






背景:
为什么从SparkStreaming入手?
因为SparkStreaming 是Spark Core上的一个子框架,如果我们能够完全精通了一个子框架,我们就能够更好的驾驭Spark。SparkStreaming和Spark SQL是目前最流行的框架,从研究角度而言,Spark SQL有太多涉及到SQL优化的问题,不太适应用来深入研究。而SparkStreaming和其他的框架不同,它更像是SparkCore的一个应用程序。如果我们能深入的了解SparkStreaming,那我们就可以写出非常复杂的应用程序。
SparkStreaming的优势是可以结合SparkSQL、图计算、机器学习,功能更加强大。这个时代,单纯的流计算已经无法满足客户的需求啦。在Spark中SparkStreaming也是最容易出现问题的,因为它是不断的运行,内部比较复杂。
本课内容:
1,SparkStreaming另类在线实验
这个另类在线实验体现在batchInterval设置的很大,5分钟甚至更大,为了更清晰的看清楚Streaming运行的各个环境。
实验内容是使用SparkStreaming在线统计单词个数,SparkStreaming连接一个端口中接收发送过来的单词数据,将统计信息输出到控制台中,其中使用netcat创建一个简单的server,来开启并监听一个端口,接收用户键盘输入的单词数据。
2,瞬间理解SparkStreaming的本质
结合这个实验并通过观察Web UI上的Job,Stage,Task等信息,再结合SparkStreaming的源码,对SparkStreaming进行分析。
实验环境说明:
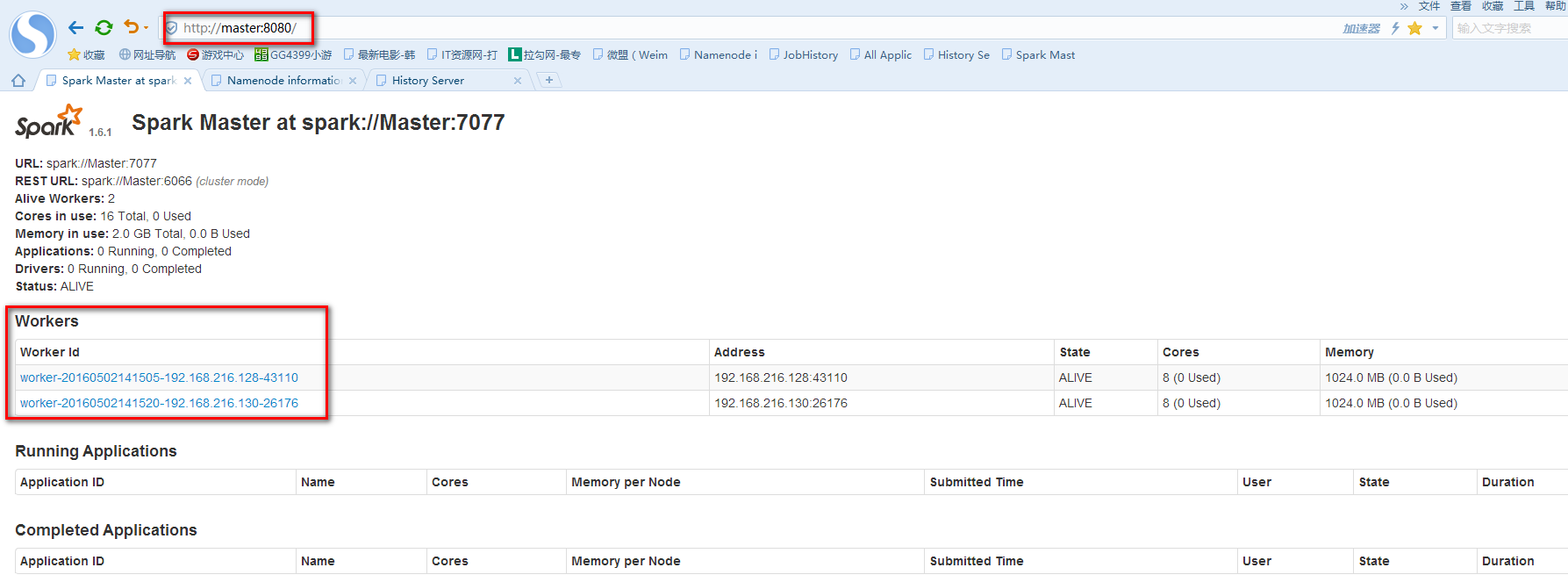
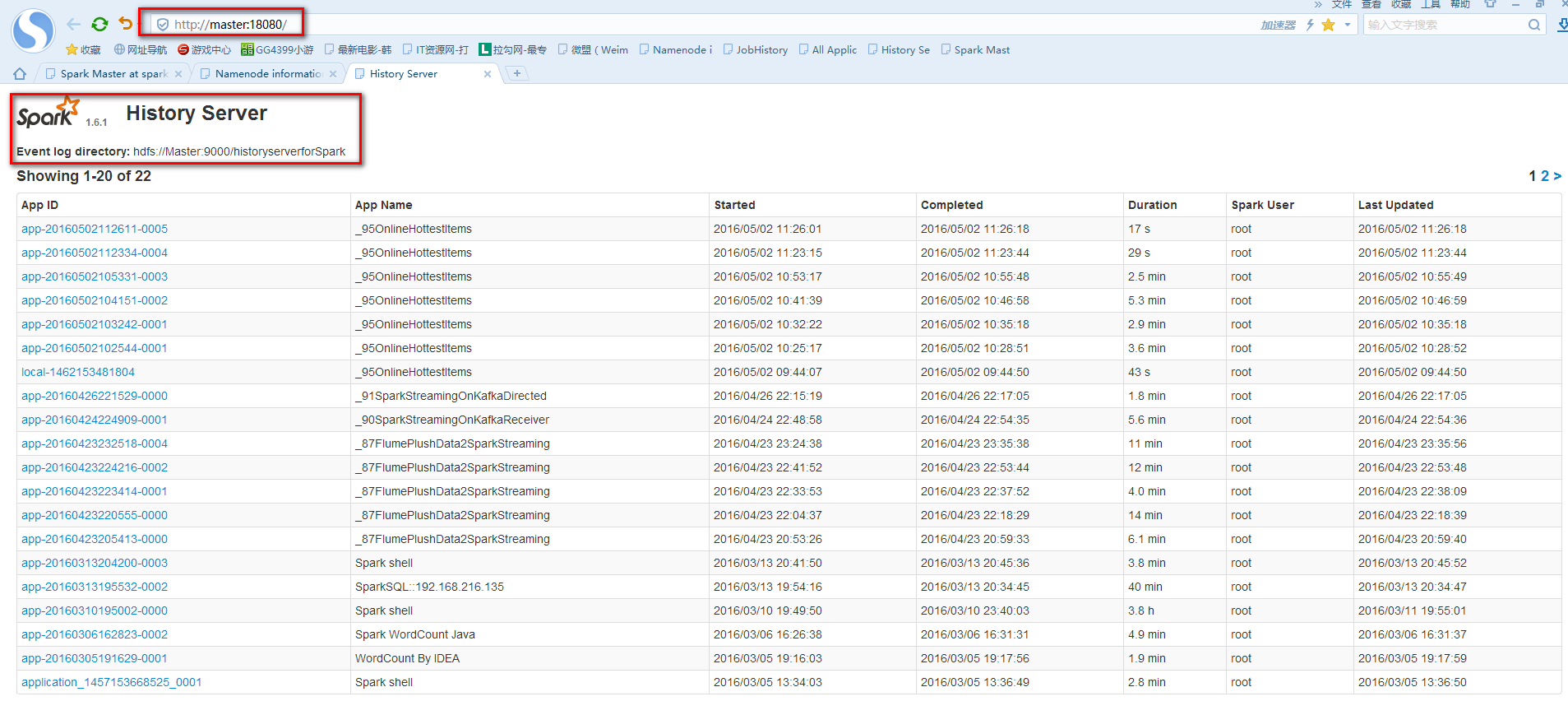
实验由3台Ubuntu14.04虚拟机上运行,其中一台作为Spark的Master,另外两台作为Spark的Worker。使用的Spark版本为目前最先版1.6.1,Spark checkpoint的存储在HDFS上(hadoop的版本为2.6.0)。为了记录SparkStreaming运行的过程信息,需要启动Spark的HistoryServer,以下是启厅Spark,HDFS,HistoryServer服务的脚本。

通过使用JPS观察各节点的进行信息,或通过浏览器访问各个服务WEB页面来确认服务是否正确运行。



实验代码如下

提交到Spark集群的脚本如下

首先在Master节点使用nc -lk 9999,创建一个简单的Server,然后在运行脚本提交Spark Application。
单词统计结果如下
















 1488
1488

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









