







Linux内核通过一个虚拟的网桥设备来实现桥接的,这个设备可以绑定若干个以太网接口设备,从而将它们桥接起来。如下图所示:
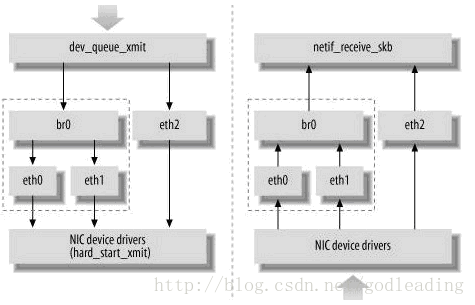
网桥设备br0绑定了eth0和eth1。对于网络协议栈的上层来说,只看得到br0,因为桥接是在数据链路层实现的,上层不需要关心桥接的细节。于是协议栈上层需要发送的报文被送到br0,网桥设备的处理代码再来判断报文该被转发到eth0或是eth1,或者两者皆是;反过来,从eth0或从eth1接收到的报文被提交给网桥的处理代码,在这里会判断报文该转发、丢弃、或提交到协议栈上层。
而有时候eth0、eth1也可能会作为报文的源地址或目的地址,直接参与报文的发送与接收(从而绕过网桥)。
相关数据结构:
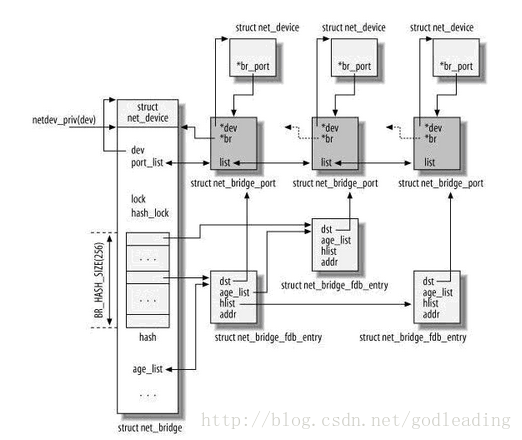
其中最左边的net_device是一个代表网桥的虚拟设备结构,它关联了一个net_bridge结构,这是网桥设备所特有的数据结构。
在net_bridge结构中,port_list成员下挂一个链表,链表中的每一个节点(net_bridge_port结构)关联到一个真实的网口设备的net_device。网口设备也通过其br_port指针做反向的关联(那么显然,一个网口最多只能同时被绑定到一个网桥)。
net_bridge结构中还维护了一个hash表,是用来处理地址学习的。当网桥准备转发一个报文时,以报文的目的Mac地址为key,如果可以在hash表中索引到一个net_bridge_fdb_entry结构,通过这个结构能找到一个网口设备的net_device,于是报文就应该从这个网口转发出去;否则,报文将从所有网口转发。
网桥数据包的处理流程:
接收过程:
对于数据包的处理流程并没有明显的主线,主要就是根据内核代码中网桥部分的源码进行分析。
网口设备接收到的报文最终通过net_receive_skb函数被网络协议栈所接收。这个函数主要做三件事情:1、如果有抓包程序需要skb,将skb复制给它们;2、处理桥接;3、将skb提交给网络层。
int netif_receive_skb(struct sk_buff *skb)
{
......
if (handle_bridge(&skb, &pt_prev, &ret, orig_dev))
goto out;
......
}
static inline struct sk_buff *handle_bridge(struct sk_buff *skb,
struct packet_type **pt_prev, int *ret,
struct net_device *orig_dev)
{
struct net_bridge_port *port;
//对于回环设备以及skb->dev->br_port为空(即不被任何网桥所包含)的数据包直接返回
if (skb->pkt_type == PACKET_LOOPBACK ||
(port = rcu_dereference(skb->dev->br_port)) == NULL)
return skb;
if (*pt_prev) {
*ret = deliver_skb(skb, *pt_prev, orig_dev);
*pt_prev = NULL;
}
//网桥的基本挂接点处理函数
return br_handle_frame_hook(port, skb);
}
br_handle_frame_hook在网桥初始化模块br_init(void)函数中被赋值.
br_handle_frame_hook = br_handle_frame;
所以网桥对于数据包的处理过程是从br_handle_frame开始的。
struct sk_buff *br_handle_frame(struct net_bridge_port *p, struct sk_buff *skb)
{
const unsigned char *dest = eth_hdr(skb)->h_dest;
int (*rhook)(struct sk_buff *skb);
//判断是否为有效的物理地址,非全0地址以及非广播地址
if (!is_valid_ether_addr(eth_hdr(skb)->h_source))
goto drop;
//判断skb包是否被共享skb->users != 1,若是,则复制一份,否则直接返回
skb = skb_share_check(skb, GFP_ATOMIC);
if (!skb)
return NULL;
//这个函数并非像想象的那样,判断是否为本地地址
//而是在判断是否为链路本地多播地址,01:80:c2:00:00:0x
if (unlikely(is_link_local(dest))) {
/* Pause frames shouldn't be passed up by driver anyway */
if (skb->protocol == htons(ETH_P_PAUSE))
goto drop;
/* If STP is turned off, then forward */
if (p->br->stp_enabled == BR_NO_STP && dest[5] == 0)
goto forward;
if (NF_HOOK(PF_BRIDGE, NF_BR_LOCAL_IN, skb, skb->dev,
NULL, br_handle_local_finish))
return NULL; /* frame consumed by filter */
else
return skb; /* continue processing */
}
forward:
switch (p->state) {
case BR_STATE_FORWARDING:
//如果网桥处于forwarding状态,并且该报文必须要走L3层进行转发,则直接返回
//br_should_route_hook钩子函数在ebtable里面设置为ebt_broute函数,它根据用户的规
//决定该报文是否要通过L3层来转发;一般rhook为空
rhook = rcu_dereference(br_should_route_hook);
if (rhook != NULL) {
if (rhook(skb))
return skb;
dest = eth_hdr(skb)->h_dest;
}
/* fall through */
case BR_STATE_LEARNING:
//如果数据包的目的mac地址为虚拟网桥设备的mac地址,则标记为host
if (!compare_ether_addr(p->br->dev->dev_addr, dest))
skb->pkt_type = PACKET_HOST;
//调用网桥在NF_BR_PREROUTING处挂载的钩子函数,因为网桥在其钩子函数过//程中嵌套调用了INET层BR_PREROUTING的钩子函数,过程有些曲折,故最后//再分析
NF_HOOK(PF_BRIDGE, NF_BR_PRE_ROUTING, skb, skb->dev, NULL,
br_handle_frame_finish);
break;
default:
drop:
kfree_skb(skb);
}
return NULL;
}
FORWARDING以及LEARNING为网桥的状态,网桥端口一般有5种状态:
1) disable 被管理员禁用
2) blcok 休息,不参与数据包转发
3) listening 监听
4) learning 学习ARP信息,准备向工作状态改变
5) forwarding 正常工作,转发数据包
/* note: already called with rcu_read_lock (preempt_disabled) */
int br_handle_frame_finish(struct sk_buff *skb)
{
const unsigned char *dest = eth_hdr(skb)->h_dest;
struct net_bridge_port *p = rcu_dereference(skb->dev->br_port);
struct net_bridge *br;
struct net_bridge_fdb_entry *dst;
struct sk_buff *skb2;
//判断网桥状态
if (!p || p->state == BR_STATE_DISABLED)
goto drop;
/* insert into forwarding database after filtering to avoid spoofing */
//br为虚拟网桥结构
br = p->br;
//根据数据包的源物理地址,更新网桥的转发表
br_fdb_update(br, p, eth_hdr(skb)->h_source);
if (p->state == BR_STATE_LEARNING)
goto drop;
/* The packet skb2 goes to the local host (NULL to skip). */
//skb2数据包用于交付本机,skb数据包则用于forward
skb2 = NULL;
//如果网口处于混杂模式,复制一份交付主机
if (br->dev->flags & IFF_PROMISC)
skb2 = skb;
dst = NULL;
//如果为广播数据包,增加计数,同样需要发一份给主机
if (is_multicast_ether_addr(dest)) {
br->dev->stats.multicast++;
skb2 = skb;
}
/*根据网桥口以及目标地址判断是否为本机数据包*/
else if ((dst = __br_fdb_get(br, dest)) && dst->is_local) {
skb2 = skb;
/* Do not forward the packet since it's local. */
skb = NULL;
}
if (skb2 == skb)
skb2 = skb_clone(skb, GFP_ATOMIC);
if (skb2)
/*完成将数据包交付给本机的工作*/
br_pass_frame_up(br, skb2);
if (skb) {
if (dst)
//如果存在目的地址则将其转发
br_forward(dst->dst, skb);
else
//否则,flood数据包,向除接收网口外的其余网口发送该数据包
br_flood_forward(br, skb);
}
out:
return 0;
drop:
kfree_skb(skb);
goto out;
}
//此函数主要实现通过网桥接收发往本机的数据包
static void br_pass_frame_up(struct net_bridge *br, struct sk_buff *skb)
{
struct net_device *indev, *brdev = br->dev;
//完成数据包的统计计数
brdev->stats.rx_packets++;
brdev->stats.rx_bytes += skb->len;
//将skb的dev改变为网桥结构的brdev
//此时skb的dev选项由实际网络设备eth0等改变为虚拟网桥设备br0
indev = skb->dev;
skb->dev = brdev;
//重新走数据包接收流程,netif_receive_skb
//但因为dev的改变,dev的br_port字段不再为空,不会重走网桥流程,直接交付
NF_HOOK(PF_BRIDGE, NF_BR_LOCAL_IN, skb, indev, NULL,
netif_receive_skb);
}
下面看一下转发数据包的流程,对于flood_forward的流程,同样通过br_forward来实现,只不过改为循环遍历hash表中的设备,对于每一个设备都调用一次br_forward流程。
/* called with rcu_read_lock */
void br_forward(const struct net_bridge_port *to, struct sk_buff *skb)
{
/*如果skb->dev 不等于网桥的dev,同时网桥状态为forwarding,则进行转发*/
if (should_deliver(to, skb)) {
__br_forward(to, skb);
return;
}
kfree_skb(skb);
}
static void __br_forward(const struct net_bridge_port *to, struct sk_buff *skb)
{
struct net_device *indev;
if (skb_warn_if_lro(skb)) {
kfree_skb(skb);
return;
}
//将skb的dev字段改为查找到的出口dev字段
indev = skb->dev;
skb->dev = to->dev;
skb_forward_csum(skb);
//遍历执行NF_BR_FORWARD钩子函数
NF_HOOK(PF_BRIDGE, NF_BR_FORWARD, skb, indev, skb->dev,
br_forward_finish);
}
int br_forward_finish(struct sk_buff *skb)
{
//继续跑NF_BR_POST_ROUTING处的钩子函数
return NF_HOOK(PF_BRIDGE, NF_BR_POST_ROUTING, skb, NULL, skb->dev,
br_dev_queue_push_xmit);
}
int br_dev_queue_push_xmit(struct sk_buff *skb)
{
/* drop mtu oversized packets except gso */
/*如果skb数据包的长度大于MTU值,则丢弃*/
if (packet_length(skb) > skb->dev->mtu && !skb_is_gso(skb))
kfree_skb(skb);
else {
/* ip_refrag calls ip_fragment, doesn't copy the MAC header. */
if (nf_bridge_maybe_copy_header(skb))
kfree_skb(skb);
else {
skb_push(skb, ETH_HLEN);
// 此时skb的dev已经替换成进行转发的dev了,dev_queue_xmit将使
//用该网口设备的发送函数完成数据包的发送
dev_queue_xmit(skb);
}
}
return 0;
}
发送过程:
协议栈上层需要发送报文时,调用dev_queue_xmit(skb)函数。如果这个报文需要通过网桥设备来发送,则skb->dev指向一个网桥设备。网桥设备没有使用发送队列(dev->qdisc为空),所以dev_queue_xmit将直接调用dev->hard_start_xmit函数,而网桥设备的hard_start_xmit等于函数br_dev_xmit;
/* net device transmit always called with no BH (preempt_disabled) */
/*br_dev_xmit为网桥设备的数据包发送函数*/
int br_dev_xmit(struct sk_buff *skb, struct net_device *dev)
{
struct net_bridge *br = netdev_priv(dev);
const unsigned char *dest = skb->data;
struct net_bridge_fdb_entry *dst;
dev->stats.tx_packets++;
dev->stats.tx_bytes += skb->len;
skb_reset_mac_header(skb);
skb_pull(skb, ETH_HLEN);
/*如果为广播地址,则flood该数据包
* 如果能够根据skb中的目的mac地址查找到对应的网口,则通过br_deliver发送该数据包
* 如果查找不到,同样flood该数据包
*/
if (dest[0] & 1)
br_flood_deliver(br, skb);
else if ((dst = __br_fdb_get(br, dest)) != NULL)
br_deliver(dst->dst, skb);
else
br_flood_deliver(br, skb);
return 0;
}
br_flood_deliver函数的实现过程,同样是遍历hash表,对于每一个网口设备都调用一次__br_deliver,所以下面就主要看一下br_deliver函数的流程
void br_deliver(const struct net_bridge_port *to, struct sk_buff *skb)
{
if (should_deliver(to, skb)) {
__br_deliver(to, skb);
return;
}
kfree_skb(skb);
}
static void __br_deliver(const struct net_bridge_port *to, struct sk_buff *skb)
{
/*将skb中的dev改成出口设备所对应的dev*/
skb->dev = to->dev;
NF_HOOK(PF_BRIDGE, NF_BR_LOCAL_OUT, skb, NULL, skb->dev,
br_forward_finish);
}
/*最终仍然通过br_dev_queue_push_xmit完成数据包的发送过程*/
int br_forward_finish(struct sk_buff *skb)
{
return NF_HOOK(PF_BRIDGE, NF_BR_POST_ROUTING, skb, NULL, skb->dev,
br_dev_queue_push_xmit);
}
至此,整个网桥中数据的处理流程已经完全结束了。
Netfilter:
对于网桥中的netfilter的钩子函数的调度过程有些曲折,对于INET层的钩子函数全部被嵌套进BRIDGE层钩子函数的运行流程中。
下面首先来看一下网桥一共挂载了哪些钩子函数
static struct nf_hook_ops br_nf_ops[] __read_mostly = {
{ .hook = br_nf_pre_routing,
.owner = THIS_MODULE,
.pf = PF_BRIDGE,
.hooknum = NF_BR_PRE_ROUTING,
.priority = NF_BR_PRI_BRNF, },
{ .hook = br_nf_local_in,
.owner = THIS_MODULE,
.pf = PF_BRIDGE,
.hooknum = NF_BR_LOCAL_IN,
.priority = NF_BR_PRI_BRNF, },
{ .hook = br_nf_forward_ip,
.owner = THIS_MODULE,
.pf = PF_BRIDGE,
.hooknum = NF_BR_FORWARD,
.priority = NF_BR_PRI_BRNF - 1, },
{ .hook = br_nf_forward_arp,
.owner = THIS_MODULE,
.pf = PF_BRIDGE,
.hooknum = NF_BR_FORWARD,
.priority = NF_BR_PRI_BRNF, },
{ .hook = br_nf_local_out,
.owner = THIS_MODULE,
.pf = PF_BRIDGE,
.hooknum = NF_BR_LOCAL_OUT,
.priority = NF_BR_PRI_FIRST, },
{ .hook = br_nf_post_routing,
.owner = THIS_MODULE,
.pf = PF_BRIDGE,
.hooknum = NF_BR_POST_ROUTING,
.priority = NF_BR_PRI_LAST, },
//以上为BRIDGE层挂载的钩子函数,一下为INET层挂载的钩子函数
{ .hook = ip_sabotage_in,
.owner = THIS_MODULE,
.pf = PF_INET,
.hooknum = NF_INET_PRE_ROUTING,
.priority = NF_IP_PRI_FIRST, },
{ .hook = ip_sabotage_in,
.owner = THIS_MODULE,
.pf = PF_INET6,
.hooknum = NF_INET_PRE_ROUTING,
.priority = NF_IP6_PRI_FIRST, },
};
其实在这些钩子函数内部并没有涉及数据包操作的具体流程,大多是一些条件判断和验证的工作,现在就拿发往本机的数据包在作为一个例子,看一下这个数据包在netfilter中的流经过程(自认为还算有代表意义)。
对于发往本机网桥口的skb包,其skb->dev->br_port不为空,因此会进入网桥的处理流程,br_handler_frame,在此函数的退出处会首先运行NF_BR_PRE_ROUTING的钩子函数
NF_HOOK(PF_BRIDGE, NF_BR_PRE_ROUTING, skb, skb->dev, NULL,
br_handle_frame_finish);
网桥挂载在BR_PRE_ROUTING的函数为br_nf_pre_routing
在此函数内部首先完成ipv4及ipv6数据的分流,这里只考虑ipv4数据,接着进行ipv4数据正确性的验证,以及网桥标记nf_bridge->mask |= BRNF_NF_BRIDGE_PREROUTING;(下面还要用到此标记)在函数的最后通过NF_HOOK(PF_INET, NF_INET_PRE_ROUTING, skb, skb->dev, NULL,br_nf_pre_routing_finish)完成对于INET层PRE_ROUTING钩子函数的遍历。
遍历结束后进入br_nf_pre_routing_finish函数,这个函数首先对数据包打标记,nf_bridge->mask ^= BRNF_NF_BRIDGE_PREROUTING;(跟上一个标记对应)主要处理skb包需要进行dnat的情形(貌似,没有细看),在函数的最后
NF_HOOK_THRESH(PF_BRIDGE, NF_BR_PRE_ROUTING, skb, skb->dev, NULL,
br_handle_frame_finish, 1);
在这里通过NF_HOOK_THRESH而非NF_HOOK的意思是因为,NF_HOOK_THRESH是从当前优先级的下一个函数开始遍历所有的钩子函数,在这里也就是说从br_nf_pre_routing函数的下一个优先级函数开始遍历BR_PRE_ROUTING的后续函数,虽然目前网桥只挂载了这一个函数,但是这属于Netfilter的机制问题。
接着,在跑完BR_PRE_ROUTING的剩余函数后就进入br_handle_frame_finish函数,对于本机数据包则继续调用br_pass_frame_up函数,在br_pass_frame_up函数中将skb的dev字段修改为虚拟网桥的dev,最后NF_HOOK(PF_BRIDGE, NF_BR_LOCAL_IN, skb, indev, NULL, netif_receive_skb);将数据包重新跑skb的接收流程,由于网桥设备的dev->br_port不为空,因此不会再进入网桥处理流程了。
那网桥是怎样防止同一个skb包跑两次INET_PRE_ROUTING的流程呢,主要就是通过挂在在INET_PRE_ROUTING出优先级最高的NF_IP_PRI_FIRST处的函数ip_sabotage_in以及上文特殊提到的两个打标记的代码来完成的。
static unsigned int ip_sabotage_in(unsigned int hook, struct sk_buff *skb,
const struct net_device *in,
const struct net_device *out,
int (*okfn)(struct sk_buff *))
{
/*此钩子函数用于确保发往本机的skb包只跑一次INET_PRE_ROUTING的钩子函数
* 在第一次进入BR_PRE_ROUTING时打上标记mask,在BR_PRE_ROUTING的钩子函数中遍历INET_PRE_ROUTING的钩子函数
* 在br_pre_routing结束的时候,异或该mask值,这样就使得发往本机的skb包在第二次交付的时候可以不再跑钩子
*/
if (skb->nf_bridge &&
!(skb->nf_bridge->mask & BRNF_NF_BRIDGE_PREROUTING)) {
return NF_STOP;
}
return NF_ACCEPT;
}
NF_STOP的意思就是说该skb包就立即结束检查而接受,不再进入链表中后续的hook节点。















 1410
1410

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









