









2020美赛C题:python实现npl自然语言处理记录
前言
此次2020美赛一共4天,最后一天通宵完成论文,总算在早上九点钟之前完成了代码。以下是简单记录我在完成代码时遇到的一些困难和解决办法
文本预处理
参考代码:
主要参考代码
使用nltk对文本进行分词删除停止词等预处理,使得一条评论被若干有意义的词代替。我的电脑停止词地址:C:\Users\Lenovo\AppData\Roaming\nltk_data\corpora\stopwords
可以自己制作停止词,我用的是文件里的english停止词作为原本,以及我自己添加的关于吹风机评论中常出现的意义的词,做成了一个新的停止词:hair_dryer
遇到的问题,在使用spacy下的指定包时,用pip直接下载失败,不知道具体什么原因,但是后来自己在网页上下载了之后用指定命令本地安装成功了。指定命令也很玄乎,在这里耽误了很多时间:spacy下的load(‘en’)
LDA主题分析加可视化
LDA模型建立见上一篇参考代码
多进程程序需写进main函数
在实现主体分类后还对模型的复杂度和一致性得分进行了计算,在执行一致性得分是出现了错误,最后发现是我的代码不在main函数里所以无法执行多进程程序。最后的解决方法参照:
多进程程序需写进main函数
计算模型困惑度
在LDA模型建立后进行了困惑度计算模型准确性
困惑度和一致性
可视化
参考代码:pyLDAvis可视化参考代码
主题分析结果感觉玄乎,主要看个人理解,而且每次跑出来的记过都不一样。放在论文中主要是因为他有两个可视化,显得非常高级。提升LDA主题分类的方法我暂时没有想到。
错误解决
使用和LDA模型一起的那篇文章的可视化方法,我在使用pyLDAvis可视化时遇到了一个很大的困难,困难详情和解决方法见我的求助帖:python吧
最后是换了一个思路进可视化,原来的可能是因为我没有下载jupyter note。所以最后只能使用网址打开结果,而不是从本地的工具中打开。
ps:按照贴吧里的方式打开IIS后,C盘用户文件夹出现了一个新的用户:DefaultAppPool
NLTK情感分析
参考代码:对推特里的评论进行情感分析
制作语料包
使用和实验数据同类型的语料才能得到较为准确的结果。在这里我们将原推特语料包进行了更改,但是我最终还是没有得到较为准确 的结果,可能是语料不够丰富,爬虫暂时还没有学习。
在这次比赛中我是直接修改了推特语料包,但是其实自己做一个新的文档就可以了,将代码的import twitter_samples更改为新创建的语料文件夹,然后将积极和消极分别放在两个.json下。该文件夹放在C:\Users\Lenovo\AppData\Roaming\nltk_data\corpora 目录下就行了
from nltk.corpus import twitter_samples
情感积极性量化
原代码中只实现了输出了评论的积极性,要么是积极要么是消极。我对其进行了一写改动,计算了每一个积极词语或消极词语出现频率,最后用积极频率-消极频率生成了情感积极度。使用了以下的代码作为启发:情感积极度计算
一些收获
python查错
首先是关于python代码错误提示的查找方法。我以往查错一般都只查找到自己写的代码的层面。通过这一次我发现有时候你的代码没有错的,错误出现在原本的包函数中,这个时候我们要顺着python错误提示的函数继续往下找。为什么下载的包中的函数也会有错误呢,一类是你的windows系统不支持某种语法(见:[Errno 2] No such file or directory: ‘nul’),一类是他包中有一些函数更改了名字,执行的时候只认识更改后的名字,但是你的包没有改名。
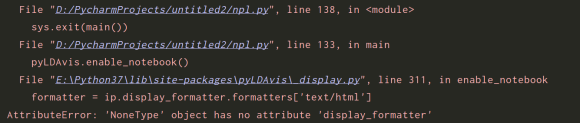
下图是我做pyLDAvis时遇到的错误提示
美赛感悟
一个重点,美赛不需要支撑材料
我们的情感积极性分析结果十分差强人意,在最后一天的白天我几乎都在调整语料包试图提高准确度。很遗憾,最后失败了。然后。。。。。。
我只能说还好不需要支撑材料,我们最后附录里都没放一点代码。
团队分工不要太明确了。这样会让每个人都很孤独,很累
这次比赛是在线上进行的,这使得我们的交流变得更加的困难。而且每个人之间的分工变得更加的独立。
讲实话这一次的论文很多地方我都没看过一遍,我只修改了部分模型的建立和填写了模型的求解答案。以及最后一个晚上写了结论。其余的时间我都在与代码进行抗争。但是在最后的论文中体现我代码的部分其实并不多,虽然每一个结果都需要我量化之后的情感度再计算,但是一想到我们代码运行出的数据准确性奇低,我就觉得我其实在论文中没做多少贡献。如果使用我的数据结果进行计算,会发现我们做的大部分合理猜想都没法得到验证,所以。。。。。。
我的其他两个队友,一个队友是基本写完了所有论文的主要部分。还有数据筛选,简单计算。而且大部分的模型都是由她一个人想出来的,我只在前两天经常参与了讨论,提供了一些想法。
另外一个队友主要是翻译,这次因为支气管炎的问题又无法在语音中交流,所以她在建模方面基本没有提供想法。一些不涉及建模主要思想的论文部分由她来完成,且兼任做图做表等。
美赛与国赛
相比上次国赛在一起思考,并且可以互相提供帮助,这一次的完全分工给人的感觉太差了。我们都是物联网专业的,本来的优势就是技能限制不大所以可以互相提供帮助,在这一次比赛中完全没有用到。
这一次比国赛使用的时间也多了很多,除去吃饭睡觉我们基本上都在做建模,而且吃饭睡觉的时间也很短暂,每天都是一点以后或者两点睡,七点多起。最后一天还通宵了。
还是很怀念国赛在一起每天有那么多时间可以思考吃什么,还可以到处串门打听敌情的时光。
数学建模
之后我们队伍没有再参加比赛了,因为没有训练所以建模的能力一直在退化。后来我作为论文写手和其他两个人组队去参加了一次华数杯,拿了二等奖但其实这个比赛水平不高,题目也基本靠文字建模,答案不靠边编的厉害也能上。真正热爱数学建模的不是靠这比赛的两三天来学习 ,还是需要长期的积累与团队多次的训练磨合。而国赛才是真正检验一个队伍水平的比赛,美赛其实都不能完全说明水平。可能有些队伍在论文上面很精彩,拿了其他大大小小的很多奖,但是国赛却从来没拿过,这可能就要思考是不是模型太过理想空洞而忽略了建模的本身:如何高效合理的去解决问题。















 380
380











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









