






定义与声明
定义变量的本质是在内存中开辟一块空间,用于存放数据
一个实例化的变量=空间+数据
定义任何变量都需要在内存中开辟空间,因为运行程序需要先加载到内存,然后才会定义变量
函数的定义也是要在内存中开辟空间的 定义是要开空间的,定义只有一次(只能初始化一次),声明可以多次,只是告知,声明不开空间
初始化和赋值是不一样的。初始化是和定义变量在一起完成,表现在汇编代码上是一条语句,在定义出变量的时候,与生俱来的就完成初始化。而赋值是另外一条汇编代码
什么是实例化?形参实例化,类实例化,相当于胖子与张三的关系,先笼统的描述,再具体为确切的某一个东西
类型
类型的本质就是偏移量,所有的虚拟地址都是资源,定义变量和创建线程都是一种抢占虚拟地址资源的行为,取地址都是只能得到一个地址,只能得到它们的起始地址加偏移量,然后连续读取多少个字节就可以把这个对象访问到。类型就是给编译器看的,然后就会让寄存器开多大来识别对象。拥有虚拟地址的资源就是拥有通过页表映射的权限,就拥有更大的物理内存
生命周期和作用域:
局部变量(临时变量)只在代码块中有效,代码块就是{}之间
函数调用→栈帧→临时变量在栈帧中开空间→临时变量具有临时性,是因为变量所在的栈帧空间具有临时性→函数调用结束,栈帧销毁→临时变量也就被释放 生命周期和作用域都和代码块强相关,但是侧重含义不同,生命周期是存活时间,作用域是影响范围
变量是在内存上开辟的一块空间,局部变量出了作用域就销毁了,是类型+变量名+初始化的值。因此,局部变量不做初始化是随机值
定义不同类型的变量意味着要开辟不同大小的空间

在另外一个文件中创建的变量在这个文件中是不能使用的,需要声明。所有变量声明时,不能设置初始值。如下图不能写=100

左值与右值
任何数据的存放都是要开辟空间的,因此,数据的属性有两个。例:int a=10
变量名在不同的应用场景中代表不同的含义
左值:数据的空间,变量属性 a = 1 a为左值,表示整型变量
右值:数据的内容,数据属性 int b = a a为右值,表示1
头文件
#pragma once防止头文件被重复包含
包含头文件是库提供的,使用<>
包含头文件是自己写的,使用""
头文件中已经包含了库中的头文件,在使用时,就不用再次包含,直接包含自己写的头文件即可
如下图,就是一个标准的头文件,包含库头文件和变量声明和函数声明

多文件之间需要进行数据交互,使用头文件便于维护
头文件默认会在当前路径或者指定路径下寻找,不需要在编译选项中带
文件操作
对文件的基本操作包括读写
操作文件需要先将文件打开,然后完成读写,然后关闭文件
每次打开一个文件,都会创建一个FILE结构体,这个结构体是与被打开文件紧密关联的,FILE结构体中包含着关于文件的所有信息。用这个结构体的指针FILE*来标定这个被打开文件的结构体的地址,从而方便做管理
FILE* pf = fopen("文件路径","打开方式")
fopen是打开文件进行文件操作的第一步,这个函数中包含两个参数,第一个参数是字符串,内容是要打开的文件的路径,可以是绝对路径,也可以是相对路径,如果不写路径,只写文件名,即默认在当前进程所在路径下打开。第二个参数是打开方式,常用的有"r"读,"w"写(每次打开都会先清空文件),"a"追加(在已有文件内容的后面追加内容)。如果文件存在于这个路径中,就会返回这个被打开文件的结构体的地址,而如果在这个路径下并不存在这个文件,就会返回一个空指针。
fclose(FILE*)关闭文件,参数是一个文件指针,用以标识关闭特定的文件
fputc将字符输出到文件中,使用如下

fputs向文件输出字符串
fgetc从文件中读取字符,读取到末尾返回EOF并设置结束标志,读取错误返回EOF
fgets从文件中读取字符串
stdin stdout stderr和所有的文件指针一样,都属于文件流(FILE* stream)
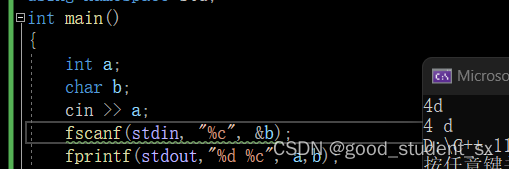
应用示例:
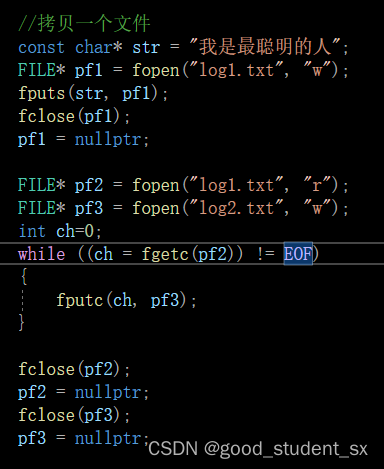
fread fwrite读写文件。ptr:指向存储读取数据的内存缓冲区的指针。size:要读取的每个元素的大小(以字节为单位)。count:要读取的元素的数量。stream:指向已打开的文件的指针,文件必须以二进制模式打开(使用 "rb" 或 "wb" 等标志)。
fprintf 和printf用法相同,只不过第一个参数是文件流指针

文件缓冲区
 EOF
EOF
EOF(End-of-File)是C语言中表示文件结束的标志符号,用于指示已到达文件的末尾或输入流的末尾。它通常被定义为-1,用于判断是否读取到了文件结束符。在输入和文件操作中,可以使用EOF来检测文件结束的状态。
那么当fgetc返回了EOF,如何判断其是读取到末尾了还是读取错误了?ferror()为真表示读取错误
feof()为真表示读取到结尾

检测EOF应该在一边读取一边检测,不能等到读取结束后再检测

static
通过头文件的包含,我们可以实现跨多文件之间的函数和变量的使用。
static修饰某一个全局变量,可以使该变量只能在该文件内使用,不能在文件外部被直接访问。
static修饰函数,只能在本文件使用,不能在文件外部被直接访问。但是可以封装访问,将static函数封装进一个函数,然后跨文件访问该函数,即可实现对跨文件static函数的访问。这就是封装思想。只对外暴露使用接口,不展示内部实现细节。
static修饰全局变量,改变了全局变量的作用域,不改变生命周期。是一种安全机制,将它限制在本文件中,对外部只暴露接口。函数也是同理,先定义,后使用,要使用需要先声明。
static修饰局部变量,会延长该变量的生命周期,将局部变量变成全局变量的生命周期,出了代码块也不销毁。但是不影响作用域,依然是只能在代码块内被访问。
理解全局数据区(数据段):包含静态数据区,已初始化全局数据区,未初始化全局数据区。全局生命周期是指在整个进程运行的过程中都是有效的。
sizeof
sizeof(a) sizeof(int) sizeof a 都是可以的。sizeof不是函数,是操作符。sizeof不仅可以求内置类型的大小,还可以求自定义类型的大小。
ASCII
在计算机中,数据的存储是0101二进制,是不能直接将字符存在计算机的,因此,将(常用符号英文字母)和数字一一建立映射关系,从而将字符转成数字,实现字符以二进制的形式在计算机上能够存储。1个字节8个比特位,2^7是128,因为是以正数表示,所以最高位是0,一共可以表示128个数字,0~127。英文字母比较少,127个数字映射字母+符号已经足够了。但是中文是由汉字组成,汉字与数字建立映射需要更多的表示方法。
unicode--万国码
Linux中一般是以UTF-8的方式
UTF-8 是使用最广的一种 Unicode 的实现方式。 其他实现方式还包括 UTF-16(字符用两个字节或四个字节表示)和 UTF-32(字符用四个字节表示)。UTF-8 是 Unicode 的实现方式之一。
utf-8 兼容ASCII。常见的汉字用2个字节表示,不常用的汉字用3个字节表示

某些场景下,会使用UTF-16编码,C++库中的String是模板,需要使用UTF-16时,只需要更改模板参数即可
乱码:代码写的方式与字符编码方式不符,在编码表中不能找到对应的字符,就会出现乱码
GBK--国标库,国人专门将汉字做了编码表
数据的存储-->整形和字符 整形转补码,字符转ASCII
整型的字面值读出来是原码形式,在计算机内部存储或在cpu计算都是以补码形式
任何数据在计算机中的存储都是以二进制形式
整型在内存中存储的是补码
整型或char等等数字运算时,只有字面值转二进制表示的是原码,截断可以用原码截断,一般是用补码截断,截断也要保留符号位。要进行计算一律使用32比特位补码,要进行原码反码补码转换,一律使用32比特位补码,不够32位的,先整形提升到32位,再进行原反补转换
有符号数:
整数在内存中的存储是符号位(正数为0,负数为1)+数据位
正数的原码反码补码相同,负数的原码第一位是1,反码是原码的符号位不变,其他位按位取反。补码是反码+1
二进制转十六进制,四位二进制转一位十六进制数

补码→原码 先取反,再+1
无符号数:
没有符号位。原码=反码=补码
unsigned int b = -10 的意义 以%d来取,就是-10,以%u来取,就是巨大的数 。而内存中存着的数据一直就只有那一份补码 ,不同类型来取代表不同意义
sizet i = -1 的含义是最大值,因为内存中存的是补码,正数原反补相同,负数的补码是取反+1,因此-1的原码是1000000000000000000000000000001,取反+1就是全是1,sizet是无符号整型,所以32位1都是有效位,表示最大值
数据在存储的时候,以数据的二进制补码先存下来。之后在读取的时候,是根据类型读取的。也就是说,单纯的数是没有意义的,必须带上前面的类型才有意义,才能表示出这个数据的意义。
先把空间开辟出来,然后把数据转化完二进制,再放到空间中
存的时候,不关心变量类型,只是将数据转成二进制补码存储(只看数字),单纯的放到开辟的内存空间中。存字面数据必须先转成补码,在放入空间当中。所谓符号位,完全看数据本身是否携带+-号,和变量是否有符号无关!
取的时候,根据变量类型取值,有符号位,就取补码转反码转原码,没有符号位就是原反补相同。取数据一定要先看变量本身类型,然后才决定要不要看最高符号位。如果不需要,直接二进制转成十进制。如果需要,则需要转成原码,然后才能识别。(当然,最高符号位在哪里,又要明确大小端)
因此,同一份内存中的补码,在不同类型的取时,表现为不同的值
大小端
所有的数据都是在内存中存储的
大小端存储本质是按照字节为单位数据和空间的对应关系
在数据层面,数据按照字节为单位,有高权值位和低权值位之分。
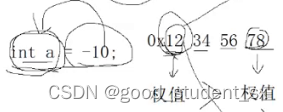
在空间层面,每个字节都有地址,地址有高地址和低地址之分。

通常来说,都是小端。按照字节为单位,小权值位在低地址。大端相反,也就是小权值位在高地址。举例如下:
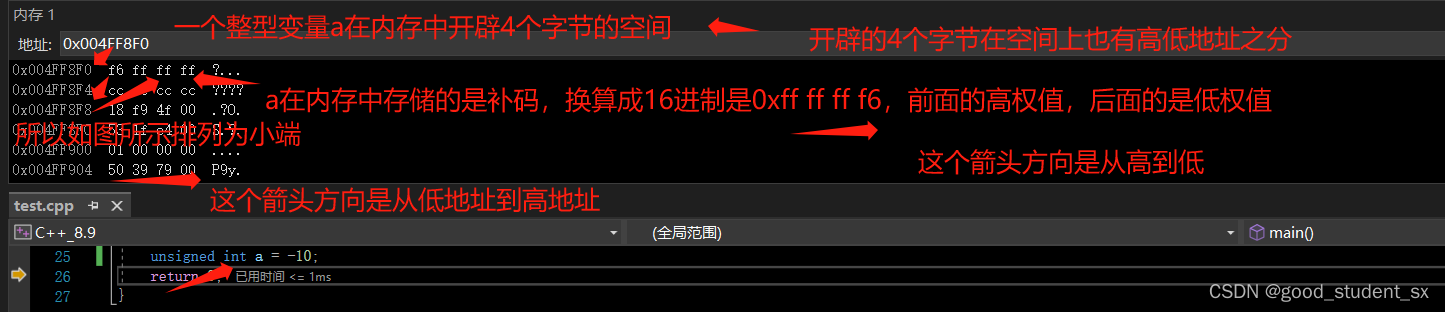 因此,数据在内存中的存储,不仅仅是受到原反补的影响,还受到大小端的影响(数据在内存中的存放顺序)。在存的时候,以补码 小端的形式存,在取的时候,以小端的形式取,还要看类型
因此,数据在内存中的存储,不仅仅是受到原反补的影响,还受到大小端的影响(数据在内存中的存放顺序)。在存的时候,以补码 小端的形式存,在取的时候,以小端的形式取,还要看类型
数据的取值范围
一个比特位存放一个二进制数,比特是最小的存储单元,只能存0和1
32位机器有32个寄存器
一个char,大小为一个字节,8个比特位,取值范围为-128 - 127 。最小值11000000,发生截断,因为最高位是符号位,所以规定它是-128。最大值01111111,也就是127。00000000表示0
同理,short的取值范围是-2^15 - 2^15-1
int的取值范围是-2^32 - 2^32-1
字符的存储
\0不是字符串的内容,但是占用字符串的空间,标识结束,如果没有\0,字符串就不知道何时结束。strlen不包含,sizeof包含。
sizeof字符串是包含\0的空间大小(字节) strlen字符串是计算\0之前的字符长度,如果没有\0就会是随机值
ASCII编码表:值和符号,一一映射对应关系
一个字符一个字节,是8个比特位,也就是8个二进制数。这就决定了它的取值范围,字符的存储是转成ASCII值,然后转补码。
字符'\0'的ASCII值是0。char a ='\0',8个比特位是00000000,32个比特位也全部是0。a以%d打印,结果为0
字符'0'的ASCII值是48,char a = '0',以%d打印,结果是48
bool类型
c99中才支持bool类型,头文件stdbool.h,win和Linux都可以。bool类型只要两个取值:true和false。大小为1个字节。 0为假,非0为真。
bool和0比较推荐使用下图写法

浮点数比较相等
浮点数本身有精度损失,不能使用==来比较
应该将两个浮点数相减,然后和定义的精度或者系统提供的精度进行比较
过程如下:
定义精度
![]()
两浮点数相减结果在误差范围内(自定义精度),即可认为相等

abs是求绝对值的函数
![]()
也可以直接与系统提供的精度比较

如果是浮点数和0比较,可以直接将该浮点数和精度比较,即 if (fabs(x)< FLT_EPSILON),表示相等
强制类型转换
int double这种表示数字大小的可以强制类型转换,不同类型的指针之间可以强制类型转换(都是指针),int和指针之间可以强制类型转换。完全没有联系的类型之间不可以强制类型转换
0 '\0' NULL 以%d的形式打印,结果都是0。说明这三个在内存中是一样的数,但是它们三个在进行使用时分属于三个类型: int char 指针,同一个数却适用于不同类型,就是发生了强制类型转换

如图所示,对于实际在内存中是一个数,却因为对他的看法不同而发生使用场景的不同,就是强制类型转换。如果是改变了内存中的数,比如将数字123转变成了字符串"123",虽然看上去都是123,但是实际在内存存储的值发生了变化,这是真实的转变,是需要调用接口来完成的。强制类型转换没有发生真实的转变,只是因为类型的不同而发挥不同的意义
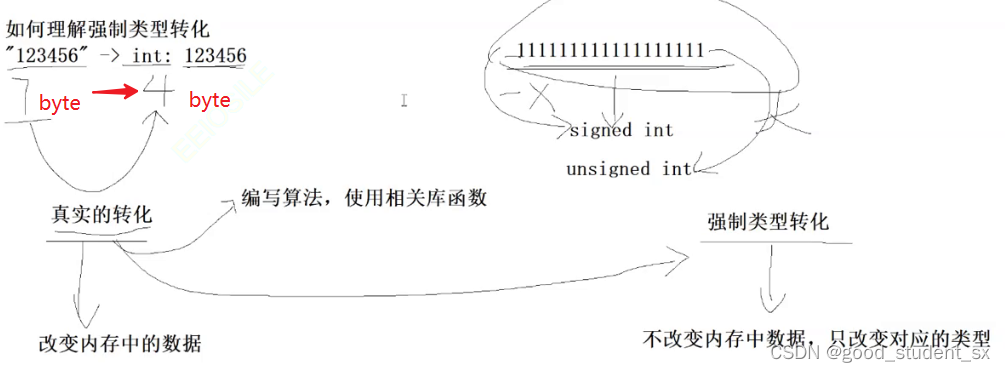
注意每一条语句最后的分号; 表示一条语句的结束
变量+运算符→表达式→语句→代码块→函数→一份C语言程序















 2055
2055

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









