







第6部分 正则表达式
6.1 正则表达式基础
6.1.1 定义与用途
- 定义:是一种用于匹配字符串中字符模式的工具
- 用途:它可以用来搜索、编辑和处理文本
6.1.2 匹配规则
- 注意:为了与普通文本区分开来,在表达和示例中使用了反引号``,反引号内的内容表示代码
- 普通字符:字母、数字、空格可以直接匹配它们本身,如 `a` 匹配字符 `a`,`1` 匹配字符 `1`
- 字符集:用方括号来定义一个字符集,方括号内的任意一个字符都可以匹配
表达 匹配 举例 `[...]` 字符集匹配,匹配方括号内的任意一个字符 括号内可以是范围(例如[a-z])或单独字符,例如 [abc] 匹配字符 a、b 或 c `[^...]` 非字符集匹配,匹配方括号内的任意一个字符以外的字符 [^abc] 匹配除 a、b、c 之外的任何字符 - 特殊字符:特殊字符在正则表达式中具有特殊意义,用来定义某种匹配模式
表达 匹配 举例 `.` 点号可以匹配任意单个字符(除了换行符) 正则表达式 `a.b` 可以匹配 "aab","acb",但不能匹配 "ab" `|` “或”操作符,用于匹配其左右两边的任意一个正则表达式 例如 `cat|dog` 匹配 "cat" 或 "dog" - 转义字符:在正则表达式中,转义符号(通常是 \)后面跟的特殊字符通常会形成转义元字符(元字符介绍在6.1.3),这些元字符在正则表达式中有特殊的含义和功能
表达 匹配 举例 `\` 转义字符,用来匹配特殊字符 例如,正则表达式 `\.` 可以匹配 "." 字符(这里匹配的是点号本身,注意和点号作为特殊字符匹配时区分) - 量词:量词用来指定前一个字符或子模式的重复次数
表达 匹配 举例 `*` 匹配前一个字符0次或多次(包括0次) 例如,正则表达式 `a*` 可以匹配 "","a","aa" 等 `+` 匹配前一个字符1次或多次 例如,正则表达式 `a+` 可以匹配 "a","aa" 等,但不能匹配 "" `?` 匹配前一个字符0次或1次 例如,正则表达式 `a?` 可以匹配 "","a" `{n}` 匹配前一个字符恰好 n 次 例如,正则表达式 `a{3}` 可以匹配 "aaa" `{n,}` 匹配前一个字符至少 n 次 例如,正则表达式 `a{2,}` 可以匹配 "aa","aaa" 等 `{n,m}` 匹配前一个字符至少 n 次,至多 m 次 例如,正则表达式 `a{2,4}` 可以匹配 "aa","aaa","aaaa" - 边界符号:边界符号用来指定匹配的位置
表达 匹配 举例 `^` 匹配字符串的开头 正则表达式 `^a` 可以匹配 "apple" 中的 "a",但不能匹配 "banana" 中的 "a" `$` 匹配字符串的结尾 正则表达式 `a$` 可以匹配 "banana" 中的 "a",但不能匹配 "apple" 中的 "a" `\b` 匹配单词边界,适用于匹配单词的开头或结尾 正则表达式 `\bword\b` 可以匹配 "word" 但不能匹配 "Anotherword" 或 "word123" `\B` 匹配非单词边界,适用于匹配不在单词边界的字符串部分 正则表达式 `\Bword\B` 可以匹配 "swordfish" 中间的 "word"
6.1.3 元字符
- 定义:元字符是正则表达式中具有特殊意义的字符,有的元字符本身可以作为一般的字符使用,所以要通过“转义”(前面加一个反斜杠“\”)来去除他们本身的特殊意义
- 作用:可以用来匹配数字、字母、空白字符等特殊模式,增强了正则表达式的匹配能力
- 常用元字符:
元字符 描述 `\d` 匹配任意一个数字字符, 可以代替 `[0-9]` ,但无法取代,因为方括号能表示的区间更易于调整,例如 `[0-2]`可以取更小的范围 `\D` 匹配任意一个非数字字符,相当于 `[^0-9]` `\w` 匹配任意一个字母、数字或下划线字符,相当于 `[a-zA-Z0-9_]` `\W` 匹配任意一个非字母、非数字和非下划线字符,相当于 `[^a-zA-Z0-9_]` `\s` 匹配任意一个空白字符(空格、制表符等眼睛看不到的) `\S` 匹配任意一个非空白字符(眼睛能看到的) `\t` 匹配一个制表符(Tab) `\n` 匹配一个换行符 `\r` 匹配一个回车符 `\\` 匹配一个反斜杠字符 `\` `\.` 匹配一个点字符 `.` [一-龢]或者[\u4E00-\u9FA5]匹配汉字
6.2 分组、捕获和断言
- 说明:正则表达式中的 () 用于创建捕获组,可以用来分组,这样这部分就可以被视为一个单独的整体进行匹配操作。分组不仅可以对特定部分进行重复匹配,也可以进行捕获操作,即保存匹配的子字符串以备后用
6.2.1 分组匹配
- () 用于将表达式的一部分括起来,使它们作为一个整体进行匹配,例如:
- 表达式:(abc)
- 匹配对象:abc(作为一个整体进行匹配)
6.2.2 捕获组
- 创建捕获组后,可以通过特定的方法提取分组时保存匹配的子字符串。每个捕获组都有一个唯一的编号,按照左括号出现的顺序从1开始编号。比如:
- 表达式:(\d{3})-(\d{2})-(\d{4})
- 匹配对象:123-45-6789
- 捕获组1:123
- 捕获组2:45
- 捕获组3:6789
6.2.3 引用捕获组
- 反向引用:在同一个正则表达式中,可以通过反向引用来使用之前的捕获组。反向引用的语法为 \1、\2 等,表示匹配之前捕获的内容。比如:
- 表达式:(.)\1
- 匹配对象:表示匹配一个任意字符(第一个捕获组),然后再次匹配该字符(即相同字符)
- 替换中引用:使用`Replace`方法替换字符串中的内容时,可以使用`$1`、`$2`等来引用这些捕获组,比如:
- 表达式:(.)\1+
- 替换操作:regEx.Replace("aaabbb", "$1")
- 解释:匹配任意字符后面跟随一个或多个相同字符,并将其替换为单个字符
- 代码中引用:每个正则表达式匹配对象(match)都有一个 SubMatches 集合(在6.5.2里),包含所有捕获组的内容,通过索引访问捕获组的内容(索引从0开始)可以获取匹配到的分组内容,比如:
- 匹配字符串:"aaabbbccc"
- 表达式:(.)\1+
- 代码索引:SubMatches(0)
- 解释:该正则表达式匹配到三组重复字符,使用SubMatches(0) 分别返回三个捕获组中的内容,"aaa" 返回 "a","bbb" 返回 "b","ccc" 返回 "c"
6.2.4 非捕获组和零宽断言
| 分类 | 表达 | 作用 |
| 非捕获组 | `(?:...)` | 用于分组但不捕获其中的内容,也就是确认字符串是否符合匹配格式,而不需要提取具体的部分(常用于提高效率) |
| 正向先行断言 | `(?=...)` | 用于检查某个模式在当前位置之后是否存在,但不包括在匹配结果中 |
| 负向先行断言 | `(?!...)` | 用于检查某个模式在当前位置之后是否不存在,不包括在匹配结果中 |
- 示例比较:假设我们有字符串 `foo123bar456`,并应用不同的模式:
- 非捕获组:
foo(?:123|456)- 匹配
foo123,但不捕获123或456
- 匹配
- 正向先行断言:
foo(?=\d)- 匹配
foo,条件是检查 foo 后面是否紧跟一个数字字符一个数字字符
- 匹配
- 负向先行断言:
foo(?!\d)- 匹配不到任何字符,因为条件是检查后面不紧跟着一个数字字符
6.3 创建正则表达式对象
6.3.1 前期绑定
- 添加引用库:工具 > 引用 >勾选 ’Microsoft VBScript Regular Expressions 5.5‘
- 代码:
' 直接声明reg对象就可以使用 Dim reg As New RegExp
6.3.1 后期绑定
- 使用 CreateObject 方法来创建 `VBScript.RegExp` 对象,便可使用
- 代码:
' 先声明再创建Reg对象 Dim reg As Object Set reg = CreateObject("VBScript.RegExp")
6.3.3 区别总结
| 区别 | 前期绑定 | 后期绑定 |
| 引用库 | 需要 | 不需要 |
| 代码补全和语法检查 | 支持 | 不支持 |
| 执行速度 | 较快 | 较慢 |
| 适用性 | 开发和调试阶段,方便检查提高效率 | 更灵活,适用于不确定运行环境的情况 |
- 总结:大多数情况下,正则表达式的代码都比较简单,重点在于匹配的正则表达式模式(也就是属性 Pattern ),所以推荐使用后期绑定,这样可以确保代码在不同环境下的兼容性和稳定性。
6.4 常用属性和方法
6.4.1 Global 属性
- 描述:设置是否全局搜索匹配。默认为 False,只匹配第一个
- 示例:全局匹配所有符合模式的字符串
reg.Global = True
6.4.2 Pattern 属性
- 描述:定义要匹配的正则表达式模式
- 示例:匹配任意四个字母的单词
reg.Pattern = "\b\w{4}\b"
6.4.3 IgnoreCase 属性
- 描述:设置是否区分大小写。默认为 False,区分大小写
- 示例:不区分大小写
reg.IgnoreCase = True
6.4.4 MultiLine 属性
- 描述:设置是否多行匹配模式。默认为 False,把字符串视为一整段(不分段匹配)
- 示例:多行模式
reg.MultiLine = True
6.4.5 Execute 方法
- 描述:执行正则表达式匹配,查找所有符合匹配模式的子字符串,并返回一个匹配集合对象
- 示例:查找匹配项,其中 string 是要搜索的字符串
Set matches = reg.Execute(string)
6.4.6 Replace 方法
- 描述:搜索匹配正则表达式模式的子字符串,并将其替换为指定的字符串
- 示例:把string替代为引号里的内容,并返回一个newString
newString = reg.Replace(string, "****")
6.4.7 Test 方法
- 描述:用于测试字符串是否包含匹配正则表达式模式的子字符串。它返回一个布尔值 (True 或 False),表示是否找到了匹配项
- 示例:测试在string中是否找到匹配项
result = reg.Test(string)
6.5 匹配结果的对象
6.5.1 MatchCollection 对象
含义:是一个集合对象,包含了正则表达式在输入文本中找到的所有匹配项,每个匹配项都表示为一个 Match 对象
常用属性:
- 1. Count 属性
- 功能:返回集合中 `Match` 对象的数量
- 用法:`matches.Count`
- 2. Item 属性
- 功能:返回集合中第几个 `Match` 对象,从0开始计数
- 用法:`matches.Item(index)` 或 `matches(index)`
- 示例:输出第一个匹配到的对象
Set match = matches(0) MsgBox "Found match: " & match.Value
- 3. _NewEnum 属性
- 功能:返回一个枚举器(enumerator),用于支持 For Each 循环遍历集合对象中的元素
- 用法:在 VBA 中,当定义一个集合类(比如 MatchCollection 对象)时,可以通过实现 _NewEnum 属性,使得该集合对象可以直接用于 For Each 循环
- 示例:输出匹配集合中的每个匹配值
For Each match In matches MsgBox "Found match: " & match.Value Next match
6.5.2 Match 对象
含义:表示正则表达式匹配中的一个匹配项,包含匹配的文本和其他相关信息
常用属性:
- 1. Value 属性
- 功能:返回匹配的文本
- 用法:`match.Value`
- 2. FirstIndex 属性
- 功能:返回匹配的起始位置(从0开始)
- 用法:`match.FirstIndex`
- 注意:因为FirstIndex从0开始计数,如果希望得到的位置从 1 开始计数(例如找到匹配文本在原始字符串中的起始位置),需要在实际使用时将 FirstIndex 的返回值加 1
- 3. Length 属性
- 功能:返回匹配的长度
- 用法:`match.Length`
- 4. SubMatches 属性
- 功能:返回一个 `SubMatches` 集合,包含所有捕获的子匹配项,通过索引访问捕获组的内容(索引从0开始)可以获取匹配到的分组内容
- 前提:在正则表达式模式中使用了括号来创建捕获组(捕获组内容在6.2.3里面)
- 用法:`match.SubMatches(n)`表示访问子匹配项第n+1个捕获组的内容,也就是表达式里面的第n+1个括号
6.6 VBA 正则表达式使用案例
6.6.1 计算累计金额
- 示例:选择任意一个单元格,并计算单元格内所有金额的合计数
- 注意:
- Application.InputBox(String , Type) 方法
- 解释:一个特殊的输入框函数,允许用户输入或选择数据
- 链接:Application.InputBox 方法 (Excel) | Microsoft Learn
- Type:=8表示返回用户选择的单元格对象
- Application.InputBox(String , Type) 方法
- 表达式:"\d+\.?\d*" ,匹配可能包含小数点的数字
- 代码:
Sub CalculateSumFromCell() Dim ss As Range Dim sumNum As Double Dim reg As Object Dim sj As Object Dim ss1 As Object ' 忽略运行时错误,继续执行(防止直接叉掉输入框) On Error Resume Next ' 提示用户选择一个单元格 Set ss = Application.InputBox("选择一个单元格", Type:=8) ' 没有选择单元格则退出程序 If ss Is Nothing Then MsgBox "未选择单元格": Exit Sub ' 创建正则表达式对象 Set reg = CreateObject("VBScript.RegExp") ' 设置正则表达式模式 With reg .Global = True .Pattern = "\d+\.?\d*" '匹配数字,可能包含小数点 ' 执行正则表达式,查找匹配项 Set sj = .Execute(ss) End With ' 遍历所有匹配项并累加 For Each ss1 In sj sumNum = sumNum + ss1 Next ss1 ' 显示累计结果 MsgBox "合计数为:" & sumNum End Sub
6.6.2 标记关键字符
- 示例:在选中单元格区域中,查找“金额”和“价格”字符,将其标红,并统计出现次数
- 注意:
- `.FirstIndex + 1`:获取匹配项的起始位置,FirstIndex从0开始计数,而Characters对象从1开始计数,所以需要加1
- `.Length`:获取匹配项的长度,即匹配的字符数
- [单元格].Characters(起点,长度).Font.Color:设置匹配字体的颜色
- RGB(255, 0, 0):这是红色的RGB值
- 表达式: "金额|价格",金额或者价格
- 代码:
Sub HighlightAndCount() Dim reg As Object Dim cell As Range, match As Object Dim matches As Object Dim sumJinE As Long, sumJiaGe As Long Dim startPos As Long, length As Long ' 创建正则表达式对象(后期绑定) Set reg = CreateObject("VBScript.RegExp") With reg .Global = True .IgnoreCase = True .Pattern = "金额|价格" End With ' 初始化计数器 sumJinE = 0 sumJiaGe = 0 ' 遍历选中单元格 For Each cell In Selection If reg.test(cell.Value) Then Set matches = reg.Execute(cell.Value) For Each match In matches startPos = match.FirstIndex + 1 length = match.length ' 标红匹配的文本 cell.Characters(startPos, length).Font.Color = RGB(255, 0, 0) ' 更新计数器 If match.Value = "金额" Then sumJinE = sumJinE + 1 ElseIf match.Value = "价格" Then sumJiaGe = sumJiaGe + 1 End If Next match End If Next cell ' 显示匹配项的总次数 MsgBox "“金额”出现 " & sumJinE & " 次,“价格”出现 " & sumJiaGe & " 次" End Sub
6.6.3 排除匹配
- 示例:找到给出字符串中不包含数字的部分
- 表达式:"[^0-9]+",匹配非数字字符
- 代码:
Sub ExtractNonNum() Dim reg As Object Dim matches As Object, match As Object Dim inputText As String Dim result As String Dim cell As Range ' 创建正则表达式对象(后期绑定) Set reg = CreateObject("VBScript.RegExp") ' 示例字符串 inputText = "foo123bar456baz789" ' 排除匹配示例:找到不包含数字的部分 With reg .Global = True .Pattern = "[^0-9]+" ' 执行匹配 Set matches = .Execute(inputText) End With ' 把找到的字符串连接起来 result = "排除包含数字的部分: " For Each match In matches result = result & match.Value & " " Next match ' 显示结果 MsgBox result End Sub
6.6.4 首尾匹配
- 示例:在选中单元格区域中,查找小于1000的数值并标红
- 表达式:"^(?!0\d{1,2})\d{1,3}$",匹配1000以内的数字,并排除以0开头的1到3位数
- `^`:匹配字符串的开头。
- `(?!0\d{1,3})`:负向前瞻断言,排除匹配以0开头的1到3位数。
- `\d{1,3}`:匹配1到3位数字。
- `$`:匹配字符串的结尾。
- 代码:
Sub MatchNumbers() Dim cell As Range Dim regexPattern As String Dim regex As Object Dim matches As Object ' 定义正则表达式模式 regexPattern = "^(?!0\d{1,3})\d{1,3}$" ' 创建正则表达式对象 Set regex = CreateObject("VBScript.RegExp") With regex .Global = True .Pattern = regexPattern End With ' 循环遍历选定区域的每个单元格 For Each cell In Selection ' 检查单元格内容是否匹配正则表达式 If regex.Test(cell.Value) Then ' 如果匹配,则将单元格的字体颜色设为红色 cell.Font.Color = RGB(255, 0, 0) ' 红色 End If Next cell End Sub
6.6.5 Replace替换
- 示例:在 Sheet1 中 A 列的数据为店铺名称加店仓号,将店铺名称和店仓号的位置互换

- 表达式:"\d+$",匹配字符串末尾的数字
- 思路:通过使用 `reg.Test` 方法测试是否字符串结尾为数字,如果是将字符串替换成空格,剩余部分为店铺名称,赋值给变量storeName。再把数字赋值给storeNumber,合并成新的格式
- 代码:
Sub SwapStoreAndNumber() ' 创建正则表达式对象 Dim reg As Object Set reg = CreateObject("VBScript.RegExp") ' 设置正则表达式模式,匹配数字部分 With reg .Global = True .Pattern = "\d+$" End With ' 获取数据范围 Dim ws As Worksheet Set ws = ThisWorkbook.Sheets("Sheet1") Dim lastRow As Long lastRow = ws.Cells(ws.Rows.Count, 1).End(xlUp).Row ' 遍历每一行,进行处理 Dim i As Long For i = 1 To lastRow Dim cellValue As String cellValue = ws.Cells(i, 1).Value ' 使用正则表达式测试和替换 If reg.Test(cellValue) Then ' 匹配成功,提取店铺名称和店仓号 Dim storeName As String Dim storeNumber As String ' 替换获取店铺名称部分 storeName = reg.Replace(cellValue, "") ' 提取店仓号部分 storeNumber = reg.Execute(cellValue)(0) ' 生成新的格式 "店仓号 店铺名称" ws.Cells(i, 2).Value = storeNumber & storeName Else ' 如果不包含数字,则直接复制到B列 ws.Cells(i, 2).Value = cellValue End If Next i End Sub
6.6.6 和数组结合使用
- 示例:在 Sheet1 中 A 列的数据提取出所有的数字,并将这些数字写入 B 列中
- 优点:通过数组处理数据,减少了对 Excel 单元格的频繁访问,从而提高了代码的执行效率
- 方法:先把A列的数据写入数组arr,然后遍历数组,用正则表达式匹配需要的结果,结果存储在一个新数组brr里面,最后把brr写入指定位置
- 代码:
Sub ExtractNumbers() ' 创建正则表达式对象 Dim reg As Object Set reg = CreateObject("VBScript.RegExp") ' 设置正则表达式模式,匹配数字部分 With reg .Global = False ' 只匹配第一个出现的数字 .Pattern = "\d+" ' 匹配一个或多个数字 End With ' 获取数据范围 Dim ws As Worksheet Set ws = ThisWorkbook.Sheets("Sheet1") Dim lastRow As Long lastRow = ws.Cells(ws.Rows.Count, 1).End(xlUp).Row ' 将 A 列的数据写入数组 Dim arr As Variant arr = ws.Range("A1:A" & lastRow).Value ' 创建结果数组 Dim brr() As Variant ReDim brr(1 To lastRow) ' 结果数组的大小与数据行数相同 ' 遍历数组,提取数字 Dim i As Long For i = 1 To UBound(arr) If reg.Test(arr(i, 1)) Then brr(i) = reg.Execute(arr(i, 1))(0) ' 提取并存储匹配的数字 Else brr(i) = "" ' 如果没有匹配到数字,存储为空字符串 End If Next i ' 将结果数组写回到工作表的 B 列 ws.Range("B1").Resize(lastRow, 1).Value = WorksheetFunction.Transpose(brr) End Sub
6.6.7 多个表达式循环匹配
- 示例:从 Sheet1 中的 A 列中匹配并提取符合不同模式的内容,并将结果写入 B、C、D 列中

- 方法:创建正则表达式对象时,定义多个匹配模式的表达式,并用Array把多个表达式连接在一起,再对每个数据进行循环匹配
- 代码:
Sub MultiPatternMatch() ' 创建正则表达式对象 Dim reg As Object Set reg = CreateObject("VBScript.RegExp") ' 定义多个正则表达式模式 Dim patterns As Variant patterns = Array("\d+", "[A-Za-z]+", "[^\w\s]+") ' 匹配数字、字母和特殊字符 ' 获取数据范围 Dim ws As Worksheet Set ws = ThisWorkbook.Sheets("Sheet1") Dim lastRow As Long lastRow = ws.Cells(ws.Rows.Count, 1).End(xlUp).Row ' 将 A 列的数据写入数组 Dim arr As Variant arr = ws.Range("A1:A" & lastRow).Value ' 创建结果数组 Dim brr() As Variant ReDim brr(1 To lastRow, 1 To UBound(patterns) + 1) ' 结果数组的大小与数据行数和模式数相同 ' 遍历数组,使用多个正则表达式进行匹配 Dim i As Long, j As Long For i = 1 To UBound(arr) For j = 0 To UBound(patterns) reg.Pattern = patterns(j) If reg.Test(arr(i, 1)) Then brr(i, j + 1) = reg.Execute(arr(i, 1))(0) ' 提取并存储匹配的内容 Else brr(i, j + 1) = "" ' 如果没有匹配到内容,存储为空字符串 End If Next j Next i ' 将结果数组写回到工作表的 B、C、D 列 ws.Range("B1").Resize(lastRow, UBound(patterns) + 1).Value = brr End Sub
6.6.8 懒惰模式
- 定义:懒惰模式(Lazy Mode)在正则表达式中是指匹配尽可能少的字符。默认情况下,正则表达式是贪婪的(Greedy),即尽可能多地匹配字符。懒惰模式通过在量词后面加上 `?` 实现,表示匹配尽可能少的字符
- 示例:提取一个字符串中尖括号 `<>` 内部的内容,且尽可能少地匹配字符
- 字符串: <tag1>content1</tag1><tag2>content2</tag2>
- 匹配结果对比:

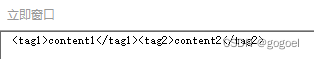
- 代码:
Sub ExtractTagsLazyMode() ' 创建正则表达式对象 Dim reg As Object Set reg = CreateObject("VBScript.RegExp") ' 设置正则表达式模式,使用懒惰模式匹配尖括号内的内容 With reg .Global = True .Pattern = "<.*?>" End With ' 定义测试字符串 Dim inputStr As String inputStr = "<tag1>content1</tag1><tag2>content2</tag2>" ' 执行正则表达式匹配 Dim matches As Object Set matches = reg.Execute(inputStr) ' 输出匹配结果 Dim i As Integer For i = 0 To matches.Count - 1 Debug.Print matches(i).Value Next i End Sub
6.6.9 分组匹配
去重
- 示例1:将重复出现的字符替换成唯一字符
- 表达式:"(.)\1+",匹配任意字符后面跟随一个或多个相同字符
- `(.)`:表示匹配任意单个字符,并将其放入捕获组1
- `\1+`:表示匹配捕获组1中字符的一个或多个重复
- 思路:先查找符合条件的字符,再使用`Replace`方法将重复的字符替换成唯一的那个字符。`$1`表示第一个捕获组,即前面匹配的单个字符
- 注意:vbCrLf 表示插入一个换行符
- 代码:
Sub ReplaceDuplicateCharacters() Dim regEx As Object Dim inputStr As String Dim outputStr As String ' 创建RegExp对象 Set regEx = CreateObject("VBScript.RegExp") ' 输入字符串,可以自行修改 inputStr = "aaabbbcccaaa" ' 设置正则表达式模式和属性 With regEx .Global = True ' 全局匹配 .IgnoreCase = False ' 区分大小写 .Pattern = "(.)\1+" ' 匹配任意字符后面跟随一个或多个相同字符 End With ' 替换重复字符 ' "$1"表示第一个捕获组,即第一个字符,重复的字符会被替换成唯一的那个字符 outputStr = regEx.Replace(inputStr, "$1") ' 输出结果 MsgBox "输入字符串: " & inputStr & vbCrLf & "替换后: " & outputStr ' 释放对象 Set regEx = Nothing End Sub
转换日期格式
- 示例2:把Sheet1中A列的YYYYMMDD格式的日期转换为YYYY-MM-DD格式
- 注意:通过先把单元格格式设置为文本(`ws.Cells(i, 2).NumberFormat = "@"`),再写入日期,可以确保显示的日期格式为 `YYYY-MM-DD`,并且在单元格编辑模式下也显示相同的格式。避免了Excel自动转换日期格式的问题(自动显示为YYYY/MM/DD格式)
- 代码:
Sub ConvertDateFormat() Dim regEx As Object Dim ws As Worksheet Dim lastRow As Long Dim i As Long Dim inputStr As String Dim outputStr As String ' 创建RegExp对象 Set regEx = CreateObject("VBScript.RegExp") ' 设置正则表达式模式和属性 With regEx .Global = True .Pattern = "(\d{4})(\d{2})(\d{2})" ' 匹配YYYYMMDD格式的日期 End With ' 获取当前工作表 Set ws = ThisWorkbook.Sheets("Sheet1") ' 假设所在工作表名称为Sheet1 ' 获取最后一行 lastRow = ws.Cells(ws.Rows.Count, "A").End(xlUp).Row ' 遍历列A中的所有日期 For i = 1 To lastRow inputStr = ws.Cells(i, 1).Value ' 获取原始日期字符串 ' 使用正则表达式替换为YYYY-MM-DD格式 If regEx.Test(inputStr) Then outputStr = regEx.Replace(inputStr, "$1-$2-$3") ws.Cells(i, 2).NumberFormat = "@" ' 设置单元格格式为文本 ws.Cells(i, 2).Value = outputStr ' 将结果写入列B End If Next i ' 释放对象 Set regEx = Nothing End Sub
文本处理
- 示例3:将店铺名称和店仓号的位置互换,和【6.5.5 Replace替换】不同的处理方式
- 表达式:”([A-Za-z]+)(\d+)“,表示匹配一个或多个大写或小写字母(店铺名称)后跟一个或多个数字(店仓号)
- 代码:
Sub SwapStoreNameAndNumber() Dim regEx As Object Dim matches As Object Dim match As Object Dim inputStr As String Dim outputStr As String ' 创建RegExp对象 Set regEx = CreateObject("VBScript.RegExp") ' 设置正则表达式模式和属性 With regEx .Global = True .Pattern = "([A-Za-z]+)(\d+)" ' 匹配店铺名称和店仓号 End With ' 输入字符串 inputStr = "StoreA123 StoreBB456 StoreCCC789" ' 使用Replace方法将店铺名称和店仓号位置交换 outputStr = regEx.Replace(inputStr, "$2$1") ' 输出结果 Debug.Print "Original String: " & inputStr Debug.Print "Modified String: " & outputStr ' 释放对象 Set regEx = Nothing End Sub
6.6.10 检查英文拼写
- 示例:使用正则表达式检查选中单元格中的英文单词拼写,并将拼写错误的单词标记为红色
- 表达式:"[a-zA-Z]{2,}'?’?[a-zA-Z]*",匹配至少两个字母的英文单词,中间可能包括英文撇号和中文单引号(防止打错)
- 方法:使用 Application.CheckSpelling(match.Value) 可以检查单词的拼写。如果返回 False,表示拼写错误
- 代码:
Sub CheckSpellingWithRegExp() Dim reg As Object Set reg = CreateObject("VBScript.RegExp") With reg .Global = True .pattern = "[a-zA-Z]{2,}'?’?[a-zA-Z]*" End With Dim cell As Range ' 遍历选中单元格区域中的每个单元格 For Each cell In Selection.Cells Dim matches As Object Set matches = reg.Execute(cell.value) ' 执行正则表达式匹配 Dim match As Object For Each match In matches If Not Application.CheckSpelling(match.value) Then ' 如果单词拼写错误,标记为红色 Dim startIdx As Long startIdx = match.FirstIndex + 1 ' 匹配的单词在单元格中的起始位置 Dim length As Long length = Len(match.value) ' 匹配的单词长度 cell.Characters(startIdx, length).Font.Color = RGB(255, 0, 0) End If Next match Next cell End Sub

















 9687
9687

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









