







一、朴素贝叶斯算法详解
朴素贝叶斯算法的关键就是这个朴素贝叶斯公式
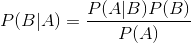
朴素贝叶斯算法适用于文本分类,最后是要知道,这个文本属于每一个类别的概率,属于哪一个类别的概率最大,就是属于那个类别
所以现在y是类别标签是下面的classVec,x是他的特征属性,就是下面的postingList,
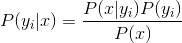
这个公式的精华在于假设每个属性之间是相互独立的所以才有了下面的公式
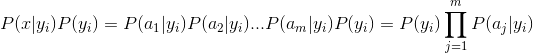
二 、算法的实际计算
条件概率p(x|y)的计算吗,当他是离散值的时候,很容易就是计算出来的他的概率,也就是p(x|y),x中的每个特征的p(x|y)相加
当特征属性为连续值时,通常假定其值服从高斯分布(也称正态分布)。即:
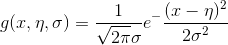
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1353
1353











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









