(triggers.get(i));
continue
;
}
//执行job
JobRunShell shell =
null
;
try
{
//创建一个job的Runshell
shell = qsRsrcs.getJobRunShellFactory().createJobRunShell(bndle);
shell.initialize(qs);
}
catch
(SchedulerException se) {
qsRsrcs.getJobStore().triggeredJobComplete(triggers.get(i), bndle.getJobDetail(), CompletedExecutionInstruction.SET_ALL_JOB_TRIGGERS_ERROR);
continue
;
}
//把runShell放在线程池里跑
if
(qsRsrcs.getThreadPool().runInThread(shell) ==
false
) {
// this case should never happen, as it is indicative of the
// scheduler being shutdown or a bug in the thread pool or
// a thread pool being used concurrently - which the docs
// say not to do...
getLog().error(
"ThreadPool.runInThread() return false!"
);
qsRsrcs.getJobStore().triggeredJobComplete(triggers.get(i), bndle.getJobDetail(), CompletedExecutionInstruction.SET_ALL_JOB_TRIGGERS_ERROR);
}
}
continue
;
// while (!halted)
}
}
else
{
// if(availThreadCount > 0)
// should never happen, if threadPool.blockForAvailableThreads() follows contract
continue
;
// while (!halted)
}
//保证负载平衡的方法,每次执行一轮触发后,本scheduler会等待一个随机的时间,这样就使得其他节点上的scheduler可以得到资源.
long
now = System.currentTimeMillis();
long
waitTime = now + getRandomizedIdleWaitTime();
long
timeUntilContinue = waitTime - now;
synchronized
(sigLock) {
try
{
if
(!halted.get()) {
// QTZ-336 A job might have been completed in the mean time and we might have
// missed the scheduled changed signal by not waiting for the notify() yet
// Check that before waiting for too long in case this very job needs to be
// scheduled very soon
if
(!isScheduleChanged()) {
sigLock.wait(timeUntilContinue);
}
}
}
catch
(InterruptedException ignore) {
}
}
}
catch
(RuntimeException re) {
getLog().error(
"Runtime error occurred in main trigger firing loop."
, re);
}
}
// while (!halted)
// drop references to scheduler stuff to aid garbage collection...
qs =
null
;
qsRsrcs =
null
;
}
|
调度器每次获取到的trigger是30s内需要执行的,所以要等待一段时间至trigger执行前2ms.在等待过程中涉及到一个新加进来更紧急的trigger的处理逻辑.分析写在注释中,不再赘述.
可以看到调度器的只要在运行状态,就会不停地执行调度流程.值得注意的是,在流程的最后线程会等待一个随机的时间.这就是quartz自带的负载平衡机制.
以下是三个步骤的跟进:
触发器的获取
调度器调用:
triggers = qsRsrcs.getJobStore().acquireNextTriggers(
now + idleWaitTime, Math.min(availThreadCount, qsRsrcs.getMaxBatchSize()), qsRsrcs.getBatchTimeWindow());
|
在数据库中查找一定时间范围内将会被触发的trigger.参数的意义如下:参数1:nolaterthan = now+3000ms,即未来30s内将会被触发.参数2 最大获取数量,大小取线程池线程剩余量与定义值得较小者.参数3 时间窗口 默认为0,程序会在nolaterthan后加上窗口大小来选择trigger.quratz会在每次触发trigger后计算出trigger下次要执行的时间,并在数据库QRTZ2_TRIGGERS中的NEXT_FIRE_TIME字段中记录.查找时将当前毫秒数与该字段比较,就能找出下一段时间内将会触发的触发器.查找时,调用在JobStoreSupport类中的方法:
public
List<OperableTrigger> acquireNextTriggers(
final
long
noLaterThan,
final
int
maxCount,
final
long
timeWindow)
throws
JobPersistenceException {
String lockName;
if
(isAcquireTriggersWithinLock() || maxCount >
1
) {
lockName = LOCK_TRIGGER_ACCESS;
}
else
{
lockName =
null
;
}
return
executeInNonManagedTXLock(lockName,
new
TransactionCallback<List<OperableTrigger>>() {
public
List<OperableTrigger> execute(Connection conn)
throws
JobPersistenceException {
return
acquireNextTrigger(conn, noLaterThan, maxCount, timeWindow);
}
},
new
TransactionValidator<List<OperableTrigger>>() {
public
Boolean validate(Connection conn, List<OperableTrigger> result)
throws
JobPersistenceException {
//...异常处理回调方法
}
});
}
|
该方法关键的一点在于执行了executeInNonManagedTXLock()方法,这一方法指定了一个锁名,两个回调函数.在开始执行时获得锁,在方法执行完毕后随着事务的提交锁被释放.在该方法的底层,使用 for update语句,在数据库中加入行级锁,保证了在该方法执行过程中,其他的调度器对trigger进行获取时将会等待该调度器释放该锁.此方法是前面介绍的quartz集群策略的的具体实现,这一模板方法在后面的trigger触发过程还会被使用.
public
static
final
String SELECT_FOR_LOCK =
"SELECT * FROM "
+ TABLE_PREFIX_SUBST + TABLE_LOCKS +
" WHERE "
+ COL_SCHEDULER_NAME +
" = "
+ SCHED_NAME_SUBST
+
" AND "
+ COL_LOCK_NAME +
" = ? FOR UPDATE"
;
|
进一步解释:quratz在获取数据库资源之前,先要以for update方式访问LOCKS表中相应LOCK_NAME数据将改行锁定.如果在此前该行已经被锁定,那么等待,如果没有被锁定,那么读取满足要求的trigger,并把它们的status置为STATE_ACQUIRED,如果有tirgger已被置为STATE_ACQUIRED,那么说明该trigger已被别的调度器实例认领,无需再次认领,调度器会忽略此trigger.调度器实例之间的间接通信就体现在这里.
JobStoreSupport.acquireNextTrigger()方法中:
int rowsUpdated = getDelegate().updateTriggerStateFromOtherState(conn, triggerKey, STATE_ACQUIRED, STATE_WAITING);
最后释放锁,这时如果下一个调度器在排队获取trigger的话,则仍会执行相同的步骤.这种机制保证了trigger不会被重复获取.按照这种算法正常运行状态下调度器每次读取的trigger中会有相当一部分已被标记为被获取.
获取trigger的过程进行完毕.
触发trigger:
QuartzSchedulerThread line336:
List<TriggerFiredResult> res = qsRsrcs.getJobStore().triggersFired(triggers);
调用JobStoreSupport类的triggersFired()方法:
public
List<TriggerFiredResult> triggersFired(
final
List<OperableTrigger> triggers)
throws
JobPersistenceException {
return
executeInNonManagedTXLock(LOCK_TRIGGER_ACCESS,
new
TransactionCallback<List<TriggerFiredResult>>() {
public
List<TriggerFiredResult> execute(Connection conn)
throws
JobPersistenceException {
List<TriggerFiredResult> results =
new
ArrayList<TriggerFiredResult>();
TriggerFiredResult result;
for
(OperableTrigger trigger : triggers) {
try
{
TriggerFiredBundle bundle = triggerFired(conn, trigger);
result =
new
TriggerFiredResult(bundle);
}
catch
(JobPersistenceException jpe) {
result =
new
TriggerFiredResult(jpe);
}
catch
(RuntimeException re) {
result =
new
TriggerFiredResult(re);
}
results.add(result);
}
return
results;
}
},
new
TransactionValidator<List<TriggerFiredResult>>() {
@Override
public
Boolean validate(Connection conn, List<TriggerFiredResult> result)
throws
JobPersistenceException {
//...异常处理回调方法
}
});
}
|
此处再次用到了quratz的行为规范:executeInNonManagedTXLock()方法,在获取锁的情况下对trigger进行触发操作.其中的触发细节如下:
protected
TriggerFiredBundle triggerFired(Connection conn,
OperableTrigger trigger)
throws
JobPersistenceException {
JobDetail job;
Calendar cal =
null
;
// Make sure trigger wasn't deleted, paused, or completed...
try
{
// if trigger was deleted, state will be STATE_DELETED
String state = getDelegate().selectTriggerState(conn,
trigger.getKey());
if
(!state.equals(STATE_ACQUIRED)) {
return
null
;
}
}
catch
(SQLException e) {
throw
new
JobPersistenceException(
"Couldn't select trigger state: "
+ e.getMessage(), e);
}
try
{
job = retrieveJob(conn, trigger.getJobKey());
if
(job ==
null
) {
return
null
; }
}
catch
(JobPersistenceException jpe) {
try
{
getLog().error(
"Error retrieving job, setting trigger state to ERROR."
, jpe);
getDelegate().updateTriggerState(conn, trigger.getKey(),
STATE_ERROR);
}
catch
(SQLException sqle) {
getLog().error(
"Unable to set trigger state to ERROR."
, sqle);
}
throw
jpe;
}
if
(trigger.getCalendarName() !=
null
) {
cal = retrieveCalendar(conn, trigger.getCalendarName());
if
(cal ==
null
) {
return
null
; }
}
try
{
getDelegate().updateFiredTrigger(conn, trigger, STATE_EXECUTING, job);
}
catch
(SQLException e) {
throw
new
JobPersistenceException(
"Couldn't insert fired trigger: "
+ e.getMessage(), e);
}
Date prevFireTime = trigger.getPreviousFireTime();
// call triggered - to update the trigger's next-fire-time state...
trigger.triggered(cal);
String state = STATE_WAITING;
boolean
force =
true
;
if
(job.isConcurrentExectionDisallowed()) {
state = STATE_BLOCKED;
force =
false
;
try
{
getDelegate().updateTriggerStatesForJobFromOtherState(conn, job.getKey(),
STATE_BLOCKED, STATE_WAITING);
getDelegate().updateTriggerStatesForJobFromOtherState(conn, job.getKey(),
STATE_BLOCKED, STATE_ACQUIRED);
getDelegate().updateTriggerStatesForJobFromOtherState(conn, job.getKey(),
STATE_PAUSED_BLOCKED, STATE_PAUSED);
}
catch
(SQLException e) {
throw
new
JobPersistenceException(
"Couldn't update states of blocked triggers: "
+ e.getMessage(), e);
}
}
if
(trigger.getNextFireTime() ==
null
) {
state = STATE_COMPLETE;
force =
true
;
}
storeTrigger(conn, trigger, job,
true
, state, force,
false
);
job.getJobDataMap().clearDirtyFlag();
return
new
TriggerFiredBundle(job, trigger, cal, trigger.getKey().getGroup()
.equals(Scheduler.DEFAULT_RECOVERY_GROUP),
new
Date(), trigger
.getPreviousFireTime(), prevFireTime, trigger.getNextFireTime());
}
|
该方法做了以下工作:
1.获取trigger当前状态
2.通过trigger中的JobKey读取trigger包含的Job信息
3.将trigger更新至触发状态
4.结合calendar的信息触发trigger,涉及多次状态更新
5.更新数据库中trigger的信息,包括更改状态至STATE_COMPLETE,及计算下一次触发时间.
6.返回trigger触发结果的数据传输类TriggerFiredBundle
从该方法返回后,trigger的执行过程已基本完毕.回到执行quratz操作规范的executeInNonManagedTXLock方法,将数据库锁释放.
trigger触发操作完成
Job执行过程:
再回到线程类QuartzSchedulerThread的 line353这时触发器都已出发完毕,job的详细信息都已就位
QuartzSchedulerThread line:368
qsRsrcs.getJobStore().releaseAcquiredTrigger(triggers.get(i));
shell.initialize(qs);
|
为每个Job生成一个可运行的RunShell,并放入线程池运行.
在最后调度线程生成了一个随机的等待时间,进入短暂的等待,这使得其他节点的调度器都有机会获取数据库资源.如此就实现了quratz的负载平衡.
这样一次完整的调度过程就结束了.调度器线程进入下一次循环.
总结:
简单地说,quartz的分布式调度策略是以数据库为边界资源的一种异步策略.各个调度器都遵守一个基于数据库锁的操作规则保证了操作的唯一性.同时多个节点的异步运行保证了服务的可靠.但这种策略有自己的局限性.摘录官方文档中对quratz集群特性的说明:
Only one node will fire the job for each firing. What I mean by that is, if the job has a repeating trigger that tells it to fire every 10 seconds, then at 12:00:00 exactly one node will run the job, and at 12:00:10 exactly one node will run the job, etc. It won't necessarily be the same node each time - it will more or less be random which node runs it. The load balancing mechanism is near-random for busy schedulers (lots of triggers) but favors the same node for non-busy (e.g. few triggers) schedulers.
The clustering feature works best for scaling out long-running and/or cpu-intensive jobs (distributing the work-load over multiple nodes). If you need to scale out to support thousands of short-running (e.g 1 second) jobs, consider partitioning the set of jobs by using multiple distinct schedulers (including multiple clustered schedulers for HA). The scheduler makes use of a cluster-wide lock, a pattern that degrades performance as you add more nodes (when going beyond about three nodes - depending upon your database's capabilities, etc.).
说明指出,集群特性对于高cpu使用率的任务效果很好,但是对于大量的短任务,各个节点都会抢占数据库锁,这样就出现大量的线程等待资源.这种情况随着节点的增加会越来越严重.
附:
通讯图中关键步骤的主要sql语句:
3.
select
TRIGGER_ACCESS
from
QRTZ2_LOCKS
for
update
4.
SELECT
TRIGGER_NAME,
TRIGGER_GROUP,
NEXT_FIRE_TIME,
PRIORITY
FROM
QRTZ2_TRIGGERS
WHERE
SCHEDULER_NAME =
'CRMscheduler'
AND
TRIGGER_STATE =
'ACQUIRED'
AND
NEXT_FIRE_TIME <=
'{timekey 30s latter}'
AND
( MISFIRE_INSTR = -1
OR
( MISFIRE_INSTR != -1
AND
NEXT_FIRE_TIME >=
'{timekey now}'
) )
ORDER
BY
NEXT_FIRE_TIME
ASC
,
PRIORITY
DESC
;
5.
SELECT
*
FROM
QRTZ2_JOB_DETAILS
WHERE
SCHEDULER_NAME = CRMscheduler
AND
JOB_NAME = ?
AND
JOB_GROUP = ?;
6.
UPDATE
TQRTZ2_TRIGGERS
SET
TRIGGER_STATE =
'ACQUIRED'
WHERE
SCHED_NAME =
'CRMscheduler'
AND
TRIGGER_NAME =
'{triggerName}'
AND
TRIGGER_GROUP =
'{triggerGroup}'
AND
TRIGGER_STATE =
'waiting'
;
7.
INSERT
INTO
QRTZ2_FIRED_TRIGGERS
(SCHEDULER_NAME,
ENTRY_ID,
TRIGGER_NAME,
TRIGGER_GROUP,
INSTANCE_NAME,
FIRED_TIME,
SCHED_TIME,
STATE,
JOB_NAME,
JOB_GROUP,
IS_NONCONCURRENT,
REQUESTS_RECOVERY,
PRIORITY)
VALUES
(
'CRMscheduler'
, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?);
8.
commit
;
12.
select
STAT_ACCESS
from
QRTZ2_LOCKS
for
update
13.
SELECT
TRIGGER_STATE
FROM
QRTZ2_TRIGGERS
WHERE
SCHEDULER_NAME =
'CRMscheduler'
AND
TRIGGER_NAME = ?
AND
TRIGGER_GROUP = ?;
14.
SELECT
TRIGGER_STATE
FROM
QRTZ2_TRIGGERS
WHERE
SCHEDULER_NAME =
'CRMscheduler'
AND
TRIGGER_NAME = ?
AND
TRIGGER_GROUP = ?;
14.
SELECT
*
FROM
QRTZ2_JOB_DETAILS
WHERE
SCHEDULER_NAME = CRMscheduler
AND
JOB_NAME = ?
AND
JOB_GROUP = ?;
15.
SELECT
*
FROM
QRTZ2_CALENDARS
WHERE
SCHEDULER_NAME =
'CRMscheduler'
AND
CALENDAR_NAME = ?;
16.
UPDATE
QRTZ2_FIRED_TRIGGERS
SET
INSTANCE_NAME = ?,
FIRED_TIME = ?,
SCHED_TIME = ?,
ENTRY_STATE = ?,
JOB_NAME = ?,
JOB_GROUP = ?,
IS_NONCONCURRENT = ?,
REQUESTS_RECOVERY = ?
WHERE
SCHEDULER_NAME =
'CRMscheduler'
AND
ENTRY_ID = ?;
17.
UPDATE
TQRTZ2_TRIGGERS
SET
TRIGGER_STATE = ?
WHERE
SCHED_NAME =
'CRMscheduler'
AND
TRIGGER_NAME =
'{triggerName}'
AND
TRIGGER_GROUP =
'{triggerGroup}'
AND
TRIGGER_STATE = ?;
18.
UPDATE
QRTZ2_TRIGGERS
SET
JOB_NAME = ?,
JOB_GROUP = ?,
DESCRIPTION = ?,
NEXT_FIRE_TIME = ?,
PREV_FIRE_TIME = ?,
TRIGGER_STATE = ?,
TRIGGER_TYPE = ?,
START_TIME = ?,
END_TIME = ?,
CALENDAR_NAME = ?,
MISFIRE_INSTRUCTION = ?,
PRIORITY = ?,
JOB_DATAMAP = ?
WHERE
SCHEDULER_NAME = SCHED_NAME_SUBST
AND
TRIGGER_NAME = ?
AND
TRIGGER_GROUP = ?;
19.
commit
;
|















 1863
1863

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









