






《数据迁移》
漫步于数据的海洋
在实验中静静感受这些数据迁移的魅力
动手所到之处
都是一段代码
与终端交织而成的盛宴
by 光城
前面文章写了MySQL的插入,亿级数据的快速插入方法,以及MySQL入库HBase的策略方案。
本节则是在上述基础上做的更加高端的一部。同时对MySQL入库HBase做一个总结。
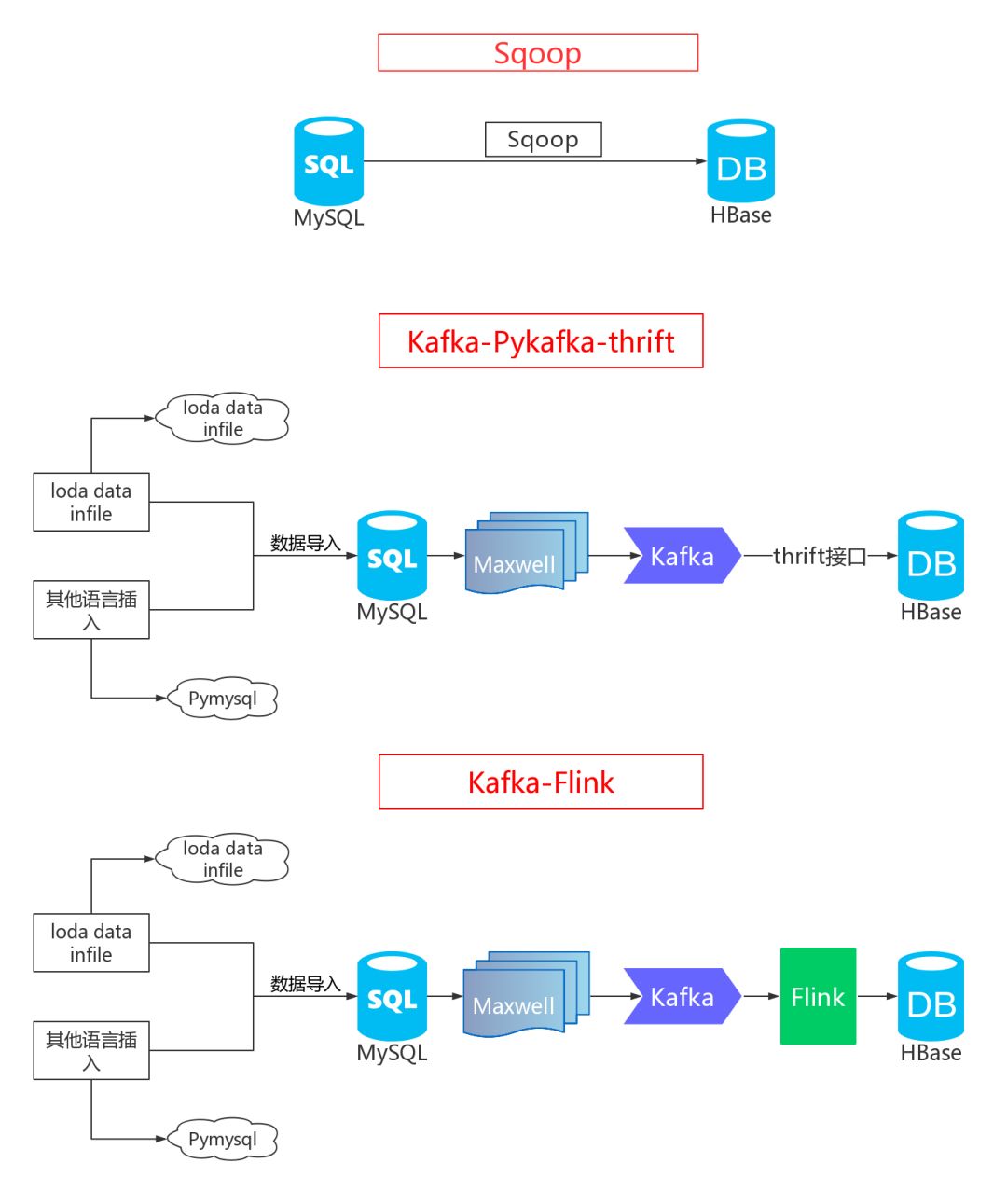
回顾之前,先给大家放一个我的总体框架图:
1
初出茅庐
初出茅庐

使用Sqoop,直接将MySQL同步HBase,天真啊,一个Sqoop能搞定?好用?
经过我的实践证明,小数据完全没问题,那这个成亿数据,就问题大了去了,很多人用这个根本完成不了这个需求,不过我完成了。
怎么做的呢?
如果直接输入Sqoop命令去导入,经过一段时间,就卡了,根本无法全部导入完毕,于是乎,分片导入思想诞生了,写个bash脚本,放在服务器或者自己机器上跑即可。
怎么分片?
这个就是所谓的1亿数据的分开插入,每次只针对一小部分数据使用Sqoop,做个循环,直到这一亿数据导入完,那新的问题又来。
速度如何保证?
如果分片,速度自然无法保证,这虽然完成了上述的需求,但是导入完毕的效率非常低,当时导入1.8亿条耗时70多个小时,大家可以看到效率多么低了吧,有没有解决办法?
当然有,接下来进入,第二个方案。
2
小有成就
小有成就

在使用Sqoop后,binlog与kafka大吼一声,我来也,对没错,第二个思路就是,使用maxwell提取binlog的增删改查操作,然后发送到kafka的监听的topic上,再通过Python的pykafka库对数据进行消费,利用thrift接口进行sink,也就是存入数据库,哈哈,听了这么多,我都晕死了。
那速度如何呢?
这个速度当然快了啊,如果使用Python操纵HBase单条插入,那就非常慢了,但是比上述的要快,是不是还有批量插入呢,没错,里面有个批量插入,直接可以实现2-3秒的2万数据导入,实现高效率导入,这个最终耗时可从原来的70多个小时到7个小时左右,直接提高了10倍!
生命不息,奋斗不止;
速度不够,不断调整。
3
游刃有余
游刃有余

接着我们来到了第三个方案,那就是Kafka-Flink,这个简直非常好的一个思路,上述方案二提供了Python入库,那么对于大数据来说,更多的是使用Java,于是就查资料,学习,就get到Flink这个点子上了,这个同步过程实际上就是ETL,算是数据仓库的一部分吧,上游的数据经过Flink做各种计算,过滤,再到下游,进行业务处理,那这个就是标准的数据仓库作业。
对于方案三,详细阐述一下,前面不变,依旧使用maxwell提取binlog,后面使用kafka消费后,通过Flink进行sink到HBase,Flink在这个中间起到一个过滤、map、求和等等的操作,我们可以通过Flink按照自己给定的时间来进行数据的sink,最后数据就抵达了下游,从MySQL真正实时同步到HBase。
那么问题来了,效率呢?
当然快的可怕,1s至少1w的速度,你们觉得1亿数据得多快。
漫步于数据的海洋
在实验中静静感受这些数据迁移的魅力
动手所到之处
都是一段代码
与终端交织而成的盛宴
















 477
477











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









