







第十一章 聚类分析
这本书讲得很浅,基本原理讲一讲,更侧重于用软件解决问题。
聚类是一个把数据对象集划分成多个组或簇的过程,使得簇内的对象具有很高的相似性,但与其他簇中的对象很不相似。
对于聚类方法的分类,有以下几种:
- 基于划分的聚类:把数据划分为k个组,使得每个组至少包含一个对象。大部分划分方法是基于距离的,给定要构建的分区数k,首先创建一个初始划分,然后采用一种迭代的重定位技术,通过把对象从一个组移动到另一个组来改进划分。适合发现中小规模的数据库中的球状簇。
- 基于层次的聚类:分为凝聚的或分裂的方法,也就是自底向上或自顶向下,由分到总或由总到分。可以使基于距离的或是基于密度的和连通性的,也考虑了子空间聚类。
- 基于密度的聚类:只要是“领域”中的密度超过某个阈值,就继续增长给定的簇,可以发现任意形状的簇。
- 基于网格的方法:把对象空间量化为有限个单元,形成一个网格结构,所有的聚类操作都在这个网格结构上进行,处理速度快。
- 基于划分的方法
- k-均值:
假设数据集D包含n个欧式空间中的对象,划分方法把D中的对象分配到k个簇C1,.......,Ck中,使得对于1≤i,j≤k,Ci包含于D且Ci∩Cj=∅,一个目标函数用来评估划分的质量,使得簇内对象相互相似,而与其他簇中的对象相异,也就是说,该目标函数以簇内高相似性和簇间低相似性为目标。
基于形心的划分技术使用簇Ci的形心代表该簇,簇的形心是它的中心点,形心可以有多种定义,例如簇内的对象的均值或中心点等等。Ci内对象p与簇内代表ci之间的差用dist(p,ci)来度量,dist(x,y)是两个点xy之间的欧氏距离。簇Ci的质量可以用簇内变差度量,它是Ci中所有对象和形心ci之间的误差的平方和,定义为:
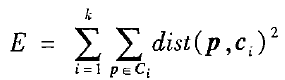
k-均值算法把簇的形心定义为簇内点的均值,它的处理流程如下,首先,在D中随机地选择k个对象,每个对象代表一个簇的初始均值或中心。对剩下的每个对象,根据其与各个簇中心的欧式距离,将它分配到最相似的簇。然后,k-均值算法迭代地改善簇内变差。对于每个簇,使用上次迭代分配到该簇的对象,计算新的均值。然后,使用更新后的均值作为新的簇中心,重新分配所有对象。迭代继续,直到分配稳定,即本轮形成的簇与前一轮形成的簇相同。
k-均值方法常常会有局部最优解。
- 基于层次的方法
将数据对象组成层次结构或簇的“树”,凝聚和分裂层次聚类分别使用自底向上和自顶向下策略把对象组织到层次结构中。
凝聚的层次聚类方法使用自底向上的策略,令每个对象形成自己的簇,迭代地把簇合并成越来越大的簇,直到所有的对象都在一个簇中,或者满足某个终止条件;分裂的层次聚类方法使用自顶向下的策略,把所有对象至于一个簇中,该簇是层次结构的根,然后把根上的簇划分成多个较小的子簇,并且递归的把这些簇划分成更小的簇,直到最底层的簇都足够凝聚。
凝聚的层次聚类算法中的代表是AGNES算法,分裂的层次聚类算法中的代表是DIANA算法。
- 基于密度的方法
基于密度的聚类方法主要策略就是把簇看做数据空间中被稀疏区域分开的稠密区域,可以发现非球状的簇,代表性的方法是DBSCAN算法。
- 基于网格的方法
基于网格的聚类方法采用空间驱动的方法,把嵌入空间划分为独立于输入对象分布的单元。使用一种多分辨率的网格数据结构,将对象空间量化成有限数目的单元,这些单元形成了网格结构,所有的聚类操作都在该结构上进行,典型的算法是STING算法。















 1481
1481

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









