







 本文深入探讨Greenplum如何从PostgreSQL发展为分布式MPP数据库,包括集群化概述、分布式数据存储和查询计划并行化。Greenplum基于PostgreSQL,通过数据分布、查询优化和执行并行化提升性能,支持多种分布式存储策略,如哈希分布、随机分布和复制表。同时,Greenplum实现查询计划并行化,利用Motion算子处理数据在不同节点间的传输,以充分发挥集群优势。
本文深入探讨Greenplum如何从PostgreSQL发展为分布式MPP数据库,包括集群化概述、分布式数据存储和查询计划并行化。Greenplum基于PostgreSQL,通过数据分布、查询优化和执行并行化提升性能,支持多种分布式存储策略,如哈希分布、随机分布和复制表。同时,Greenplum实现查询计划并行化,利用Motion算子处理数据在不同节点间的传输,以充分发挥集群优势。
了解更多Greenplum技术干货,欢迎访问Greenplum中文社区网站
Greenplum 是最成熟的开源分布式分析型数据库(2019年8月发布的 Greenplum 6 之OLTP性能大幅提升,成为了一款真正的HTAP数据库,评测数据将于近期发布),Gartner 2019 最新评测显示 Greenplum 在经典数据分析领域位列全球第三,在实时数据分析领域位列并列第四。两个领域中前十名中唯一一款开源数据库产品。这意味着如果选择一款基于开源的产品,前十名中别无选择,唯此一款。Gartner 报告详情。
那么 Greenplum 分布式数据库是如何炼成?众所周知 Greenplum 基于 PostgreSQL。PostgreSQL 是最先进的单节点数据库,其相关内核文档、论文资源很多。而有关如何将单节点 PostgreSQL 改造成分布式数据库的资料相对较少。本文从6个方面介绍将单节点 PostgreSQL 数据库发展成分布式 MPP 数据库所涉及的主要工作。当然这些仅仅是极简概述,做到企业级产品化耗资数亿美元,百人规模的数据库尖端人才团队十几年的研发投入结晶而成。虽然不是必需,然而了解 PostgreSQL 基本内核知识对理解本文中的一些细节有帮助。Bruce Momjian 的PPT是极佳入门资料
(https://momjian.us/main/presentations/internals.html)。
1. Greenplum 集群化概述
PostgreSQL 是世界上最先进的单机开源数据库。Greenplum 基于PostgreSQL,是世界上最先进的开源MPP数据库 (有关Greenplum更多资讯请访问Greenplum中文社区)。从用户角度来看,Greenplum 是一个完备的关系数据库管理系统(RDBMS)。从物理层面,它内含多个 PostgreSQL 实例,这些实例可以单独访问。为了实现多个独立的 PostgreSQL 实例的分工和合作,呈现给用户一个逻辑的数据库,Greenplum 在不同层面对数据存储、计算、通信和管理进行了分布式集群化处理。Greenplum 虽然是一个集群,然而对用户而言,它封装了所有分布式的细节,为用户提供了单个逻辑数据库。这种封装极大的解放了开发人员和运维人员。
把单节点 PostgreSQL 转化成集群涉及多个方面的工作,本文主要介绍数据分布、查询计划并行化、执行并行化、分布式事务、数据洗牌(shuffle)和管理并行化等6个方面。
Greenplum 在 PostgreSQL之上还添加了大量其他功能,例如 Append-Optimized 表、列存表、外部表、多级分区表、细粒度资源管理器、ORCA 查询优化器、备份恢复、高可用、故障检测和故障恢复、集群数据迁移、扩容、MADlib机器学习算法库、容器化执行UDF、PostGIS扩展、GPText套件、监控管理、集成Kubernetes等。
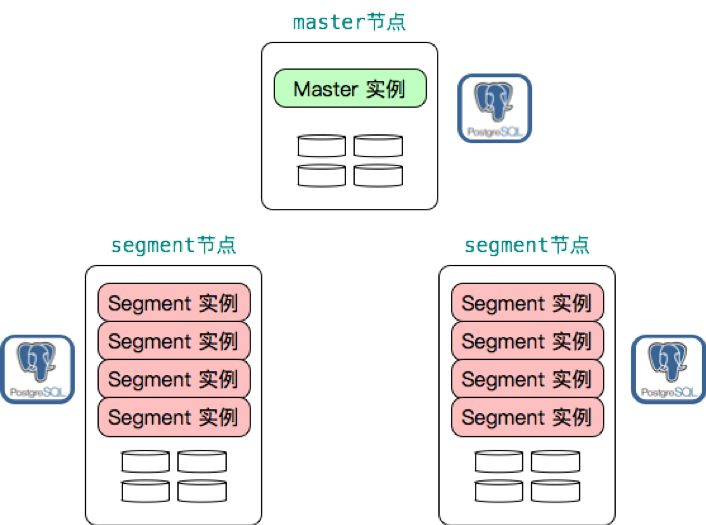
下图展示了一个 Greenplum 集群的俯瞰图,其中一个master节点,两个segment节点,每个segment节点上部署了4个segment实例以提高资源利用率。每个实例,不管是master实例还是segment实例都是一个物理上独立的 PostgreSQL 数据库。
2. 分布式数据存储
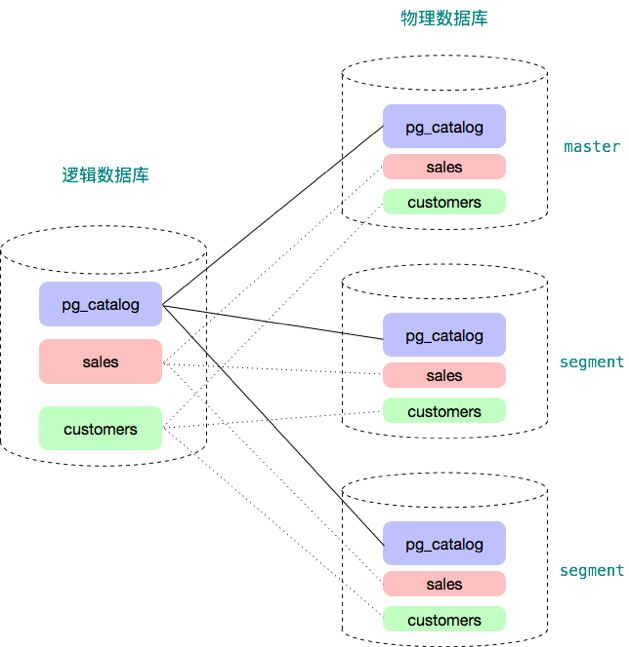
数据存储分布化是分布式数据库要解决的第一个问题。分布式数据存储基本原理相对简单,实现比较容易,很多数据库中间件也可以做到基本的分布式数据存储。Greenplum 在这方面不单单做到了基本的分布式数据存储,还提供了很多更高级灵活的特性,譬如多级分区、多态存储。Greenplum 6进一步增强了这一领域,实现了一致性哈希和复制表,并允许用户根据应用干预数据分布方法。如下图所示,用户看到的是一个逻辑数据库,每个数据库有系统表(例如pgcatalog下面的pgclass, pg_proc 等)和用户表(下例中为sales表和customers表)。在物理层面,它有很多个独立的数据库组成。每个数据库都有它自己的一份系统表和用户表。master 数据库仅仅包含元数据而不保存用户数据。master 上仍然有用户数据表,这些用户数据表都是空表,没有数据。优化器需要使用这些空表进行查询优化和计划生成。segment 数据库上绝大多数系统表(除了少数表,例如统计信息相关表)和master上的系统表内容一样,每个segment都保存用户数据表的一部分。
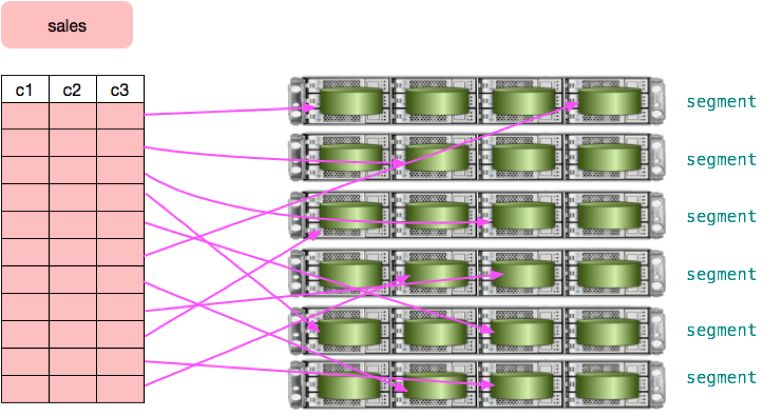
在 Greenplum 中,用户数据按照某种策略分散到不同节点的不同segment实例中。每个实例都有自己独立的数据目录,以磁盘文件的方式保存用户数据。使用标准的 INSERT SQL 语句可以将数据自动按照用户定义的策略分布到合适的节点,然而INSERT性能较低,仅适合插入少量数据。Greenplum 提供了专门的并行化数据加载工具以实现高效数据导入,详情可以参考 gpfdist 和 gpload 的官方文档。此外 Greenplum 还支持并行 COPY,如果数据已经保存在每个 segment 上,这是最快的数据加载方法。下图形象的展示了用户的 sales 表数据被分布到不同的segment实例上。
除了支持数据在不同的节点间水平分布,在单个节点上Greenplum 还支持按照不同的标准分区,且支持多级分区。Greenplum 支持的分区方法有:
- 范围分区:根据某个列的时间范围或者数值范围对数据分区。譬如以下 SQL 将创建一个分区表,该表按天分区,从 2016-01-01 到 2017-01-01 把全部一年的数据按天分成了366个分区:
CREATE TABLE sales (id int, date date, amt decimal(10,2))
DISTRIBUTED BY (id)
PARTITION BY RANGE (date)
( START (date '2016-01-01') INCLUSIVE
END (date '2017-01-01') EXCLUSIVE
EVERY (INTERVAL '1 day') );
- 列表分区:按照某个列的数据值列表,将数据分不到不同的分区。譬如以下 SQL 根据性别创建一个分区表,该表有三个分区:一个分区存储女士数据,一个分区存储男士数据,对于其他值譬如NULL,则存储在单独 other 分区。
CREATE TABLE rank (id int, rank int, year int, gender char(1), count int )
DISTRIBUTED BY (id)
PARTITION BY LIST (gender)
( PARTITION girls VALUES ('F'),
PARTITION boys VALUES ('M'),
DEFAULT PARTITION oth er );
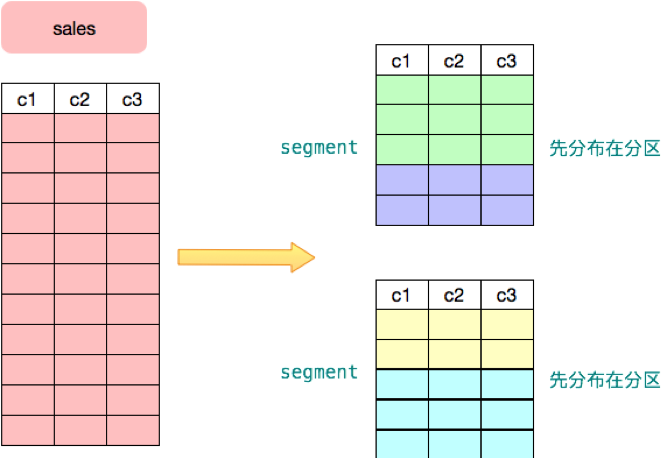
下图展示了用户的 sales 表首先被分布到两个节点,然后每个节点又按照某个标准进行了分区。分区的主要目的是实现分区裁剪以通过降低数据访问量来提高性能。分区裁剪指根据查询条件,优化器自动把不需要访问的分区过滤掉,以降低查询执行时的数据扫描量。PostgreSQL 支持静态条件分区裁剪,Greenplum 通过 ORCA 优化器实现了动态分区裁剪。动态分区裁剪可以提升十几倍至数百倍性能。
Greenplum支持多态存储,即单张用户表,可以根据访问模式的不同使用不同的存储方式存储不同的分区。通常不同年龄的数据具有不同的访问模式,不同的访问模式有不同的优化方案。多态存储以用户透明的方式为不同数据选择最佳存储方式,提供最佳性能。Greenplum 提供以下存储方式:
-
堆表(Heap Table):堆表是 Greenplum 的默认存储方式,也是 PostgreSQL 的存储方式。支持高效的更新和删除操作,访问多列时速度快,通常用于 OLTP 型查询。
-
Append-Optimized 表:为追加而专门优化的表存储模式,通常用于存储数据仓库中的事实表。不适合频繁的更新操作。
-
AOCO (Append-Optimized, Column Oriented) 表:AOCO 表为列表,具有较好的压缩比ÿ
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 684
684

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









