







源码分析(基于jdk1.8)
LinkedHashMap继承HashMap,大部分原理和HashMap相同,本文着重讲解其多出来的一部分(不熟悉HashMap原理(或源码)的同学,建议先自行查找资料,了解一下HashMap的原理)。
put(K key, V value)方法
点击去看,只有一行代码,调用putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict)方法,如下:

再进去看这个方法,如下:
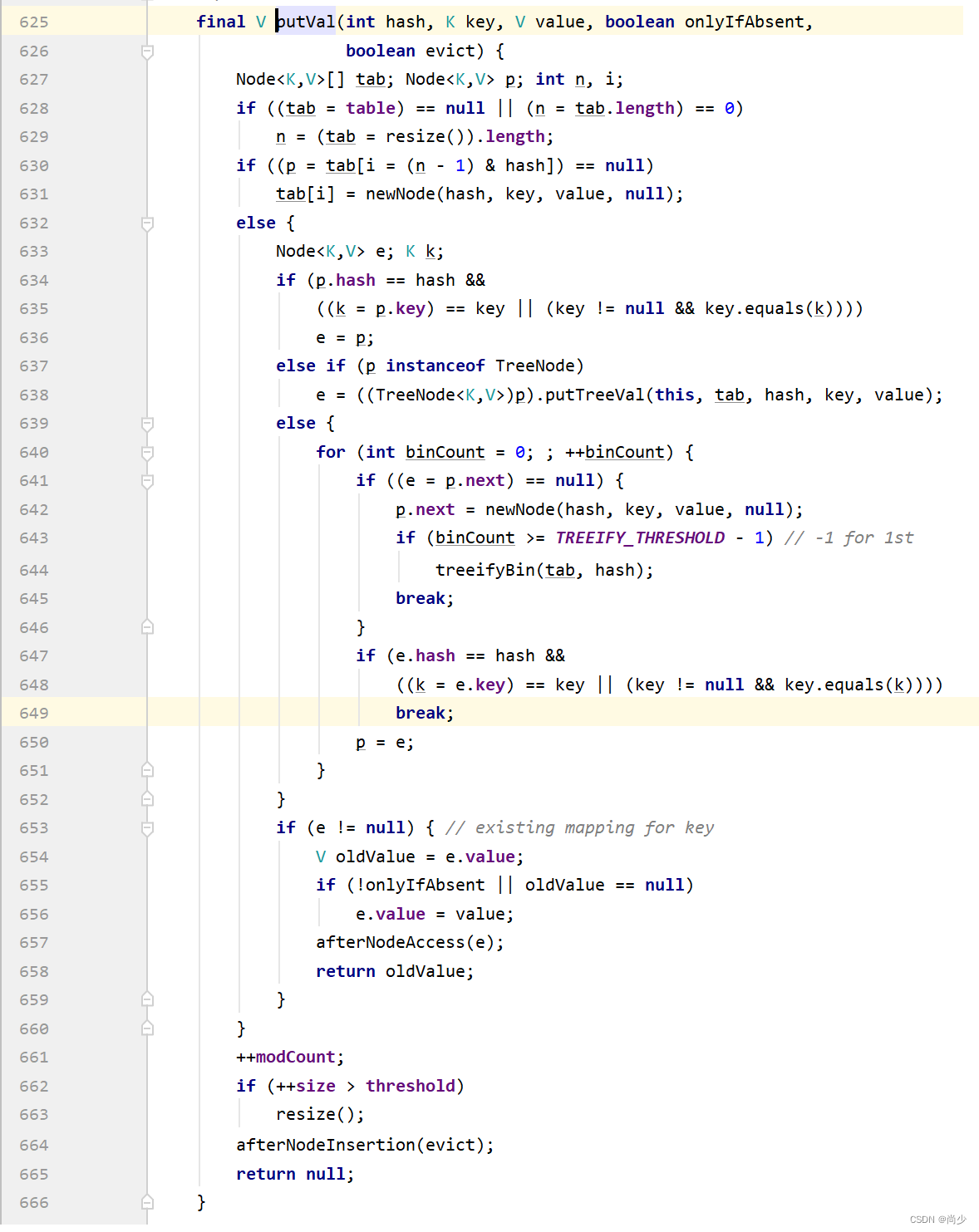
代码挺长,感觉挺复杂,莫慌,作者带着你。此时若是首次执行put(K key, V value)方法,会进入到628行的if中,初始化好Node数组,默认长度16,默认负载因子0.75;接着如果put的是新key,则执行630行的if,否则如果key已存在,再次put则执行632行的else。我们先看630行的if,调用newNode(xxx)(用xxx来省略参数)方法,此方法由LinkedHashMap重写,如下:

再点进去看linkNodeLast§,如下:
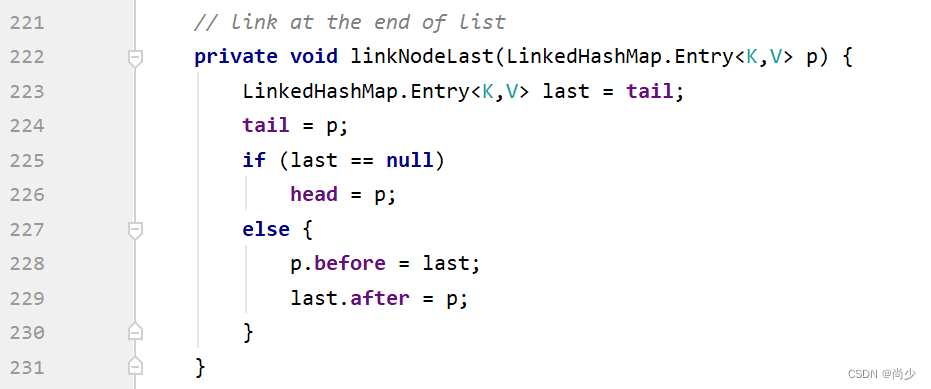
这个方法的作用是把新创建的LinkedHashMap.Entry对象,放到双向链表的尾端。LinkedHashMap相比HashMap,多维护了一个双向链表,由head和tail表示:

链表是双向的,即能从头遍历到尾(根据head和LinkedHashMap.Entry的after属性),也能从尾遍历到头(根据tail和LinkedHashMap.Entry的before属性);但不是循环双向链表,即head的before为null,不为tail,tail的after为null,不为head。
我们接着往下看代码,putVal(xxx)的631行代码执行完毕,往下走,到了664行,此时执行重写的afterNodeInsertion(evict)方法:

evict是传的true,head也是不为null,看最后一个条件removeEldestEntry(first),此方法默认直接返回false,但若是我们写了一个类,继承LinkedHashMap,重写了该方法,那么该行if也是能够执行的,会调用HashMap的removeNode(xxx)方法:
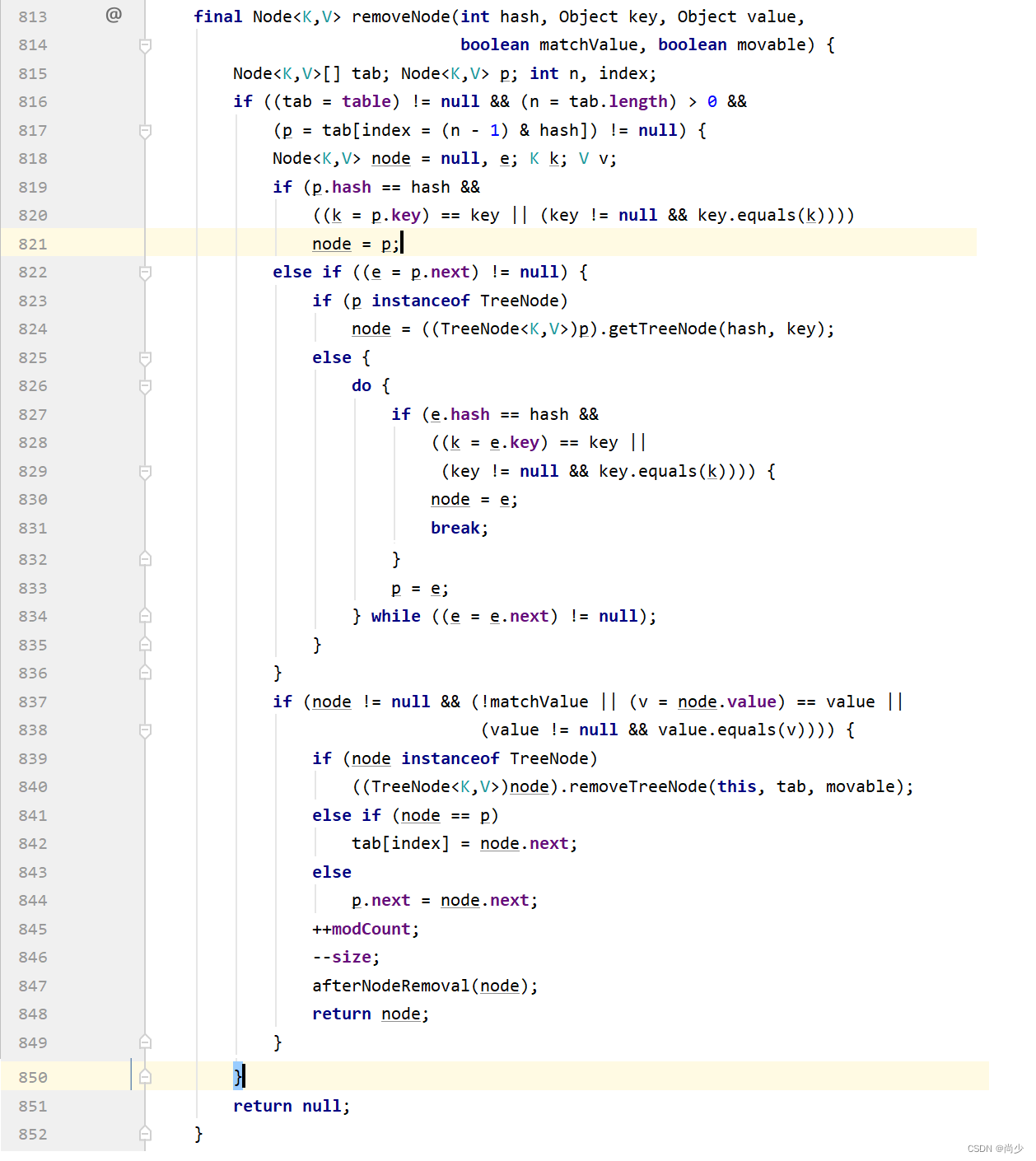
该方法的作用是把node对象从Node数组移除(对应的位置上,置为null);put新元素时,816、819、837、841(该行就是把node对象从Node数组移除)行的if会执行,也会执行847行的afterNodeRemoval(node),此方法被重写了,点进去看:

该方法的作用就是把上述移除的node对象,也从LinkedHashMap的双向链表中移除。此时putVal(K key, V value)执行完成。
put新key的情况已描述完,下面分析put已存在的key这种情况,回头去看putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict)的632行的else块。此时634、653、655行(新的value覆盖旧的value)的if语句会成立,执行afterNodeAccess(Node<K,V> e)方法,此方法被LinkedHashMap重写,如下:
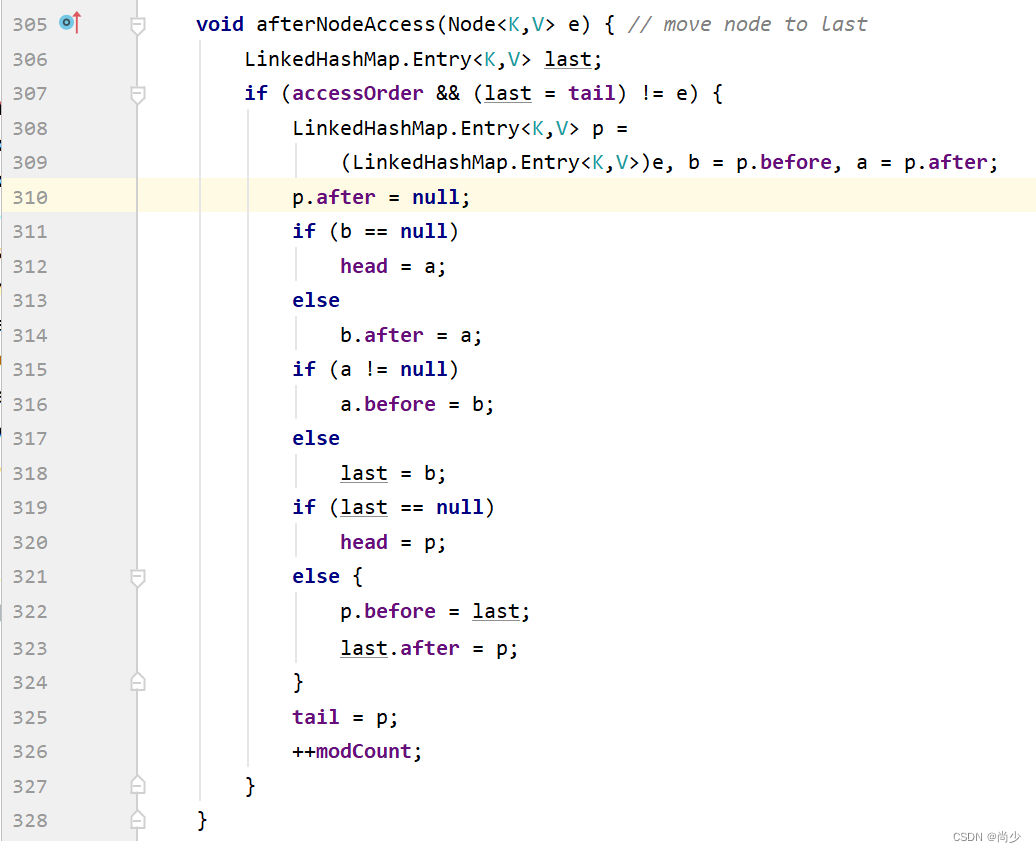
该方法的作用:当LinkedHashMap的accessOrder为true时,把参数指定的node元素,移到双向链表的尾端(tail属性也赋值为该node元素了);此时putVal(K key, V value)执行完成。put新元素和已存在元素的情况都已分析,该方法分析完毕。
get(Object key)方法
该方法比较简单:

如果accessOrder属性为true,会调用一下被重写的afterNodeAccess(Node<K,V> e)方法,上面已描述清楚。
总结
put新元素时,会把元素放到双向链表的尾部,并且调用removeEldestEntry()方法:若为true,把首元素从双向链表中移除;为false,不做处理。
put旧元素时,当accessOrder为true时,把对应的元素移到双向链表的尾部;为false时,不做处理。
get元素时,当accessOrder为true时,把对应的元素移到双向链表的尾部;为false时,不做处理。
注:LinkedHashMap的遍历,就是对双向链表的遍历(从首到尾的方向)。














 5766
5766











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









