







文 / Yanping Huang,Google AI 软件工程师
深度神经网络 (DNN) 已推动诸多机器学习任务取得进步,其中包括语音识别、视觉识别和语言处理。BigGan、Bert 以及 GPT2.0 取得的最新进展表明,随着 DNN 模型规模逐渐增大,任务处理的表现也逐渐提升。此外,视觉识别任务过往取得的进步也表明模型大小和分类准确度之间存在很强的关联性。例如,2014 年 ImageNet 视觉识别挑战赛的获胜者 GoogleNet 使用 400 万参数实现 74.8% 的 top-1 准确率,而短短三年之后,2017 年 ImageNet 挑战赛的获胜者 Squeeze-and-Excitation Networks 就使用 1.458 亿(超过 36 倍)参数实现 82.7% 的 top-1 准确度。然而,在此期间,GPU 内存仅扩大了 3 倍左右,而目前最先进的图像模型已达到 Cloud TPUv2 可用内存的上限。因此,我们急需一款可扩容的高效基础架构来实现大规模深度学习,并克服当前加速器上的内存限制问题。
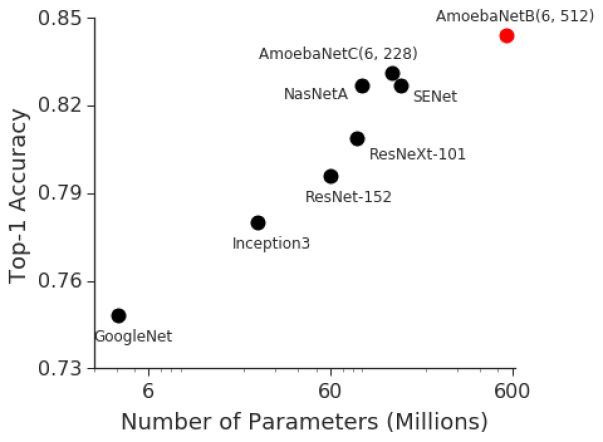
最近开发的具有代表性的图像分类模型呈现出 ImageNet 准确率与模型大小之间的高度关联性
在 "GPipe:Efficient Training of Giant Neural Networks using Pipeline Parallelism"(使用流水线并行技术有效培训巨型神经网络)一文中,我们展示了如何使用流水线并行技术扩展 DNN 训练,从而克服这一限制。GPipe 是一个分布式机器学习库,使用同步随机 梯度下降 和流水线并行技术进行训练,适用于任何由多个序列层组成的 DNN。重要的是,GPipe 让研究人员无需调整超参数,即可轻松部署更多加速器,从而训练更大的模型并扩展性能。为了证明 GPipe 的有效
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 16
16

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









