







在语音去噪中最常用的方法是谱减法,谱减法是一种发展较早且应用较为成熟的语音去噪算法,该算法利用加性噪声与语音不相关的特点,在假设噪声是统计平稳的前提下,用无语音间隙测算到的噪声频谱估计值取代有语音期间噪声的频谱,与含噪语音频谱相减,从而获得语音频谱的估计值。谱减法具有算法简单、运算量小的特点,便于实现快速处理,往往能够获得较高的输出信噪比,所以被广泛采用。该算法经典形式的不足之处是处理后会产生具有一定节奏性起伏、听上去类似音乐的“音乐噪声”。
转换到频域后,这些峰值听起来就像帧与帧之间频率随机变化的多频音,这种情况在清音段尤其明显,这种由于半波整流引起的“噪声”被称为“音乐噪声”。从根本上,通常导致音乐噪声的原因主要有:
(1)对谱减算法中的负数部分进行了非线性处理
(2)对噪声谱的估计不准
(3)抑制函数(增益函数)具有较大的可变性
推荐几篇关于谱减法介绍好的博文:
基于谱减法的声音去噪:http://blog.csdn.net/xiahouzuoxin/article/details/41124245
谱减法语音降噪原理:http://blog.csdn.net/leixiaohua1020/article/details/47276353
下面介绍一种经典谱减法:
设语音信号的时间序列为x(n),加窗分帧处理后可以得到第i帧语音信号为Xi(m),帧长为N。任何一帧语音信号Xi(m)做DFT(谱减法就要变换到频域)后为
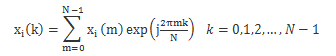
接着,我们需要得到两个分量用于后续的计算一个是幅值,一个是相位角。其中幅值就是|Xi(k)|,相位角为

在谱减中要把这两组数都保存。
已知前导无话段(噪声段)时长为IS,对应的帧数为NIS,可以求出该噪声段的平均能量值为
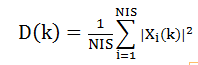
接下来就需要用原始语音减去这个噪声成分了,其计算过程如下:
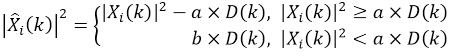
式中,a和b是两个常数,a为过减因子,b为增益补偿因子。
此时我们已经得到了在频域干净了语音,只需要经过快速傅里叶逆变换就可以得到时域的语音序列。此时这里的相位角就可以发挥作用了,由于语音信号相位不灵敏的特征,可以直接将相位角信息用到谱减后的信号中。
其流程如图所示:
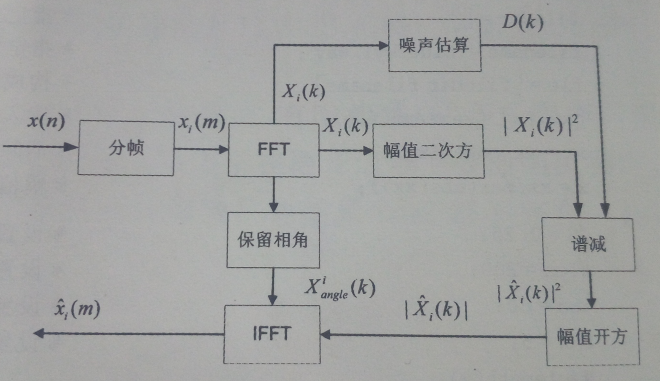
消噪后的语音有明显的“音乐噪声”,增强过减因子a数值,有时能减少“音乐噪声”,但是过大时也会使波形失真,因此同时要选用一个折中的值。又由于在语音信号叠加随机噪声,每一次叠加上的随机噪声都是不相同的。
参考文献:1.《MATLAB在语音信号分析与合成中的应用》 宋知用 编著















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









