






多线程介绍:
1、基础回顾:
线程状态:
- NEW-新建:创建了线程对象,还未开始执行。
- RUNNABLE-运行:线程对象已在java虚拟机运行,分为就绪(Ready)和运行中(Running)。
- BLOCKED-阻塞:等待获取锁的状态。
- WAITING-等待:在等待另一个线程的动作。 比如,线程调用了wait()后,等待另一个线程的notify()。
- TIME_WAITING-限时等待:同上,只不过有时间限制。
- TERMINATED-完成:线程已执行完成。
Thread、Runnable、Callable:
- Runnable接口只是定义了一个run()方法,当线程执行start()时,会调用该方法。 所以,Thread类其实也是实现了Runnable,严格意义上说,thread才是真正的线程。
- Runnable需要传入Thread中使用,thread的run方法也是调用runnable的run方法。所以,将同一个runnable对象传入不同的thread,可以共享runnable中的资源;
- Callable:同Runnable相似,要传到thread中执行,但是可以拿到返回值。
Thread常用api:
- 获取和设置对象本身的信息:
getState():该方法返回Thread对象的状态。
- sleep(): 主动挂起ms时间,不会让出cpu;
- wait是Object方法,obj.wait(),则当前线程会加入obj对象的等待队列中,直到被唤醒。 所以多个线程在操作obj对象时,必须获取obj的锁,wait和notify要处于同步块中。
- yeild(): 当然线程让出cpu资源给其他线程执行(不一定谦让成功)。
- interrupt():中断目标线程,其实只是把线程的一个变量设置为true,并不能真正中断线程。 至于要不要被中断,要看目标线程本身的逻辑,比如:
- 目标线程中可以调用interrupted方法判断,如果有了中断标记,就执行return退出。
- 假如有了中断标记,目标线程在调用阻塞方法如wait、join、sleep等方法时,会抛出InterruptedException异常,需要正确处理这些异常(比如catch异常并退出)。
- interrupted():判断目标线程是否被中断,但是将清除线程的中断标记。
- isinterrupted():判断目标线程是否被中断,不会清除中断标记。
2、synchronized
对象锁以下两种:
public void method1() { synchronized (this) { } } public void synchronized method1(){ }类锁:
public static void method2() { synchronized (MyClass.class) { } } public static void synchronized method2() { }锁的本质,就是保证共享资源,在同一时间只能有一个线程可以访问。
锁的原理,每个对象中都有对象头,对象头中有个监视器(Monitor)。 Synchronized是基于它实现的,同步块的进入和退出需要获取和释放对象的监视器。简单讲就是在monitor有个标志(state:0-没有被占用;1-被某个线程占用),如果被占用就记录该线程的id。 此外还维护了一个list,记录所有等待锁的线程id,锁释放后,就从list中取一个线程唤醒。
3、wait和notify
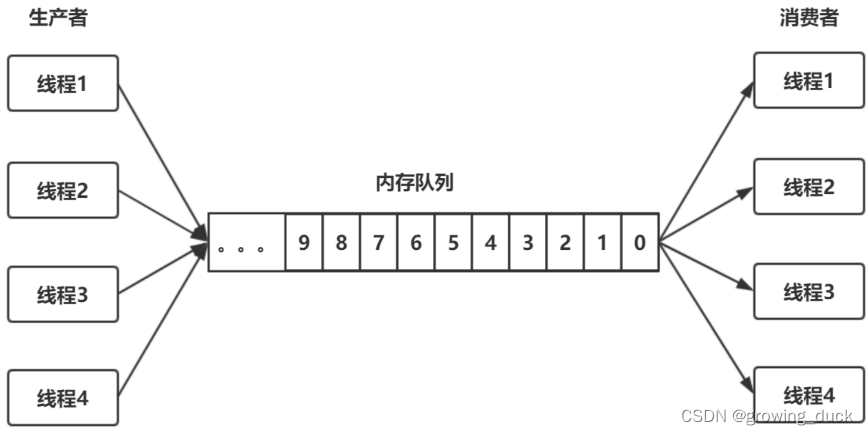
一个内存队列,多个生产者在存放数据,多个消费者在读取数据。要实现这样的模型,就要做到几件事:
- 内存队列本身要加锁,才能实现线程安全。
- 阻塞。当内存队列满了,生产者放不进去时,会被阻塞;当内存队列是空的时候,消费者无事可做,会被阻塞。
- 双向通知。消费者被阻塞之后,生产者放入新数据,要notify()消费者;反之,生产者被阻塞之后,消费者消费了数据,要notify()生产者。
当然了,第二和第三,可以用其他方法,比如自己沉睡一段时间后重试,但是这样效率低且不实时。所以可以用 wait 和 notify,实现阻塞和通知。
问题:
1、为什么wait() 和 notify() 是Object的函数,而不是作为Thread自己的函数?
因为多个线程针对的是资源本身,也就是锁的对象。上面也说了,synchronized锁的对象内,记录了获取锁的线程id 和 所有等待的线程列表。 而调用了 对象.wait()方法的线程,也是被记录在锁对象内。 所以,只能由资源对象去决定,应该阻塞 和 唤醒 哪个线程。
2、为什么wait 和 notify 必须和synchronized一起使用?
两个线程之间要通信,对于同一个对象来说,一个线程调用该对象的wait(),另一个线程调用该对象的notify(),他们都要感知对象的状态,所以同一时间只能有一个去操作对象!
3、为什么wait的时候必须释放锁?
因为wait的时候会进入阻塞状态,这时候还在synchronized中,其他线程也无法获取对象锁 调用notify,就会发生死锁。
4、notify 和 notifyall的区别?
notify是唤醒一个; notifyall是唤醒所有; 尽量使用notifyall,因为notify唤醒的那一个,可能无法正常使用了(或者唤醒的是同类线程,比如生产者1唤醒生产者2,生产者2进入了wait),就没有办法获取锁继续往下走,然后唤醒其他的,导致死锁。
5、为什么wait方法要在while循环内? 使用if可以吗?
当线程调用wait进入等待,然后在下一次被唤醒并获取到锁后,还要执行后续代码。 那么,在执行后续代码前,还需要再次判断,是否要重新wait。 如果使用if,被唤醒后一定会执行后续代码,可能会出问题。
4、线程关闭
不要stop和destory,原因很简单,如果强制杀死线程,则线程中所使用的资源,例如文件描述符、网络连接等无法正常关闭。
因此,一个线程一旦运行起来,不要强行关闭,合理的做法是让其运行完(方法执行完成),干净地释放掉所有资源,然后退出。如果是一个不断循环运行的线程,就需要用到线程间的通信机制,让主线程通知其退出。
5、守护线程
线程分为守护线程和用户线程,调用某个线程的setDaemon(true)方法,就会将其设置为守护线程。
当所有的用户线程退出后,整个JVM进程就会退出,而不会在乎守护线程的状态。 而守护线程会在主线程退出后,自动退出。 因此,守护线程一般可以用来监控用户线程来做事,
比如一些后台任务,定时任务,监听器,垃圾回收器等,就是用的守护线程。
并发概念:
1、并发与并行:
并发:在一个处理器上快速切换多个任务,看起来像是同时运行。
并行:在不同的处理器、计算机上同时运行多个任务。
2、同步:
简单说就是同一时间内,只能有一个执行。
3、不可变对象:
初始化后,不能修改其可是状态(比如它的属性值)。 就像String类,如果给它赋新的值,其实会创建另一个新对象。
因此,不可变对象是线程安全的。
并发问题:
1、数据竞争:多个线程对一个非同步的数据,同时操作,可能造成不同的结果
2、死锁: 两个或两个以上的线程在执行过程中,由于竞争资源或者由于彼此通信而造成的一种阻塞的现象,若无外力作用,会永远的阻塞下去。
3、活锁:任务或者执行者没有被阻塞,但是由于某些条件没有满足,导致一直重复尝试—失败—尝试—失败的过程。
4、资源不足:多个线程等待某一资源的释放,然后选择下一个线程执行该资源。 但是可能由于系统没有涉及良好的算法等因素,导致资源不足,这些线程长时间等待下去。 所以,在等待时需要加入时间考虑。
5、优先权反转:并发时,可能低优先权的任务先获取到资源,就会在高优先权的任务前执行。
JMM内存模型:
jmm为java内存模型,讲之前,先看看 CPU缓存模型:
CPU缓存模型:
CPU Cache:
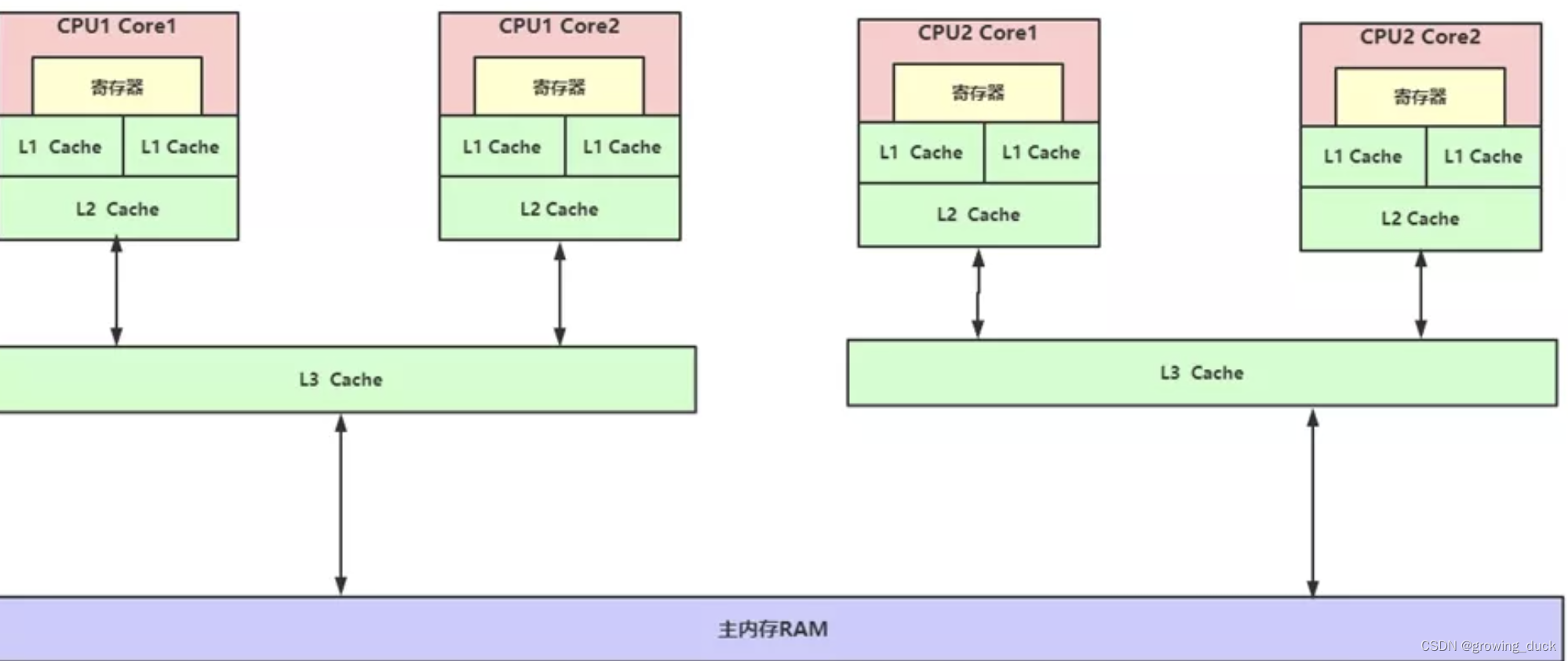
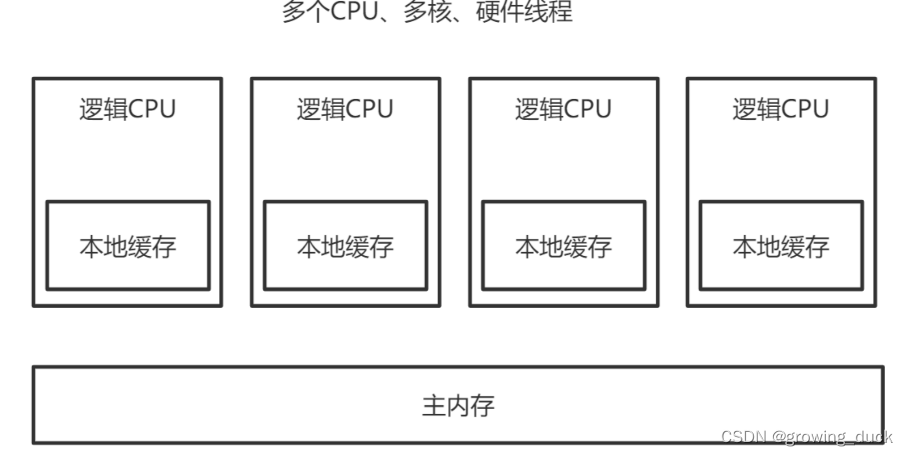
我们知道,CPU是负责执行指令的;自身的频率和指令执行的速度非常快,比内存还要快好几个级别。 如果,每次读写都要和内存交互,性能就会很低。 因此,CPU也有自己的缓存,用于解决 CPU处理速度 与 内存读写速度不匹配的矛盾;就像内存缓存的是硬盘数据,用于解决硬盘访问速度过慢的问题。
如图,现在的电脑都有多个CPU,每个CPU都有多个核。 每个核里面,都有自己的缓存L1,L2。 多个核共享L3, 多个CPU共享主内存。 L1,L2,L3就是CPU自己的缓存(整体可以都看做CPU Cache),他们的工作方式是,将内存的数据复制到CPU Cache中使用,计算完成后将结果写入内存中。
但是,如果多个线程同时从主内存当中,读取了一个副本,都进行各自的计算,就可能造成结果不一致的问题。 因此,它们需要遵循一定的规范协议来保证数据同步,即 缓存一致性协议。 这些规范就是操作系统通过内存模型定义的,无论windows、linux,他们都有自己的内存模型。
寄存器:
寄存器是CPU内部的最快和最小的存储器,比CPU Cache更快,直接和CPU核心交互。 它有很多buffer组成,如store buffer,load buffer等。 它和CPU Cache 都是存储器,但CPU Cache并不是由寄存器组成的。
内存可见性问题:
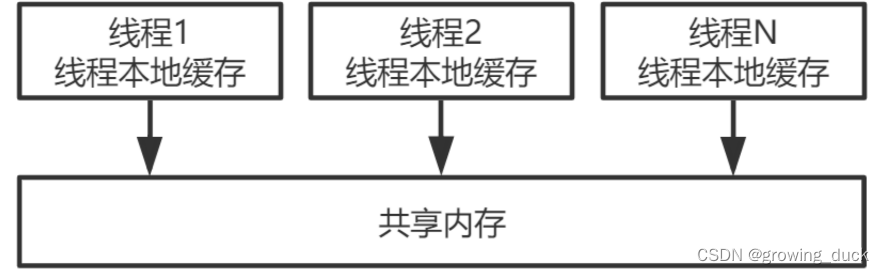
有了缓存一致性协议的保障,对于CPU Cache(L1, L2, L3)和主内存,数据是同步的。 但是呢,在寄存器和这些缓存之间,是异步的。 比如向内存中写一个变量,会先保存在store buffer里面, 稍后异步的写入L1中,同时同步的写入主内存中,最终可能造成数据不一致。 因此,从宏观层面来看,可以看做: 每个cpu都有自己的缓存,缓存和主内存不同步,造成结果不正确。
对应到java中,就是JVM抽象的内存模型了: JMM(Java Memory Model)
指令重排序 与 内存可见性问题 的关系:
程序执行时,为了提升效率,编译器和处理器都会对代码的指令重新排序,不一定按照你写的代码顺序执行。 一般分为: 编译器对于指令的重排、指令并行重排、内存系统对指令的重排。 这些重排序,在单线程下结果不会有变化,但是在多线程下,可能会出问题。 比如上面说的,store buffer延迟写入的内存可见性问题,就是重排序的第三种。 因此,我们需要 内存屏障 来保证。
内存屏障:
一种计算机硬件或软件机制,用于控制处理器和内存之间的数据同步和可见性。 它可以禁止编译器重排序和 CPU 重排序。
编译器的内存屏障,只是为了告诉编译器不要对指令进行重排序。当编译完成之后,这种内存屏障 就消失了,CPU并不会感知到编译器中内存屏障的存在。
CPU的内存屏障,是CPU提供的指令,可以由开发者显示调用。
内存屏障通常包含以下几种:
- LoadLoad:禁止读和读的重排序,保证两次读按顺序执行。
- StoreStore:禁止写和写的重排序,保证两次写按顺序执行。
- LoadStore:禁止读和写的重排序,保证先读后写。
- StoreLoad:禁止写和读的重排序,保证先写后读。
Java在Unsafe类中提供了三个:
- loadFence=LoadLoad+LoadStore
- storeFence=StoreStore+LoadStore
- fullFence=loadFence+storeFence+StoreLoad
JMM:
JMM模型,在上面简单看过,它抽象了线程和主内存的关系,也就是每个线程有自己的缓存副本,这些线程共享主内存。为了保证这种模型下不出问题,JMM描述了一组规范,定义了程序中对各个变量的访问方式。
比如:使用volatile修饰的变量
- 写操作前,插入StoreStore,保证多次写按顺序操作;
- 写操作后,插入StoreLoad,保证写完后再读;
- 读操作前,插入loadFence,保证读写顺序;
总之,volatile修饰的变量,可以让多个线程之间拿到内存最新的值,保证读写不乱序。
final也可以保证数据不被更改,还可以使用像synchronized、Lock等同步机制,也可以保证多个线程之间按串行。 他们都可以禁止重排序,保证最终结果。作为开发人员,不需要关注底层实现,正确使用即可。
注意:volatile只能保证可见性和有序性,不能保证原子性。
这就有点疑惑了,可见性保证变量被修改后,能通知到其他线程获取最新值,为什么在多线程环境下还有问题? 举个例子:
private volatile int i = 0; i++;上面的i++操作,不是一个原子操作,分为了3步:
- 线程读取i的值
- i进行自增计算
- 刷新回i的值
假如,当 i=5 的时候,A,B两个线程同时读入了 i 的值。 然后A线程执行了 temp = i + 1的操作, 此时的 i 的值还没有变化,然后B线程也执行了 temp = i + 1的操作。注意,此时A,B两个线程保存的 变量副本 i 的值都是5,temp 的值都是6。
然后A线程执行了 i = temp 的操作,此时会将i=6刷入主内存,并通知到B线程。 B线程需要重新读取 i 的值,并更新自己的变量副本i=6。 但是,B线程保存的 temp 仍然是6(已经执行过i+1的操作了), 接着B线程执行 i=temp ,结果i的值还是6,最终刷回主内存。
也就是说,两个线程都执行了i++,但是结果不是7,比预期少了1。
所以,volatile修饰的变量,在多线程环境下,如果不是做的原子操作(如i++),那就需要加锁来保证原子性了。 或者,变量用AtomicInteger这种类型的。
volatile使用场景,比如在单例模式的双检锁中:
如下的懒汉式加载,在执行new Singleton时,不是一个原子操作。 分为3步:
- 创建内存空间。
- 在内存空间中初始化对象 Singleton。
- 将内存地址赋值给 instance 对象(执行了此步骤,instance 就不等于 null 了)
假如Singleton不用volatile修饰,那么在new Singleton时,可能出现重排序,执行顺序变成 1,3,2。 这样,如果线程1刚好执行了3(instance对象还没有完全实例化,但是不为null),线程2也刚好在第一次判断null的地方,就会拿到一个实例化一半的对象,导致程序出错。
public class Singleton {
private Singleton() {
}
// 使用 volatile 禁止指令重排序
private static volatile Singleton instance = null;
public static Singleton getInstance() {
if (instance == null) { // ① 第一次判断null
synchronized (Singleton.class) {
if (instance == null) {
instance = new Singleton(); // ② 第二次判断null
}
}
}
return instance;
}
}














 633
633











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









