







作者 / Ju-yeong Ji, Gemma DevRel, Ravin Kumar, Google Data Scientist, Language Applications
不久前我们对 Gemma 的架构展开了讨论,今天的文章中,我们将与您探讨 Gemma 2 模型。让我们开始吧!
讨论
https://developers.googleblog.com/en/gemma-explained-overview-gemma-model-family-architectures/
Gemma 2
最近,我们发布了具有开创性的全新开放模型套件 Gemma 2,在性能和可访问性方面树立了新标准。Gemma 2 迅速崭露头角,目前可选的参数版本有 2B、9B 和 27B 三种。Gemma 2 27B 模型在 LMSYS 聊天机器人竞技场排行榜上的排名迅速攀升。在引人入胜的实际对话方面,27B 模型的表现甚至优于规模为其两倍以上的热门模型,跻身成为排名最高、最实用的开放模型之一。与此同时,Gemma 2 2B 可以在边缘设备上运行,展示了其卓越的对话式 AI 能力,强于聊天机器人竞技场上的所有 GPT-3.5 模型。
开发者可以跨平台和工具使用 Gemma 2 强大的调优功能。我们通过 Google Cloud 等基于云的解决方案和 Axolotl 等社区工具简化了 Gemma 2 的微调流程。通过与 Hugging Face 和 NVIDIA TensorRT-LLM 等合作伙伴以及 JAX 和 Keras 的无缝集成,我们实现了跨多种硬件配置的性能优化和高效部署。
Google Cloud
https://console.cloud.google.com/vertex-ai/publishers/google/model-garden/gemma2
Axolotl
https://github.com/OpenAccess-AI-Collective/axolotl
以下是这款新模型的核心参数:
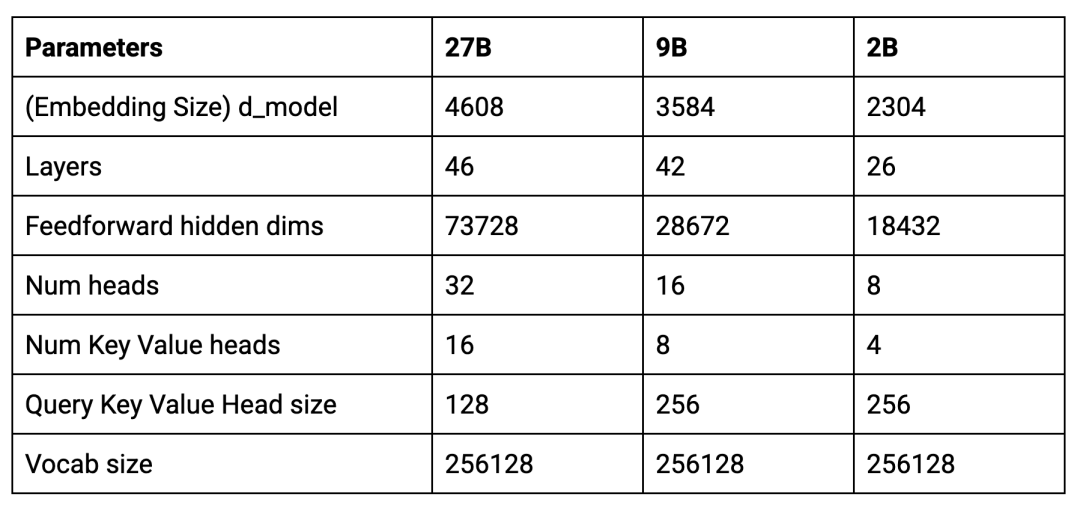
主要差异
Gemma 2 与原始 Gemma 模型具有相似的架构基础,包括旋转位置编码 (RoPE) 和近似的 GeGLU 非线性。然而,新的架构创新赋予了 Gemma 2 有别于前几代模型的特色。
交替局部注意力和全局注意力
Gemma 2 并非一次性考虑文本中的所有字词,有时只关注一小段字词 (局部注意力),有时也会考虑所有字词 (全局注意力)。这种组合有助于模型高效理解文本的即时上下文和整体含义。
Logit 软上限
假设您正在训练一个模型来预测句子中的下一个字词。有时,模型可能会对某个字词的预测过于自信,即使这并非是最佳选择。Logit 软上限可通过限制模型对其预测的信心程度来预防这种情况,从而提高整体性能。
用于预归一化和后归一化的 RMSNorm
我们可以将此视为在训练期间防止模型的计算变得过大或过小的一种方法。就像我们可以通过调整音响的音量来防止声音失真一样,RMSNorm 可确保流经模型的信息保持在合理的范围内,从而实现更稳定且有效的训练。
分组查询注意力 (GQA)
这种技术提高了模型处理信息的效率,尤其是在处理大量文本时。通过将查询分组来改进传统的多头注意力机制 (MHA),从而加快处理速度,尤其是针对大型模型。这类似于将大型任务拆分为更小、更易于管理的分块,使模型能够在不牺牲准确性的情况下更快地理解字词之间的关系。
Gemma 27B
Gemma2ForCausalLM(
(model): Gemma2Model(
(embed_tokens): Embedding(256000, 4608, padding_idx=0)
(layers): ModuleList(
(0-45): 46 x Gemma2DecoderLayer(
(self_attn): Gemma2SdpaAttention(
(q_proj): Linear(in_features=4608, out_features=4096, bias=False)
(k_proj): Linear(in_features=4608, out_features=2048, bias=False)
(v_proj): Linear(in_features=4608, out_features=2048, bias=False)
(o_proj): Linear(in_features=4096, out_features=4608, bias=False)
(rotary_emb): Gemma2RotaryEmbedding()
)
(mlp): Gemma2MLP(
(gate_proj): Linear(in_features=4608, out_features=36864, bias=False)
(up_proj): Linear(in_features=4608, out_features=36864, bias=False)
(down_proj): Linear(in_features=36864, out_features=4608, bias=False)
(act_fn): PytorchGELUTanh()
)
(input_layernorm): Gemma2RMSNorm()
(post_attention_layernorm): Gemma2RMSNorm()
(pre_feedforward_layernorm): Gemma2RMSNorm()
(post_feedforward_layernorm): Gemma2RMSNorm()
)
)
(norm): Gemma2RMSNorm()
)
(lm_head): Linear(in_features=4608, out_features=256000, bias=False)
)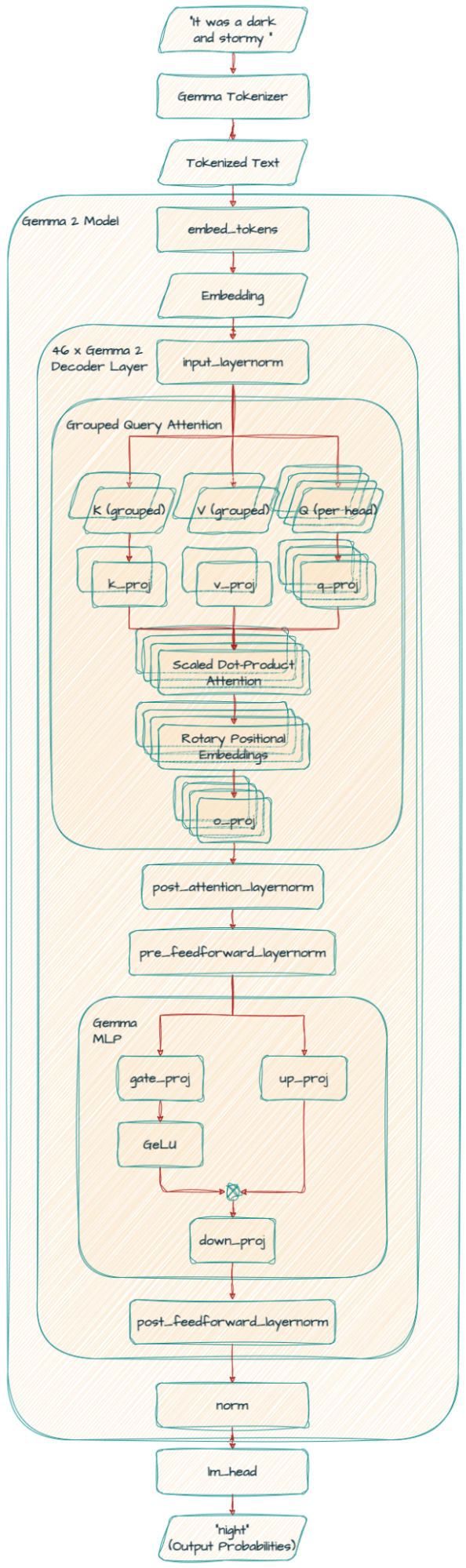
self_attn
在自注意力 (self-attention) 机制中,Gemma 2 使用了分组查询注意力 (GQA)。
k_proj 和 v_proj 共享相同的头部,每个头部的大小为 128,共有 16 个头 (128 x 16 = 2,048)。相比之下,q_proj 和 o_proj 有 32 个头并行运行 (128 x 32 = 4,096)。
请注意,Gemma 9B 模型使用相同的 GQA,但头的数量不同 (k_proj 和 v_proj 为 8 个头,q_proj 和 o_proj 为 16 个头),且头的大小为 256。
(self_attn): Gemma2SdpaAttention(
(q_proj): Linear(in_features=3584, out_features=4096, bias=False)
(k_proj): Linear(in_features=3584, out_features=2048, bias=False)
(v_proj): Linear(in_features=3584, out_features=2048, bias=False)
(o_proj): Linear(in_features=4096, out_features=3584, bias=False)
(rotary_emb): Gemma2RotaryEmbedding()
)Gemma 2B 模型使用的是: k_proj 和 v_proj 的头数量为 4,q_proj 和 o_proj 头数量为 8,头的大小为 256。
pre_feedforward_layernorm
和 post_feedforward_layernorm
另一个显著区别是 Gemma 2 中增加了额外的 RMSNorm,这增强了训练过程中的稳定性。
重要研究结果
我们在技术报告中提供了详细信息,关于 Gemma 2 主要研究结果的总结如下:
技术报告
https://storage.googleapis.com/deepmind-media/gemma/gemma-2-report.pdf
模型蒸馏与从零开始训练
我们使用模型蒸馏的方法使其从较大的模型 (27B) 提取知识来训练 2B 和 9B 模型。
从更大的模型中蒸馏知识,即使使用相同数量的 token 训练,也能显著提高性能。
分组查询注意力与多头注意力
用 GQA 取代 MHA,能够在提高参数效率和缩短推理时间的同时,实现同等性能,使 GQA 成为首选。
模型深度与宽度
在参数数量相同的情况下,较深模型的性能表现略优于较宽的模型。
未来计划
在本文中,我们介绍了下一代 Gemma 模型: Gemma 2。
未来我们将与您探讨基于 Griffin 的开放模型: RecurrentGemma。
Griffin
https://arxiv.org/abs/2402.19427
如果您想深入探索迷人的 AI 世界,并从该领域的前沿专家那里获得见解,欢迎您访问 http://goo.gle/ai-podcast,收听 "People of AI Podcast" 节目。
欢迎您持续关注,感谢您的阅读!




谷歌开发者特别招募活动进行中
诚邀热爱技术的你加入
通过多种形式 (文章/视频/coding 等) 创作与 Google 技术相关的讲解分享、实践案例或活动感受等内容,以及分享您应用 AI 技术的故事经历与成果。我们将为您提供平台和资源,助力您在分享中提升技能。更有惊喜权益等您领取,快来报名参与吧!
 点击屏末 | 阅读原文 | 即刻体验 Gemma 2
点击屏末 | 阅读原文 | 即刻体验 Gemma 2




















 10
10

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









