







本文主要基于周志华老师的《机器学习》第八章内容
个体与集成
集成学习通过构建并结合多个学习器来完成学习任务。集成学习的一般结构如图所示:
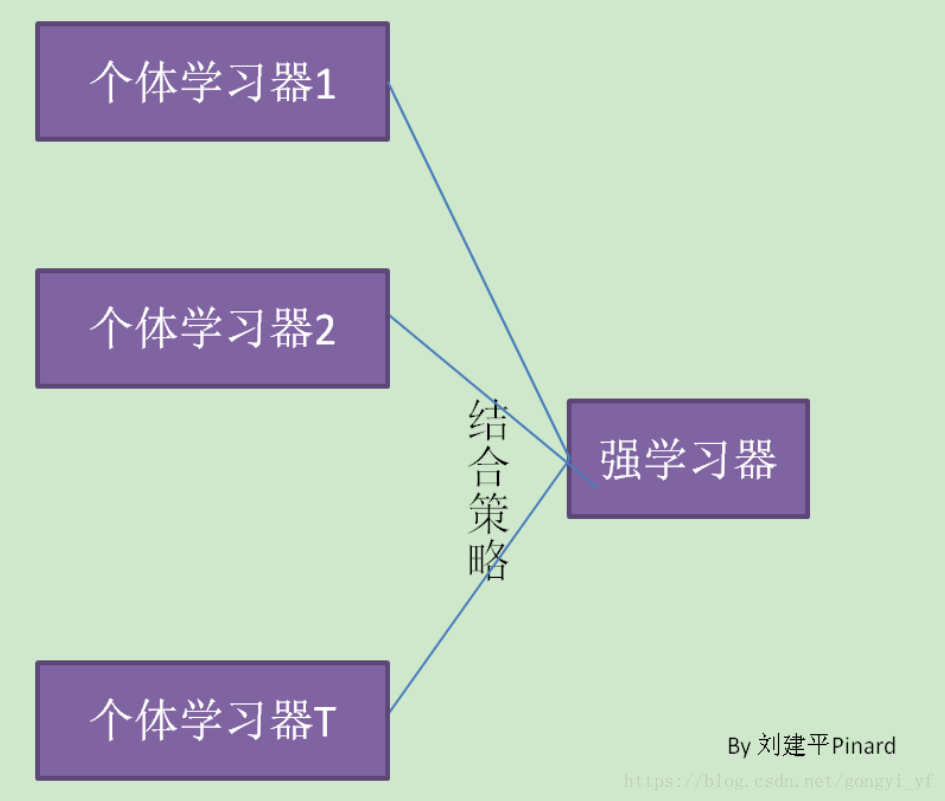
先产生一组个体学习器,在用某种策略把它们结合在一起。个体学习器通常有一个现有的学习算法从训练数据产生,如决策树桩和BP神经网络。个体学习器可以使相同类型的也可以是不同类型的,比如全是神经网络或者同事含有神经网络和决策树桩。
集成学习通过将多个学习器进行结合,通常可以获得比单一学习器显著优越的泛化性能,尤其是弱学习器(即泛化性能略优于随机猜测的学习器,比如在二分类问题上精度略高于50%的分类器)。从理论上来说,使用弱学习器集成就足以获得好的性能。
如何提高集成学习的性能?这要求个体学习器应该“好而不同”。书上的例子很好且简单易懂,这里直接拿来。
在二分类任务中,假定三个分类器在三个测试样本上的表现分别如下面的三个表所示,
其中对号表示分类正确,叉号表示分类错误,集成策略选择投票法。在(a)中,每个分类器都只有66.6%的精度,但是集成学习后达到了100%,(b)中,三个分类器完全一样,集成后没有区别,(c)中,每个分类器的精度都只有33.3%,集成后结果更差。这个例子直观的解释了为什么应该好而不同,即个体学习器要比较准确,并且各个个体学习器之间还要有一定的差异性。

集成学习根据个体学习器的生成方式可以分为2大类,如果个体学习器存在强依赖关系、必须串行生成的序列化方法,典型代表是Boosting。第二种是个体学习器之间不存在强依赖关系,可以同时生成的并行化方法,如Bagging和随机森林(Random Forest)。
Boosting
Boosting是一族可将弱学习器提升为强学习器的算法。算法的流程为:先从初始训练集训练出一个个体学习器,再根据该学习器的表现对训练样本的分布进行调整,使得先前学习器做错的训练样本在后续受到更多关注,然后基于调整后的样本分布来训练下一个个体学习器,如此反复进行,直到个体学习器的数量达到事先指定的值T或者集成的误差已经小于阈值,最终将这些个体学习器进行加权结合。
算法流程
Boosting算法族中最著名的是AdaBoost算法。下面是算法的过程:
输入:训练集 D={
(x1,y1),.....,(xm,ym)} D = { ( x 1 , y 1 ) , . . . . . , ( x m , y m ) } ,基学习算法 ξ ξ ,训练次数T
过程:
1. D1(x)=1/m. D 1 ( x ) = 1 / m . (表示第一轮时每个样本的权重是相等的)
2. fort=1,2,3,...,Tdo: f o r t = 1 , 2 , 3 , . . . , T d o :
3. ht=ξ(D,Dt); h t = ξ ( D , D t ) ;
4. εt=Px−Dt(ht(x)≠f(x)); ε t = P x − D t ( h t ( x ) ≠ f ( x ) ) ; ( f(x)是真实函数 f ( x ) 是 真 实 函 数 )
5. ifεt>0.5thenbreak i f ε t > 0.5 t h e n b r e a k
6. αt=12ln(1−εt
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 1984
1984











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









