






weditor 获取选中的tab时:

(放百度app的weditor截图会违规被删)
1、若能获取selected属性:
比如此时百度app的tab被选中,可以获取 selected属性,true为被选中,false为未被选中。
获取selected:
selected = d(resourceId="com.baidu.searchbox:id/home_tab_item_textview", text="百度").info['selected']2、若无法获取selected属性:
可以使用 opencv对屏幕图片做图像处理后,使用OCR判断哪个tab被选中
1)若选中的效果是文字高亮:

比如:下方首页tab的白色高亮;
直接保留高亮的颜色即可,OCR的文字即为选中的tab,具体如下:
首先获取app截图:
import uiautomator2 as u2
d = u2.connect()
image = d.screenshot(format='opencv')然后保留高亮的颜色,颜色的范围需要自己获取:
def reserve_color(image, color_list):
"""
保留颜色, 保留 color_list 里的颜色
color_list: list
白色: ((0, 0, 211), (180, 30, 255))
红色:((0, 170, 80), (20, 255, 255))
"""
# 将图像转换为hsv颜色空间
hsv = cv2.cvtColor(image, cv2.COLOR_BGR2HSV)
final_mask = np.zeros_like(image)[:, :, 0] # 掩膜
for color in color_list:
lower, upper = color
mask = cv2.inRange(hsv, lower, upper)
final_mask = cv2.bitwise_or(final_mask, mask) # 合并掩膜
channels = cv2.split(image) # 切分通道
result = []
for channel in channels:
result.append(cv2.bitwise_and(channel, final_mask))
image = cv2.merge(result) # 合并通道
return image注意的是,color_list的color是HSV值过滤的下限和上限,不知道HSV颜色的,可以使用这个函数转换:
def get_point_hsv(image, x, y):
hsv = cv2.cvtColor(image, cv2.COLOR_BGR2HSV)
return hsv[y, x]然后对过滤颜色后的图片做OCR,这里推荐用CnOCR:
from cnocr import CnOcr
ocr_obj = CnOcr()
res_dict = ocr_obj.ocr_for_single_line(image)
text = res_dict['text']若识别不准确,可以调整模型,识别函数等内容,具体参照:
https://cnocr.readthedocs.io/zh/latest/
2)若选中的效果是tab选中框:
比如微信的这种:
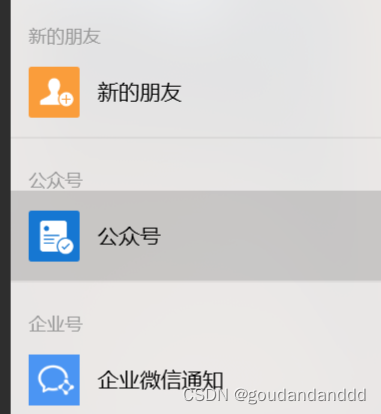
因为没有高亮的文字颜色,所以不能选择保留文字的颜色;
可以跟前面使用相同步骤,只是保留的颜色需要保留选中框的颜色,也就是灰色,只保留灰色以后,中间的文字就会被去掉,变成黑色,可以使用OCR识别;















 5459
5459











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









