







首先简单介绍MapReduce框架的I/O处理各个步骤:
1)从HDFS读取文件输入到Map程序中
2)将Mapper程序中的输出结果保存到本地中
3)Reducer从Mapper获取数据文件,即Reducer与Mapper之间进行网络传输操作
4)Reducer从Mapper获取相应分区的所有数据之后,会进行数据合并操作,此过程中,Reducer端对
接收到数据进行排序。
5)Reducer实例从本地硬盘中读取所有已经整理好的数据记录,调用reduce方法对数据进行处理。
6)Reducer程序的输出结果重新写回到HDFS中。
1.压缩内容选择
1)输入文件的压缩:如果对输入文件进行压缩,则将输入块读入Mapper程序中时可进行更少的I/O处理。然而,解压文件时需要消耗更多的CPU周期。
2)压缩Mapper程序的中间输出:在一个MapReduce程序中,Mapper程序中会Mapper节点上产生中间结果,这些文件被对应的Reducer程序进行分区,根据分区进行排序,并且由Reducer程序利用HTTP协议进行下载。压缩这类输出可减少文件从Mapper程序中写入到本地磁盘的文件I/O,也可以减少分区从Mapper节点传输到Reducer节点的网络I/O。
3)压缩MapReduce程序的输出:不管程序是否需要进行Reducer阶段的处理。都只对需要进行Map处理的程序应用Mapper程序进行输出,对经过Reducer处理的程序应用Reducer程序进行输出。
2.压缩方式
可使用三种标准对压缩方式进行评价
1)压缩文件的大小:越小越好,因为在磁盘和网络之间进行读写时涉及的I/O操作越少越好
2)压缩文件所用时间:越快愈好
3)已经压缩的格式是否可以进行再分割:可以分割的格式允许单一文件由多个Mapper程序处理,可实现更好的并行度。
上述三种压缩方式需要进行权衡,例如实现更快压缩的方式下需要占用更多CPU周期。
常用压缩方式的对比表格
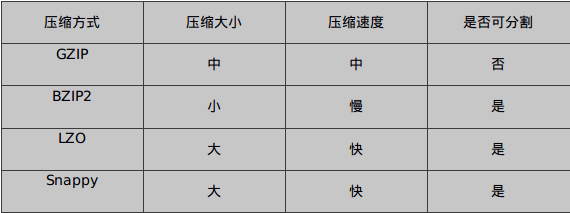
上述Snappy压缩方式比GZIP方式快几个数量级,然而输出文件更大,大出20%-100%。Snappy压缩源于Google并广泛应用MapReducer程序和衍生框架中
Hadoop框架中带有对文件进行压缩和解压缩的编码解码器(一个编码解码器CompressionCodec类的实现)。编码解码器列表由core-site.xml中的io.compression.codecs属性提供,它的值是由逗号列表,每项是CompressionCodec实现类的全类名。
默认情况是不启动压缩。可以将mapred-site.xml中的下列属性值设置为true以启用压缩。
mapreduce.output.fileoutputformat.compress 用于输出
mapreduce.map.output.compress用于Mapper程序中间输出
mapreduce.output.fileoutputformat.compress.codec 为输出配置默认的编码解码器
mapreduce.ma.output.compress.codec Mapper程序中间输出配置默认的编码解码器3.配置压缩方式
打开压缩用于输出,在配置时添加下面几行:
Configuration cond = new Configuration();
Jon job = new Job(conf);
FileOutput.setCompressOutput(job,true);
FileOutput.setOutputCompressionClass(job,GzipCodec.class);
使用Snappy的编码解码器
FileOutputFormat.setOutputCompressionClass(job,SnappyCodec.class)
打开压缩用于Mapper程序的中间输出,在配置时我们添加下面的几行
Configuration conf = new Configuration();
conf.setBoolean("mapreduce.map.output.compress",true);
conf.setClass("mapreduce.map.output.compress.codec",GzipCodec.class,CompressionCodec.class);
FileOutput.setCompressOutput(job,true);
FileOutput.setOutputCompressionClass(job,GzipCodec.class);
Job job = new Job(conf);














 865
865

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









