







在微服务框架中,由于各个系统功能分离明确,需要大量的服务器对系统部署进行支持。每个生产系统都会产生大量的日志,数据分散且管理困难,一旦出现问题,查找日志需要寻找运维人员进行协助,但是可能出现查询日志速度较慢,无法准确定位,影响生产问题解决的情况。所以我们需要一套日志系统来收集各个服务器上的日志数据,并且能使用集中高效的web方式搜索查看日志,同时能对日志进行维度分析等。在此,我们选择ELK框架来实践日志系统。
ELK是什么?
- E:ElasticSearch,一款基于Lucene的分布式搜索引擎,基于RESTful web接口。Elasticsearch由Java语言开发,是一个近实时搜索平台,延迟时间通常为1s。
- L:Logstash,一款开源的实时日志收集传输以及格式化的工具。Logstash由JRuby语言设计,语法十分简洁,并且社区内存在各种强大的插件,方便开发者使用。
K:kibana,一款配合ElasticSearch可视化界面,内置各种查询,聚合操作,并且能生成漂亮的图形化功能。
在了解ELK的基本概念后,对于如何运用到实际的日志系统中,我们还必须要了解整个日志系统的基本架构,这样才能深刻理解ELK各个部分的不同作用。
日志系统的基本结构
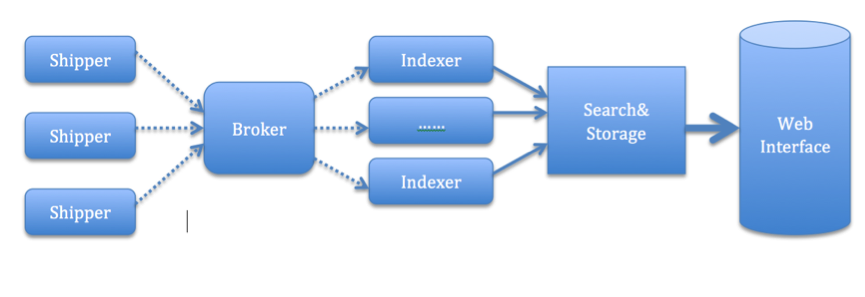
说明:
- Shipper:日志数据收集端。独立的agent部署在各个服务器端,将各种日志数据收集传输到中间转发器上。
- Broker:中间转发器。数据缓冲池,在远程agent端与中心agent端做第一层数据转发与存储。可以提高系统性能,防止数据直接打入存储端导致内存占用过多。
- Indexer:数据转化器。从Broker中提取数据,并且根据业务需求进行字段的提取改造,再传输存储到存储器中。
- Search&Storage:存储池和搜索引擎。存储Indexer传输过来的数据,根据规则对数据进行索引等操作。并且提供给web端接口进行数据查询聚合等。
- Web Interface:web界面,便于显示查询日志,并且能对数据进行基本的统计等操作。
一个日志系统,就像是一个巨大的工厂。每个人负责不同的工作,才能使工厂运行起来。其中logstash便是作为shipper和indexer端的工具,用来进行数据传输和格式化。Elasticsearch则是功能强大的数据存储池,并且向外提供搜索功能。Kibana就是最终对数据的展示界面,提供给用户统计分析等功能。而中间的Broker角色,则推荐选择redis或者Kafka来实现数据缓冲。
环境部署搭建
下面我们来尝试搭建一个单机版本的ELK系统,用来了解查看其效果。
环境配置
- 192.168.1.10:远程Shipper
- 192.168.1.20:Broker(以redis为例)
- 192.168.1.30:Indexer、Elasticsearch以及Kibana
- Elasticsearch版本:2.3.1
- Logstash版本:2.3.1
- Kibana版本:4.4.1
Redis版本:2.8.19
请注意,ELK版本由于迭代速度较快,版本较多,请选择适合自己的版本号,并且注意各个不同组件间的兼容问题。尽量选择较新的版本。Logstash要求依赖JDK1.7,所以以上机器都默认已经装好了JDK。部署远程Shipper
下载并解压:
tar zxvf logstash-2.3.1.tar.gz
cd /home/appdeploy/logstash-2.3.1
mkdir conf编辑配置文件 conf/logstash-file-agent.conf:
input { stdin{} file { type => "log4j-json" path => "/apache-tomcat-7.0.68/logs/os.log" start_position => "end" } } output { redis{ codec => json data_type => "list" host => ["192.168.1.10:6379"] password => "logstash123" key => "logstash" reconnect_interval => 5 timeout => 5 workers => 10 } }启动logstash:
$ ./logstash –f ../conf/logstash-file-agent.conf &
部署中心Indexer
安装解压步骤与之前相同,配置文件conf/logstash-file-indexer.conf如下:
``` input { redis{ codec => "json" data_type => "list" host => "192.168.1.10" key => " logstash " password => "logstash123" port => 6379 threads => 10 } } output { elasticsearch { hosts => ["localhost:9200"] } } ``` - 启动$ ./logstash –f ../conf/logstash-file-indexer.conf &
部署ElasticSearch
下载并解压:
tar zxvf elasticsearch-2.3.1
cd elasticsearch-2.3.1/binElasticsearch使用默认的配置即可,默认的cluster name为:elasticsearch。如果需要配置集群的话,需要让不同的实例在同一个集群中,这样集群名的配置就很重要了。
启动elasticsearch
$ ./elasticsearch &
部署Kibana
下载并解压:
tar zxvf kibana-4.5.0-linux-x64
cd config
vi kibana.yml修改Kibana.yml文件
配置elasticsearch地址:
elasticsearch:”localhost:9200”启动:
cd bin/
./kibana &
测试
由于在远程agent中配置了输入和监控文件两种input方法,可以通过在对话中直接输入消息或者修改文件的方法案进行测试。同时可以使用monitor命令监控redis中的数据量:
$ redis-cli –p 6379 monitor
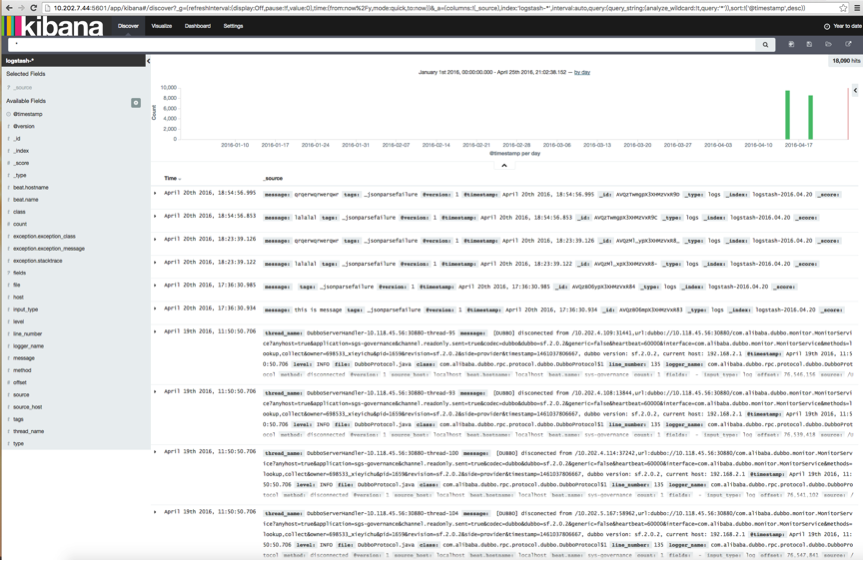
此时,输入Kibana访问界面,可以看到数据输出了:http://192.168.1.30:5601















 2731
2731

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









