







宝子们!还在对着 Hadoop 部署文档抓头发吗?作为被 Hadoop 虐过无数次的 “过来人”,今天我把压箱底的零基础友好版教程掏出来了!从环境准备到伪分布模式,每一步都拆成 “傻瓜式操作”,连我妈(真・0 基础)看了都能跟着敲命令!教程里藏了 20 + 高频命令和 99% 新手会踩的坑,收藏起来慢慢看,咱们直接开整~
一、🐘Hadoop 冷知识大起底:原来你是这样的大象!
1. 大象的诞生:从谷歌偷师的技术狠人

Hadoop 的 “爸爸” 叫道格・卡丁,江湖人称 “开源界的爱迪生”—— 他靠一个 Lucene 检索 jar 包打天下,后来盯着谷歌的三篇神级论文(GFS/MapReduce/BigTable)直接 “抄作业”,硬是搞出了 Hadoop 这个 “大象”!为啥是大象?因为它能扛住 PB 级数据(1PB=1024TB),还能无限扩展服务器集群,稳得像老黄牛~
2. Hadoop 三巨头:各司其职的铁三角
- HDFS(分布式文件系统):大数据的 “超级仓库”,把海量数据拆成小块存到不同服务器,就像给数据建了个 “分布式快递柜”,存得多还能随便加柜子。
- Yarn(资源调度器):集群的 “资源管家”,给 MapReduce、Spark 这些计算任务分配 CPU 和内存,没它任务就得 “饿肚子”。
- Common(公共工具):Hadoop 的 “万能工具箱”,管着配置文件解析、IO 操作这些 “杂活”,少了它整个框架就得 “散架”。
3. 生态圈全家桶:大象的朋友圈有多牛?
Hadoop 可不是孤家寡人,它的朋友圈堪称大数据界的 “复仇者联盟”:
- Hive:让不会写代码的人用 SQL 玩转大数据,数据分析的 “摸鱼神器”。
- ZooKeeper:分布式系统的 “和事佬”,解决节点间的通信和一致性问题,避免集群 “内讧”。
- Flume/Sqoop:数据 “搬运工”,专门把数据库、日志文件的数据搬到 HDFS 里,解放数据工程师的双手。
- Azkaban:任务 “闹钟”,定时触发数据处理流程,再也不用手动敲命令到凌晨。
4. 版本选择困难症?看这!
- Apache 版:免费开源,适合咱们 0 基础学习,最新 3.3.1 版(教程就用它,踩坑最少!)。
- CDH 版:商用版,道格・卡丁亲自操刀,企业级稳定,缺点是要钱。
- 国产版:比如 DataLight,支持国产化适配,性价比拉满,适合咱们自己人。
二、💻环境准备:0 基础也能搞定的 “傻瓜操作”
1. 安装 Java:踩坑重灾区,跟着步骤走就行!
① 检查是否安装(不会看?看这里!)
java -version
# 如果显示“command not found”,说明还没装,进入新手村第一关!② 安装 OpenJDK 1.8+(双系统保姆级教程)
# Ubuntu/Debian系统(最常用的Linux系统)
sudo apt update && sudo apt install openjdk-8-jdk -y
# 输入密码时别手抖,输完按回车就行,等进度条走完就装好了~
# CentOS 7系统(生产环境老大哥)
sudo yum install java-1.8.0-openjdk -y
# 安装时可以喝杯茶,顺便看看大象壁纸,很快就好!③ 配置环境变量(关键到敲黑板!)
sudo nano /etc/profile
# 打开文件后,用方向键下到最后一行,输入(注意路径别抄错!):
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
export PATH=$JAVA_HOME/bin:$PATH
# 保存按Ctrl+O,退出按Ctrl+X,然后执行命令让配置生效:
source /etc/profile
# 验证:输入echo $JAVA_HOME,能看到路径就成功,看不到回来找我!2. 下载 Hadoop:官网直达 + 解压秘籍
1. 上传 Hadoop 安装包(以 3.3.1 版本为例)
- 下载地址:从Hadoop 官网下载
hadoop-3.3.1.tar.gz,上传到 Linux 系统(推荐用 Xftp 等工具,或通过wget命令下载)。
2. 解压安装包
# 新建统一安装目录(规范操作,避免混乱)
sudo mkdir -p /opt/installs/
# 解压到指定目录(注意!你的版本是3.3.1,别输错文件名)
tar -zxvf hadoop-3.3.1.tar.gz -C /opt/installs/3. 重命名文件夹(简化路径,方便后续操作)
# 进入安装目录
cd /opt/installs/
# 重命名(从hadoop-3.3.1改为hadoop,后续命令更简洁)
mv hadoop-3.3.1 hadoop4. 配置环境变量(关键!让系统识别 Hadoop 命令)
# 用vi编辑器打开系统配置文件(你用的vi,和教程统一!)
vi /etc/profile
# 按下键盘字母「i」进入编辑模式,在文件末尾添加以下两行(注意路径正确!):
export HADOOP_HOME=/opt/installs/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
# 编辑完成后,按「Esc」键退出编辑模式,输入「:wq」保存并退出5. 刷新配置文件(让环境变量立即生效)
source /etc/profile
# 这一步就像给系统“刷新”,之后就能直接敲hadoop命令啦~6. 验证 Hadoop 是否安装成功(关键一步!)
hadoop version
# 正常会输出:Hadoop 3.3.1,看到这个就说明安装+配置成功啦! 7. 设置用户权限(避免后续权限报错,新手必做!)
7. 设置用户权限(避免后续权限报错,新手必做!)
sudo chown -R $USER:$USER /opt/installs/hadoop
# 给Hadoop文件夹打上你的“专属标签”,否则可能出现权限不足的报错哦~三、🎮本地模式:5 分钟跑通第一个 Hadoop 程序(附实战测试案例)
1. 本地模式是什么?
简单来说就是单节点单机运行,Hadoop 所有进程都在你这台电脑里跑,不需要集群配置。数据和计算结果都存储在本地磁盘,适合新手快速验证 Hadoop 是否能正常工作,就像游戏里的 “新手村教程”,帮你建立信心~
2. 实战案例:WordCount 词频统计(大数据界的 “Hello World”)
① 准备测试文件(3 行文本,单词用空格分隔)
# 在/home目录创建wc.txt并写入数据
touch /home/wc.txt # 创建空文件
echo "hello world spark flink" >> /home/wc.txt
echo "hello laoyan 2202 laolv" >> /home/wc.txt
echo "hello suibian suibian hello" >> /home/wc.txt
# 检查文件内容(确保数据正确)
cat /home/wc.txt
# 输出应包含3行文本,包含hello、world、spark等单词② 运行 Hadoop 自带的 WordCount 工具
hadoop jar /opt/installs/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.1.jar wordcount /home/wc.txt /home/output命令拆解(新手必看!):
hadoop jar:执行 Hadoop 的 Java 程序(底层是 MapReduce 框架)hadoop-mapreduce-examples-3.3.1.jar:Hadoop 自带的示例 jar 包,包含 WordCount 等经典案例wordcount:指定运行 “词频统计” 功能/home/wc.txt:输入文件路径(本地磁盘上的文件)/home/output:输出结果路径(** 必须不存在!** 否则报错)
⚠️ 避坑重点:
如果提示 Output directory /home/output already exists,说明结果目录已存在,需提前删除:
rm -r /home/output 2>/dev/null # 强制删除,不存在也不报错③ 查看统计结果
# 进入输出目录
cd /home/output
# 查看结果文件(以part-r-00000结尾)
cat part-r-00000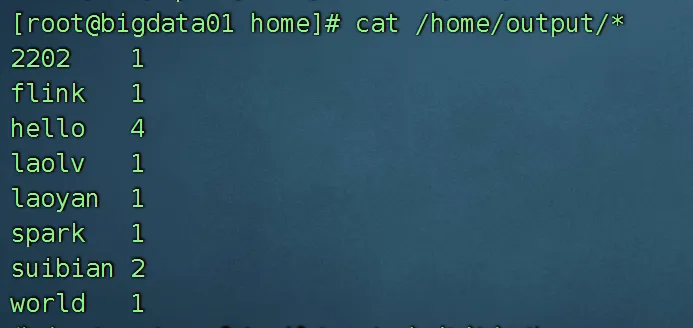
3. 进阶案例:PI 值计算(体验分布式计算思想)
① 运行 PI 计算程序
hadoop jar /opt/installs/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.1.jar pi 10 100参数说明:
10:创建 10 个 Map 任务(模拟分布式计算中的任务分片)100:每个任务生成 100 个随机点估算 π 值(数值越大结果越精确)
② 结果解读
程序运行后会输出类似信息:
...
Estimated value of Pi is 3.141592653589793
... 这是 Hadoop 通过蒙特卡洛方法估算的 π 值,接近真实值 3.1415926535...
4. 案例总结:本地模式的特点
| 数据位置 | 计算方式 | 适用场景 | 注意事项 |
|---|---|---|---|
| 输入 / 输出均在本地磁盘 | 单节点非分布式计算 | 入门学习、功能验证 | 结果目录必须提前删除 |
5. 常见错误及解决(新手必看!)
| 报错信息 | 原因 | 解决方法 |
|---|---|---|
Command not found: hadoop | Hadoop 环境变量未配置 | 检查/etc/profile中HADOOP_HOME路径,执行source /etc/profile |
Output directory exists | 结果目录已存在 | 运行前删除:rm -r /home/output |
ClassNotFoundException | jar 包路径错误或版本不符 | 确认路径为/opt/installs/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.1.jar |
四、伪分布模式部署 —— 单节点模拟分布式集群(从本地模式到分布式的关键一步)
完成本地模式的测试后(通过 WordCount 和 PI 计算验证了 Hadoop 基本功能),接下来我们进入更贴近真实生产环境的伪分布模式部署。这一步的核心是:用一台服务器模拟分布式集群,体验 HDFS 分布式存储和 MapReduce 分布式计算的完整流程。
4.1 为什么需要伪分布模式?
本地模式虽能验证 Hadoop 功能,但数据和计算均在单机完成,无法体现「分布式」的核心优势。伪分布模式通过 ** 单节点模拟 NameNode(管理元数据)、DataNode(存储数据块)、SecondaryNameNode(辅助元数据管理)三个角色,让我们在低成本下学习分布式存储原理,为后续全分布集群部署打基础。
4.2 部署前的环境准备(必须完成的 6 个前置操作)
注意:以下操作需在本地模式部署完成后进行(已安装 Hadoop 3.3.1、Java 8+,且通过
hadoop version验证成功)。
4.2.1 关闭系统安全屏障(防火墙 + SELinux)
本地模式不涉及网络通信,但伪分布需要集群内部进程通信,必须关闭防火墙和 SELinux:
# 关闭防火墙(CentOS为例,Ubuntu用ufw disable)
systemctl stop firewalld && systemctl disable firewalld
# 禁用SELinux(永久生效需重启)
sed -i 's/SELINUX=enforcing/SELINUX=disabled/' /etc/selinux/config
setenforce 0 # 临时生效,无需重启4.2.2 配置免密登录(自己连自己)
分布式集群中,主节点需无密码访问从节点。伪分布虽只有 1 台服务器,但仍需配置本地免密:
# 生成密钥对(一路回车默认即可)
ssh-keygen -t rsa -P "" -f ~/.ssh/id_rsa
# 将公钥添加到本地信任列表
ssh-copy-id localhost
# 测试:输入ssh localhost,应直接登录无需密码4.2.3 设置主机名映射(集群通信的关键)
Hadoop 进程通过主机名通信,需将bigdata01(自定义主机名)映射到本地 IP:
# 编辑hosts文件
vi /etc/hosts
# 添加一行(IP和主机名对应,bigdata01可替换为你的主机名)
127.0.0.1 bigdata014.2.4 统一用户权限(避免启动报错)
Hadoop 进程需以当前用户启动,确保安装目录权限归属正确:
sudo chown -R $USER:$USER /opt/installs/hadoop4.3 核心配置文件修改(路径:/opt/installs/hadoop/etc/hadoop/)
伪分布的核心是通过配置文件告诉 Hadoop:“虽然只有 1 台服务器,但你要模拟分布式角色”。需修改以下 3 个文件:
4.3.1 core-site.xml:定义 HDFS 核心参数
<configuration>
<!-- NameNode的访问地址(Hadoop 3.x默认端口9820) -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://bigdata01:9820</value> <!-- 主机名与hosts文件一致 -->
</property>
<!-- Hadoop临时目录(存储元数据和数据块,必须提前创建!) -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/installs/hadoop/tmp</value>
</property>
</configuration>4.3.2 hdfs-site.xml:定义 HDFS 专属参数
<configuration>
<!-- 数据副本数(单节点只能设1,真实集群一般设3) -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<!-- NameNode的Web界面地址(访问集群状态用) -->
<property>
<name>dfs.namenode.http-address</name>
<value>bigdata01:9870</value> <!-- 后续通过此地址访问管理页面 -->
</property>
</configuration>4.3.3 workers:指定从节点(DataNode 运行的节点)
vi workers # 清空原有内容,仅保留一行
bigdata01 # 与hosts中的主机名完全一致4.4 启动集群:从格式化到可视化验证(关键 3 步)
4.4.1 格式化 NameNode(初始化元数据)
首次启动前,必须格式化 NameNode,创建元数据存储目录:
hdfs namenode -format注意:
- 格式化会清空
hadoop.tmp.dir目录(即/opt/installs/hadoop/tmp),首次部署无需担心; - 若需二次格式化(如修改配置后),需先删除旧目录:
-
rm -rf /opt/installs/hadoop/tmp/* hdfs namenode -format4.4.2 启动 HDFS 服务
执行脚本启动所有 HDFS 进程(NameNode+DataNode+SecondaryNameNode):
start-dfs.sh4.4.3 验证服务状态(2 种方式)
-
命令验证:执行
jps命令,应看到 3 个进程:12345 NameNode # 管理元数据 12346 DataNode # 存储数据块 12347 SecondaryNameNode # 辅助元数据管理 -
Web 界面验证:浏览器输入
http://你的服务器IP:9870(如http://192.168.233.128:9870),应看到 HDFS 集群管理页面,显示 “Live Nodes” 为 1(即当前 DataNode 节点)。 -
4.5 实战测试:用 HDFS 跑 WordCount(分布式存储初体验)
伪分布的核心是数据存储在 HDFS(分布式文件系统),而非本地磁盘。以下用之前本地模式的
wc.txt文件,演示完整流程:4.5.1 上传文件到 HDFS(数据上云)
# 在HDFS中创建目录(类似本地mkdir) hdfs dfs -mkdir -p /user/root # 上传本地文件到HDFS(本地路径→HDFS路径) hdfs dfs -put /home/wc.txt /user/root
4.5.2 运行 WordCount(输入输出均在 HDFS)
hadoop jar /opt/installs/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.1.jar wordcount /user/root/wc.txt /user/root/output注意:
- 输出目录
/user/root/output必须不存在,否则报错(可用hdfs dfs -rm -r /user/root/output删除旧目录); - 输入路径是 HDFS 路径(以
/开头),而非本地路径(如/home/wc.txt)。 -
4.5.3 查看分布式计算结果
-
hdfs dfs -cat /user/root/output/part-r-00000输出应与本地模式一致(如
hello 4),但数据存储在 HDFS 的分布式文件系统中,而非本地磁盘。 -
4.6 伪分布 VS 本地模式:关键区别总结(划重点!)
对比项 本地模式 伪分布模式 数据存储位置 本地磁盘(如 /home/wc.txt)HDFS(如 /user/root/wc.txt)计算结果位置 本地磁盘(如 /home/output)HDFS(如 /user/root/output)分布式特性 无(单节点非分布式) 有(模拟 NameNode/DataNode) 适用场景 入门验证、单机功能测试 开发调试、学习分布式原理 4.7 常见问题及解决方案(新手必看!)
-
问题 1:
hdfs namenode -format报错 “NameNode is not formatted”- 原因:临时目录
/opt/installs/hadoop/tmp已存在旧数据。 - 解决:删除旧目录后重新格式化:
-
rm -rf /opt/installs/hadoop/tmp/* hdfs namenode -format -
问题 2:Web 界面无法访问(提示 “连接拒绝”)
- 原因:防火墙未关闭或端口被占用。
- 解决:
① 检查防火墙状态:systemctl status firewalld(CentOS);
② 确认 9870 端口被监听:netstat -tunlp | grep 9870;
③ 重启集群:stop-dfs.sh && start-dfs.sh。
-
问题 3:
hadoop jar命令报错 “Input path does not exist”- 原因:文件未成功上传到 HDFS。
- 解决:用
hdfs dfs -ls /user/root检查文件是否存在,若不存在重新上传。 -
4.8 下一步:完整 Hadoop 伪分布(含 Yarn 调度)
当前仅完成 HDFS 伪分布,若需体验完整的分布式计算(包括资源调度),需补充 Yarn 配置:
- 修改
yarn-site.xml,设置 ResourceManager 地址; - 启动 Yarn 服务:
start-yarn.sh; - 验证 Yarn 进程(NodeManager/ResourceManager)。
-
五、HDFS 核心 Shell 命令:高效管理分布式文件系统(附实战示例)
完成伪分布模式部署后,我们需要掌握 HDFS 的核心 Shell 命令 —— 这是与分布式文件系统交互的 “瑞士军刀”。即使 Web 界面(如
http://IP:9870)在查看大文件或复杂操作时可能报错,Shell 命令依然稳定可靠。以下是开发中最常用的命令分类及实战用法:5.1 为什么需要 Shell 命令?(对比三种操作方式)
-
操作方式 优势 劣势 适用场景 Web 界面 可视化操作,适合查看集群状态 无法操作复杂逻辑,大文件查看易报错 监控集群、简单文件浏览 Shell 命令 功能强大,支持脚本自动化 需要记忆命令语法 日常开发、批量操作、脚本编写 Java 代码 灵活定制,适合复杂业务逻辑 开发成本高,需编写代码 项目集成、自定义功能开发 结论:Shell 命令是 HDFS 操作的 “刚需”,尤其在开发调试阶段,必须熟练掌握!
-
5.2 基础操作命令:文件与目录管理(每天必用!)
5.2.1 文件上传(本地→HDFS)
命令 语法 示例 核心区别 puthdfs dfs -put 本地文件 HDFS路径hdfs dfs -put /home/wc.txt /user/root上传后保留本地文件,安全首选 moveFromLocalhdfs dfs -moveFromLocal 本地文件 HDFS路径hdfs dfs -moveFromLocal /tmp/log.txt /logs/上传后删除本地文件(不可逆!谨慎使用) 场景:将本地测试文件
wc.txt上传到 HDFS:
- 原因:临时目录
hdfs dfs -put /home/wc.txt /user/root 5.2.2 目录操作(创建 / 查看)
① 创建目录
- 单级目录:
hdfs dfs -mkdir /input # 在HDFS根目录创建input文件夹多级目录(递归创建):
hdfs dfs -mkdir -p /user/root/logs/2025/05 # 一次性创建嵌套目录,无需逐级创建② 查看目录内容
- 基础查看(单层):
hdfs dfs -ls /user/root # 显示该目录下的文件和子目录递归查看(所有层级):
hdfs dfs -ls -R /user # 列出user目录下所有文件,包括深层嵌套的子目录5.2.3 文件内容查看(解决 Web 界面报错!)
当 Web 界面点击文件显示 “无法预览” 时,Shell 命令是最佳解决方案:
-
hdfs dfs -cat /user/root/wc.txt # 直接在终端显示文本文件内容 hdfs dfs -head /large.log # 查看大文件前1KB内容(避免Web界面加载超时) hdfs dfs -tail -f /access.log # 实时追踪日志文件新增内容(类似Linux的tail -f)5.3 数据传输命令:本地↔HDFS 双向交互
5.3.1 HDFS→本地(下载文件)
-
hdfs dfs -get /user/root/output.txt ~/downloads/ # 下载单文件到本地指定目录 hdfs dfs -getmerge /part-* ~/merged.txt # 合并HDFS分片文件后下载(如MapReduce输出结果)5.3.2 HDFS 内部操作(文件搬家 / 复制)
- 移动文件(重命名 / 调整路径):
hdfs dfs -mv /old/wc.txt /new/wordcount.txt # 在HDFS内移动文件并改名复制文件(备份 / 迁移):
hdfs dfs -cp /user/root/wc.txt /backup/ # 将文件复制到backup目录5.4 高级操作:权限管理与文件维护
5.4.1 权限控制(避免访问报错)
HDFS 权限语法与 Linux 一致,支持
chmod和chown:hdfs dfs -chmod 755 /user/root # 赋予所有者读写执行权限,其他用户只读执行 hdfs dfs -chown hadoop:hadoop /data # 修改文件所有者为hadoop,所属组为hadoop5.4.2 删除操作(谨慎!)
- 删除文件:
hdfs dfs -rm /user/temp.txt # 删除单个文件删除目录(含子内容):
hdfs dfs -rm -r /user/old_data # 递归删除目录,删除后进入回收站(默认保留24小时) hdfs dfs -rm -r -skipTrash /user/delete_now # 不进回收站,直接永久删除(生产环境慎用!)5.4.3 空间与状态查看
hdfs dfs -df -h / # 查看HDFS整体空间使用情况(总容量/已用/剩余,-h参数让显示更友好) hdfs dfs -du -h /user/root # 查看指定目录下各文件大小(人类可读格式)5.5 实战案例:用 Shell 命令完成 WordCount 全流程
假设 HDFS 中已有
/user/input/wc.txt,演示如何用命令完成统计并查看结果: -
上传文件(若未上传):
hdfs dfs -put /home/wc.txt /user/input运行 WordCount(输入输出均在 HDFS):
-
hadoop jar /opt/installs/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.1.jar wordcount /user/input/wc.txt /user/output - 查看结果(解决 Web 界面无法显示):
hdfs dfs -cat /user/output/part-r-000005.6 避坑指南:命令常见错误及解决
报错信息 原因 解决方法 File exists: /user/root/wc.txt目标路径文件已存在 先删除: hdfs dfs -rm /user/root/wc.txtNo such file or directory路径拼写错误 / 文件未上传 用 hdfs dfs -ls确认路径正确性Permission denied权限不足 修改权限: hdfs dfs -chmod 777 目标文件Cannot create directory多级目录未加 -p参数改用 -mkdir -p创建嵌套目录5.7 命令速查表(建议截图保存!)
功能分类 命令 语法示例 说明 文件上传 puthdfs dfs -put local.txt /hdfs/本地→HDFS,保留原文件 目录创建 mkdir -phdfs dfs -mkdir -p /a/b/c递归创建多级目录 文件查看 cathdfs dfs -cat /hdfs/file.txt显示文本文件内容 下载文件 gethdfs dfs -get /hdfs/file.txt local/HDFS→本地,单文件下载 权限修改 chmodhdfs dfs -chmod 755 /hdfs/dir修改文件 / 目录权限 递归操作 -R参数hdfs dfs -ls -R /对所有子目录生效 5.8 总结:Shell 命令的核心价值
掌握 HDFS Shell 命令后,你将拥有:
- 脱离 Web 界面限制:直接通过终端高效操作,避免图形化界面的功能局限;
- 脚本自动化能力:为后续编写数据处理脚本(如定时上传日志、清理旧数据)打下基础;
- 分布式思维培养:理解数据在本地与 HDFS 之间的流动,为全分布集群操作做准备。
- 建议将常用命令整理成备忘录,遇到报错时对照「避坑指南」排查。下一部分我们将进入Yarn 配置,完成完整的 Hadoop 伪分布环境(含计算资源调度),敬请期待!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









