







 Google 推出的新版“声音搜索”采用“闻曲知音”技术,提升了音乐识别的速度和准确性。该技术利用深度神经网络处理音频,生成独特的音乐指纹,在设备本地和服务器端实现高效匹配。通过增加神经网络大小、提高嵌入维度和优化索引加权,新版“声音搜索”在保持快速响应的同时,能处理更多歌曲,提供更佳识别体验。
Google 推出的新版“声音搜索”采用“闻曲知音”技术,提升了音乐识别的速度和准确性。该技术利用深度神经网络处理音频,生成独特的音乐指纹,在设备本地和服务器端实现高效匹配。通过增加神经网络大小、提高嵌入维度和优化索引加权,新版“声音搜索”在保持快速响应的同时,能处理更多歌曲,提供更佳识别体验。
文 / Google AI 苏黎世办公室 James Lyon
2017 年,我们发布了具有闻曲知音功能的 Pixel 2,就是利用深度神经网络为移动设备带来低功耗、始终开启的音乐识别功能。在开发 “闻曲知音” 时,我们的目标是打造一个小巧高效的音乐识别器,这需要数据库中的每个曲目有一个非常小的指纹,以支持音乐识别功能完全在设备上运行,而无需连接互联网。事实证明,“闻曲知音” 不仅对设备上的音乐识别器有效,其准确性和效率也大大超出我们当时使用的服务器侧系统声音搜索,后者构建之时深度神经网络尚未得到广泛应用。很自然地,我们就想能否将 “闻曲知音” 背后的技术用于服务器侧 “声音搜索” 中,让 Google 的音乐识别功能成为世界之最优。
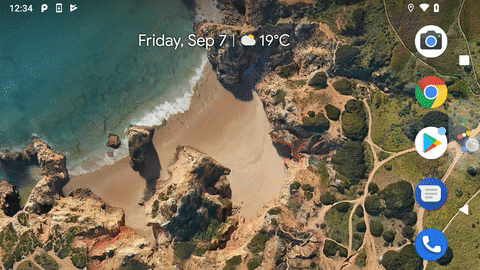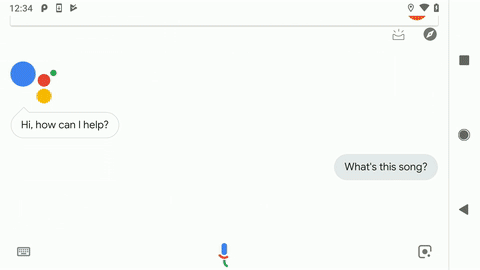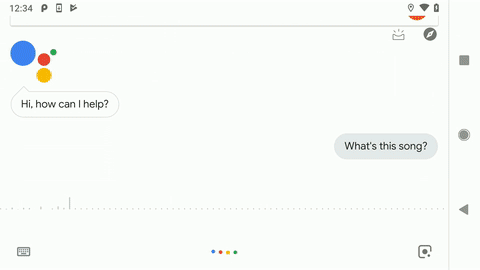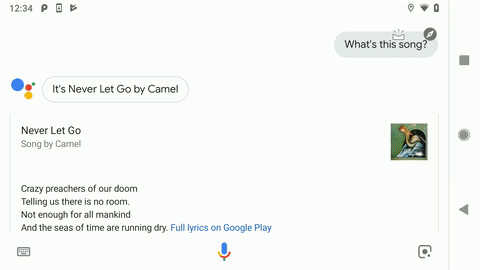
最近,我们发布了新版本 “声音搜索”,其中就采用了 “闻曲知音” 中使用的部分技术。您可以在任意 Android 手机上通过 Google 搜索应用或 Google 智能助理来使用这一功能。只要开启语音查询功能,当您附近有音乐正在播放时,系统就会弹出 “这首歌的歌名是什么?” 的提示,供您点击查询。或者,您也可以直接问:“Hey Google,这首歌的歌名是什么?” 使用最新版本的 “声音搜索”,即可获得比以往更快更准确的搜索结果!
“闻曲知音” 与 “声音搜索” 对比
“闻曲知音” 使音乐识别技术微型化,令其变得小而高效,足以在移动设备上连续运行而不会对电池产生明显影响。为此,我们开发了一个全新的系统,使用卷积神经网络将几秒的音频转换成一个独特的 “指纹”。然后,系统会将指纹与设备上储存海量音乐的数据库进行比对,该数据库会定期更新以添加最新发布的曲目并删除过气曲目。相比之下,服务器侧 “声音搜索” 系统则不同,其需要比对的曲目约为 “闻曲知音” 的 1000 倍之多。由于音乐库的数量过于庞大,这对搜索的速度和准确性都是极大的挑战。在深入讨论这部分内容之前,我们先来了解一下 “闻曲知音” 的运作原理。
“闻曲知音” 的核心匹配流程
“闻曲知音” 通过将八秒音频片段的音乐特征投影到一系列低维嵌入式空间来生成音乐 “指纹”,这些低维嵌入式空间包含七个时长两秒的音频片段,片数之间的时间间隔为一秒,由此产生如下分段图:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 411
411

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









