







 Google 推出端到端全神经设备端语音识别器,支持 Gboard 语音输入,使用 RNN 变换器技术,实现无网络延迟和离线状态下的高效识别。此模型直接将音频转化为字符输出,提高实时语音转写的准确性和流畅性。
Google 推出端到端全神经设备端语音识别器,支持 Gboard 语音输入,使用 RNN 变换器技术,实现无网络延迟和离线状态下的高效识别。此模型直接将音频转化为字符输出,提高实时语音转写的准确性和流畅性。
文 / Johan Schalkwyk,Google 语音团队研究员
2012 年,研究表明,语音识别技术可借助深度学习显著提升准确度,很多产品因此开始采用这项技术,例如 Google 语音搜索。 这是该领域变革的开端:此后,每年都会有新的架构出现,不断提升语音识别质量,其中包括深度神经网络 (DNN)、递归神经网络(RNN)、长短期记忆网络 (LSTM)、卷积网络 (CNN) 等。在此期间,延迟问题仍然是人们关注的焦点,毕竟能够快速响应请求的自动助手会让用户感觉更有帮助。
我们很高兴地宣布推出端到端的全神经设备端语音识别器,为 Gboard 的语音输入功能提供支持。在我们近期的论文《用于移动设备的流式端到端语音识别》中,我们展示了使用 RNN 变换器 (RNN-T) 技术训练的模型。该模型非常紧凑,可放入手机中。这意味着语音识别不再有网络延迟或声音断断续续的问题 — 全新识别器始终可供使用,即使在离线状态下也是如此。该模型在字符级运行,因此只要您开始讲话,模型就会逐个字符地输出单词,就像有人实时打出您讲话的内容一样,完全符合您对键盘听写系统的期望。
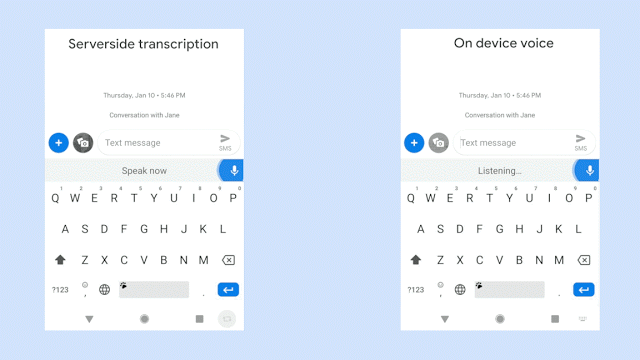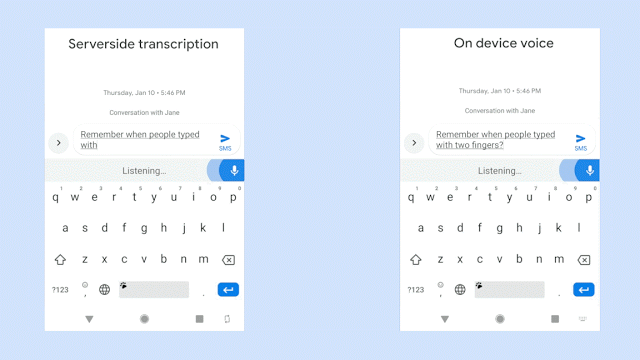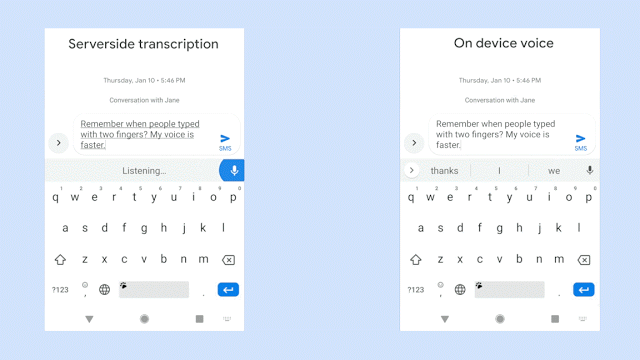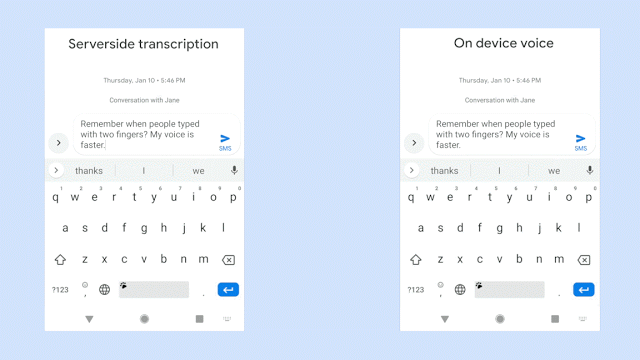
此图,比较在识别相同的语音句子时,服务器端语音识别器(左侧面板)和全新设备端识别器(右侧面板)的输出效果。来源:Akshay Kannan 和 Elnaz Sarbar
历史回顾
在过去,语音识别系统是由多个组件构成,其中包括将音频片段(通常为 10 毫秒帧)映射到音素的声学模型、将音素连接起来形成单词的发音模型,以及表达可能的给定短语的语言模型。在早期系统中,这些组件保持独立优化。
大约在 2014 年ÿ
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 16
16

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









