






Hive部署及两种启动方式
0.导论
Hive是什么?
Facebook解决海量日志数据的分析而开发了Hive,后来开源给了Apache软件基金会。
The Apache Hive ™ data warehouse software facilitates reading, writing, and managing large datasets residing in distributed storage using SQL.
Hive是一种用类SQL语句来协助读写、管理那些存储在分布式存储系统上大数据集的数据仓库软件。
Hive特点?
最大特点:可避免写MapReduce程序分析数据,直接可以通过类SQL来分析。
Hive是将数据映射成数据库和一张张的表,库和表的元数据信息一般存在关系型数据库上(比如MySQL)。
数据存储方面:存储很大的数据集,数据完整性、格式要求并不严格。
数据处理方面:Hive语句会生成MapReduce任务去计算,故不适用于实时计算的场景,它适用于离线分析。
Hive安装?
这里我使用MySQL作为Hive的元数据库,所以大家需要有个MySQL数据库。
关于MySQL安装就不赘述了,Hive安装如下:
https://mirrors.cnnic.cn/apache/hive/hive-3.1.1/
下载上述的Hive,解压缩后,修改配置文件:hive-site.xml。
按照下面配置即可(只需要修改下面相关的配置)。
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://city:3306/hive?createDatabaseIfNotExist=true&amp;useSSL=false</value>
<description>
JDBC connect string for a JDBC metastore.
To use SSL to encrypt/authenticate the connection, provide database-specific SSL flag in the connection URL.
For example, jdbc:postgresql://myhost/db?ssl=true for postgres database.
</description>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
<description>username to use against metastore database</description>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>root</value>
<description>password to use against metastore database</description>
</property>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/hive/warehouse</value>
<description>hive default warehouse, if nessecory, change it</description>
</property>
</configuration>
配置环境变量
vi ~/.bashrc
#Hive
export HIVE_HOME=/usr/local/hive
export PATH=$PATH:$HIVE_HOME/bin
生效
source ~/.bashrc
初始化元数据库
schematool -dbType mysql -initSchema
1.CLI连接
直接输入:
./hive/bin/hive
或者输入:
./hive/bin/hive --service cli
2.HiveServer2/beeline
这种方式需要配置一些文件,有点复杂,并且容易出问题,下面一起来看。
对于这个启动需要修改hadoop文件夹下的hdfs-site.xml与core-site.xml文件。
2.1 修改hdfs-site.xml配置文件
打开这个配置文件,并加入下面内容!
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
2.2 修改core-site.xml配置文件
下面加入两条配置信息,来设置hadoop的代理用户!
hadoop.proxyuser.hadoop.hosts配置成*的意义,表示任意节点使用 hadoop 集群的代理用户 hadoop 都能访问 hdfs 集群。
hadoop.proxyuser.hadoop.groups 表示代理用户的所属组。
<property>
<name>hadoop.proxyuser.hadoop.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.hadoop.groups</name>
<value>*</value>
</property>
首先启动hiveserver2:
输入:hiveserver2

紧接着输入:
beeline -u jdbc:hive2://localhost:10000 -n hadoop
-n表示指定的用户名。如果没有权限,会提示输入密码之类的。
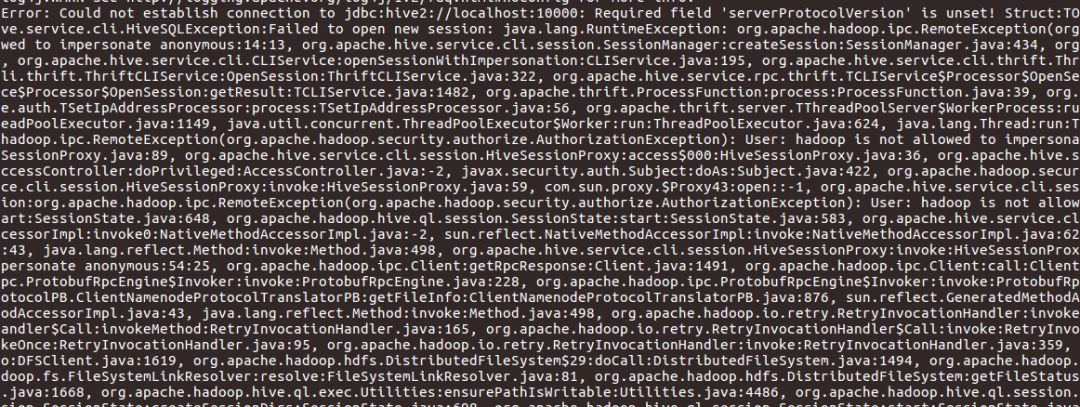
输入密码后,发现连接不上(ps:如果你没有问题,那就直接跳过下面这个问题解决办法),针对此问题如下解决办法:
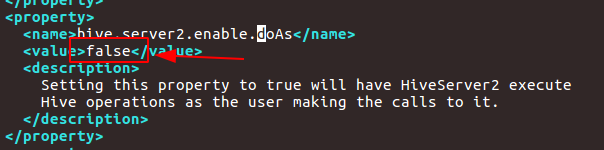
进入hive的conf目录,找到doAs配置,改为false即可!
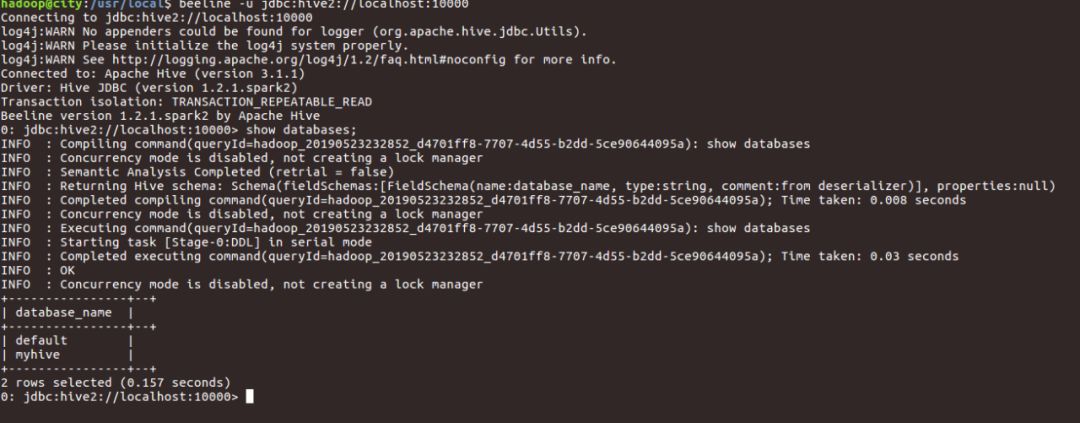
再次输入:
beeline -u jdbc:hive2://localhost:10000 -n hadoop
验证是否连接成功:
show databases
成功后,会看到至少一个default数据库名,这样就成功了!
除了上述方法之外,还可以直接先进入beeline,再对数据库进行连接。
如下图所示:
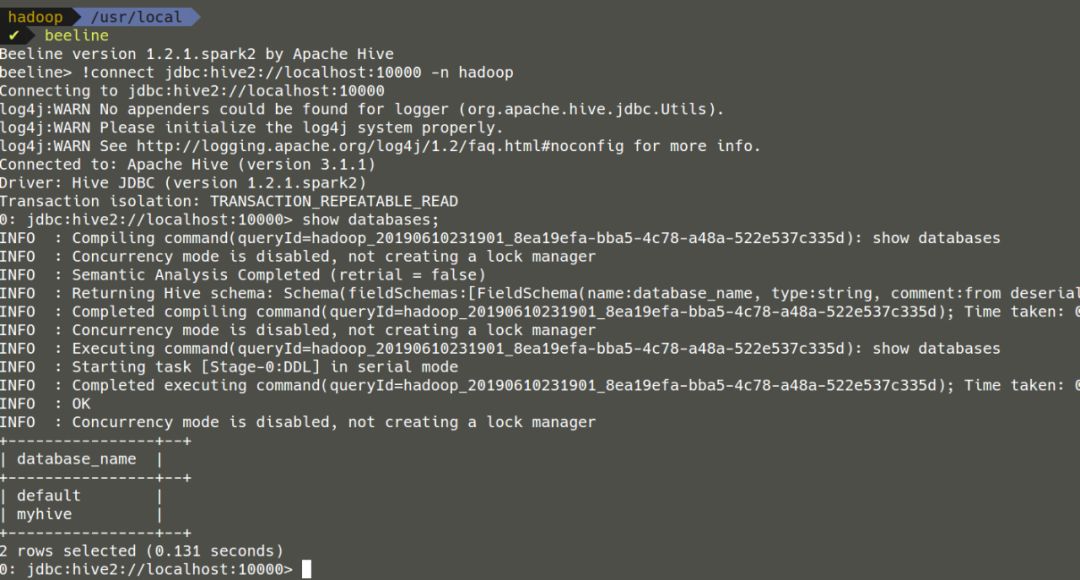
至此,数据库连接就完成了。
















 147
147











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









