






大家好,我是 「微扰理论」,目前在 Hashdata 担任数据库内核研发工程师。
前言
在计算机和半导体产业发展了许多年之后,摩尔定律已经越来越接近于理论上的物理极限;免费的午餐结束了。而为了继续提高计算机的性能,处理器厂商纷纷引入了多核架构。
为了更好地利用现代多核架构下的计算资源;PG 9.6 也终于正式引入并行查询的能力;其中并行顺序扫描 (parallel sequential scan) 则是 PG 引入的第一个并行化的算子。在 PG 9.6 之前,PG 开发者们也花了几年的时间去讨论和构建支持并行化的一些基础设施;包括动态共享内存、共享内存队列、后台工作进程等;我们在之前的文章中已经进行了相关内容的介绍。在最近发布的 PG 15 中,大部分只读的算子都已经部分或全部支持了并行化。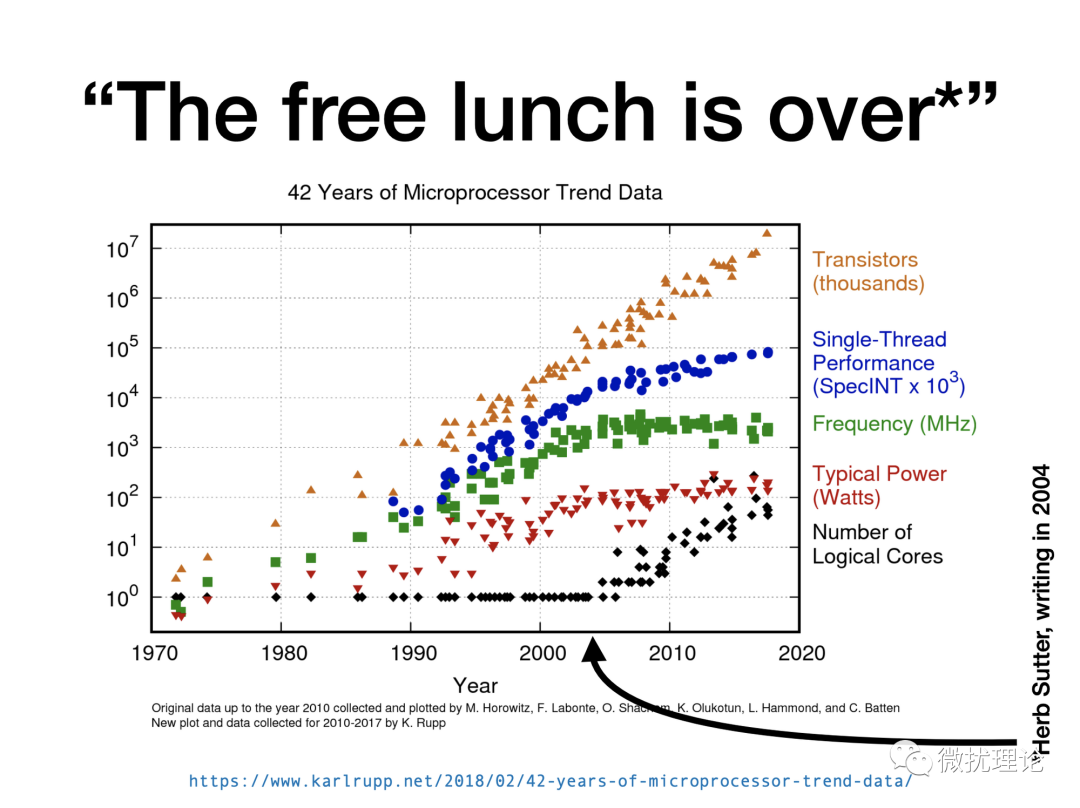 微扰酱最近的主要工作都集中在 PG 并行化算子实现的调研上,今天就来分享一下 PG 中最简单也是最早被支持的并行顺序扫描算子的实现细节。
微扰酱最近的主要工作都集中在 PG 并行化算子实现的调研上,今天就来分享一下 PG 中最简单也是最早被支持的并行顺序扫描算子的实现细节。
一个简单的例子
首先我们来看一个简单的例子;这个例子也是微扰酱这几天调试代码反复使用的查询语句。
-- encourage use of parallel plans
postgres=# set parallel_setup_cost=0;
postgres=# set parallel_tuple_cost=0;
postgres=# set min_parallel_table_scan_size=0;
postgres=# set max_parallel_workers_per_gather=4;
-- prepare test table
postgres=# create table test(t int);
postgres=# insert into test select * from generate_series(1, 1000);
-- explain the query
postgres=# explain select * from test;
QUERY PLAN
---------------------------------------------------------------------
Gather (cost=0.00..9.17 rows=1000 width=4)
Workers Planned: 2
-> Parallel Seq Scan on test (cost=0.00..9.17 rows=417 width=4)
(3 rows)正常来说,在比较小的表中,PG 是不会生成并行的查询计划的;所以为了使得 PG 生成并行查询计划,我们设置了几个相关的 GUC 值;包括:
parallel_setup_cost 是初始化并行环境的成本;在 PG 中默认设置为1000,是一个很大的值。
parallel_tuple_cost 是并行扫描每个元组的成本。
min_parallel_table_scan_size 是表扫描启用并行化的最低阈值;默认为 8 MB。
max_parallel_workers_per_gather 是 gather 操作的最大并行度。
这样,在生成的查询计划中,我们就可以看到 Workers Planned: 2 了;这意味着整个查询计划有两个 worker 参与扫描。由于查询计划最上层是 Gather 算子,根据火山模型,整个查询便由 Gather 驱动。Gather 算子于 leader 进程上执行,从共享内存中的队列获取由另外两个工作进程放入的消息并从中解析出元组信息,通过 shm_mq_receive 实现;两个工作进程则依次启动并对数据表竞争读,将元组打包成消息放入队列中,通过 shm_mq_send 实现 。
下面,我们读具体过程进行详述。先贴上在 leader 进程、 worker 进程和 master 进程中执行的一些关键函数和调用关系并提供了详细的注释;供大家对照后文阅读。
执行器调用过程
leader
ExecGather()
// 这里生成工作进程的计划;在本例中 worker 进程最顶层的算子为 SeqScan
ExecInitParallelPlan()
ExecParallelInitializeDSM()
ExecSeqScanInitializeDSM()
LaunchParallelWorkers() // 这一步将创建工作进程
foreach work loop:
RegisterDynamicBackgroundWorker()
SendPostmasterSignal // 通知 postmaster;由 postmaster 创建工作进程
// setup tuple queue readers to read results
ExecParallelCreateReaders()
// 获取下一条数据
gather_getnext()
while (gatherstate->nreaders > 0 || gatherstate->need_to_scan_locally)
gather_readnext() // 从某个 reader 读取一个元组
for(;;)
// 轮询 reader,读完一个再读下一个; 如果某个 reader 未能成功初始化,则不返回任何元组
reader = gatherstate->reader[gatherstate->nextreader]
TupleQueueReaderNext() // 从 queue reader 里获取元组
shm_mq_receive() // 从 queue 中获取一条消息
// try read
while (!mqh->mqh_length_word_complete)
res = shm_mq_receive_bytes()
// 如果当前 reader 被 detach 了,移除当前reader;如果所有全部完成,需要关闭 workers
if (readerdone)
if (gatherstate->nreaders == 0)
ExecShutdownGatherWorkers()
ExecParallelFinish()
// 需要等待工作进程结束;似乎是通过工作进程调用 pq_putmessage('X', NULL, 0) 完成的
WaitForParallelWorkersToFinish()
if (tup) return tup
// tuple 为空不阻塞;尝试读下一个 reader
gatherstate->nextreader++
// 返回投影
return ExecProject()worker
ParallelWorkerMain()
dsm_attach() // 绑定到 dsm segment
dsm_create_descriptor()
shm_toc_attach()
// set parallel state
shm_toc_lookup(toc, PARALLEL_KEY_FIXED, false)
before_shmem_exit(ParallelWorkerShutdown, PointerGetDatum(seg)) // 注册退出回调函数
// attach error queue
shm_mq_set_sender()
shm_mq_attach(mq, seg, NULL)
// send BackendKeyData message
pq_beginmessage(&msgbuf, 'K');
// restore database connection
BackgroundWorkerInitializeConnectionByOid()
// restore state; protected by transaction
RestoreLibraryState()
RestoreGUCState()
RestoreComboCIDState()
// attach per-session segment
AttachSession()
RestoreTransactionSnapshot()
...
EnterParallelMode()
entrypt(seg, toc); // actuall is ParallelQueryMain
// setup DestReceiver, SharedExecutorInstrumentation and QueryDesc
ExecParallelGetReceiver() // 这一步很重要,后面 tqueueReceiveSlot 要用
shm_toc_lookup(toc, PARALLEL_KEY_INSTRUMENTATION, true)
ExecParallelGetQueryDesc()
// 执行器初始化
ExecParallelInitializeWorker()
ExecSeqScanInitializeWorker()
table_beginscan_parallel()
RestoreSnapshot() // 从序列化的快照中恢复快照
relation->rd_tableam->scan_begin()
// prepare to track buffer/WAL usage
InstrStartParallelQuery()
// 正式执行
ExecutorRun()
standard_ExecutorRun()
ExecutePlan()
for(;;)
ExecProcNode() // obtain a tuple
ExecProcNodeFirst()
ExecSeqScan()
ExecScan()
ExecScanFetch()
SeqNext()
table_scan_getnextslot()
heap_getnextslot()
heapgettup_pagemode()
page = table_block_parallelscan_nextpage()
// 当前 page 没有被读完
if (pbscanwork->phsw_chunk_remaining > 0)
nallocated = ++pbscanwork->phsw_nallocated;
// 当前 page 被读完
else
nallocated = pg_atomic_fetch_add_u64(&pbscan->phs_nallocated, pbscanwork->phsw_chunk_size)
heapgetpage()
pgstat_count_heap_getnext()
if (!dest->receiveSlot(slot, dest)) // actually tqueueReceiveSlot
shm_mq_send()
dest->rShutdown(dest)
// 关闭执行器
ExecutorFinish()
// 获取 instrumentation 后必须执行
ExecutorEnd()
// clean
dsa_detach()
ExitParallelMode()
DetachSession()
// report success
pq_putmessage()postmaster
// 循环等待事件即可;在合适的时机 fork 出 worker 进程。
PostmasterMain()
ServerLoop()
sigusr1_handler()
maybe_start_bgworkers()
do_start_bgworker()
fork_process()Leader 进程和 Worker 进程
对于例子中简单的查询语句,整个查询树只有两层结构,在整个查询的执行过程中我们一共需要关注3个进程;分别是 master 进程、 leader 进程和 worker 进程。在执行过程中执行 ps 命令即可查询到这三种进程,我们分别用红色、蓝色和绿色标出。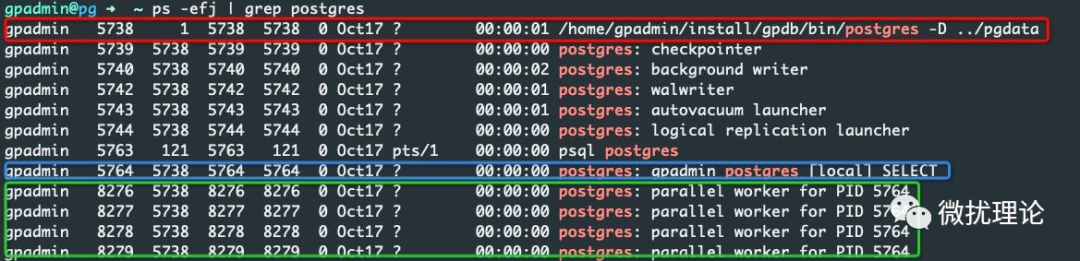 其中,leader 进程和非并行化的算子一样,本质上是用户连接 PG 后 fork 出来用于处理查询的进程;只不过在并行化算子中,为了和 worker 进程区分,我们这里就称为 leader 进程。Worker 进程的发起,也是由 leader 进程控制的。
其中,leader 进程和非并行化的算子一样,本质上是用户连接 PG 后 fork 出来用于处理查询的进程;只不过在并行化算子中,为了和 worker 进程区分,我们这里就称为 leader 进程。Worker 进程的发起,也是由 leader 进程控制的。
但是 leader 进程本身并不能直接 fork 出 worker 进程,而是需要通过给 master 进程发信号再由 master 进程 fork 的方式进行。
在 master 进程中,由 ServerLoop() 负责等待信号,如果发现是要求 fork worker 进程的信号,就会进行相应的后台工作进程的启动工作;再 fork_process 调用之后,worker 进程就产生并立刻进入初始化和后续的扫描工作。
而他们之间的通信主要通过动态共享内存和在此之上建立的消息队列实现;错误上报、扫描元组的传递都是通过该机制实现的;底层是一个无锁环形队列,实现非常巧妙,我们之后有机会展开讨论。
Worker 进程创建过程
那 worker 进程具体是如何被创建的呢?我们先来看看 PG 执行器收到的查询计划的结构。
Gather [startup_cost=0 total_cost=9.1666666666666679 plan_rows=1000 plan_width=4 parallel_aware=false parallel_safe=false async_capable=false plan_node_id=0]
[num_workers=2 rescan_param=0 single_copy=false invisible=false initParam=0x0]
[targetlist]
TargetEntry [resno=1 resname="t" resorigtbl=24576 resorigcol=1]
Var [varno=-2 varattno=1 vartype=23 varnosyn=1 varattnosyn=1]
[lefttree]
-> SeqScan [startup_cost=0 total_cost=9.1666666666666679 plan_rows=417 plan_width=4 parallel_aware=true parallel_safe=true async_capable=false plan_node_id=1
extParam=0x00000001 allParam=0x00000001]
[scanrelid=1]
[]
[targetlist]
TargetEntry [resno=1]
Var [varno=1 varattno=1 vartype=23 varnosyn=1 varattnosyn=1]计划的最上层是 Gather ;所以在执行器开始执行的时候,leader 进程首先就会从 ExecGather 开始进行执行操作,而这个时候,worker 进程其实还没有被创建。 真正地创建是在执行 ExecGather 的过程中发生的;如果 leader 进程执行过程中发现并行上下文尚未完成初始化,且计划器计划的并行工作进程数量大于0;则需要进行相应的并行进程初始化工作。
真正地创建是在执行 ExecGather 的过程中发生的;如果 leader 进程执行过程中发现并行上下文尚未完成初始化,且计划器计划的并行工作进程数量大于0;则需要进行相应的并行进程初始化工作。
在 ExecInitParallelPlan() 调用的过程中,我们也会初始化 worker 进程所需要的查询计划,放入 node->pei 中,并通过共享内存同步给 worker 进程。随后,通过调用 LaunchParallelWorkers() 准备 worker 进程启动所需要的一些信息并发送信号给 master 要求 fork worker 进程。
在这个过程里, leader 也会负责将队列信息和 worker 进程的信息绑定在一起。
for (i = 0; i < pcxt->nworkers_to_launch; ++i)
{
memcpy(worker.bgw_extra, &i, sizeof(int));
if (!any_registrations_failed &&
RegisterDynamicBackgroundWorker(&worker,
&pcxt->worker[i].bgwhandle))
{
shm_mq_set_handle(pcxt->worker[i].error_mqh,
pcxt->worker[i].bgwhandle);
pcxt->nworkers_launched++;
}
}而 worker 进程启动的时候就可以从共享内存中获取 bgw_extra。
void
ParallelWorkerMain(Datum main_arg)
{
memcpy(&ParallelWorkerNumber, MyBgworkerEntry->bgw_extra, sizeof(int));
}从而获取当前的消息队列应该是哪一个;通过调用 ExecParallelGetReceiver 可关联 shm_mq。
static DestReceiver *
ExecParallelGetReceiver(dsm_segment *seg, shm_toc *toc)
{
char *mqspace;
shm_mq *mq;
mqspace = shm_toc_lookup(toc, PARALLEL_KEY_TUPLE_QUEUE, false);
mqspace += ParallelWorkerNumber * PARALLEL_TUPLE_QUEUE_SIZE;
mq = (shm_mq *) mqspace;
shm_mq_set_sender(mq, MyProc);
return CreateTupleQueueDestReceiver(shm_mq_attach(mq, seg, NULL));
}最后,整个唤起进程的过程中可能会失败,所以实际唤起的工作进程数量可能是少于预期的;不过这并不会构成问题。
多个进程是如何协同扫描的?
现在我们来介绍多个进程是如何一起扫描的。在微扰酱一开始的猜测里,扫描可能是由 Planner 事先分配好每个进程的扫描的范围;然后并发协同扫描的。而这样,显然会导致多个进程扫描时产生一定的乱序,从而导致读性能下降,看起来不太可取。
那 PG 具体是如何做的呢?
事实上,PG 的做法是让多个进程竞争地顺序读数据表。其实现则依赖于在共享内存中存储的变量 ParallelBlockTableScanDesc 。它是被多个 worker 进程共享并用于控制目前扫描进行到哪一页的描述符。
多个进程扫描获取下一个元组的时候首先会去获取一批页,通过原子操作更新共享内存中的描述符实现互斥;如果进程获取的页没读完,则会先将获取的页中的元组全部读出,后再次申请新的页;核心代码如下。
BlockNumber
table_block_parallelscan_nextpage(Relation rel,
ParallelBlockTableScanWorker pbscanwork,
ParallelBlockTableScanDesc pbscan)
{
nallocated = pbscanwork->phsw_nallocated =
pg_atomic_fetch_add_u64(&pbscan->phs_nallocated,
pbscanwork->phsw_chunk_size);
}因此,并发扫描的粒度是以页为单位的。在一部分进程因为一些原因被阻塞的情况下,其他进程,则可以继续后续页中的数据。所有 worker 进程读出的数据都会通过共享内存队列发送给 leader 进程。Leader 进程也会循环读取每个队列中的数据,如果其中有队列中没有新的数据并不会阻塞,而是直接跳过当前进程继续读后续队列的数据。
这样,在并发读的过程中,由于有文件系统基于窗口的预读机制,在大部分情况下和严格顺序读的磁盘性能差距并不明显。
并发顺序扫描的意义?
写到这里,不知道读者会不会产生一个疑问;既然并发顺序读本身并不能提高 IO 本身的效率,甚至引入了一些额外的初始化和竞争的开销;那并发顺序扫描的算子到底有什么意义呢?
我们知道,并发主要释放的还是 CPU 的计算能力,尤其是在多核的场景下;而顺序扫描本身其实是一个纯 IO 的场景,在例子中非常简单的查询语句下其实确实是不能发挥什么优势的。但是如果你的查询语句比较复杂,涉及过滤、聚合等运算,那每个进程在获取数据之后就要进行许多诸如哈希计算这样耗费 CPU 计算资源的操作;并发的意义就得以体现了。看网上流传的一些评测数据中,在启用并发度为4的连接查询时,通常也能达到接近于4倍的效率提升。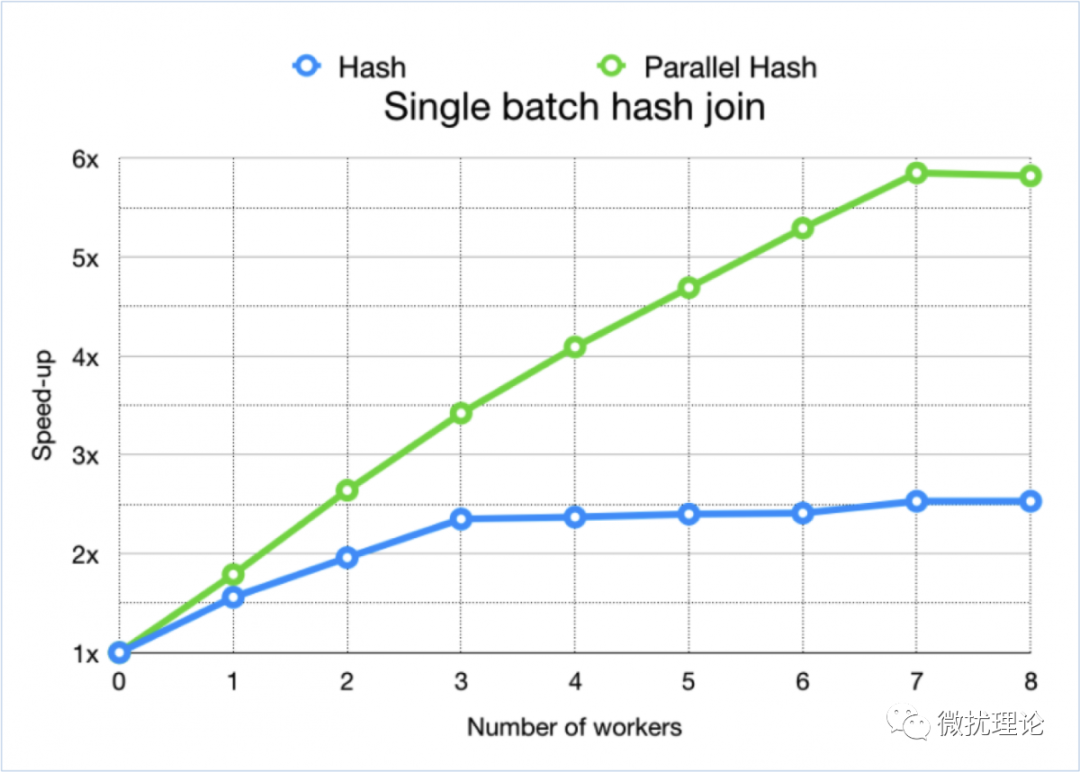 而并发顺序扫描的意义就是为后续的其他并行算子提供基础。正如微扰酱的这篇文章也是后续研究其他算子的基础;大家的点赞、关注、转发也能让微扰酱有更可持续的写作基础一样。
而并发顺序扫描的意义就是为后续的其他并行算子提供基础。正如微扰酱的这篇文章也是后续研究其他算子的基础;大家的点赞、关注、转发也能让微扰酱有更可持续的写作基础一样。
参考链接
[1]. PostgreSQL 并行表扫描分析 Gather Parallel Seq Scan https://www.mytecdb.com/blogDetail.php?id=22
[2]. Parallel Hash for PostgreSQL https://www.enterprisedb.com/blog/parallel-hash-postgresql
[3]. Parallelism in PostgreSQL 11 https://2019.pgdu.org/static/presentations/Thomas-parallelism-postgresql-11.pdf
[4]. Using gdb to trace into a parallel worker spawned by postmaster during a large query https://www.highgo.ca/2021/07/09/using-gdb-to-trace-into-a-parallel-worker-spawned-by-postmaster-during-a-large-query/
结语
计算机是一门需要动手实践才能掌握的学科,想了解数据库最好的方式莫过于加入一家不错的公司啦;欢迎大家找我内推 hashdata;入职即享20天年假,优秀更可远程办公,快私信微扰酱一键内推吧~














 279
279











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









