







本章内容已经合并到了Kafka之Broker、Producer和Consumer知识点汇总
消费者详解
消费方式
- pull:默认采用 pull(拉)模式,从 broker 中读取数据。pull 模式不足之处是,如果 kafka 没有数据,消费者可能会陷入循环中,一直返回空数据。针对这一点,Kafka 的消费者在消费数据时会传入一个时长参数 timeout,如果当前没有数据可供消费,consumer 会等待一段时间之后再返回,这段时长即为 timeout。
- push:push(推)模式很难适应消费速率不同的消费者,因为消息发送速率是由 broker 决定的。它的目标是尽可能以最快速度传递消息,但是这样很容易造成 consumer 来不及处理消息,典型的表现就是拒绝服务以及网络拥塞。而 pull 模式则可以根据 consumer 的消费能力以适当的速率消费消息。
消费者组概念
Consumer Group(CG):消费者组,由多个consumer组成。同一个组内消费者的group.id相同。
- 消费者组内每个消费者负责消费不同分区的数据,一个分区只能由一个组内消费者消费。
- 消费者组之间互不影响。所有的消费者都属于某个消费者组,即消费者组是逻辑上的一个订阅者。
- 如果向消费组中添加更多的消费者,超过主题分区数量,则有一部分消费者就会闲置,不会接收任何消息。
消费者组初始化流程
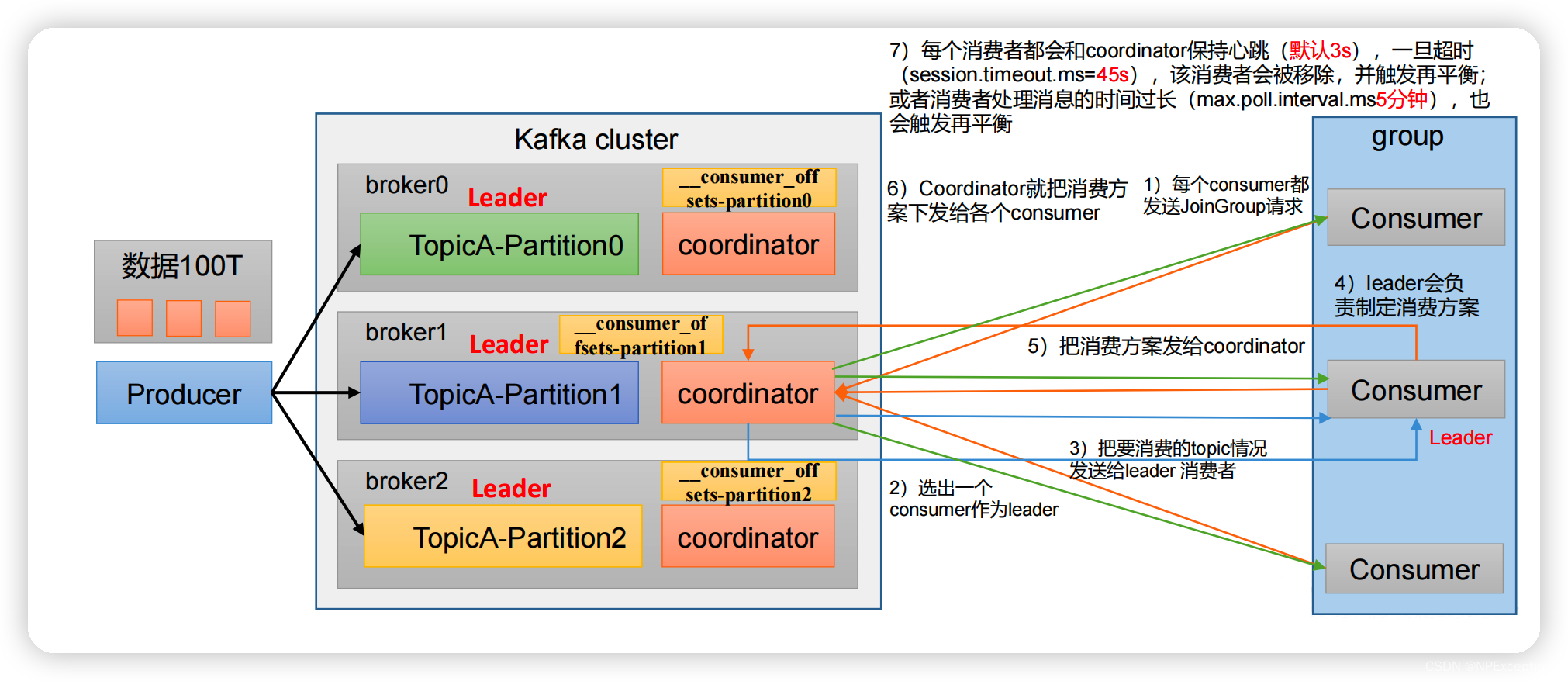
- 每个consumer都向kafka发送JoinGroup请求。
- coordinator选出一个consumer作为leader。
- coordinator把要消费的topic情况发送给leader消费者。
- 消费者leader会负责制定消费方案。
- 消费者leader把消费方案发给coordinator。
- coordinator就把消费方案下发给同组的consumer。
- 每个消费者都会和coordinator保持心跳(默认3s),一旦超时(
session.timeout.ms=45s),该消费者会被移除,并触发再平衡;或者消费者处理消息的时间过长(max.poll.interval.ms=5分钟),也会触发再平衡。
消费者组消费流程
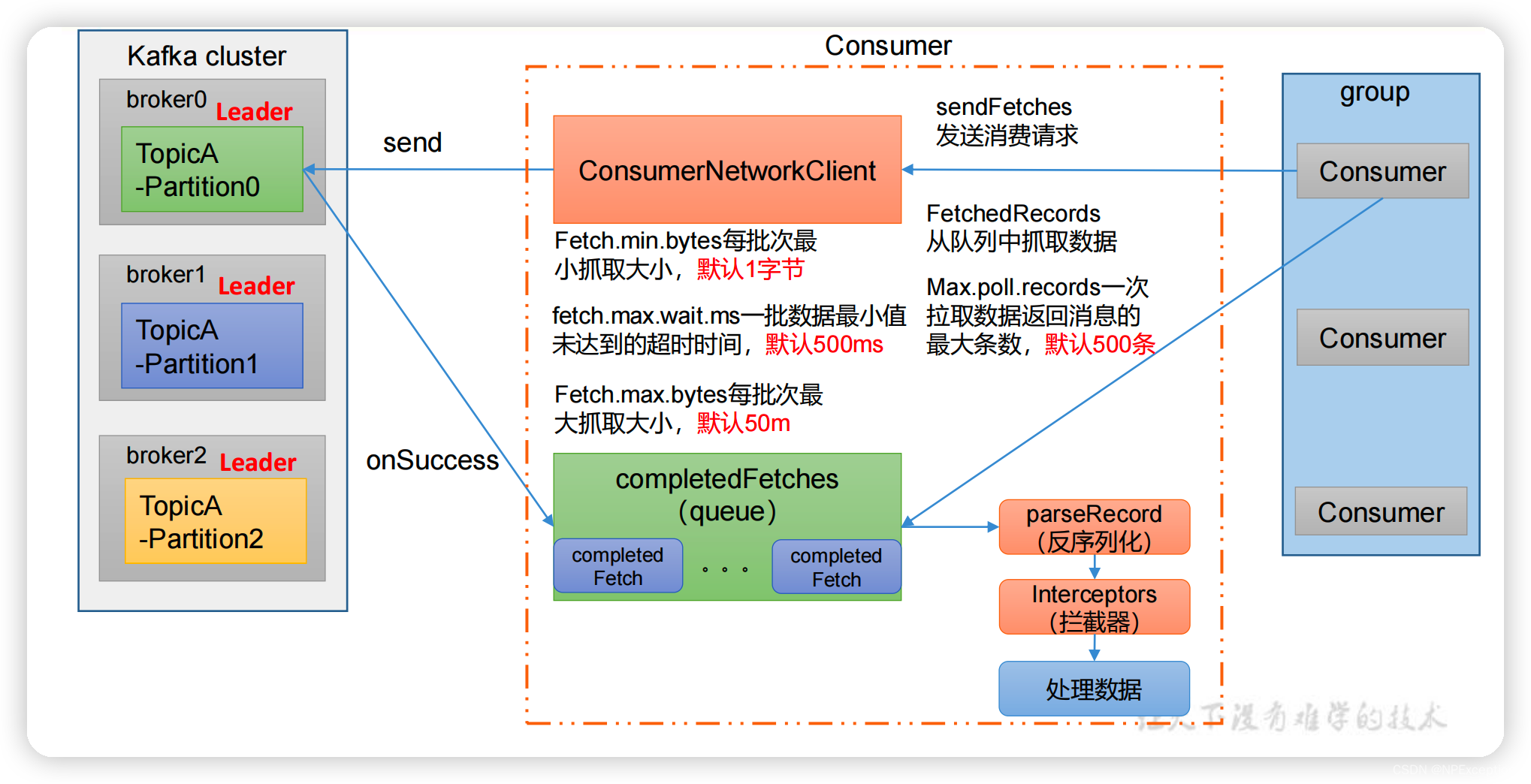
消费者网络客户端将消费请求发送给Kafka,Kafka根据指定分区主题的offset往下取数据并返回,并将消费到到最大位置的offset提交到__consumer_offsets,网络客户端将获取到消息经过反序列化器和拦截器返回到消费者。
消费者分区分配策略
Kafka可以同时使用多个分区分配策略,通过partition.assignment.strategy配置消费者分区分配策略,可选策略如下:
- Range
- RoundRobin
- Sticky
- CooperativeSticky
Range
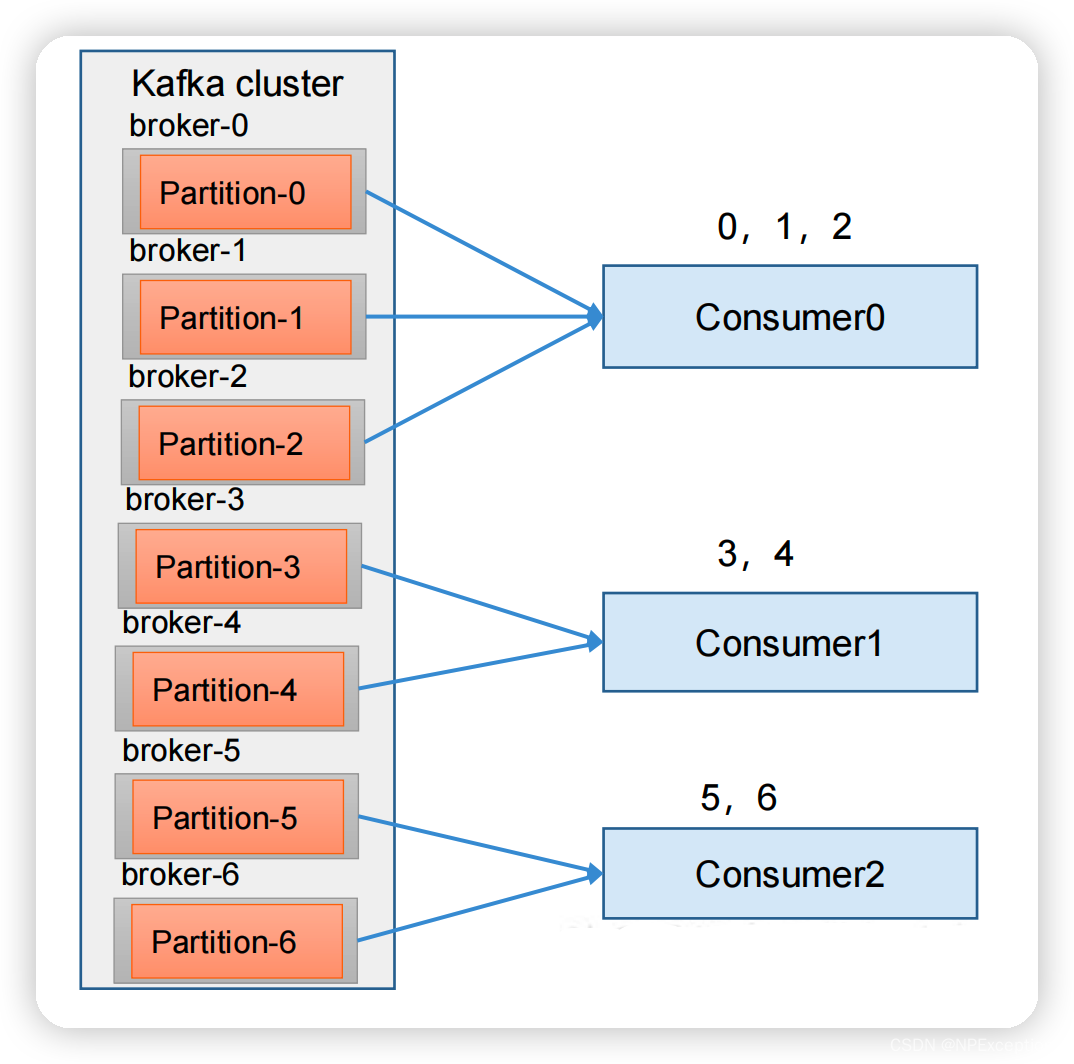
Range 是对每个 topic 而言的。首先对同一个 topic 里面的分区按照序号进行排序,并对消费者按照字母顺序进行排序。
通过 partitions数/consumer数 来决定每个消费者应该消费几个分区。如果除不尽,那么前面几个消费者将会多消费 1 个分区。
缺点:如果只是针对 1 个 topic 而言,C0消费者多消费1个分区影响不是很大。但是如果有N多个 topic,那么针对每个 topic,消费者 C0都将多消费 1 个分区,topic越多,C0消费的分区会比其他消费者明显多消费 N 个分区。容易产生数据倾斜!
个人猜想:Range分区分配策略存在数据倾斜问题,但官方默认的默认分区分配策略是Range + CooperativeSticky,根据从官网的解读理解,先按照Range进行分区分配,再平衡期间允许消费者尽可能的保持Range原先分配的分区,但是有一些为了平衡不得不迁移一些原本分配的分区到另外的消费者。

RoundRobin
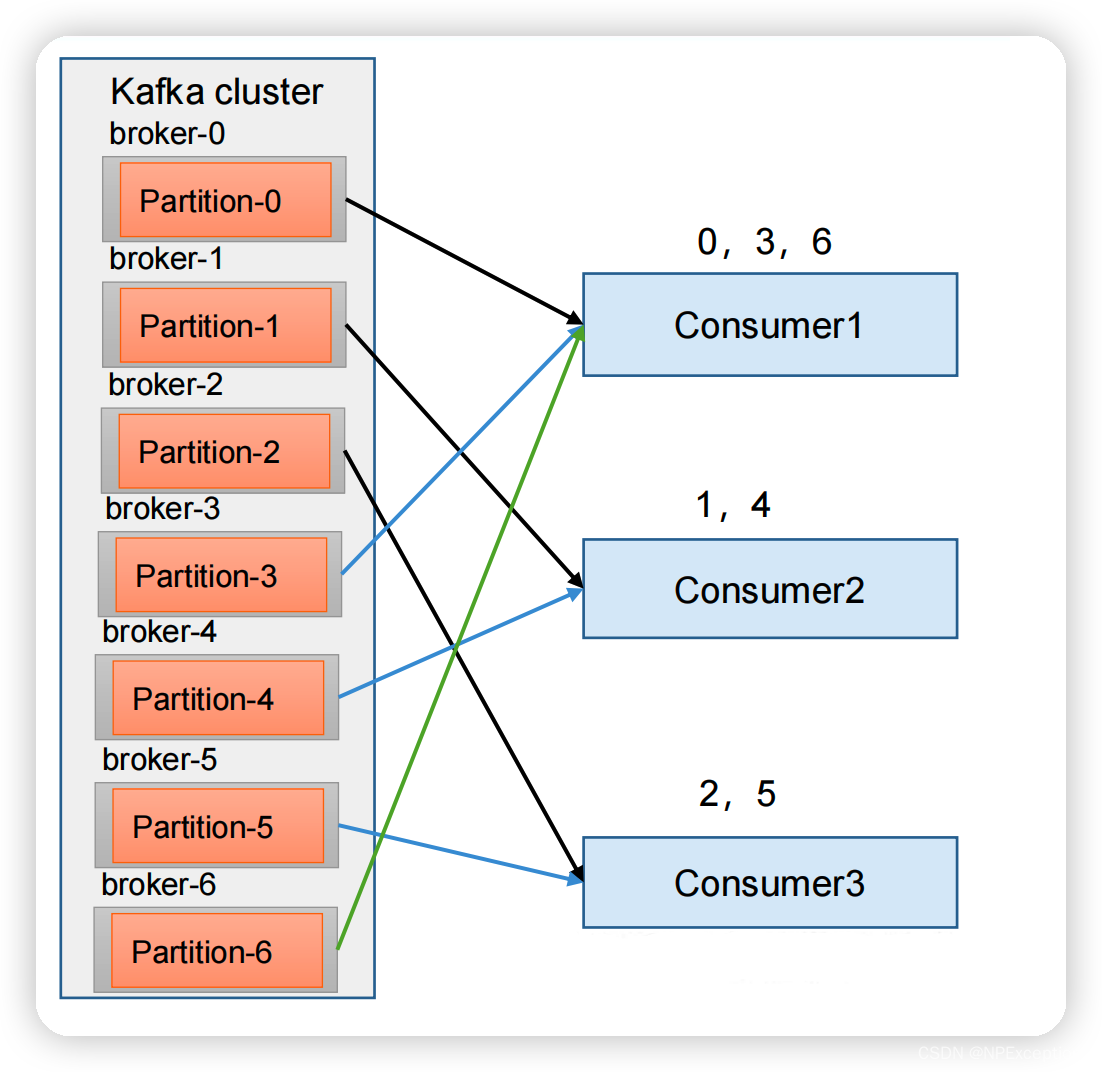
RoundRobin 针对集群中所有Topic而言。RoundRobin 轮询分区策略,是把所有的partition 和所有的consumer 都列出来,然后按照 hashcode 进行排序,最后通过轮询算法来分配partition 给到各个消费者。
Sticky
粘性分区定义:可以理解为分配的结果带有粘性的。即在执行一次新的分配之前,考虑上一次分配的结果,尽量少的调整分配的变动,可以节省大量的开销。
例如,消费者C0、C1和C2按照Sticky分别消费的分区是:
C0:0,1,3
C1:2,4
C2:5,6
当C0消费者超时或者挂了之后,C1和C2将会分担C0的0,1和3分区的消费,按照Sticky策略再平衡之后的消费方案如下:
C0:GG了
C1:2,4,0,3
C2:5,6,1
对C1和C2原本的分配分案尽量少的调整分配的变动。
粘性分区是 Kafka 从 0.11.x 版本开始引入这种分配策略,首先会尽量均衡的放置分区到消费者上面,在出现同一消费者组内消费者出现问题的时候,会尽量保持原有分配的分区不变。
CooperativeSticky
官方解释:遵循与StickyAssignor相同的(粘性的)赋值逻辑,但允许在StickyAssignor遵循即时的再平衡协议时进行合作再平衡。
翻译过来就是分区分配策略和Sticky策略一样,但是不同点就是,自动平衡的时候可以和其他分配或者自定义分区分配策略进行合作。换言之就是Sticky加强版,或者说是用官方的话就是Sticky的合作版本。
offset 的默认维护位置
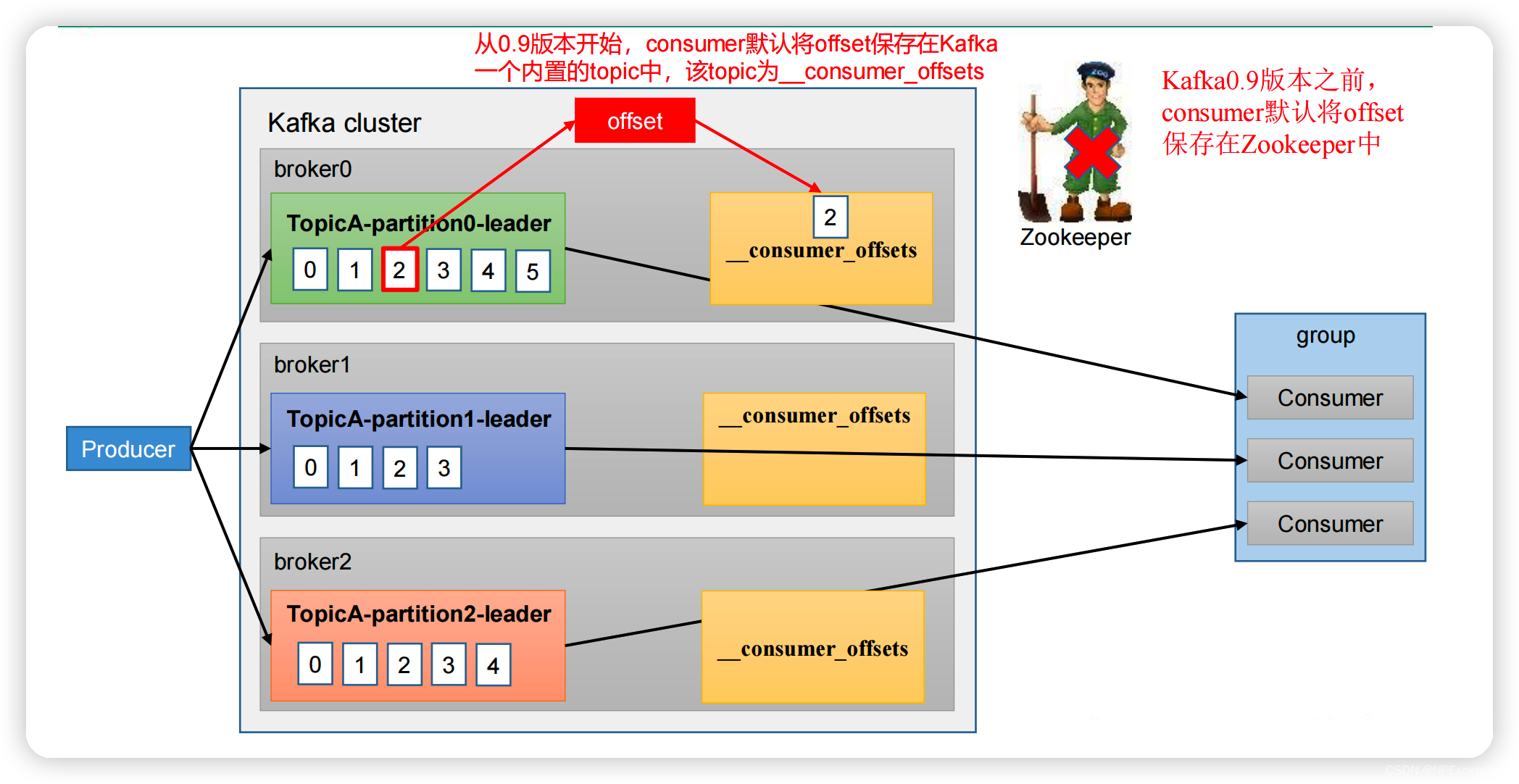
__consumer_offsets 主题里面采用 key 和 value 的方式存储数据。key 是group.id+topic+分区号,value 就是当前 offset 的值。每隔一段时间,kafka 内部会对这个topic 进行compact,也就是每个 group.id+topic+分区号就保留最新数据。
自动提交 offset
为了使我们能够专注于自己的业务逻辑,Kafka提供了自动提交offset的功能。自动提交offset的相关参数如下:
- enable.auto.commit:是否开启自动提交offset功能,默认是true。
- auto.commit.interval.ms:自动提交offset的时间间隔,默认是5s。
手动提交 offset
虽然自动提交offset十分简单便利,但由于其是基于时间提交的,开发人员难以把握offset提交的时机。因此Kafka还提供了手动提交offset的API。
手动提交offset的方法有两种:
- commitSync(同步提交):必须等待offset提交完毕,再去消费下一批数据。
- commitAsync(异步提交) :发送完提交offset请求后,就开始消费下一批数据了。
两者的相同点是,都会将本次提交的一批数据最高的偏移量提交;不同点是,同步提交阻塞当前线程,一直到提交成功,并且会自动失败重试(由不可控因素导致,也会出现提交失败);而异步提交则没有失败重试机制,故有可能提交失败。
漏消费
先提交offset后,消费者消费数据之前线程挂了,造成数据的漏消费。
重复消费
先消费数据,在offset提交之前线程挂了,消费者服务重新启动后会造成数据重复消费。
消费者事务
如果想完成Consumer端的精准一次性消费,那么需要Kafka消费端将消费过程和提交offset过程做原子绑定,即消费者事务。消费者消费数据和提交offset要么一起提交,要么都不提交。
消费者事务可以和SpringBoot事务等其他支持事务的框架一起使用 。
消费者配置列表
| 配置项 | 描述 |
|---|---|
| bootstrap.servers | 消费者连接集群所需的 broker 地 址列表,多个用逗号分隔。 |
| key.deserializer | key序列化所用到的反序列化器。 |
| value.deserializer | key序列化所用到的反序列化器。 |
| group.id | 消费者所属的消费者组。 |
| enable.auto.commit | 默认值为 true,消费者会自动周期性地向服务器提交偏移量。 |
| auto.commit.interval.ms | 如果设置了 enable.auto.commit 的值为 true, 则该值定义了消费者偏移量向 Kafka 提交的频率,默认 5s。 |
| auto.offset.reset | 当偏移量被重置(不存在)时采取的策略。 官网解释:当Kafka中没有初始偏移量或者当前偏移量在服务器上不存在(例如,因为数据已经被删除)该怎么办: earliest:自动重置偏移量到最早的偏移量。 latest:默认,自动重置偏移量为最新的偏移量。 none:如果消费组原来的(previous)偏移量 不存在,则向消费者抛异常。 anything:向消费者抛异常。 |
| offsets.topic.num.partitions | __consumer_offsets 的分区数,默认是 50 个分区。 |
| session.timeout.ms | Kafka 消费者和 coordinator 之间连接超时时间,默认 45s。超过该值,该消费者被移除,消费者组执行再平衡。 |
| heartbeat.interval.ms | Kafka 消费者和 coordinator 之间的心跳时间,默认 3s。 该条目的值必须小于 session.timeout.ms ,也不应该高于session.timeout.ms 的 1/3。 |
| max.poll.interval.ms | 消费者处理消息的最大时长,默认是 5 分钟。超过该值,该消费者被移除,消费者组执行再平衡。 |
| fetch.min.bytes | 默认 1 个字节。消费者获取服务器端一批消息最小的字节数。 |
| fetch.max.wait.ms | 默认 500ms。如果没有足够的数据立即满足fetch.min.bytes给出的要求,服务器在响应获取请求之前阻塞的最长时间。 |
| fetch.max.bytes | 默认50M,获取请求返回的最大字节数,最小值1024。 如果服务器端一批次的数据大于该值仍然可以拉取回来这批数据,因此,这不是一个绝对最大值。一批次的大小受 message.max.bytes (broker config)or max.message.bytes (topic config)影响。 |
| max.poll.records | 一次 poll 拉取数据返回消息的最大条数,默认是 500 条。 |
| partition.assignment.strategy | 消 费 者 分 区 分 配 策 略 , 默 认 策 略 是 Range + CooperativeSticky。Kafka 可以同时使用多个分区分配策略。 策略可选值有:Range、RoundRobin、Sticky、CooperativeSticky。 |















 4134
4134











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











