







环境准备
- java环境
- kafka环境
- kafka-clients jar包
或者依赖:
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>2.8.0</version>
</dependency>
Kafka 生产者发送原理
kafka producer读取外部数据通过main线程给拦截器(Interceptors),拦截器发送给序列化器(Serializer),序列化器发送给分区器(Partitioner),分区器将数据发送给消息记录累加器(RecordAccumulato),记录累加器使用多个队列来缓存数据,(默认大小为32m,即buffer.memory),当每个队列的数据达到batch.size(默认16k)配置的大小或者等待linger.time(默认为0ms)时间后,sender线程就会将满足条件的队列数据封装成一个个请求通过选择器(Selector)发送给kafka,默认每个broker只能缓存5个未应答的请求(即max.in.flight.requests.per.connection)。成功发送kafka后,kafka会将接收到的数据同步给副本并且给选择器(Selector)应答发送结果。如果应答结果是成功,则删除对应的数据请求和清空对应队列的数据,如果应答结果是失败,则将数据请求进行重试retries次(默认Integer.MAX_VALUE)。
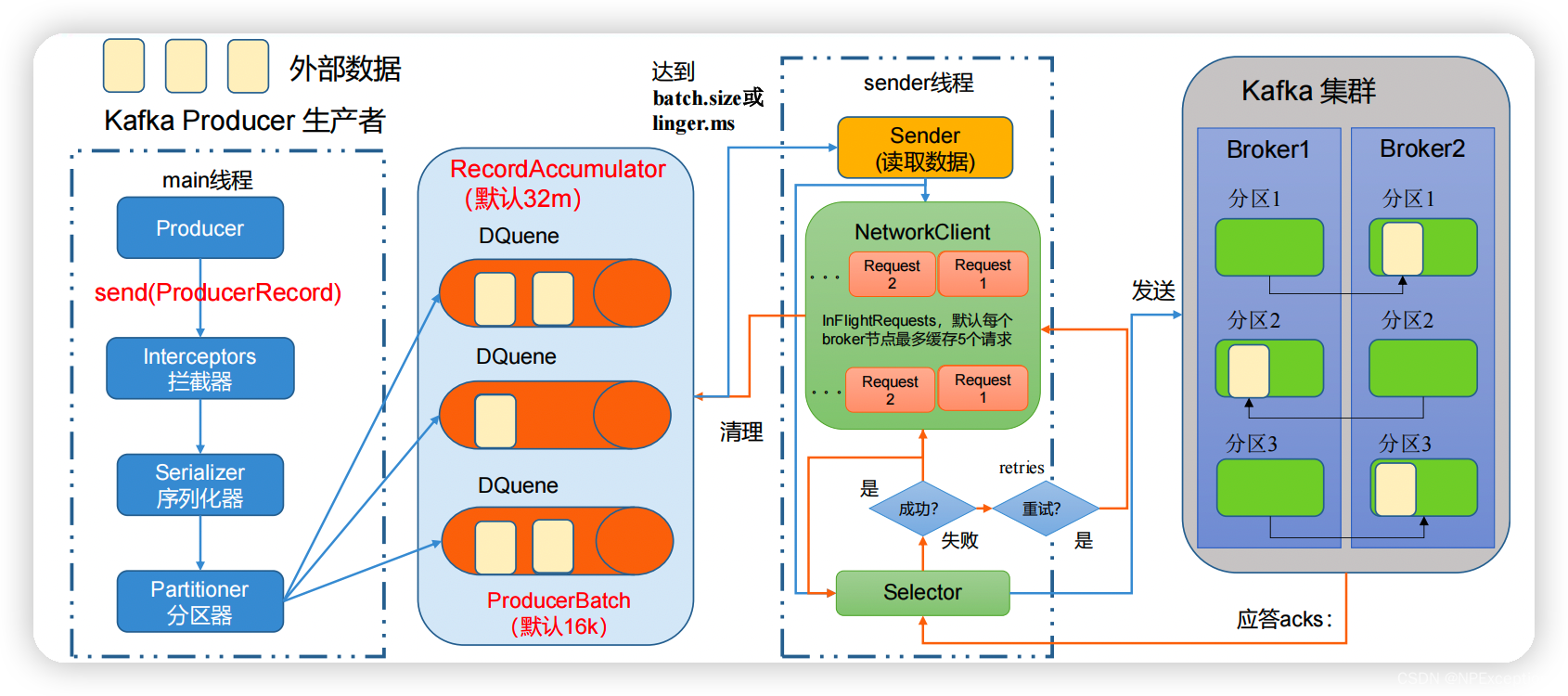
kafka应答producer策略:
0:生产者发送过来的数据,不需要等数据落盘应答。
1:生产者发送过来的数据,Leader 收到数据后应答。
-1(all):生产者发送过来的数据,Leader和ISR队列里面的所有节点同步数据后应答。默认值是-1,-1 和all 是等价的。
kafka生产者API
需要用到的类:
KafkaProducer:需要创建一个生产者对象,用来发送数据。
ProducerConfig:获取所需的一系列配置参数。
ProducerRecord:每条数据都要封装成一个 ProducerRecord 对象。
使用java api之前先使用命令创建一个test_topic主题,指定为3个分区和3个副本(kafka虽然会自动创建主题,但是默认创建的主题默认1个分区和一个副本。
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 3 --partitions 3 --topic test_topic
小试牛刀
package com.huazai.kafka.example;
import org.apache.kafka.clients.producer.*;
import java.util.Properties;
import java.util.UUID;
import java.util.concurrent.CountDownLatch;
/**
* @author pyh
* @date 2021/7/25 12:43
*/
public class CustomProducer {
private final static String TOPIC = "test_topic";
private final static Integer COUNT = 100;
public static void main(String[] args) throws Exception {
Properties properties = new Properties();
// kafka连接地址,多个地址用“,”隔开
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, KafkaConstant.KAFKA_CLUSTER_ADDRESS);
/*
消息发送到broker之后的应答策略:
0:生产者发送过来的数据,不需要等数据落盘应答。
1:生产者发送过来的数据,Leader 收到数据后应答。
-1(all):生产者发送过来的数据,Leader+和 isr 队列里面的所有节点收齐数据后应答。默认值是-1,-1 和
应答策略,all相当于-1
*/
properties.put(ProducerConfig.ACKS_CONFIG, "all");
// sender线程将RecordAccumulator队列中的数据请求发送给broker之后失败的重试次数,默认Integer.MAX_VALUE
properties.put(ProducerConfig.RETRIES_CONFIG, Integer.MAX_VALUE);
// 每个分区未发送消息总字节大小(单位:字节),超过设置的值就会提交数据到服务端
properties.put(ProducerConfig.BATCH_SIZE_CONFIG, 16384);
// 如果数据在队列中迟迟未达到 batch.size的大小(默认16KB),sender线程等待 linger.time 之后就会发送数据。linger.time默认为0,则batch.size参数无效
properties.put(ProducerConfig.LINGER_MS_CONFIG, 1);
// RecordAccumulator 缓冲区大小(默认32M)
properties.put(ProducerConfig.BUFFER_MEMORY_CONFIG, 33554432);
// 序列化key所用到的类
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
// 序列化value所用到的类
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
/*
生成程序生成的所有数据的压缩类型。 默认为none(即没有压缩)。
有效值为none、gzip、snappy、lz4、zstd。 压缩是全批的数据,因此批处理的效果也会影响压缩比(批处理越多意味着压缩越好)。
*/
properties.put(ProducerConfig.COMPRESSION_TYPE_CONFIG, "snappy");
// 指定自定义分区器
// properties.put(ProducerConfig.PARTITIONER_CLASS_CONFIG, "com.huazai.kafka.example.producer.CustomPartitioner");
KafkaProducer<String, String> producer = new KafkaProducer<String, String>(properties);
CountDownLatch countDownLatch = new CountDownLatch(COUNT);
for (int i = 0; i < COUNT; i++) {
// 生产者异步发送方式
producer.send(new ProducerRecord<>(TOPIC, null, "test_topic " + UUID.randomUUID() + "-" + i), new Callback() {
@Override
public void onCompletion(RecordMetadata recordMetadata, Exception e) {
// 没有异常,表示发送成功
if (e == null) {
System.out.println("异步发送消息所在分区:" + recordMetadata.partition() + ",偏移量:" + recordMetadata.offset());
}
// 回调一遍倒数一遍,直至循环完才让主线程继续往下走
countDownLatch.countDown();
}
});
// 生产者同步发送方式
// RecordMetadata recordMetadata = producer.send(new ProducerRecord<>(TOPIC, "", "test_topic " + UUID.randomUUID() + "-" + i)).get();
// System.out.println("同步发送消息所在分区:" + recordMetadata.partition() + ",偏移量:" + recordMetadata.offset());
}
// 由于kafka是异步发送的,需要等到发送回调完成之后才能让程序结束,否则程序提前结束会导致发送失败。
countDownLatch.await();
System.out.println("发送完毕!");
producer.close();
}
}
启动程序之前先执行消费者命令监控消息消费情况。
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test_topic
启动程序,客户端监控结果如下:

java控制台结果如下:
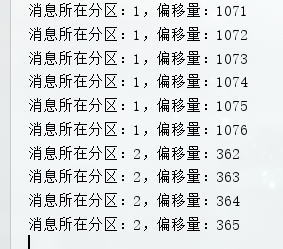
既没有指定也没有指定partition情况下,默认采用分区策略中的轮询策略分别向不同的分区发送消息。
分区策略测试
分区策略:
- 指明 partition 的情况下,直接将指明的值直接作为 partiton 值;
- 没有指明 partition 值但有 key 的情况下,将 key 的 hash 值与 topic 的 partition 数进行取余得到partition 值;
- 既没有partition值又没有key值的情况下,Kafka采用Sticky Partition(黏性分区器),会随机选择一个分区,并尽可能一直使用该分区,待该分区的batch已满或者已完成,Kafka再随机一个分区进行使用(和上一次的分区不同)。
// 指定发送消息的key为“hello world”
producer.send(new ProducerRecord<>(TOPIC, "hello world", "test_topic " + UUID.randomUUID() + "-" + i), new Callback() {
@Override
public void onCompletion(RecordMetadata recordMetadata, Exception e) {
// 没有异常,表示发送成功
if (e == null) {
System.out.println("异步发送消息所在分区:" + recordMetadata.partition() + ",偏移量:" + recordMetadata.offset());
}
// 回调一遍倒数一遍,直至循环完才让主线程继续往下走
countDownLatch.countDown();
}});
在以上代码中指定了key为“hello world”,key的hash值与 topic 的 partition数进行取余得到partition 值。

经过几次程序的反复调用,结果都是向同一个分区发送数据。
编写自定义分区器:
package com.huazai.kafka.example;
import org.apache.kafka.clients.producer.Partitioner;
import org.apache.kafka.common.Cluster;
import org.apache.kafka.common.PartitionInfo;
import java.util.List;
import java.util.Map;
import java.util.Random;
/**
* 自定义分区器
* @author pyh
* @date 2021/7/28 23:50
*/
public class CustomPartitioner implements Partitioner {
/**
*
* @param topic 主题
* @param key key值
* @param keyBytes key值字节
* @param value value值
* @param valueBytes value值字节码
* @param cluster 集群信息
* @return
*/
@Override
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
// 获取指定主题可用分区集合
List<PartitionInfo> partitionInfos = cluster.availablePartitionsForTopic("test_topic");
return partitionInfos.size() - 1;
}
@Override
public void close() {
}
@Override
public void configure(Map<String, ?> map) {
}
}
在CustomProducer类中添加以下配置使用指定的自定义分区器
// 指定自定义分区器
properties.put(ProducerConfig.PARTITIONER_CLASS_CONFIG, CustomPartitioner.class.getName());
自定义分区使用了最大分区数(3)减1,得到发送的分区数为2,结果如下:

遇到的问题
连接超时
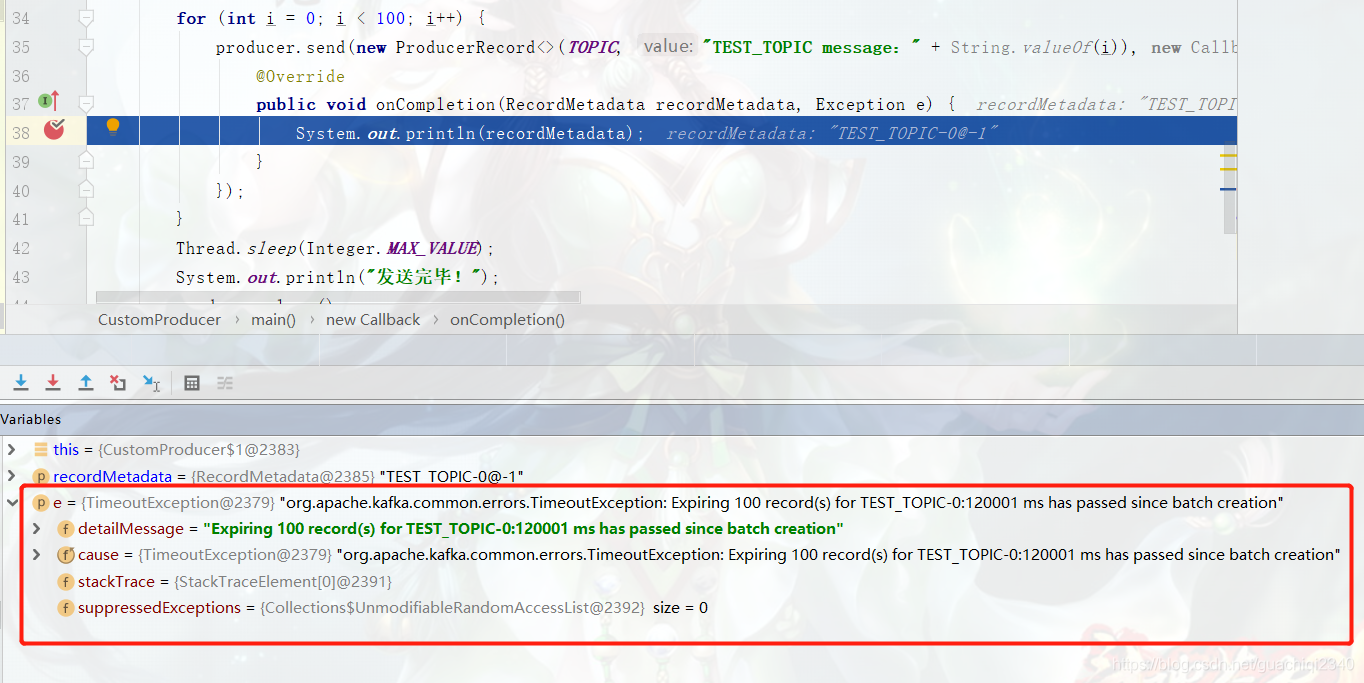
解决方案:
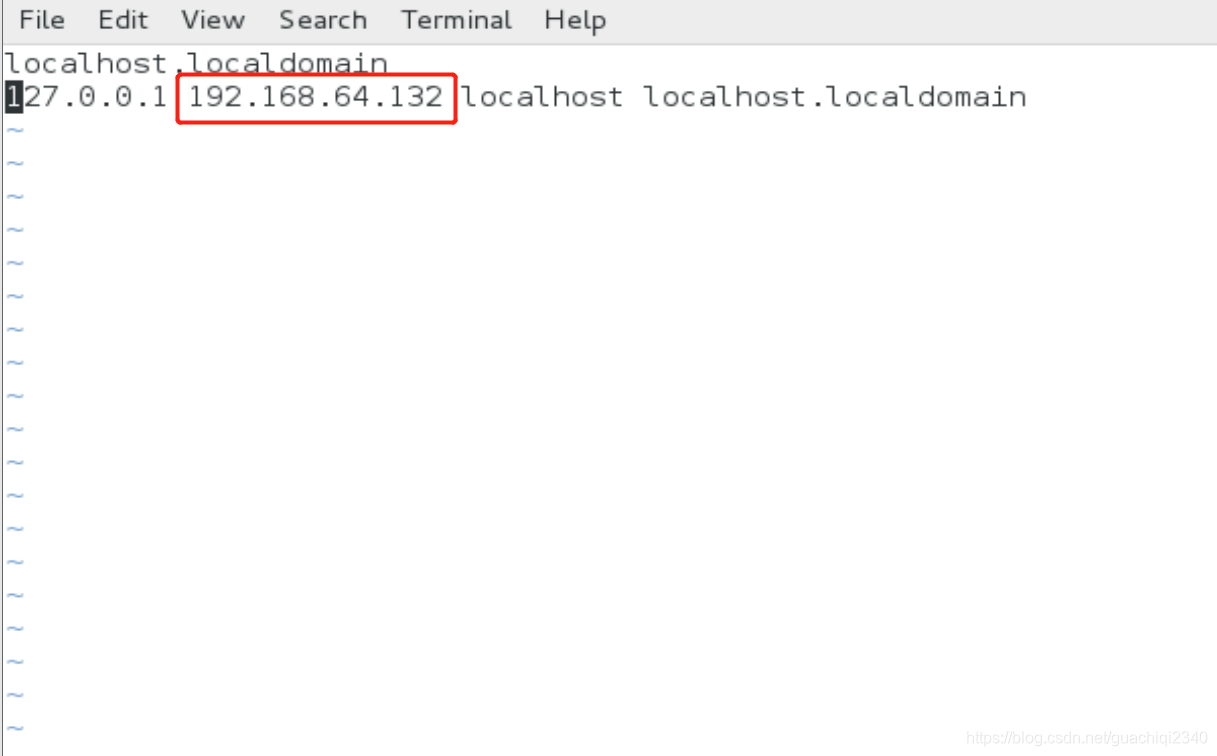
- 在kafka/config目录下的server.properties配置advertised.listeners或listeners的ip地址需与kafka所在主机的hostname保持一致)
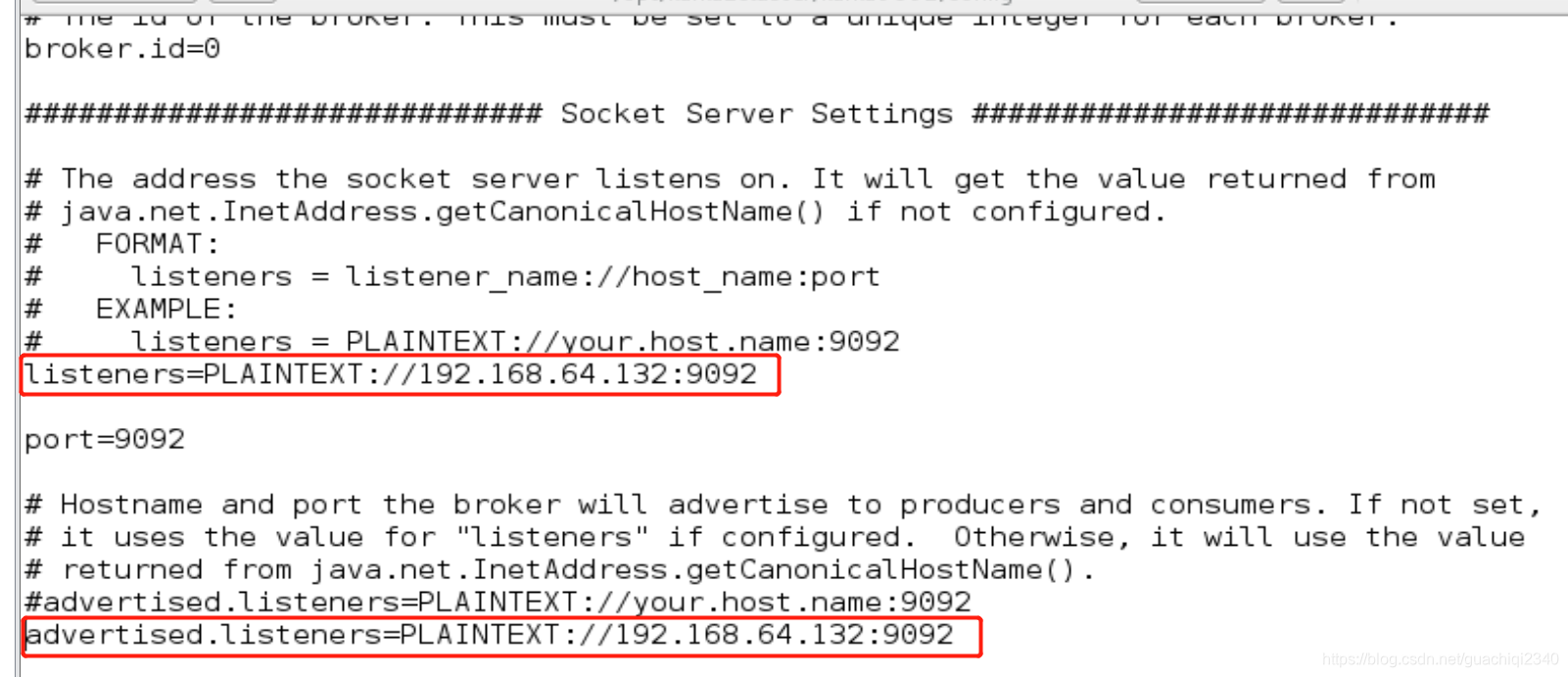
- 网络问题。检查/etc/hosts中的主机ip映射的hostname与配置的listeners中的hostname是否保持一致。
















 2185
2185











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











