




 本文深入探讨了CPU性能优化,重点在于平均负载、CPU上下文切换和中断的影响。通过实验场景展示了CPU密集型、I/O密集型以及大量进程对平均负载的影响,揭示了平均负载与CPU核心数的关系。此外,还分析了上下文切换次数过多导致的性能问题,并通过观察中断次数来评估系统性能。最后,提到了CPU时间的组成部分及其在性能分析中的作用。
本文深入探讨了CPU性能优化,重点在于平均负载、CPU上下文切换和中断的影响。通过实验场景展示了CPU密集型、I/O密集型以及大量进程对平均负载的影响,揭示了平均负载与CPU核心数的关系。此外,还分析了上下文切换次数过多导致的性能问题,并通过观察中断次数来评估系统性能。最后,提到了CPU时间的组成部分及其在性能分析中的作用。
平均负载
单位时间内,平均活跃进程数(包括可运行状态、不可中断状态).
- 可运行状态:进程正在使用 / 等待cpu
- 不可中断状态:进程正在等待硬件设备的I/O,是系统对进程和硬件设备的一种保护机制
平均负载多少算高?
一般情况下,需要结合load1、load5、load15三个值来预测趋势
- load1 > load15,说明平均负载在升高
- load1 < load15,说明平均负载在降低
结论:平均负载 > cpu core * 70%
cpu core = grep -E “processor” /proc/cpuinfo | wc -l
区别cpu使用率
CPU使用率是单位时间内CPU繁忙情况的统计。而平均负载包括正在使用CPU、等待CPU、等待IO的进程:
- CPU密集型进程,CPU使用率高,平均负载高 ==> 正在使用cpu进程
- I/O密集型进程,平均负载高,CPU使用率低 ==> 正在等待io操作进程
- 大量等待CPU的进程,平均负载高,CPU使用率也会比较高 ==> 正在等待cpu进程
模拟实验
| 工具 | 备注 |
|---|---|
| stress | linux压力测试软件 |
| sysstat | mpstat、pidstat查看cpu |
场景一:CPU密集型进程
终端1执行如下命令:
stress -c 1 --timeout 600 # 产生1个进程,压测cpu600s
终端2执行uptime查看平均负载
watch -d uptime # watch 监测 -d 表示高亮显示变化的部分
Every 2.0s: uptime
18:55:09 up 129 days, 17:37, 4 users, load average: 1.02, 1.04, 1.53
终端3查看cpu使用率变化:
mpstat -P ALL 2 5 # 每两秒刷新下所有CPU的统计报告,一共刷新显示5次
06:58:30 PM 38 100.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 # 有一个cpu的%User达到99%上
终端4查看cpu升高的进程:
pidstat -u 2 1
07:00:26 PM 0 4014 100.00 0.00 0.00 100.00 7 stress # stress进程cpu使用率达到100%
结论:平均负载的升高是由CPU使用率高造成的
场景二:io密集型进程
终端1执行如下命令:
stress -c 1 --timeout 600 # 产生1个进程,压测cpu600s
终端2执行uptime查看平均负载
watch -d uptime # watch 监测 -d 表示高亮显示变化的部分
Every 2.0s: uptime
18:55:09 up 129 days, 17:37, 4 users, load average: 1.68, 1.04, 0.78
终端3查看cpu使用率变化:
mpstat -P ALL 2 5 # 每两秒刷新下所有CPU的统计报告,一共刷新显示5次
Average: 2 1.52 0.51 10.15 16.75 0.00 0.00 0.00 0.00 0.00 71.07 # %system和%iowait还是较高
终端4查看cpu升高的进程:
pidstat -u 2 1
Average: 0 21233 0.00 2.97 0.00 2.97 - stress # stress进程的%system还是较高,说明系统调用在发生
结论:平均负载的升高是由进程等待io造成的
场景三:大量进程的情况
终端1执行如下命令:
stress -c 10 --timeout 600 # 产生1个进程,压测cpu600s
终端2执行uptime查看平均负载
watch -d uptime # watch 监测 -d 表示高亮显示变化的部分
Every 2.0s: uptime
18:55:09 up 129 days, 17:37, 4 users, load average: 10.68, 8.04, 0.78
终端3查看cpu使用率变化:
mpstat -P ALL 2 5 # 每两秒刷新下所有CPU的统计报告,一共刷新显示5次
07:15:00 PM CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle # cpu的%User基本达到100%
07:15:02 PM all 98.31 0.12 1.31 0.00 0.00 0.25 0.00 0.00 0.00 0.00
07:15:02 PM 0 98.49 0.00 1.51 0.00 0.00 0.00 0.00 0.00 0.00 0.00
07:15:02 PM 1 98.51 0.00 1.00 0.00 0.00 0.50 0.00 0.00 0.00 0.00
07:15:02 PM 2 99.50 0.00 0.50 0.00 0.00 0.00 0.00 0.00 0.00 0.00
07:15:02 PM 3 100.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
07:15:02 PM 4 98.01 0.50 1.49 0.00 0.00 0.00 0.00 0.00 0.00 0.00
终端4查看cpu升高的进程:
pidstat -u 2 1
Average: 0 25187 85.44 0.49 0.00 85.92 - stress # stress的%User升高
Average: 0 25188 55.34 0.49 0.00 55.83 - stress
Average: 0 25189 54.85 0.49 0.00 55.34 - stress
Average: 0 25190 73.79 0.49 0.00 74.27 - stress
Average: 0 25191 51.46 0.00 0.00 51.46 - stress
Average: 0 25192 48.06 0.00 0.00 48.06 - stress
结论:平均负载的升高是由进程等待cpu造成的
cpu上下文切换
平均负载一节了解到,出现大量进程等待cpu时,会出现竞争cpu情况,进程在竞争cpu的时候并没有真正运行,为什么会引起系统负载升高呢?
-
概念
linux是一个多任务操作系统,支持远大于cpu数量的任务同时运行. 很短时间内,将cpu轮流分配给它们,造成多任务同时运行的错觉.cpu上下文就是cpu寄存器和程序计数器,内部存储着进程执行所依赖的环境.
cpu上下文切换就是保存前一个任务的cpu上下文,加载新任务的cpu上下文到寄存器和程序计数器中,运行新任务.
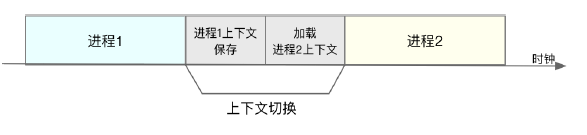
进程上下文切换次数较多的情况下,很容易导致 CPU 将大量时间耗费在寄存器、内核栈以及虚拟内存等资源的保存和恢复上,进而大大缩短了真正运行进程的时间。这也正是上一节中我们所讲的,导致平均负载升高的一个重要因素。
场景:上下文切换场景
终端1模拟多线程运行(大于cpu核数):
sysbench --threads=10 --max-time=300 threads run
终端2查看上下文切换次数:
vmstat 1
procs -----------memory---------- —swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
4 0 0 246176 44380 4851316 0 0 16 41 1 0 3 2 94 1 0
6 0 0 246264 44380 4851288 0 0 0 756 62879 1191921 17 74 8 1 0
6 0 0 240436 44388 4851276 0 0 5844 36 61314 1075210 17 74 9 0 0
7 0 0 232468 44388 4851364 0 0 7264 0 62711 1146061 19 72 9 0 0
7 0 0 224360 44388 4851532 0 0 6992 92 66109 1238124 17 76 7 0 0
发现如下特征:
- r就绪队列达到9:说明存在cpu竞争
- in中断次数达到60000多
- cs每秒上下文次数达到100多w
- sys+us基本达到95%以上,主要被sys占用,说明cpu基本被内核占用了
终端3查看线程上下文切换次数:
07:24:47 PM 0 - 32572 24030.00 76416.00 |__sysbench # 上下文切换次数升高
07:24:47 PM 0 - 32573 28676.00 65905.00 |__sysbench
07:24:47 PM 0 - 32574 29351.00 81350.00 |__sysbench
07:24:47 PM 0 - 32575 31630.00 90670.00 |__sysbench
07:24:47 PM 0 - 32576 30515.00 77848.00 |__sysbench
07:24:47 PM 0 - 32577 31343.00 65780.00 |__sysbench
Average: 0 32571 - 59.81 100.00 0.00 100.00 - sysbench # cpu使用列表升高,基本被sys占用
Average: 0 - 32572 5.74 31.58 0.00 37.32 - |__sysbench
Average: 0 - 32573 5.26 33.49 0.00 38.76 - |__sysbench
Average: 0 - 32574 6.22 28.71 0.00 34.93 - |__sysbench
Average: 0 - 32575 5.26 29.19 0.00 34.45 - |__sysbench
Average: 0 - 32576 5.74 29.19 0.00 34.93 - |__sysbench
终端4查看中断类型:
watch -d cat /proc/interrupts
从中可以观察到,以下两个参数在不断变化
Local timer interrupts
Rescheduling interrupts 重新调度中断(RES),表示唤醒空闲状态的CPU来调度新的任务运行,这是多处理器系统中,调度器用来分散任务到不同CPU的机制
结论:
每秒上下文切换次数的大小,取决于CPU性能,一般来说,切换稳定,数值从百到万以内,都算正常:
- cswch/s 切换多,说明进程在等待资源,可能发生了I/O等其他问题 资源上下文切换
- nvcswch/sq 切换多,说明进程被强制调度,也就是争抢CPU,说明CPU有瓶颈 非自愿上下文切换
- 中断次数多了,说明CPU被中断程序占用,具体可以分析 /proc/interrupts文件
cpu时间
主要说下下面几个不常见的:
nice(通常缩写为 ni)代表修改过优先级的进程占用的cpu百分比. 这里注意,nice 可取值范围是 -20 到 19,数值越大,优先级反而越低. 优先级越高,占用的cpu时间片越多.
irq(通常缩写为 hi),代表处理硬中断的 CPU 时间.
softirq(通常缩写为 si),代表处理软中断的 CPU 时间.
steal(通常缩写为 st),代表当系统运行在虚拟机中的时候,被其他虚拟机占用的CPU 时间.
guest(通常缩写为 guest),运行虚拟机的 CPU 时间.
-
案例分析 查看进程内部函数调用关系(perf)
perf top # 查看进程函数调用
ab # 模拟请求nginx,查看nginx服务性能终端1启动nginx和php容器进程:
$ docker run --name nginx -p 10000:80 -itd feisky/nginx
$ docker run --name phpfpm -itd --network container:nginx feisky/php-fpm终端2查看nginx服务性能:
并发 10 个请求测试 Nginx 性能,总共测试 100 个请求
$ ab -c 10 -n 100 http://192.168.0.10:10000/
This is ApacheBench, Version 2.3 <$Revision: 1706008 $>
Copyright 1996 Adam Twiss, Zeus Technology Ltd,
…
Requests per second: 11.63 [#/sec] (mean)
Time per request: 859.942 [ms] (mean)ab 的输出结果我们可以看到,Nginx 能承受的每秒平均请求数只有 11.63.
终端2再次查看nginx服务性能:
ab -c 10 -n 10000 http://127.0.0.1:10000/
top查看cpu,发现%User大于90%以上. 是由php进程引起.
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
21514 daemon 20 0 336696 16384 8712 R 41.9 0.2 0:06.00 php-fpm
21513 daemon 20 0 336696 13244 5572 R 40.2 0.2 0:06.08 php-fpm进一步定位是php进程哪一个函数引起:
-g 开启调用关系分析,-p 指定 php-fpm 的进程号 21515
$ perf top -g -p 21515 # 定位到php进程的sqrt和add_function函数使用 grep 查找函数调用
$ grep sqrt -r app/ # 找到了 sqrt 调用
app/index.php: x+=sqrt(x += sqrt(x+=sqrt(x);
$ grep add_function -r app/ # 没找到 add_function 调用,这其实是 PHP 内置函数结论:发现是由于测试代码没有被删除,内部执行了1000000内数字的sqrt操作,删除重新运行容器,ab测试达到2000/s以上
总结:
分析过程,应该多角度、多指标分析:
比如 案例中,发现系统%User高达80%以上,但是top查看却没有高cpu进程,pidstat -u也没有发现高cpu进程;这个时候,我们应该看看进程状态,结合pidstat、perf一步步定位到进程层面、函数层面即可.
一般cpu问题:定位到进程即可.
出现大量不可中断进程和僵尸进程
-
进程状态(常见的5个状态)
状态 说明 R cpu正在运行或正等待运行 D 不可中断状态,一般表示进程跟硬件交互不允许打断 Z 僵尸进程,表示子进程已经结束,父进程没回收它的资源(比如进程描述符、PID等) S 睡眠状态,表示进程因为等待某个事件被系统挂起. 当进程等待事件发生时,会被唤醒进入R状态 I 空闲状态,用在不可中断的内核线程上,区分D状态(不会导致平均负载升高). 说明
a) 不可中断进程:排查系统是不是出现了I/O性能问题. 引起系统的负载升高
b) 僵尸进程:这是多进程很容易碰到的问题. 正常情况下,一个进程创建子进程,会通过wait()等待子进程结束,回收子进程资源; 如果父进程没有回收子进程资源,或子进程执行太快,父进程还未来得及处理子进程状态,这时子进程就会变成僵尸进程. 大量的僵尸进程会耗尽PID进程号,导致新进程不能创建. -
案例分析
终端1启动app容器:
docker run --privileged --name=app -itd feisky/app:iowait
终端2使用top查看:
a) 平均负载升高
b) 僵尸进程较多
c) %iowait升高
d) 发现了2个状态D进程终端3执行dstat查看cpu、io使用情况
dstat 1 10 # 间隔1秒输出10组数据
发现:每当iowait升高时,磁盘的读请求(read)很大.终端4执行pidstat查看进程层面io情况
pidstat -d 1 20 # 1秒输出20组信息
发现:每秒的读数据有32M终端5执行strace查看app执行什么系统调用?
strace -p 6082 # 发现命令失效 此时应该先去看看进程是否正常 ps -ef |grep 6082 发现进程已经变成Z状态
终端6执行perf top查看系统事件:
perf top
发现app在直接读取磁盘
总结:通过修改app源码,解决了app直接读取磁盘,iowait降低; 僵尸进程一般用pstree -aps 僵尸进程pid
中断
中断是一种异步的事件处理机制,可以提高系统的并发处理能力;短暂的中断可以提高系统并发处理能力,但是长期的中断会引起性能问题,导致cpu不能处理正常的任务.
-
中断:
系统用来响应硬件设备请求的一种机制,它会打断进程的正常调度和执行,然后调用内核中的中断处理程序来响应设备的请求.
中断其实是一种异步的事件处理机制,可以提高系统的并发处理能力. -
阶段
linux将中断处理过程分为两个阶段
1.上半部分(快速处理中断),中断禁止模式下运行,处理和硬件相关、时间相关的操作
2.下半部分(异步处理后续任务),采用内核线程,采用异步方式发送信号给系统,处理后续任务比如网卡接收流量
第一部分,网卡接收到数据包,快速处理,将网卡数据读取到内存中,然后更新寄存器状态(表示数据读取好了),最后发送一个软中断信号
第二部分,从内存找到网络数据,再按照网络协议栈,对数据进行逐层解析和处理,发送给应用程序. linux启动的[ksoftirqd/0]线程 -
中断运行情况
/proc/softirqs 提供了软中断的运行情况
/proc/interrupts 提供了硬中断的运行情况
案例分析
终端1启动nginx容器:
# 运行 Nginx 服务并对外开放 80 端口
$ docker run -itd --name=nginx -p 80:80 nginx
终端2模拟nginx客户端请求,发送小包:
# -S 参数表示设置 TCP 协议的 SYN(同步序列号),-p 表示目的端口为 80
# -i u100 表示每隔 100 微秒发送一个网络帧
# 注:如果你在实践过程中现象不明显,可以尝试把 100 调小,比如调成 10 甚至 1
$ hping3 -S -p 80 -i u100 192.168.0.30
top查看系统资源状况:
看到系统的%si(软中断)占用的cpu事件较多,并且%cpu达到了56%.
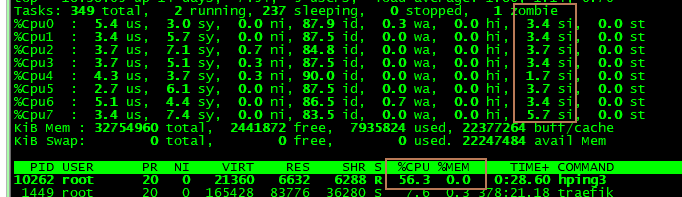
查看软中断占用情况
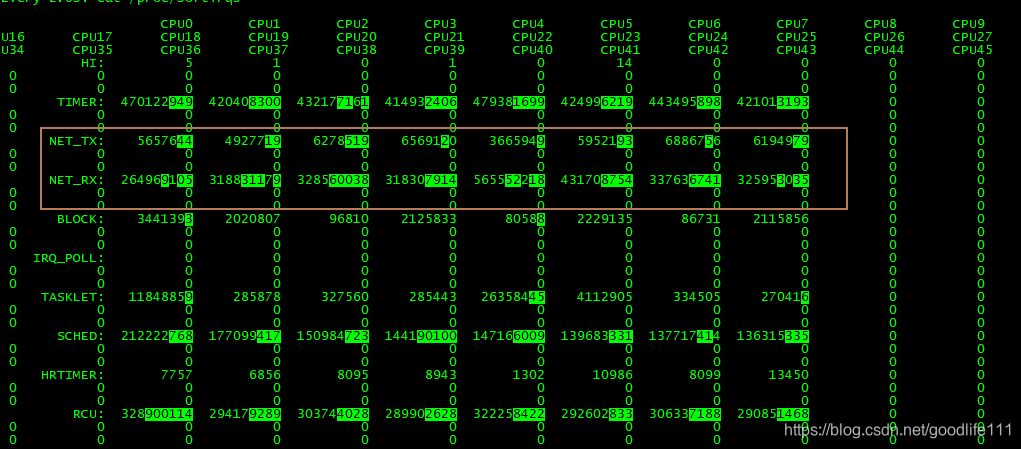
下图可以看出:主要还是网络收发变化较快
备注:其余的都是系统正常运行
TIMER(定时中断)、NET_RX(网络接收)、SCHED(内核调度)、RCU(RCU 锁)
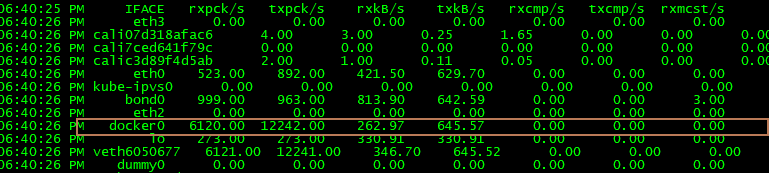
sar命令查看系统网络收发情况:
# -n DEV 表示显示网络收发的报告,间隔 1 秒输出一组数据
$ sar -n DEV 1
计算每个帧大小:645 * 1024 / 12242 = 53B,属于小包
tcpdump抓包查看:
# -i eth0 只抓取 eth0 网卡,-n 不解析协议名和主机名
# tcp port 80 表示只抓取 tcp 协议并且端口号为 80 的网络帧
$ tcpdump -i docker0 -n tcp port 80




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









