






QT实现BSDIFF差分算法和LZMA压缩算法制作差分包工具
一 导入新旧文件的代码
以打开旧文件为例,先创建一个.ini文件用于存放打开文件的目录,以便于下次打开时从ini文件中读取上次保存的目录,方便用户不用每次都自行进入比较复杂的目录,然后把打开的文件路径显示在ui中的QLineEdit中,并且添加日志信息,注意,这一步仅仅是为了获取文件的路径以及路径名,真正需要对文件操作是在生成差分文件的步骤中
connect(ui->importoldfile, &QPushButton::clicked, this, [&](){// 打开旧文件
QSettings setting("./Setting.ini", QSettings::IniFormat); //QSettings记录程序中的信息,下次再打开时可以读取出来
QString lastPath = setting.value("LastOldFilePath").toString(); //获取上次的打开路径
QString oldFilename = QFileDialog::getOpenFileName(nullptr, tr("打开文件"),lastPath,tr("Bin Files (*.bin)"));
if(!oldFilename.isEmpty())
{
setting.setValue("LastOldFilePath", oldFilename);
ui->oldfilepath->setText(oldFilename);
ui->log->append("旧版本文件: "+ui->oldfilepath->text());
}
else
{
ui->log->append("旧版本文件打开失败!");
}
});
二 制作差分包
制作差分包的过程分为两步,第一步先制作差分文件,第二步再进行压缩,这就需要一个中间文件,中间文件在处理完之后要进行删除。
1.bsdiff算法原理
BSDiff的三个基本步骤如下:
1.对old文件中所有子字符串形成一个字典;
2.对比old文件和new文件,产生diffstring和extra string;
3.将diffstring 和extra string 以及相应的控制字用qlz压缩算法压缩成一个patch包。
步骤1.是所有差量更新算法的瓶颈,时间复杂度为O(nlogn),空间复杂度为O(n),n为old文件的长度。BSDiff采用 Faster suffix sorting方法获得一个字典序,使用了类似于快速排序的二分思想,使用了bucket,I,V三个辅助数组。最终得到一个数组I,记录了以前缀分组的各个字符串组的最后一个字符串在old中的开始位置
步骤2.是BSDiff产生patch包的核心部分,详细描述如下:
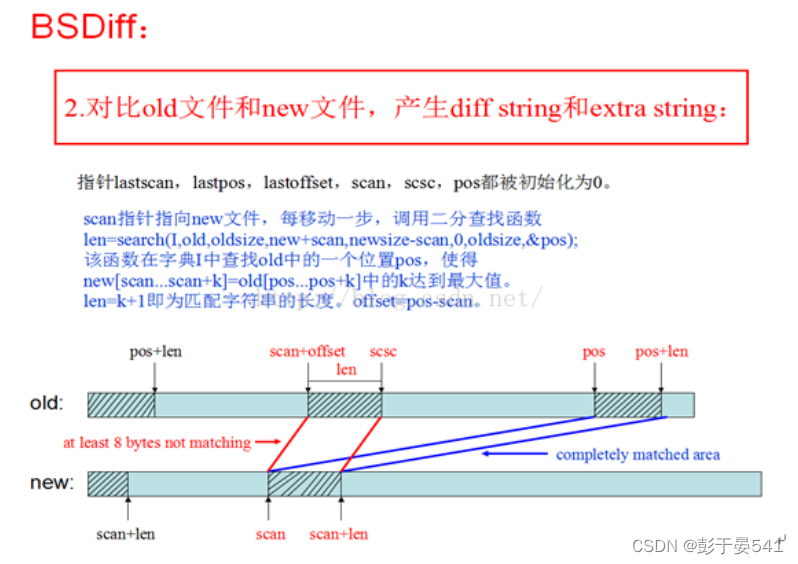
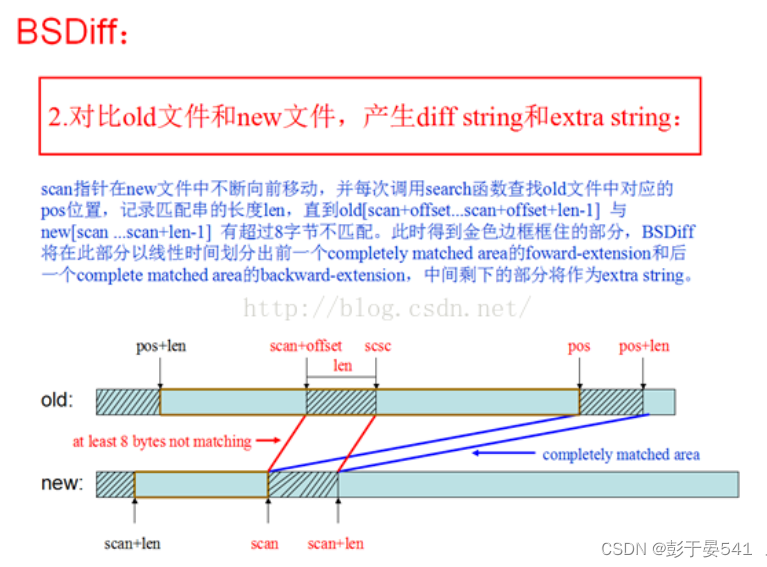
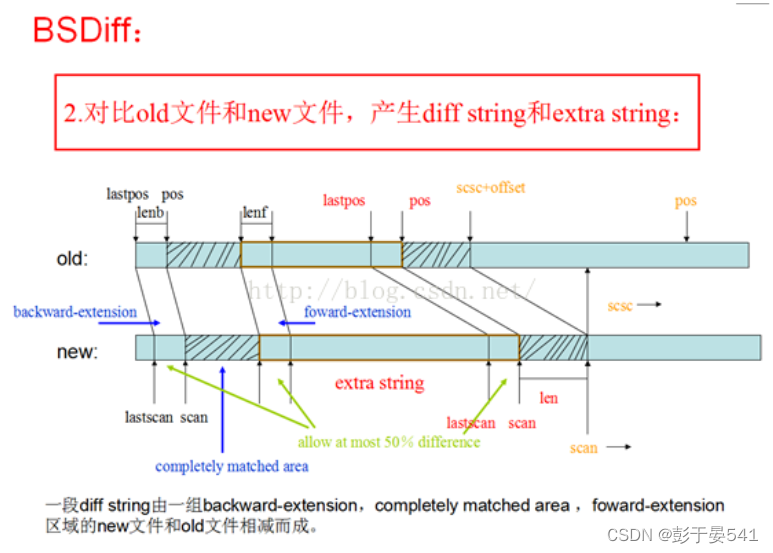
步骤3.将diff string 和extrastring 以及相应的控制字用zip压缩成一个patch包。

可以看出在用zip压缩之前的patch包是没有节约任何字符的,但diff strings可以被高效的压缩,故BSDiff是一个很依赖于压缩与解压的算法!
BSPatch基本步骤
客户端合成patch的基本步骤如下:
1.接收patch包;
2.解压patch包;
3.还原new文件。
三个步骤同时在O(m)时间内完成,但在时间常数上更依赖于解压patch包的部分,m为新文件的长度
复杂度分析
根据以上步骤,不难得出BSDiff与BSPatch的时间与空间复杂度如下:
BSDiff
时间复杂度 O(nlogn) 空间复杂度 O(n)
BSPatch
时间复杂度 O(n+m) 空间复杂度 O(n+m)
另外给出BSDiff压缩效率实验数据:
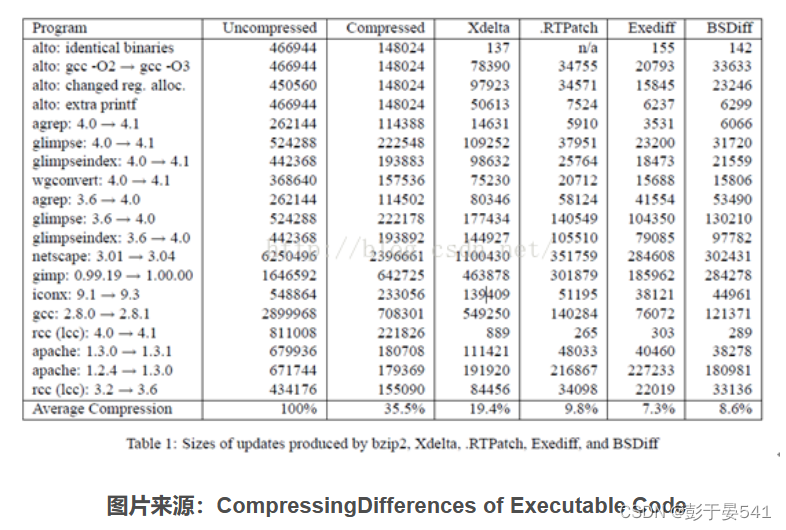
参考文献
Naïve Differences of ExecutableCode
https://www.researchgate.net/publication/2890146_Naive_Differences_of_Executable_Code
Compressing Differences ofExecutable Code
https://www.researchgate.net/publication/2379631_Compressing_Differences_of_Executable_Code
原文链接:https://blog.csdn.net/add_ada/article/details/51232889
2.BSDIFF 算法使用
可以直接使用bsdiff算法的库,该库有以下接口:
int bsdiff(const uint8_t* old, int64_t oldsize, const uint8_t* newFile, int64_t newsize, struct bsdiff_stream* stream)
{
int result;
struct bsdiff_request req;
if((req.I=stream->malloc((oldsize+1)*sizeof(int64_t)))==NULL)
return -1;
if((req.buffer=stream->malloc(newsize+1))==NULL)
{
stream->free(req.I);
return -1;
}
req.old = old;
req.oldsize = oldsize;
req.new = newFile;
req.newsize = newsize;
req.stream = stream;
result = bsdiff_internal(req);
stream->free(req.buffer);
stream->free(req.I);
return result;
}
传入参数:旧文件的指针,旧文件的大小,新文件的指针,新文件的大小,以及差分文件的文件流的结构体即可。
在生成的差分文件中,需要在头部包含一些信息,这部分信息的作用是记录新旧文件的大小,新旧文件的CRC校验码等等,以备于还原文件时用于读取和匹配。
文件头信息参考以下结构体:
/* 差分包制作时自带的文件头信息,用户只需要关心中文注释的部分 */
typedef struct image_header
{
uint32_t ih_magic; /* Image Header Magic Number */
uint32_t ih_hcrc; /* Image Header CRC Checksum 差分包包头校验 */
uint32_t ih_time; /* Image Creation Timestamp */
uint32_t ih_size; /* Image Data Size 差分包的大小 */
uint32_t ih_load; /* Data Load Address 上一版本旧文件的大小 */
uint32_t ih_ep; /* Entry Point Address 要升级的新文件的大小 */
uint32_t ih_dcrc; /* Image Data CRC Checksum 新文件的CRC */
uint8_t ih_os; /* Operating System */
uint8_t ih_arch; /* CPU architecture */
uint8_t ih_type; /* Image Type */
uint8_t ih_comp; /* Compression Type */
uint8_t ih_name[IH_NMLEN]; /* Image Name */
uint32_t ih_ocrc; /* Old Image Data CRC Checksum 上一版本旧文件的CRC */
} image_header_t;
/* 差分包制作时自带的文件头信息,用户只需要关心中文注释的部分 */
3.LZMA 压缩算法介绍
LZMA 算法是 7z 格式的默认算法。
LZMA 算法具有以下主要特征:
高压缩比
可变字典大小(最大 4 GB)
压缩速度:运行于 2 GHz 的处理器可达到 1 MB/秒
解压缩速度:运行于 2 GHz 的处理器可达到 10-20 MB/秒
较小的解压缩内存需求(取决于字典大小)
较小的解压缩代码:约 5 KB
支持 Pentium 4 的超线程(Hyper-Threading)技术及多处理器
截取项目中一段压缩接口代码的使用示例:
QString source = tr("./transfer.bin");
QString target = diffFilePath+tr("/")+diffFileName+tr(".bin");
char rs[1000] = { 0 };
//压缩
// ./Test.exe e bsdiff.bin bsdiff2.bin
//解压
// ./Test.exe d bsdiff2.bin bsdiff.bin
//int res = main2(numArgs, args, rs);
const char *p[4] = {"",
"e",
source.toUtf8(),
target.toUtf8()};
main2(4, p, rs);//该函数内有具体的压缩算法
fputs(rs, stdout);
这个接口只需要对*p[4]这个指针数组的后三个元素进行填充,第二个元素填写e或者d决定了调用压缩还是解压算法,第三个元素是需要被压缩(解压)的文件,第四个元素是压缩(解压)完成的文件。
另外,第三个参数不能由ui获取,必须是本地的某个固定路径的固定文件!!!
不然会有时候出现未生成压缩文件的后果。
举例:由ui获取了路径C:/Users/30609/Desktop/a.bin和C:/Users/30609/Desktop/b.bin,先由差分算法在该路径生成了未压缩过的差分文件temp.bin,但是作为第三个传进去的参数就必须填入C:/Users/30609/Desktop/temp.bin,最后压缩后的文件路径和文件名可以由ui获取
需要注意的是,这个接口的第三,第四个参数不能含有中文,否则会概率性出现乱码或者未生成压缩(解压)文件的情况,在代码中应对中文字符进行识别,这里使用正则表达式会比较方便。
QRegExp regExp("[\\x4e00-\\x9fa5]+");
if(!diffFilePath.contains(regExp) && !diffFileName.contains(regExp))//路径和名称中不含中文
{
... //处理文件
}
三 验证差分包
验证差分包的过程其实与生成的步骤是相反的,同样需要中间步骤,不同的是,制作时先差分再压缩,而压缩的接口内不能传入中文字符,最终生成的差分包路径和路径名中就不能含有中文字符,但是验证过程恰恰相反,先解压后还原,因此最终生成的还原文件的路径和文件名可以含有中文字符。
验证时需要先获取解压后的差分文件的文件头的信息,读取新旧文件的大小和CRC校验码,用导入的旧文件的CRC校验码匹配读取到的CRC校验码来确定差分包能否用于该文件的升级还原,而获取新文件的大小则是用于传入还原算法的接口:
int bspatch(const uint8_t* old, int64_t oldsize, uint8_t* newFile, int64_t newsize, struct bspatch_stream* stream)
{
uint8_t buf[8];
int64_t oldpos,newpos;
int64_t ctrl[3];
int64_t i;
oldpos=0;newpos=0;
while(newpos<newsize) {
/* Read control data */
for(i=0;i<=2;i++) {
if (stream->read(stream, buf, 8))
return -1;
ctrl[i]=offtin(buf);
};
/* Sanity-check */
if (ctrl[0]<0 || ctrl[0]>INT_MAX ||
ctrl[1]<0 || ctrl[1]>INT_MAX ||
newpos+ctrl[0]>newsize)
return -1;
/* Read diff string */
if (stream->read(stream, newFile + newpos, ctrl[0]))
return -1;
/* Add old data to diff string */
for(i=0;i<ctrl[0];i++)
if((oldpos+i>=0) && (oldpos+i<oldsize))
newFile[newpos+i]+=old[oldpos+i];
/* Adjust pointers */
newpos+=ctrl[0];
oldpos+=ctrl[0];
/* Sanity-check */
if(newpos+ctrl[1]>newsize)
return -1;
/* Read extra string */
if (stream->read(stream, newFile + newpos, ctrl[1]))
return -1;
/* Adjust pointers */
newpos+=ctrl[1];
oldpos+=ctrl[2];
};
return 0;
}
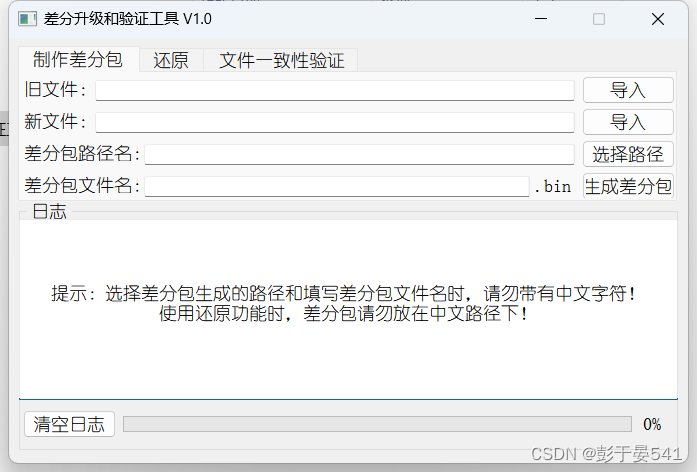
四 成品截图














 324
324











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









