








作者 / 首席工程师 Cormac Brick,软件工程师 Haoliang Zhang
我们很高兴地发布 AI Edge Torch 生成式 API,它能将开发者用 PyTorch 编写的高性能大语言模型 (LLM) 部署至 TensorFlow Lite (TFLite) 运行时,从而无缝地将新的设备端生成式 AI 模型部署到边缘设备上。本文是 Google AI Edge 博客连载的第二篇。上一篇文章为大家介绍了 Google AI Edge Torch,该产品可以在使用 TFLite 运行时的设备上实现高性能的 PyTorch 模型推理。
AI Edge Torch 生成式 API 使开发者能够在设备上引入强大的新功能,例如摘要生成、内容生成等。我们之前已经通过 MediaPipe LLM Inference API 让开发者们能够将一些最受欢迎的 LLM 部署到设备上。现在,我们很高兴能进一步拓展对模型的支持范围,并让大家部署到设备,而且具备优秀的性能表现。今天发布的 AI Edge Torch 生成式 API 是初始版本,提供以下功能:
简单易用的模型创作 API,支持自定义 Transformer。
在 CPU 上性能表现出色,并即将支持 GPU 和 NPU。
作为 AI Edge Torch 的扩展,支持 PyTorch。
完全兼容现有的 TFLite 部署流程,包括量化和运行时。
支持 TinyLlama、Phi-2 和 Gemma 2B 等模型。
兼容 TFLite 运行时和 Mediapipe LLM 运行时接口,支持 Android、iOS 和 Web。
MediaPipe LLM Inference API
https://ai.google.dev/edge/mediapipe/solutions/genai/llm_inference
AI Edge Torch
https://ai.google.dev/edge/lite/models/convert_pytorch
我们将在本文中为大家深入介绍该 API 的性能、可移植性、创作开发体验、端到端推理流水线和调试工具链。更具体的文档和示例请查看:
https://github.com/google-ai-edge/ai-edge-torch/tree/main/ai_edge_torch/generative/examples
性能表现
为了让 MediaPipe LLM Inference API 顺利支持最受欢迎的一些 LLM,我们的团队手工打造了几款在设备上拥有最佳性能的 Transformer 模型。通过这项工作,我们确定了几个主要课题: 如何有效地表示注意力机制、量化的使用以及良好的 KV 缓存。生成式 API 很好地完成了这些课题 (本文后面会具体提到),而且依然能达到之前手写版本性能的 90% 以上,并大大提高开发速度。
通过 MediaPipe 和 TensorFlow Lite 在设备上运行大语言模型
https://developers.googleblog.com/en/large-language-models-on-device-with-mediapipe-and-tensorflow-lite/
下表显示了三种模型样本的关键基准测试结果:
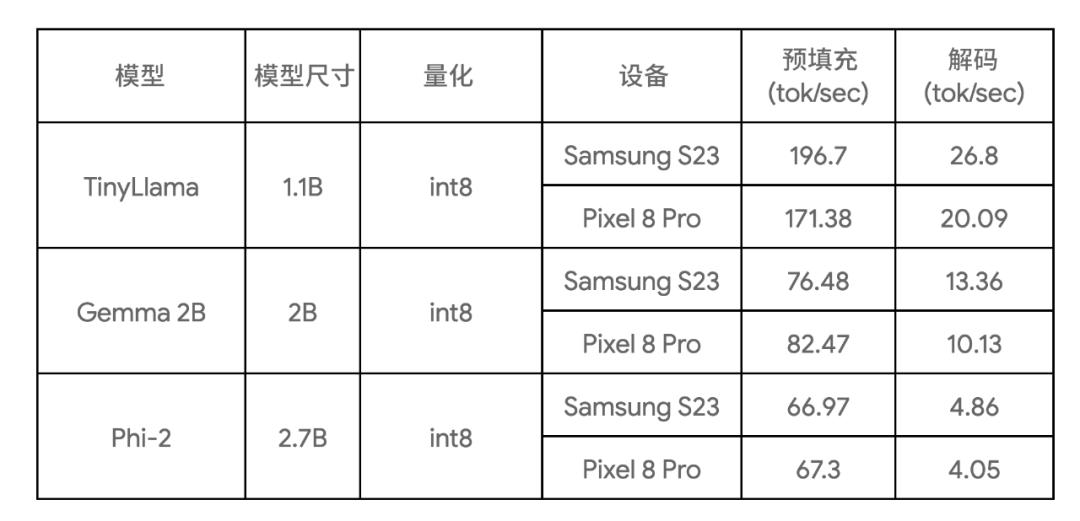
三种模型样本
https://github.com/google-ai-edge/ai-edge-torch/blob/main/ai_edge_torch/generative/examples/README.md
这些基准测试是在大核上运行,使用 4 个 CPU 线程,并且使用了这些模型在所列设备上目前所知最快的 CPU 实现。
创作体验
核
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 13
13

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









