









一、来源
Streaming Hadoop Performance Optimization at Scale, Lessons Learned at Twitter
(Data planform @Twitter)
二、观后感
2.1 概要
此稿介绍了Twitter的核心数据类库团队,在使用Hadoop处理离线任务时,使用的性能分析方法,及由此发现的问题和优化手段,对如何使用JVM/HotSpot profile(-Xprof)分析Hadoop Job的方法调用开销、Hadoop配置对象的高开销、MapReduce阶段的排序中对象序列化/反序列的高开销问题及优化等给出了实际可操作的方案。
其介绍了Apache Parquet这一面向列的存储格式,并成功应用于列投影(column project),配合predicated push-down技术,过滤不需要的列,极大提高了数据压缩比和序列化/反序列化的性能。
纯干货。
32个赞!
2.2 优化总结
1) Profile!(-Xprofile)性能优化不能靠猜,而应靠分析!
2) 序列化开销很大,但是Hadoop里有许多序列化(操作)!
3) 根据特定(数据)访问模式,选择不同的存储格式(面向行还是面向列)!
4) 使用column projection。
5) 在Hadoop的MR阶段,排序开销很大,使用Raw Comparators以降低开销。
注:此排序针对如Comparator,其会引发序列化/反序列化操作。
6) I/O并不一定就是瓶颈。必要的时候要多I/O换取更少的CPU计算。
JVM/HotSpot原生profile能力(-Xprof),其优点如下:
1) 低开销(使用Stack sampling)。
2) 能揭示开销最大的方法调用。
3) 使用标准输出(Stdout)将结果直接写入Task Logs。
2.3 Hadoop的配置对象

1) Hadoop的Configuration Object开销出人意料的高。
2) Conf的操作看起来就像一个HashMap的操作。

3) 构造函数:读取+解压+分析一个来自磁盘的XML文件

4) get()调用引起正则表达式计算,变量替换。

5) 如果在循环中对上述等方法进行调用,或者每秒一次调用,开销很高.某些(Hadoop)Jobs有30%的时间花在配置相关的方法上!(的确是出人意料的高开销)

总之,没有profile(-Xprof)技术,不可能获取以上洞察,也不可能轻易找到优化的契机和方向,需要使用profile技术来获知I/O和CPU谁才是真正的瓶颈。
2.4 中间结果的压缩
- Xprof揭示了spill线程中的压缩和解压缩操作消耗了大量时间。
- 中间结果是临时的。
- 使用lz4方法取代lzo level 3,减少了30%多的中间数据,使其能被更快地读取。
- 并使得某些大型Jobs提速150%。

2.5 对记录的序列化和反序列,会成为Hadoop Job中开销最高的操作!

2.6 对记录的序列化是CPU敏感的,相对比之下,I/O都不算什么了!

2.7 如何消除或者减小序列化/反序列化引起的(CPU)开销?
2.7.1 使用Hadoop的Raw Comparator API(来比较元素大小)
开销分析:如下图所示,Hadoop的MR在map和reduce阶段,会反序列化map结果的keys以在此阶段进行排序。

(反序列化操作)开销很大,特别是对于复杂的、非原语的keys,而这些keys又很常用。

Hadoop提供了一个RawComparator API,用于对已序列化的(原始的)数据(字节级)进行比较:


不幸的是,需要亲手实现一个自定义的Comparator。
现在,假设数据已序列化后的字节流,本身是易于比较的:
Scala有个很拉风的API,Scala还有一些宏可以产生这些API,以用于:
Tuples , case classes , thrift objects , primitives , Strings,等等数据结构。

怎么拉风法呢?首先,定义一个密集且易于比较的数据序列化(字节)格式:
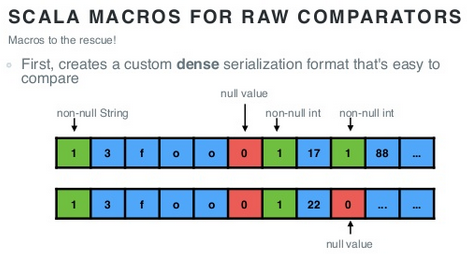
其次,生成一个用于比较的方法,以利用这种数据格式的优势:
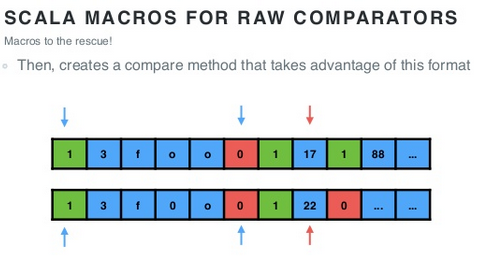
下图是采用上述优化手段后的比较开销对比:
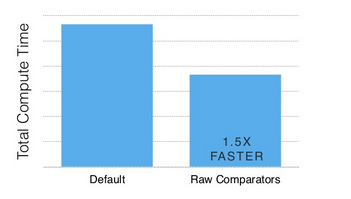
提速到150%!
接着优化!
2.7.2 使用column projection
不要读取不需要的列:

1) 可使用Apache Parquet(列式文件格式)。

2) 使用特别的反序列化手段可以在面向行的存储中跳过一些不需要的字段。
面向列的存储中,一整列按顺序存储(而不是向面向行的存储那样,列是分开存储的):
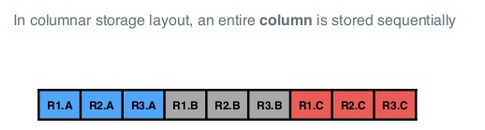
可以看到,面向列的存储,使得同类型的字段被顺序排在一起(易于压缩):

采用Lzo + Parquet,文件小了2倍多!
2.7.3 Apache Parquet
1) 按列存储,可以有效地进行列投影(column projection)。
2) 可按需从磁盘上读取列。
3) 更重要的是:可以只反序列化需要的列!

看下效果:
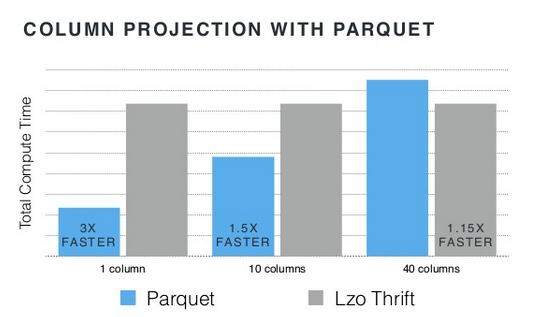
可以看到,列数越少,Parquet的威力越大,到40列时,其效率反而不如Lzo Thrift。
- 在读取所有列的情况下,Parquet一般比面向行的存储慢。
- Parquet是种密集格式,其读性能和模式中列的数目相关,空值读取也消耗时间。
- 而面向行的格式(thrift)是稀疏的,所以其读性能和数据的列数相关,空值读取是不消耗时间的。

跳过不需要的字段,如下所示:
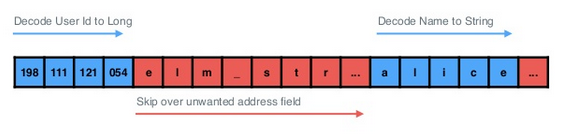
- 虽然,没有降低I/O开销
- 但是,可以仅将感兴趣的字段编码进对象中
- 相对于从磁盘读取 + 略过编码后字节的开销,在解码字符串时所花的CPU时间要高的多!
看下各种列映射方案的对比:
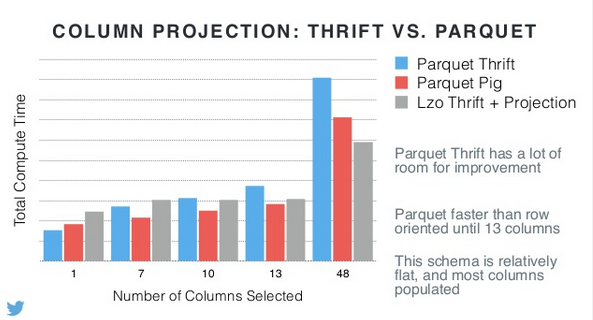
Parquet Thrift还有很多优化空间;Parquet在选取的列数小于13列之前,是更快的;此模式相对平坦,且大多数列都被生成了。
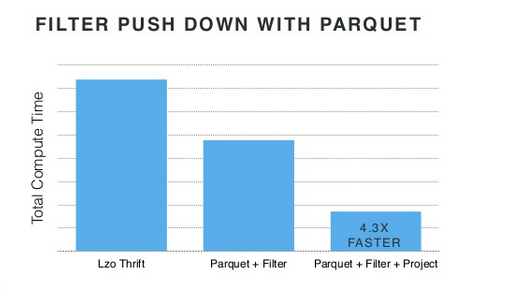
- 还可以采用Predicate Push-Down策略,使得Parquet可以跳过一些不满足过滤条件的数据记录。
- Parquet存储了一些统计信息,比如记录的chunks,所以在某些场景下,可以通过对这些统计信息进行读取分析,以跳过整个数据块(chunk)。

注:左图为column projection,中图为predicate push-down过滤,右图为组合效果。可以看到很多字段被跳过了,那绝壁可以优化序列化/反序列化的效率。
下图则展示了push-down过滤 + parquet的优化成效:
2.8 结语
感叹:Twitter真是一家伟大的公司!
上述优化手段,集群越大、Hadoop Job越多,效果越明显!















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









