







Day 1!
哈喽医学生们!Ready to challenge?这次我们发起7天肠道菌群孟德尔随机化挑战!一起加油呀!
第一天: 确定目标,初步检索!
肠道菌群的MR研究非常火热,搜索“gut microbiota and Mendelian randomization”,发现高分杂志上的文章比比皆是,影响因子不差,不乏有很多一区高影响因子文章,发文数量也蹭蹭蹭,我也来发起挑战!
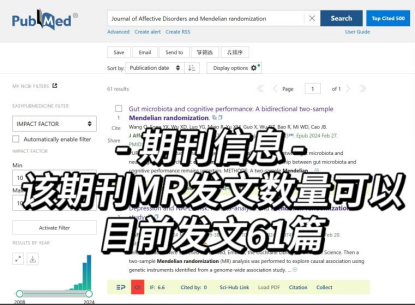
所以我初步检索了肠道菌群,似乎在我的研究领域来说还是一篇蓝海,然后我挑选了一个比较友好的目标期刊,Journal of Affective Disorders,这个杂志是我们的老朋友啦,这可不是水刊哦,一区TOP而且进入杂志官网可以看到他的杂志目前中了61篇MR,妥妥的61篇MR,包括还有一些其他公开数据库的,说明杂志对MR文章还是比较友好的!可以冲锋!所以,定下目标,我的目标期刊就是他啦!
好啦,让我们一起探索肠道菌群MR,一起冲锋呀


Day 2-3!
我的新挑战持续进行中~
第2-3天了:
工作重点都集中在选题和阅读范文上,不管做什么类型的研究、不管做那种类型的MR,我们都需要花大量的时间进行选题评价,所以我用了2天的时间来进行选题确定,就是为了避免出现做完了工作发现已经被别人写了?选题不合适?等情况
说到肠道菌群孟德尔随机化,其实它就是双样本MR的plus pro max版本!就是一个暴露对应一个结局,只不过我们现在的暴露换成了肠道菌群,那我我们进行模仿的时候主要的就是去替换结局,比如别人做的比如别人写了自身免疫性肝炎,我就在想能不能写自身免疫性脑炎呢?
理解起来超简单的,代码也不难掌握。最大的挑战,就是数据处理啦!毕竟这么多细菌,那么他的GWAS数据肯定是非常庞大的,细菌的基因总数比我们人类自身的基因多150倍!
面对这么大量的GWAS数据,我已经做好准备了!代码都备好了,我的目标期刊是Journal of Affective Disorders,所以我选了里面两篇相关的文章来参考,换个角度,换个结局,就是我的新选题啦!
比如别人写了肝癌,我能不能试着写结直肠癌呢?当然这只是个例子啦!但确实在临床上确实有它的意义。然后把别人做过的疾病换个自己领域的疾病,就能写出一篇新文章,同时,我们也可以把肠道菌群看成中介变量,和中介MR联系起来,这样文章就更丰富了!
当然啦,数据量大是我们跑结局的一个限制因素。但只要我们掌握多种MR的方法,并且加强代码和写作能力的练习,相信高分MR就在眼前啦!
好啦,今天的分享就到这里啦!
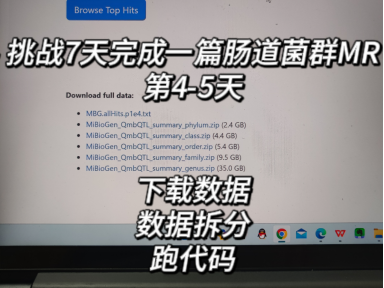

Day 4-5!
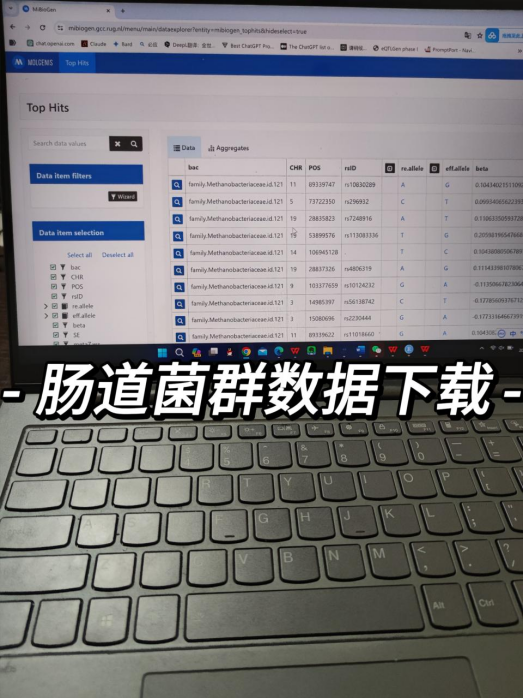
进度汇报:数据下载+数据拆分+跑代码
做分析的过程可真不简单,因为肠道菌群的数据量确实太大了,还好电脑内存、配置还行,为了转移数据,搞了个2T的大硬盘,本期挑战沉默成本陡然增加,不过平时也能用上,把自己一些公开数据库的数据转移了一波,哈哈哈只要思路对了,无非就是多花时间跑代码就好了~
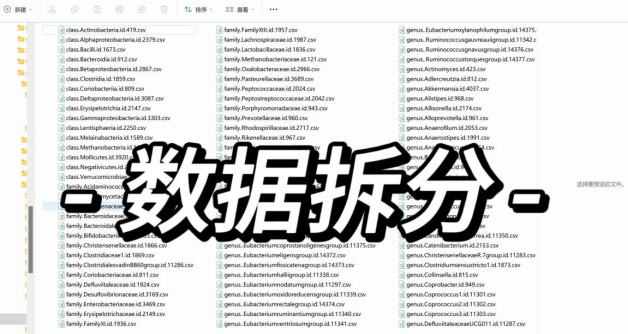
因为肠道菌群的数据太大了,如果在跑的过程中出现了error,那也就意味着需要重新跑一遍,所以把代码进行了一些调整,把暴露的肠道菌群数据进行了拆分让拆分后的数据和结局跑双样本MR,然后再把跑出来的结果组合起来。这也算是节省时间了,但还是跑了2天才跑完
归根结底,还只是双样本MR而已,没什么太复杂的,只要懂了基础,无非就是换了数据来源而已,比如有人测了口腔菌群、皮肤菌群的GWAS数据,方法都是一样的,我们之后慢慢挑战,只是跑数据需要大量的时间
这篇文章我觉得基本是挑战成功了,我只要能够跑的出来图片,后面的写作简直易如反掌,因为我有“框架写作法”指导我进行写作,1-2天写完是绰绰有余的,就是跑代码太烧电脑了
刷小红书,发现大家好像着魔了,各种学MR的教程,各种求资源,其实跑顺代码是一方面,能够高效写得出来发表级别的文章又是另一个方面,写不出来文章,那就没有意义
同时,我们也要反思,高分SCI其实就是Paper Tiger而已,没什么复杂和困难的,重点是思路,这就是我花了很多的时间进行选题的意义,就是在进行可行性分析,千万不要一来就闷头开跑,睁开眼睛看世界!一起加油呀~
最近有一些师弟师妹们来找我学习和咨询,包括前期的挑战Meta分析也好,我们准备了一整套的完整方案,从文献阅读→选题→数据分析→论文框架→论文写作→方法学(双样本MR、药把、中介、多变量、肠道菌菌群、Meta、NAHNES、GBD。。。)
30天创作一篇SCI,高效写得出来发表级别的文章,一起加油呀!

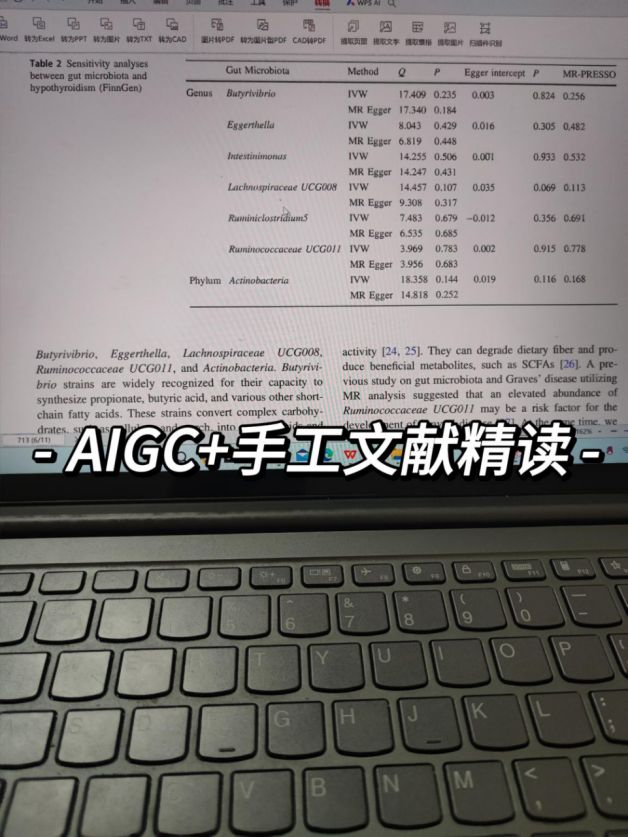

Day 6-7!
完成挑战!
进度汇报:材料+讨论+介绍+模板化内容+投稿准备(翻译+润色+选刊)
本次的主要内容是完成写作和进行投稿
总体来讲,写作比较简单的,因为我已经摸透了“框架写作法了”,按照节奏一步一步进行就行,通过AIGC工具帮助写作+自动添加引用文献+结构化语句添加+根据目标期刊润色+选刊推荐
因为投稿得比较多了,所以在前期准备的时候就根据预期的期刊进行准备了,比如说图片的格式,写作的格式等等,所以投稿准备的难度不大
一句话总结一下肠道菌群MR: 肠道菌群MR就是高配版的双样本MR。
无非就是数据量比较大,可以把肠道菌群的GWAS数据当成暴露、结局,或者是中介变量,然后我们只需要在mibiogen网站下载相关数据即可,当然因为数据量很大,需要进行数据的拆分,对设备有一定的要求。
写作:精读2-3篇选出的目标文献的肠道菌群MR论文,提取框架+充实内容+精修润色+成稿投稿。
总而言之、言而总之,思路简单+核心代码=5分+,当然,想要冲击更高分的MR,那就需要处理一些本地数据了、选题也要更下功夫,我的这个挑战还是基于IEU的
为了高分,冲锋,一起加油呀!!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









