







昨晚用自己写的网络爬虫程序从某网站了下载了三万多张图片,很是爽快,今天跟大家分享几点内容。
一、内容摘要
1:Java也可以实现网络爬虫
3:可以爬某网站的图片,动图以及压缩包
4:可以考虑用多线程加快下载速度
二、准备工作
1:安装Java JDK
3:安装Eclipse或其他编程环境
4:新建一个Java项目,导入Jsoup.jar
三、步骤
1:用Java.net包联上某个网址获得网页源代码
2:用Jsoup包解析和迭代源代码获得自己想要的最终图片网址
3:自己写一个下载的方法根据图片网址来下载图片至本地
四、程序实现及效果
例如针对下面的网页,我们可以所主区域中第一页到最后一页的所有高清图片都下载下来。
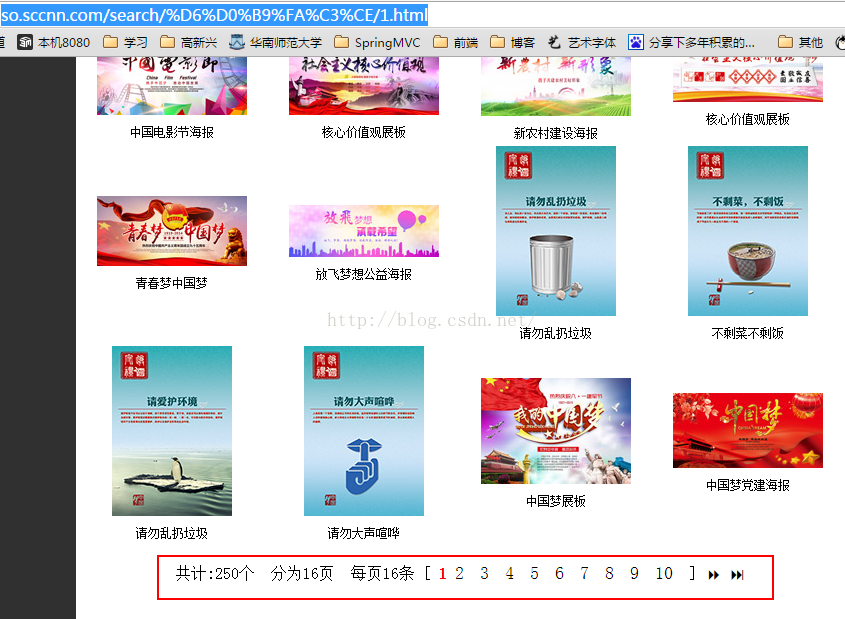
效果图:
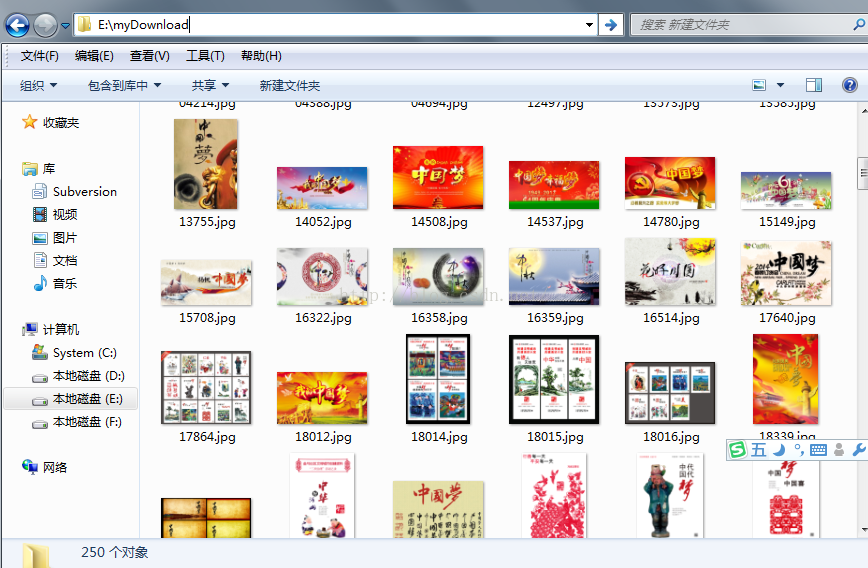
程序实现:
package com.kendy.spider;
import java.io.BufferedReader;
import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
import java.net.URLConnection;
import java.util.ArrayList;
import java.util.List;
import org.jsoup.Connection;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
public class mySpider {
/**
* 联网,获取网页源代码,解析源代码
*/
public static String getHtmlFromUrl(String url,String encoding){
StringBuffer html = new StringBuffer();
InputStreamReader isr=null;
BufferedReader buf=null;
String str = null;
try {
URL urlObj = new URL(url);
URLConnection con = urlObj.openConnection();
isr = new InputStreamReader(con.getInputStream(),encoding);
buf = new BufferedReader(isr);
while((str=buf.readLine()) != null){
html.append(str+"\n");
}
//sop(html.toString());
} catch (Exception e) {
e.printStackTrace();
}finally{
if(isr != null){
try {
buf.close();
isr.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
return html.toString();
}
public static void download(String url,String path){
File file= null;
FileOutputStream fos=null;
String downloadName= url.substring(url.lastIndexOf("/")+1);
HttpURLConnection httpCon = null;
URLConnection con = null;
URL urlObj=null;
InputStream in =null;
byte[] size = new byte[1024];
int num=0;
try {
file = new File(path+downloadName);
// if(!file.exists()){
// file.mkdir();
// }
fos = new FileOutputStream(file);
if(url.startsWith("http")){
//下面这两句话有问题
urlObj = new URL(url);
con = urlObj.openConnection();
httpCon =(HttpURLConnection) con;
in = httpCon.getInputStream();
while((num=in.read(size)) != -1){
for(int i=0;i<num;i++)
fos.write(size[i]);
}
}
} catch (Exception e) {
e.printStackTrace();
} finally{
try {
in.close();
fos.close();
} catch (Exception e) {
e.printStackTrace();
}
}
}
public static void sop(Object obj){
System.out.println(obj);
}
public static void seperate(char c){
for(int x=0;x<100;x++){
System.out.print(c);
}
sop("");
}
/**
* @author kendy
* @version 1.0
*/
public static void main(String[] args) throws Exception{
int i=0;
String picUrl=null;
List<String> list = new ArrayList<>();
for(int x=11;x<=16;x++){
String url = "http://so.sccnn.com/search/%D6%D0%B9%FA%C3%CE/" +x+".html";
String encoding = "utf-8";
String html = getHtmlFromUrl(url,encoding);
Document doc = Jsoup.parse(html);
Elements elements = doc.select("table tbody tr td table tbody tr td table tbody tr td div[valign] a[href]"); //带有href属性的a元素
//Elements pngs = doc.select("img[src$=.png]");//扩展名为.png的图片
for(Element element : elements){
picUrl = element.attr("href");
if(picUrl.startsWith("http") && picUrl.endsWith("html")){
i++;
list.add(picUrl);
sop("网址"+i+": "+picUrl);
Document document = Jsoup.connect(picUrl).get();
Elements els = document.select("div.PhotoDiv div font img");
for(Element el : els){
String pictureUrl = el.attr("src");
System.out.println("------"+pictureUrl);
download(pictureUrl,"E:\\myDownload\\");
}
}
}
seperate('*');
}
sop(list.size());
}
/* public static void main(String[] args) {
int i=0;
String picUrl=null;
String url = "http://so.sccnn.com/";
String encoding = "utf-8";
String html = getHtmlFromUrl(url,encoding);
Document doc = Jsoup.parse(html);
Elements elements = doc.getElementsByTag("img");
for(Element element : elements){
picUrl = element.attr("src");
if(picUrl.startsWith("http") && picUrl.endsWith("jpg")){
i++;
sop("图片"+i+" -------------"+picUrl);
download(picUrl,"E:\\myDownload\\");
}
}
sop("结束。。。");
}*/
}1:自定义的getHtmlFromUrl()方法和Jsoup.pars()方法其实可以用Jsoup.connect(url).get()方法代替
2:访问http和https请求不同,可以对自定义的getHtmlFromUrl和download方法进行优化
3:可以考虑用多线程加快下载速度,即本类去实现Runnable接口,并重写run方法,在构造函数里面把起始页和结束页作为参数初始化本类。















 1180
1180

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









