







4 Dubbo 扩展点加载机制
4.1 加载机制概述
Dubbo 良好的扩展性与两个方面是密不可分的,一是整个框架中针对不同的场景使用了各种设计模式,二就是加载机制。基于 Dubbo SPI 加载机制,让整个框架的接口和具体实现完全解耦,从而奠定了整个框架良好可扩展性的基础。
Dubbo 定义了良好框架结构,它默认提供了很多可以直接使用的扩展点。Dubbo 几乎所有的功能组件都是基于扩展机制(SPI)实现的。
Dubbo SPI 在 Java SPI 的基础上做了一定的改进,形成了一套自己的配置规范和特性。同时,Dubbo SPI 又兼容 Java SPI。服务在启动的时候,Dubbo 就会查找这些扩展点的所有实现。
4.1.1 Java SPI
SPI 的全称是 Service Provider Interface,起初是提供给厂商做插件开发的。Java SPI 使用了策略模式,一个接口多种实现。我们只声明接口,具体的实现并不在程序中直接确定,而是由程序之外的配置掌控,用于具体实现的装配。具体步骤如下:
(1)定义一个接口及对应的方法。
(2)编写该接口的一个实现类。
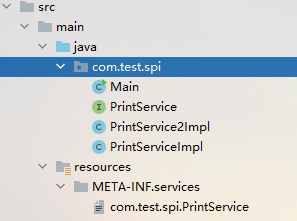
(3)在 META-INF/services/ 目录下,创建一个以接口全路径命名的文件,如 com.test.spi.PrintService。
(4)文件内容为具体实现类的全路径名,如果有多个,则用分行符分隔。
(5)在代码中通过 java.util.ServiceLoader 来加载具体的实现类。
项目结构:
代码清单:
PrintService .java
public interface PrintService {
void printInfo();
}
PrintService 实现类
public class PrintServiceImpl implements PrintService {
public void printInfo() {
System.out.println("hello world");
}
}
public class PrintService2Impl implements PrintService {
public void printInfo() {
System.out.println("hello world2");
}
}
META-INF\services\com.test.spi.PrintService
com.test.spi.PrintServiceImpl
com.test.spi.PrintService2Impl
测试类
public class Main {
public static void main(String[] args) {
// 获取所有的SPI实现,循环调用
ServiceLoader<PrintService> loader = ServiceLoader.load(PrintService.class);
for (PrintService service : loader) {
service.printInfo();
}
}
}
4.1.2 扩展点加载机制的改进
与 Java SPI 相比,Dubbo SPI 做了一定的改进和优化。
(1)JDK 标准的 SPI 会一次性实例化扩展点所有实现,如果有扩展实现则初始化很耗时,如果没用上也加载,则浪费资源。
(2)如果扩展加载失败,则连扩展的名称都蕤取不到了。
(3)增加了对扩展 IoC 和 AOP 的支持,一个扩展可以直接 setter 注入其他扩展。Dubbo SPI 只是加载配置文件中的类,并分成不同的种类缓存在内存中,而不会立即全部初始化,在性能上有更好的表现。
PrintService 接口的 Dubbo SPI 改造代码:
PrintService.java
@SPI("impl")
public interface PrintService {
void printInfo();
}
PrintService 实现类不变。
META-INF/dubbo.internal/com.test.spi.PrintService
impl=com.test.spi.PrintServiceImpl
impl2=com.test.spi.PrintService2Impl
测试类:
public class DubboMain {
public static void main(String[] args) {
// 通过 ExtensionLoader 获取接口
// PrintService.class 的默认实现
PrintService printService = ExtensionLoader
.getExtensionLoader(PrintService.class)
.getDefaultExtension();
printService.printInfo();
}
}
Java SPI 加载失败,可能会因为各种原因导致异常信息被 “吞掉”,导致开发人员问题追踪比较困难。Dubbo SPI 在扩展加载失败的时候会先抛出真实异常并打印日志。扩展点在被动加载的时候,即使有部分扩展加载失败也不会影响其他扩展点和整个框架的使用。
Dubbo SPI 自己实现了 IoC 和 AOP 机制。一个扩展点可以通过 setter 方法直接注入其他扩展的方法,T injectExtension(T instance)方法实现了这个功能。
Dubbo 支持包装扩展类,推荐把通用的抽象逻辑放到包装类中,用于实现扩展点的 AOP 特性。举个例子,到ProtocolFilterWrapper 包装扩展了 DubboProtocol 类,一些通用的判断逻辑全部放在了 ProtocolFilterWrapper 类的 export 方法中,但最终会调用 DubboProtocol#export 方法。这和 Spring 的动态代理思想一样,在被代理类的前后插入自己的逻辑进行增强,最终调用被代理类。
ProtocolFilterWrapper#export 部分代码:
public <T> Exporter<T> export(Invoker<T> invoker) throws RpcException (
// 抽象判断都放在ProtocolFilterWrapper中
if (Constants.REGISTRY_PROTOCOL.equals(invoker.getUrl().getProtocol())) {
// 最终调用了真实的 protocol 实现
return protocol.export(invoker);
}
}
4.1.3 扩展点的配置规范
Dubbo SPI 和 Java SPI 类似,需要在 META-INF/dubbo/下放置对应的 SPI 配置文件,文件名称需要命名为接口的全路径名。配置文件的内容为 key= 扩展点实现类全路径名,如果有多个实现类则使用换行符分隔。其中,key 会作为 Dubbo SPI 注解中的传入参数。另外,Dubbo SPI 还兼容了 Java SPI 的配置路径和内容配置方式。
| 规范 | 说明 |
|---|---|
| SPI 配置文件路径 | META-INF/services/ META-INF/dubbo/ META-INF/dubbo/intemal/ |
| SPI配置文件名称 | 全路径类名 |
| 文件内容格式 | key=value方式,多个用换行符分隔 |
4.1.4 扩展点的分类与缓存
Dubbo SPI 可以分为 Class 缓存、实例缓存。这两种缓存又能根据扩展类的种类分为普通扩展类、包装扩展类(Wrapper类)、自适应扩展类(Adaptive类)等。
1)Class 缓存:Dubbo SPI 获取扩展类时,会先从缓存中读取。如果缓存中不存在,则加载配置文件,根据配置把 Class 缓存到内存中,并不会直接全部初始化。
2)实例缓存:基于性能考虑,Dubbo 框架中不仅缓存 Class,也会缓存 Class 实例化后的对象。每次获取的时候,会先从缓存中读取,如果缓存中读不到,则重新加载并缓存起来。
被缓存的 Class 和对象实例可以根据不同的特性分为不同的类别:
1)普通扩展类。最基础的,配置在 SPI 配置文件中的扩展类实现。
2)包装扩展类。这种 Wrapper 类没有具体的实现,只是做了通用逻辑的抽象,并且需要在构造方法中传入一个具体的扩展接口的实现。属于 Dubbo 的自动包装特性。
3)自适应扩展类。一个扩展接口会有多种实现类,具体使用哪个实现类可以不写死在配置或代码中,在运行时,通过传入URL中的某些参数动态来确定。这属于扩展点的自适应特性。
4)其他缓存,如扩展类加载器缓存、扩展名缓存等
扩展类缓存:
| 集合 | 缓存类型 |
|---|---|
| Holder<Map<String, Class<?»> cachedClasses | 普通扩展类缓存,不包括自适应拓展类和 Wrapper 类 |
| Set<Class<?» cachedWrapperClasses | Wrapper类缓存 |
| Class<?> cachedAdaptiveClass | 自适应扩展类缓存 |
| Holder<Map<String, Class<?»> cachedClasses | 扩展名与扩展对象缓存 |
| Holder<Map<String, Class<?»> cachedClasses | 实例化后的自适应(Adaptive)扩展对象,只能同时存在一个 |
| ConcurrentMap<Class<?>, String> cachedNames | 扩展类与扩展名缓存 |
| ConcurrentMap<Class<?>, ExtensionLoader<?> EXTENSIONLOADERS | 扩展类与对应的扩展类加载器缓存 |
| ConcurrentMap<Class<?>, Object> EXTENSIONJNSTANCES | 扩展类与类初始化后的实例 |
| Map<String, Activate> cachedActivates | 扩展名的缓存 |
4.1.5 扩展点的特性
扩展类一共包含四种特性:自动包装、自动加载、自适应和自动激活。
1)自动包装
自动包装是一种被缓存的扩展类,ExtensionLoader 在加载扩展时,如果发现这个扩展类包含其他扩展点作为构造函数的参数,则这个扩展类就会被认为是 Wrapper 类。
public class ProtocolFilterWrapper implements Protocol {
private final Protocol protocol;
public ProtocolFilterWrapper(Protocol protocol) {
if (protocol == null) {
throw new IllegalArgumentException("protocol == null");
}
this.protocol = protocol;
}
....
}
ProtocolFilterWrapper 虽然继承了 Protocol 接口,但是其构造函数中又注入了一个 Protocol 类型的参数。因此ProtocolFilterWrapper 会被认定为 Wrapper 类。这是一种装饰器模式,把通用的抽象逻辑进行封装或对子类进行增强,让子类可以更加专注具体的实现。
2)自动加载
除了在构造函数中传入其他扩展实例,我们还经常使用 setter 方法设置属性值。如果某个扩展类是另外一个扩展点类的成员属性,并且拥有 setter 方法,那么框架也会自动注入对应的扩展点实例。ExtensionLoader 在执行扩展点初始化的时候,会自动通过 setter方法注入对应的实现类。如果扩展类属性是一个接口,它有多种实现,具体注入哪一个实现类就涉及第三个特性一一自适应。
3)自适应
在 Dubbo SPI 中,使用 @Adaptive 注解,可以动态地通过 URL 中的参数来确定要使用哪个具体的实现类。从而解决自动加载中的实例注入问题。©Adaptive 注解使用示例。
@SPI("netty")
public interface Transporter {
@Adaptive({Constants.SERVER_KEY, Constants.TRANSPORTER_KEY})
Server bind(URL url, ChannelHandler handler) throws RemotingException;
@Adaptive({Constants.CLIENT_KEY, Constants.TRANSPORTER_KEY})
Client connect(URL url, ChannelHandler handler) throws RemotingException;
}
@Adaptive 传入了两个 Constants 中的参数,它们的值分别是 server 和 transporter 。当外部调用 Transporter#bind方法时,会动态从传入的参数 URL 中提取 key 参数 server 的value值,如果能匹配上某个扩展实现类则直接使用对应的实现类;如果未匹配上,则继续通过第二个key参数 transporter 提取 valu值。如果都没匹配上,则抛出异常。即 @Adaptive 中传入了多个参数,则依次进行实现类的匹配,直到最后抛出异常。
4)自动激活
使用 @Activate 注解,可以标记对应的扩展点默认被激活启用。该注解还可以通过传入不同的参数,设置扩展点在不同的条件下被自动激活。主要的使用场景是某个扩展点的多个实现类需要同时启用(比如 Filter 扩展点)。
4.2 扩展点注解
4.2.1 扩展点注解 @SPI
@SPI 注解可以使用在类、接口和枚举类上,Dubbo 框架中都是使用在接口上。它的主要作用就是标记这个接口是一个Dubbo SPI 接口,即是一个扩展点,可以有多个不同的内置或用户定义的实现。运行时需要通过配置找到具体的实现类。
@Documented
@Retention(RetentionPolicy.RUNTIME)
@Target({ElementType.TYPE})
public @interface SPI {
String value() default "";
}
通过 value 属性,可以传入不同的参数来设置这个接口的默认实现类。
4.2.2 扩展点自适应注解 @Adaptive
@Adaptive 注解可以标记在类、接口、枚举类和方法上,在整个 Dubbo框架中,只有 AdaptiveExtensionFactory和AdaptiveCompiler 等使用在类级别上,其余都标注在方法上。
如果标注在接口的方法上,即方法级别注解,则可以通过参数动态获得实现类。方法级别注解在第一次 getExtension 时,会自动生成和编译一个动态的 Adaptive 类,从而达到动态实现类的效果。
下面是自动生成的 Transporter$Adaptive#bind实现代码。
public org.apache.dubbo.remoting.Server
bind(org.apache.dubbo.common.URL arg0, org.apache.dubbo.remoting.ChannelHandler argl)
throws org.apache.dubbo.remoting.RemotingException (
...
org.apache.dubbo.common.URL url = arg0;
// 通过 @Adaptive 注解中的两个 key 去寻找实现类的名称
String extName = url.getParameter("server", url.getParameter("transporter", "netty"));
...
try {
// 根据URL中的参数,尝试获取真正的扩展点实现类
extension = (org.apache.dubbo.remoting.Transporter)ExtensionLoader
.getExtensionLoader(org.apache.dubbo.remoting.Transporter.class)
.getExtension(extName);
} catch(Exception e) {
...
// 如果获取失败,则使用默认的Netty实现
extension = (org.apache.dubbo.remoting.Transporter) ExtensionLoader
.getExtensionLoader(org, apache dubbo.remoting.Transporter.class)
.getExtension("netty");
}
// 最终会调用具体扩展点实现类的bind方法
return extension.bind(arg0, argl);
}
当该注解放在实现类上,则整个实现类会直接作为默认实现,不再自动生成上述代码。在扩展点接口的多个实现里,只能有一个实现上可以加 @Adaptive 注解。如果多个实现类都有该注解则会抛出异常。
@Adaptive 注解的源代码
@Documented
@Retention(RetentionPolicy.RUNTIME)
@Target({ElementType.TYPE, ElementType.METHOD})
public @interface Adaptive {
String[] value() default {};
}
Adaptive 可以传入多个 key 值,在初始化 Adaptive 注解的接口时,会先对传入的 URL 进行 key 值匹配,第一个key没匹配上则匹配第二个,以此类推。直到所有的key匹配完毕,如果还没有匹配到, 则会使用驼峰规则匹配,如果也没匹配到,则会抛出 IllegalStateException 异常。
@Adaptive 放在实现类上,主要是为了直接固定对应的实现而不需要动态生成代码实现,就像策略模式直接确定实现类。实现方式:ExtensionLoader 中会缓存两个与 @Adaptive 有关的对象,一个缓存在 cachedAdaptiveClass 中, 即 Adaptive 具体实现类的 Class 类型。另外一个缓存在 cachedAdaptivelnstance 中,即 Class 的具体实例化对象。在扩展点初始化时,如果发现实现类有 @Adaptive 注解,则直接赋值给 cachedAdaptiveClass,后续实例化类的时候,就不会再动态生成代码,直接实例化 cachedAdaptiveClass,并把实例缓存到 cachedAdaptivelnstance 中。如果注解在接口方法上, 则会根据参数,动态获得扩展点的实现,会生成 Adaptive 类,再缓存到 cachedAdaptivelnstance 中。
4.2.3 扩展点自动激活 @Activate
@Activate 可以标记在类、接口、枚举类和方法上。主要使用在有多个扩展点实现、需要根据不同条件被激活的场景中,如Filter 需要多个同时激活,因为每个 Filter 实现的是不同的功能。Activate 参数如下。
| 参数名 | 作用 |
|---|---|
| String[] group() | URL 中的分组如果匹配则激活,则可以设置多个 |
| String[] value() | 查找 URL 中如果含有该 key 值,则会激活 |
| String[] before() | 填写扩展点列表,表示哪些扩展点要在本扩展点之前 |
| String[] after() | 同上,表示哪些需要在本扩展点之后 |
| int order() | 整型,直接的排序信息 |
4.3 ExtensionLoader 工作原理
ExtensionLoader 是整个扩展机制的主要逻辑类,在这个类里面卖现了配置的加载、扩展类缓存、自适应对象生成等所有工作。
4.3.1 工作流程
ExtensionLoader 的逻辑入口可以分为 getExtension、getAdaptiveExtension、getActivateExtension三个,分别是获取普通扩展类、获取自适应扩展类、获取自动激活的扩展类。总体逻辑都是从调用这三个方法开始的,每个方法可能会有不同的重载的方法,根据不同的传入参数进行调整。

三个入口中,getActivateExtension 对 getExtension 的依赖比较 getAdaptiveExtension 则相对独立。
getActivateExtension 方法只是根据不同的条件同时激活多个普通扩展类。因此,该方法中只会做一些通用的判断逻辑,如接口是否包含 @Activate 注解、匹配条件是否符合等。最终还是通过调用 getExtension 方法获得具体扩展点实现类。
getExtension(String name) 是整个扩展加载器中最核心的方法,实现了一个完整的普通扩展类加载过程。加载过程中的每一步,都会先检查缓存中是否己经存在所需的数据,如果存在则直接从缓存中读取,没有则重新加载。这个方法每次只会根据名称返回一个扩展点实现类。 初始化的过程:
(1)框架读取 SPI 对应路径下的配置文件,并根据配置加载所有扩展类并缓存(不初始化)。
(2)根据传入的名称初始化对应的扩展类。
(3)尝试查找符合条件的包装类:包含扩展点的 setter 方法,例如 setProtocol(Protocolprotocol)方法会自动注入 protocol 扩展点实现;包含与扩展点类型相同的构造函数,为其注入扩展类实例,例如本次初始化了一个 Class A,初始化完成后,会寻找构造参数中需要 Class A 的包装类(Wrapper),然后注入 Class A 实例,并初始化这个包装类。
(4)返回对应的扩展类实例。
getAdaptiveExtension 也相对独立,只有加载配置信息部分与 getExtension 共用了同一个方法。和获取普通扩展类一样,框架会先检查缓存中是否有已经初始化化好的 Adaptive 实例, 没有则调用 createAdaptiveExtension()重新初始化。初始化过程:
(1)和 getExtension 一样先加载配置文件。
(2)生成自适应类的代码字符串。
(3)获取类加载器和编译器,并用编译器编译刚才生成的代码字符串。Dubbo 一共有三种类型的编译器实现。
(4)返回对应的自适应类实例。
4.3.2 getExtension 的的实现原理
1)当调用 getExtension(String name) 方法时,会先检查缓存中是否有现成的数据,没有则调用 createExtension 开始创建。特殊的地方在于,如果 getExtension 传入的 name 是 true,则加载并返回默认扩展类。
public T getExtension(String name) {
if (name == null || name.length() == 0)
throw new IllegalArgumentException("Extension name == null");
if ("true".equals(name)) {
return getDefaultExtension();
}
// 实例缓存中是否有对应实例
Holder<Object> holder = cachedInstances.get(name);
if (holder == null) {
cachedInstances.putIfAbsent(name, new Holder<Object>());
holder = cachedInstances.get(name);
}
Object instance = holder.get();
if (instance == null) {
synchronized (holder) {
instance = holder.get();
if (instance == null) {
// 创建实例
instance = createExtension(name);
holder.set(instance);
}
}
}
return (T) instance;
}
2)在调用 createExtension 开始创建的过程中,也会先检查缓存中是否有配置信息,如果不存在扩展类,则会从 META-INF/services/,META-INF/dubbo/,META-INF/dubbo/internal/ 这几个路径中读取所有的配置文件,通过I/O读取字符流,然后通过解析字符串,得到配置文件中对应的扩展点实现类的全称。扩展点配置信息加载过程的代码:
private T createExtension(String name) {
// 获取类信息
Class<?> clazz = getExtensionClasses().get(name);
...
}
private Map<String, Class<?>> getExtensionClasses() {
// 先尝试从缓存中获取 classes
Map<String, Class<?>> classes = cachedClasses.get();
if (classes == null) {
synchronized (cachedClasses) {
classes = cachedClasses.get();
if (classes == null) {
// 从配置文件中加载 classes
classes = loadExtensionClasses();
cachedClasses.set(classes);
}
}
}
return classes;
}
private Map<String, Class<?>> loadExtensionClasses() {
// 要获取的类是否有 SPI 注解
final SPI defaultAnnotation = type.getAnnotation(SPI.class);
if (defaultAnnotation != null) {
// 如果有,就使用注解中的名称作为默认的实现名存入缓存
String value = defaultAnnotation.value();
if ((value = value.trim()).length() > 0) {
String[] names = NAME_SEPARATOR.split(value);
if (names.length > 1) {
throw new IllegalStateException("more than 1 default extension name on extension " + type.getName()
+ ": " + Arrays.toString(names));
}
if (names.length == 1) cachedDefaultName = names[0];
}
}
Map<String, Class<?>> extensionClasses = new HashMap<String, Class<?>>();
// 加载 META-INF/dubbo/internal/ 的配置信息
loadDirectory(extensionClasses, DUBBO_INTERNAL_DIRECTORY);
// 加载 META-INF/dubbo/ 的配置信息
loadDirectory(extensionClasses, DUBBO_DIRECTORY);
// 加载 META-INF/services/ 的配置信息
loadDirectory(extensionClasses, SERVICES_DIRECTORY);
return extensionClasses;
}
private void loadDirectory(Map<String, Class<?>> extensionClasses, String dir) {
String fileName = dir + type.getName();
try {
Enumeration<java.net.URL> urls;
ClassLoader classLoader = findClassLoader();
// 记载配置文件
if (classLoader != null) {
urls = classLoader.getResources(fileName);
} else {
urls = ClassLoader.getSystemResources(fileName);
}
if (urls != null) {
// 循环遍历 urls
while (urls.hasMoreElements()) {
java.net.URL resourceURL = urls.nextElement();
// 解析字符串,得到扩展实现类,并加入缓存
loadResource(extensionClasses, classLoader, resourceURL);
}
}
} catch (Throwable t) {
logger.error("Exception when load extension class(interface: " +
type + ", description file: " + fileName + ").", t);
}
}
3)加载完扩展点配置后,再通过反射获得所有扩展实现类并缓存起来。此处仅仅是把 Class 加载到 JVM 中,但并没有做Class 初始化。在加载 Class 文件时,会根据 Class 上的注解来判断扩展点类型,再根据类型分类做缓存。扩展点的缓存分类:
// ExtensionLoader#loadResource -> loadClass
private void loadClass(Map<String, Class<?>> extensionClasses, java.net.URL resourceURL, Class<?> clazz, String name) throws NoSuchMethodException {
// 判断是否是实现类
if (!type.isAssignableFrom(clazz)) {
throw new IllegalStateException("Error when load extension class(interface: " +
type + ", class line: " + clazz.getName() + "), class "
+ clazz.getName() + "is not subtype of interface.");
}
// 是否是自适应类
if (clazz.isAnnotationPresent(Adaptive.class)) {
// 如果是就缓存
if (cachedAdaptiveClass == null) {
cachedAdaptiveClass = clazz;
} else if (!cachedAdaptiveClass.equals(clazz)) {
// 不能有多个自适应类
throw new IllegalStateException("More than 1 adaptive class found: "
+ cachedAdaptiveClass.getClass().getName()
+ ", " + clazz.getClass().getName());
}
} else if (isWrapperClass(clazz)) {
// 如果是包装阔扩展类(装饰类),加入包装扩展类的 set 集合
Set<Class<?>> wrappers = cachedWrapperClasses;
if (wrappers == null) {
cachedWrapperClasses = new ConcurrentHashSet<Class<?>>();
wrappers = cachedWrapperClasses;
}
wrappers.add(clazz);
} else {
clazz.getConstructor();
if (name == null || name.length() == 0) {
name = findAnnotationName(clazz);
if (name.length() == 0) {
throw new IllegalStateException("No such extension name for the class " + clazz.getName() + " in the config " + resourceURL);
}
}
String[] names = NAME_SEPARATOR.split(name);
if (names != null && names.length > 0) {
// 如果有自动激活注解(Activate),就缓存到自动激活的缓存中
Activate activate = clazz.getAnnotation(Activate.class);
if (activate != null) {
cachedActivates.put(names[0], activate);
}
// 不是自适应类,也不是包装类型,就是普通的扩展类,也需要缓存
for (String n : names) {
if (!cachedNames.containsKey(clazz)) {
cachedNames.put(clazz, n);
}
Class<?> c = extensionClasses.get(n);
if (c == null) {
extensionClasses.put(n, clazz);
} else if (c != clazz) {
throw new IllegalStateException("Duplicate extension " + type.getName() + " name " + n + " on " + c.getName() + " and " + clazz.getName());
}
}
}
}
}
4)最后,根据传入的 name 找到对应的类并通过 clazz.newInstance()方法进行初始化,并为其注入依赖的其他扩展类(自动加载特性)。当扩展类初始化后,会检查一次包装扩展类 Set<Class<?>wrapperclasses,查找包含与扩展点类型相同的构造函数,为其注入刚初始化的扩展类。
private T createExtension(String name) {
// 获取类信息
Class<?> clazz = getExtensionClasses().get(name);
if (clazz == null) {
throw findException(name);
}
try {
T instance = (T) EXTENSION_INSTANCES.get(clazz);
if (instance == null) {
// 实例化 clazz.newInstance()
EXTENSION_INSTANCES.putIfAbsent(clazz, clazz.newInstance());
instance = (T) EXTENSION_INSTANCES.get(clazz);
}
// 向扩展类中注入其依赖的属性,如扩展类 A 依赖了扩展类 B
injectExtension(instance);
Set<Class<?>> wrapperClasses = cachedWrapperClasses;
// 遍历扩展点包装类,用于初始化包装类实例
if (wrapperClasses != null && !wrapperClasses.isEmpty()) {
for (Class<?> wrapperClass : wrapperClasses) {
// 找到构造方法参数为 type(扩展类的类型) 的包装类,为其注入扩展了类实例
instance = injectExtension((T) wrapperClass.getConstructor(type).newInstance(instance));
}
}
return instance;
} catch (Throwable t) {
throw new IllegalStateException("Extension instance(name: " + name + ", class: " +
type + ") could not be instantiated: " + t.getMessage(), t);
}
}
在 injectExtension 方法中可以为类注入依赖属性,它使用了 ExtensionFactory#getExtension(Class<T> type, String name) 来获取对应的 bean 实例。injectExtension 方法总体实现了类似 Spring 的 IoC 机制。首先通过反射获取类的所有方法,然后遍历以字符串set开头的方法,得到 set 方法的参数类型,再通过 ExtensionFactory 寻找参数类型相同的扩展类实例,如果找到,就设值进去。
private T injectExtension(T instance) {
try {
if (objectFactory != null) {
for (Method method : instance.getClass().getMethods()) {
// 找到所有 setter 方法,进行属性注入
if (method.getName().startsWith("set")
&& method.getParameterTypes().length == 1
&& Modifier.isPublic(method.getModifiers())) {
/**
* Check {@link DisableInject} to see if we need auto injection for this property
*/
// 不需要注入
if (method.getAnnotation(DisableInject.class) != null) {
continue;
}
Class<?> pt = method.getParameterTypes()[0];
try {
// 通过字符串截取,获得小写开头的类名。如 setTestService,截取 testService
String property = method.getName().length() > 3 ? method.getName().substring(3, 4).toLowerCase() + method.getName().substring(4) : "";
// 通过 ExtensionFactory 获取要注入的实例
Object object = objectFactory.getExtension(pt, property);
if (object != null) {
// 执行 setter 方法
method.invoke(instance, object);
}
} catch (Exception e) {
logger.error("fail to inject via method " + method.getName()
+ " of interface " + type.getName() + ": " + e.getMessage(), e);
}
}
}
}
} catch (Exception e) {
logger.error(e.getMessage(), e);
}
return instance;
}
4.3.3 getAdaptiveExtension 的实现原理
在 getAdaptiveExtension() 方法中,会为扩展点接口自动生成实现类字符串,实现类主要包含以下逻辑:为接口中每个有@Adaptive 注解的方法生成默认实现(没有注解的方法则生成空实现),每个默认实现都会从 URL 中提取 Adaptive 参数值,并以此为依据动态加载扩展点。然后,框架会使用不同的编译器,把实现类字符串编译为自适应类并返回。
生成代码的逻辑主要分为7步:
1)生成 package、import、类名称等头部信息。此处只会引入一个类 ExtensionLoader。 为了不写其他类的 import 方法,其他方法调用时全部使用全路径。类名称会变为接口名称$Adaptive的格式。例如:Transporter 接口会生成 Transporter$Adpative。
2)遍历接口所有方法,获取方法的返回类型、参数类型、异常类型等。为第(3)步判断是否为空值做准备。
3)生成参数为空校验代码,如参数是否为空的校验。如果有远程调用,还会添加 Invocation 参数为空的校验。
4)生成默认实现类名称。如果 @Adaptive 注解中没有设定默认值,则根据类名称生成, 如 YyylnvokerWrapper 会被转换为yyy.invoker.wrapper。生成的规则是不断找大写字母,并把它 “.” 们用连接起来。得到默认实现类名称后,还需要知道这个实现是哪个扩展点的。
5)生成获取扩展点名称的代码。根据 @Adaptive 注解中配置的 key 值生成不同的获取代码,例如:如果是@Adaptive(protocol),则会生成 url.getProtocol() 。
6)生成获取具体扩展实现类代码。最终还是通过 getExtension(extName) 方法获取自适应扩展类的真正实现。如果根据 URL中配置的 key 没有找到对应的实现类,则会使用第(4)步中生成的默认实现类名称去找。
7)生成调用结果代码。
使用 Dubbo 源码中自带的一个单元测试来演示代码生成过程。
// SPI配置文件中的配置
# Comment 1
impl1=com.alibaba.dubbo.common.extensionloader.ext1.impl.SimpleExtImpl1#Hello World
impl2=com.alibaba.dubbo.common.extensionloader.ext1.impl.SimpleExtImpl2 # Comment 2
impl3=com.alibaba.dubbo.common.extensionloader.ext1.impl.SimpleExtImpl3 # with head space
// 自适应接口,echo 方法上有 @Adaptive 注解
@SPI("impl1")
public interface SimpleExt {
// @Adaptive example, do not specify a explicit key.
@Adaptive
String echo(URL url, String s);
}
测试方法
// 在测试方法中调用这个自适应类
public void test_getAdaptiveExtension_UrlNpe() throws Exception {
// 生成自适应类代码
SimpleExt ext = ExtensionLoader.getExtensionLoader(SimpleExt.class).getAdaptiveExtension();
try {
ext.echo(null, "haha");
fail();
} catch (IllegalArgumentException e) {
assertEquals("url == null", e.getMessage());
}
}
会生成以下自适应代码
package org.apache.dubbo.common.extensionloader.adaptive;
import org.apache.dubbo.common.extension.ExtensionLoader;
public class SimpleExt$Adaptive
implements org.apache dubbo.common.extensionloader.extl.SimpleExt (
public String echo(org.apache.dubbo.common.URL argO^ java.lang.String argl) {
if (arg0 == null) throw new IllegalArgumentException("url == null");
org.apache.dubbo.common.URL url = arg0;
String extName = url.getParameter("simple.ext", "impl1");
if (extName == null) throw new IllegalStateException(...);
org.apache.dubbo.common.extensionloader.extl.SimpleExt extension =
(org.apache.dubbo.common, extensionloader.extl.SimpleExt)ExtensionLoader
.getExtensionLoader(org.apache.dubbo.common.extensionloader.extl.SimpleExt.class)
// 实现类变为配置文件中的 SimpleExtlmpl1
.getExtension(extName);
// 最终调用真实的扩展点方法,返回调用结果
return extension.echo(arg0, arg1);
}
}
生成完代码之后就要对代码进行编译,生成一个新的Class。Dubbo 中的编译器也是一个自适应接口,但 @Adaptive 注解是加在实现类 AdaptiveCompiler上的。这样一来 AdaptiveCompiler 就会作为该自适应类的默认实现,不需要再做代码生成和编译就可以使用了。
如果一个接口上既有 @SPI(“impl”) 注解,方法上又有 @Adaptive(“impl2”) 注解。那么会以哪个key作为默认实现呢?由上面动态生成的 $Adaptive 类可以得知,最终动态生成的实现方法会是 =url.getParameter(“impl2”, “impl”),即优先通过 @Adaptive 注解传入的 key 去查找扩展实现类; 如果没找到,则通过 @SPI 注解中的 key 去查找;如果 @SPI 注解中没有默认值,则把类名转化为 key,再去查找。
4.3.4 getActivateExtension 的实现原理
getActivateExtension(URL url, String key, String group)方法可以获取所有自动激活扩展点。参数分别是 URL,URL中指定的key(多个则用逗号隔开)和URL中指定的组信息(group)。当调用该方法时,主线流程分为4步:
1)检查缓存,如果缓存中没有,则初始化所有扩展类实现的集合。
2)遍历整个 @Activate 注解集合,根据传入 URL 匹配条件(匹配group,name等),得到所有符合激活条件的扩展类实现。然后根据 @Activate 中配置的 before、after、order 等参数进行排序。
3)遍历所有用户自定义扩展类名称,根据用户 URL 配置的顺序,调整扩展点激活顺序(遵循用户在 URL 中配置的顺序,例如 URL 为 test://localhost/test?ext=order1,default,则扩展点 ext 的激活顺序会遵循先 order1 再 default,其中 default 代表所有有 @Activate 注解的扩展点)。
4)返回所有自动激活类集合。
获取 Activate 扩展类实现,也是通过 getExtension 得到的。因此,可以认为 getExtension 是其他两种 Extension 的基石。
此处有一点需要注意,如果 URL 的参数中传入了 -default,则所有的默认 @Activate 都不会被激活,只有 URL 参数中指定的扩展点会被激活。如果传入了 “-” 符号开头的扩展点名, 则该扩展点也不会被自动激活。例如:-xxxx,表示名字为 xxxx 的扩展点不会被激活。
4.3.5 ExtensionFactory 的实现原理
我们知道 RegistryFactory 工厂类通过 @Adaptive({“protocol”}) 注解动态查找注册中心实现,根据 URL 中的 protocol 参数动态选择对应的注册中心工厂,并初始化具体的注册中心客户端。而实现这个特性的 ExtensionLoader 类,本身又是通过工厂方法 ExtensionFactory 创建的,并且这个工厂接口上也有 SPI 注解,还有多个实现。
ExtensionFactory工厂接口
@SPI
public interface ExtensionFactory {
<T> T getExtension(Class<T> type, String name);
}
既然工厂接口有多个实现,那么是怎么确定使用哪个工厂实现的呢? AdaptiveExtensionFactory 这个实现类工厂上有 @Adaptive 注解。因此,AdaptiveExtensionFactory 会作为一开始的默认实现。工厂类之间的关系如图。

可以看到,除了 AdaptiveExtensionFactory,还有 SpiExtensionFactory 和 SpringExtensionFactory 两个工厂。也就是说,我们除了可以从 Dubbo SPI 管理的容器中获取扩展点实例,还可以从 Spring 容器中获取。
Dubbo 和 Spring 容器之间是如何打通的呢?SpringExtensionFactory 工厂提供了保存 Spring 上下文的静态方法,可以把 Spring 上下文保存到 Set 集合中。 当调用 getExtension 获取扩展类时,会遍历 Set 集合中所有的 Spring 上下文,先根据名字依次从每个 Spring 容器中进行匹配,如果根据名字没匹配到,则根据类型去匹配,如果还没匹配到则返回 null,如代码所示:
public class SpringExtensionFactory implements ExtensionFactory {
...
/**
* 用能自动去重的 Set 保存 Spring 上下文
*/
private static final Set<ApplicationContext> contexts = new ConcurrentHashSet<ApplicationContext>();
...
/**
* Spring的上下文引用会在这里被保存
*/
public static void addApplicationContext(ApplicationContext context) {
contexts.add(context);
BeanFactoryUtils.addApplicationListener(context, shutdownHookListener);
}
...
@Override
@SuppressWarnings("unchecked")
public <T> T getExtension(Class<T> type, String name) {
// 遍历所有 Spring 上下文,先根据名字从 Spring 容器中查找
for (ApplicationContext context : contexts) {
if (context.containsBean(name)) {
Object bean = context.getBean(name);
if (type.isInstance(bean)) {
return (T) bean;
}
}
}
logger.warn("No spring extension (bean) named:" + name + ", try to find an extension (bean) of type " + type.getName());
if (Object.class == type) {
return null;
}
// 如果根据名字没找到,则直接通过类型查找
for (ApplicationContext context : contexts) {
try {
return context.getBean(type);
} catch (NoUniqueBeanDefinitionException multiBeanExe) {
logger.warn("Find more than 1 spring extensions (beans) of type " + type.getName() + ", will stop auto injection. Please make sure you have specified the concrete parameter type and there's only one extension of that type.");
} catch (NoSuchBeanDefinitionException noBeanExe) {
if (logger.isDebugEnabled()) {
logger.debug("Error when get spring extension(bean) for type:" + type.getName(), noBeanExe);
}
}
}
logger.warn("No spring extension (bean) named:" + name + ", type:" + type.getName() + " found, stop get bean.");
// 找不到返回 null
return null;
}
}
那么Spring的上下文又是在什么时候被保存起来的呢?在 ReferenceBean 和 ServiceBean 中会调用静态方法保存 Spring 上下文,即一个服务被发布或被引用的时候,对应的 Spring 上下文会被保存下来
SpiExtensionFactory 主要就是获取扩展点接口对应的 Adaptive 实现类。例如:某个扩展点实现类 ClassA 上有 @Adaptive 解,则调用 SpiExtensionFactory#getExtension会直接返回 ClassA 实例。
public class SpiExtensionFactory implements ExtensionFactory {
@Override
public <T> T getExtension(Class<T> type, String name) {
// 根据类型获取所有的扩展点加载器
if (type.isInterface() && type.isAnnotationPresent(SPI.class)) {
ExtensionLoader<T> loader = ExtensionLoader.getExtensionLoader(type);
// 果缓存的扩展点类不为空,直接返回 Adaptive 实例
if (!loader.getSupportedExtensions().isEmpty()) {
return loader.getAdaptiveExtension();
}
}
return null;
}
}
AdaptiveExtensionFactory 工厂上有 @Adaptive注解。这个默认工厂在构造方法中就获取了所有扩展类工厂并缓存起来,包括 SpiExtensionFactory 和 SpringExtensionFactory。AdaptiveExtensionFactory 构造方法如代码。
@Adaptive
public class AdaptiveExtensionFactory implements ExtensionFactory {
/**
* 其它工厂的缓存
*/
private final List<ExtensionFactory> factories;
public AdaptiveExtensionFactory() {
// 工厂列表也是通过SPI实现的,因此可以在这里获取所有工厂的扩展点加载器
ExtensionLoader<ExtensionFactory> loader = ExtensionLoader.getExtensionLoader(ExtensionFactory.class);
List<ExtensionFactory> list = new ArrayList<ExtensionFactory>();
// 遍历所有的工厂名称,获取对应的工厂,并保存到factories列表中
for (String name : loader.getSupportedExtensions()) {
list.add(loader.getExtension(name));
}
factories = Collections.unmodifiableList(list);
}
...
}
被 AdaptiveExtensionFactory 缓存的工厂会通过 TreeSet 进行排序,SPI 排在前面,Spring 排在后面。当调用 getExtension 方法时,会遍历所有的工厂,先从 SPI 容器中获取扩展类;如果没找到,则再从 Spring 容器中查找。我们可以理解为, AdaptiveExtensionFactory 持有了所有的具体工厂实现,它的 getExtension 方法中只是遍历了它持有的所有工厂,最终还是调用 SPI 或 Spring 工厂实现的 getExtension 方法。getExtension 方法如代码。
@Override
public <T> T getExtension(Class<T> type, String name) {
// 遍历所有工厂进行查找,顺序是 SPI -> Spring
for (ExtensionFactory factory : factories) {
T extension = factory.getExtension(type, name);
if (extension != null) {
return extension;
}
}
return null;
}
4.4 扩展点动态编译的实现
Dubbo SPI 的自适应特性让整个框架非常灵活,而动态编译又是自适应特性的基础,因为动态生成的自适应类只是字符串,需要通过编译才能得到真正的 Class。虽然我们可以使用反射来动态代理一个类,但是在性能上和直接编译好的 Class 会有一定的差距。Dubbo SPI 通过代码的动态生成,并配合动态编译器,灵活地在原始类基础上创建新的自适应类。
4.4.1 总体结构
Dubbo 中有三种代码编译器,分别是 JDK 编译器、Javassist 编译器和 AdaptiveCompiler 编译器。这几种编译器都实现了 Compiler 接口,编译器类之间的关系如图。

Compiler 接口上含有一个 SPI 注解,注解的默认值是 @SPI(“javassist”)。很明显,Javassist 编译器将作为默认编译器。如果用户想改变默认编译器,则可以通过<dubbo:application compiler="jdk" />标签进行配置。
@SPI("javassist")
public interface Compiler {
Class<?> compile(String code, ClassLoader classLoader);
}
AdaptiveCompiler上面有 @Adaptive 注解,说明 AdaptiveCompiler 会固定为默认实现,这个 Compiler 的主要作用和 AdaptiveExtensionFactory 相似,就是为了管理其他 Compiler。
@Adaptive
public class AdaptiveCompiler implements Compiler {
private static volatile String DEFAULT_COMPILER;
/**
* 设置默认的编译器名称
*/
public static void setDefaultCompiler(String compiler) {
DEFAULT_COMPILER = compiler;
}
@Override
public Class<?> compile(String code, ClassLoader classLoader) {
Compiler compiler;
// 通过 ExtensionLoader 获取对应的编译器扩展类实现,并调用真正的 compile 做编译
ExtensionLoader<Compiler> loader = ExtensionLoader.getExtensionLoader(Compiler.class);
String name = DEFAULT_COMPILER; // copy reference
if (name != null && name.length() > 0) {
compiler = loader.getExtension(name);
} else {
compiler = loader.getDefaultExtension();
}
return compiler.compile(code, classLoader);
}
}
AdaptiveCompiler#setDefaultCompiler 方法会在 ApplicationConfig 中被调用,也就是 Dubbo 在启动时,会解析配置中的<dubbo:application compiler="jdk" />标签,获取设置的值,初始化对应的编译器。如果没有标签设置,则使用@SPI(“javassist”) 中的设置,即 JavassistCompileror。
AbstpactCompiler 是一个抽象类,无法实例化,但在里面封装了通用的模板逻辑。还定义了一个抽象方法 doCompile,留给子类来实现具体的编译逻辑。JavassistCompiler和 JdkCompiler 都实现了这个抽象方法。
Abstractcompiler 的主要抽象逻辑如下:
1)通过正则匹配出包路径、类名,再根据包路径、类名拼接出全路径类名。
2)尝试通过 Class.forName 加载该类并返回,防止重复编译。如果类加载器中没有这个类,则进入第3步。
3)调用doCompile方法进行编译。这个抽象方法由子类实现。
// AbstractCompiler.java
@Override
public Class<?> compile(String code, ClassLoader classLoader) {
code = code.trim();
// 通过正则匹配出包路径、类名,
Matcher matcher = PACKAGE_PATTERN.matcher(code);
String pkg;
if (matcher.find()) {
pkg = matcher.group(1);
} else {
pkg = "";
}
matcher = CLASS_PATTERN.matcher(code);
String cls;
if (matcher.find()) {
cls = matcher.group(1);
} else {
throw new IllegalArgumentException("No such class name in " + code);
}
// 再根据包路径、类名拼接出全路径类名。
String className = pkg != null && pkg.length() > 0 ? pkg + "." + cls : cls;
try {
// 尝试通过 Class.forName 加载该类并返回,防止重复编译。
return Class.forName(className, true, ClassHelper.getCallerClassLoader(getClass()));
} catch (ClassNotFoundException e) {
if (!code.endsWith("}")) {
throw new IllegalStateException("The java code not endsWith \"}\", code: \n" + code + "\n");
}
try {
// 子类实现
return doCompile(className, code);
} catch (RuntimeException t) {
throw t;
} catch (Throwable t) {
throw new IllegalStateException("Failed to compile class, cause: " + t.getMessage() + ", class: " + className + ", code: \n" + code + "\n, stack: " + ClassUtils.toString(t));
}
}
}
4.4.2 Javassist动态代码编译
Java 中动态生成 Class 的方式有很多,可以直接基于字节码的方式生成,常见的工具库有 CGLIB、ASM、Javassist 等。而自适应扩展点使用了生成字符串代码再编译为 Class 的方式。
在讲解Dubbo中Javassist动态代码编译之前,先看下 Javassist 使用示例:
public void test() throws Exception {
// 初始化 Javassist 的类池
ClassPool classPool = ClassPool.getDefault();
// 创建一个类
CtClass ctClass = classPool.makeClass("HelloWorld");
// 添加一个方法
CtMethod ctMethod = CtNewMethod.make("public void hello() {\n" +
" System.out.println(\"hello world\");\n" +
" }", ctClass);
ctClass.addMethod(ctMethod);
// 生成类
Class aClass = ctClass.toClass();
// 通过反射实例化
Object instance = aClass.newInstance();
Method method = aClass.getMethod("hello");
//执行方法
method.invoke(instance);
}
看完 Javassis t使用示例,其实 Dubbo 中 JavassistCompiler 的实现原理也很清晰了。由于我们之前已经生成了代码字符串,因此在 JavassistCompiler 中,就是不断通过正则表达式匹配不同部位的代码,然后调用 Javassist 库中的 API 生成不同部位的代码,最后得到一个完整的 Class 对象。具体步骤如下:
1)初始化 Javassist,设置默认参数,如设置当前的 classpath。
2)通过正则匹配出所有 import 的包,并使用 Javassist 添加 import。
3)通过正则匹配出所有 extends 的包,创建 Class 对象,并使用 Javassist 添加 extends。
4)通过正则匹配出所有 implements 包,并使用 Javassist 添加 implements。
5)通过正则匹配出类里面所有内容,即得到{}中的内容,再通过正则匹配出所有方法,并使用 Javassist 添加类方法。
6)生成Class对象。
JavassistCompiler 继承了抽象类 Abstractcompiler,需要实现父类定义的一个抽象方法 doCompile。以上步骤就是整个doCompile 方法在 JavassistCompiler 中的实现。
4.4.3 JDK动态代码编译
JdkCompiler 是 Dubbo 编译器的另一种实现,使用了 JDK 自带的编译器,原生 JDK 编译器包位于 javax.tools 下。主要使用了三个东西:JavaFileObject 接口、ForwardingJavaFileManager 接口、JavaCompiler.CompilationTask 方法。整个动态编译过程可以简单地总结为:首先初始化一个 JavaFileObject 对象,并把代码字符串作为参数传入构造方法,然后调用 JavaCompiler.CompilationTask 方法编译出具体的类。JavaFileManager 负责管理类文件的输入/输出位置。以下是每个接口/方法的简要介绍:
1)JavaFileObject 接口。字符串代码会被包装成一个文件对象,并提供获取二进制流的接口。Dubbo 框架中的JavaFileObjectlmpl 类可以看作该接口一种扩展实现,构造方法中需要传入生成好的字符串代码,此文件对象的输入和输出都是 ByteArray 流。
2)DavaFileManager 接口。主要管理文件的读取和输出位置。JDK 中没有可以直接使用的实现类,唯一的实现类ForwardingDavaFileManager 构造器又是 protect 类型。因此 Dubbo 中定制化实现了一个 JavaFileManagerlmpl 类,并通过一个自定义类加载器 ClassLoaderlmpl 完成资源的加载。
3)DavaCompiler.CompilationTask 把 JavaFileObject 对象编译成具体的类。















 375
375











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









