







1、Shuffle概念
shuffle是spark中数据重分发的一种机制,以便于在跨分区进行数据的分组。
shuffle通常会引起executor与节点之间的数据复制,这期间会有大量的网络I/O,磁盘I/O和数据的序列化。这使得shuffle操作十分地复杂和昂贵。
在shuffle内部,单个map tasks的结果被保存在内存中,直到放不下为止。然后,根据目标分区对它们进行排序,并将它们写入单个文件。在reduce端,tasks会读取相关的经过排序的数据块。
shuffle还会在磁盘上产生大量的中间文件,这样做是为了当触发重算的时候这些中间文件不用被重新创建。垃圾收集可能会发生在很长的一段时间之后,如果应用程序保留了对这些RDD的引用,或者垃圾收集不经常启动的话。这意味着对于一个运行时长较长的spark作业,它可能会消耗大量的 磁盘空间。这些中间文件的存储目录在配置Spark Context时由spark.local.dir参数明确指定。
2、ShuffleManager的发展
-
ShuffleManager: 负责整个shuffle过程的管理与计算。
Spark 1.2之前,使用HashShuffleManager,在2.0就没了。1.6开始使用SortShuffleManager -
HashShuffleManager(已经废弃)
Spark 1.2之前,分为未优化的和优化后的两大类。
该管理器会产生大量的中间磁盘文件,以及大量的磁盘IO操作影响了性能。
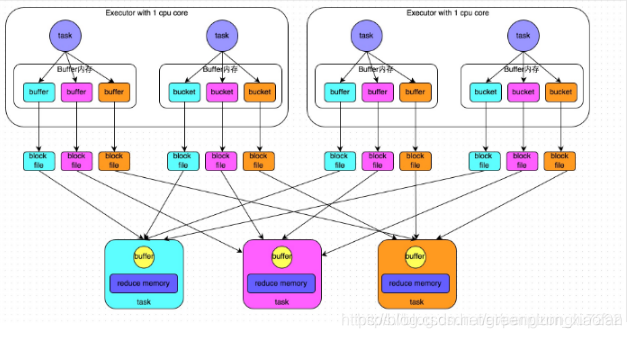
未经优化的HashShuffleManager:磁盘文件=mapreduce
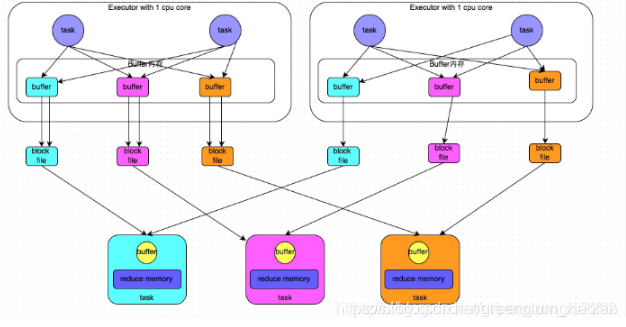
经优化的HashShuffleManager:只是开启一个参数;磁盘文件=executorreduce -
SortShuffleManager
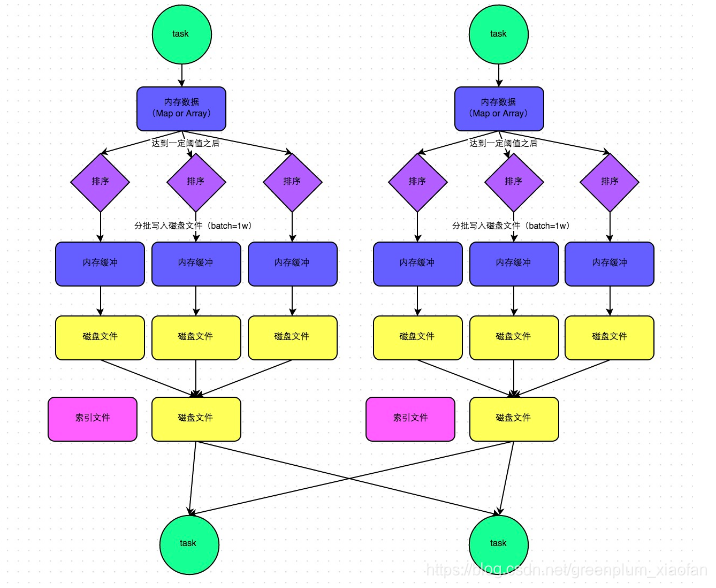
普通机制:磁盘文件:2map 一个数据文件一个索引文件
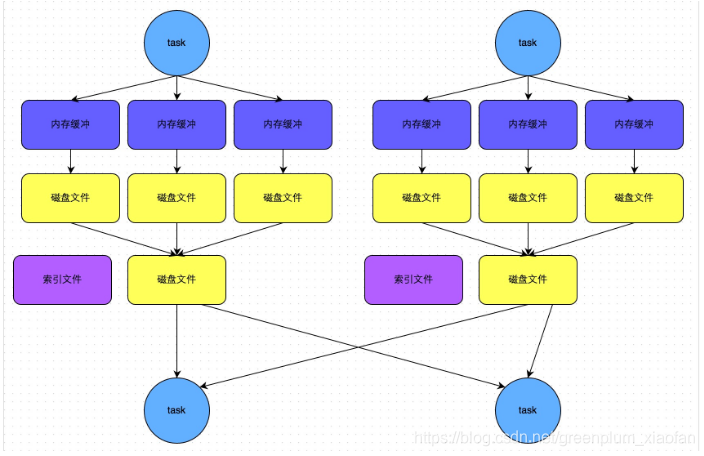
bypass机制:磁盘文件:2map 一个数据文件一个索引文件
bypass机制就是普通机制基础上去掉排序。
开启条件:
shuffle map task数量小于spark.shuffle.sort.bypassMergeThreshold参数的值。
不是map端预聚合的shuffle算子,比如重分区算子等就不会聚合。
未经优化的HashShuffleManager
经过优化的HashShuffleManager
SortShuffleManager普通机制
SortShuffleManager的bypass机制














 404
404











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









