







《Java网络编程》学习笔记
基本概念
基本的网络协议:
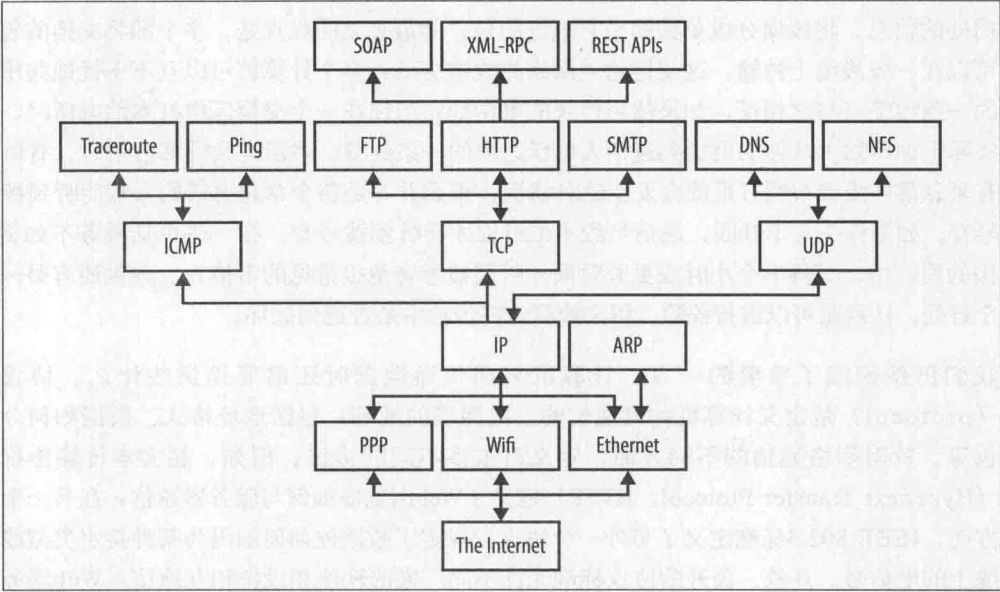
常见服务端口分配列表:
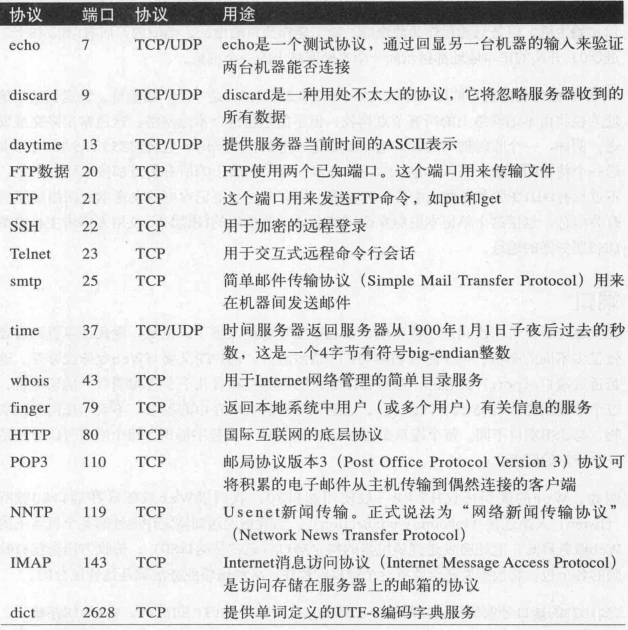
客户端服务端连接示意图:
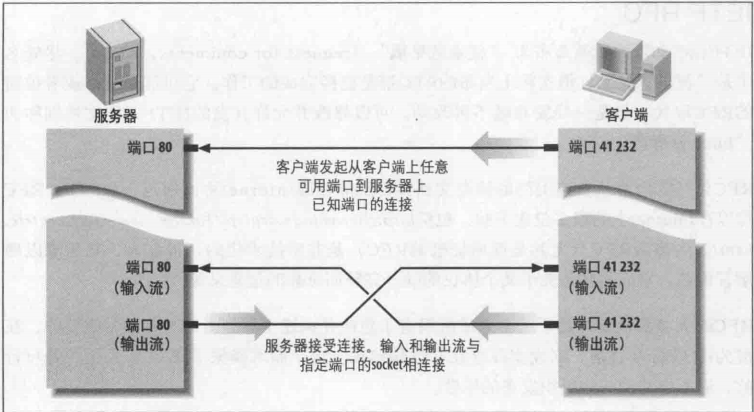
流(介绍JAVA的流)
带资源的try块
只要对象实现了Closeable接口,都可以使用“带资源的try”块,java会对try块参数表中声明的所有autocloseable对象自动调用close()。
try (OutputStream out = new FileOutputStream("D://a.txt")){
} catch (IOException e) {
e.printStackTrace();
}过滤器
过滤器有两个版本:过滤器流以及阅读器和书写器。过滤器刘仍然主要讲原始数据作为字节处理,例如通过亚索数据或解析为二进制数字。阅读器和书写器处理多种编码文本的特殊情况。
过滤器以链的形式进行组织。例如:
FileInputStream fin = new FileInputStream("data.txt");
BufferedInputStream bin = new BufferedInputStream(fin);为了防止使用者同时使用fin和bin读造成的bug,可以改写成:
InputStream in = new FileInputStream("data.txt");
in = new BufferedInputStream(in);可以创建的时候直接连接:
DataOutputStream dout = new DataOutputStream(new BufferedOutputStream(new FileOutputStream("data.txt")));
PrintStream
建议:PrintStream是有害的,网络程序员应该尽量避免。原因:
println的输出是与平台有关的(行分隔符在各个系统不一样)
PrintStream假定使用所在平台的默认编码方式,但这种方式可能是服务器不期望的(推荐使用PrintWriter)
PrintStream吞掉了所有的异常(需要用checkError()方法来判断)
数据流
DataInputStream和DataOutpStream类提供了一些方法,可以用二进制格式读/写Java的基本数据类型和字符串。所用的二进制格式主要用于在两个不同的Java程序之间交换数据。
所有的数据都是以big-endian格式写入
线程
派生Thread
通过实现run方法计算一个文件的SHA-2消息摘要
public class DigestThread extends Thread {
private String filename;
public DigestThread(String filename) {
this.filename = filename;
}
@Override
public void run() {
try {
FileInputStream in = new FileInputStream(filename);
MessageDigest sha = MessageDigest.getInstance("SHA-256");
DigestInputStream din = new DigestInputStream(in, sha);
while (din.read() != -1) ;
din.close();
byte[] digest = sha.digest();
StringBuilder result = new StringBuilder(filename);
result.append(": ");
result.append(DatatypeConverter.printHexBinary(digest));
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (NoSuchAlgorithmException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
public static void main(String[] args) {
for (String filename : args) {
Thread t = new DigestThread(filename);
t.start();
}
}
}实现runnable接口(略)
从线程返回消息
1. 可以在类里面加入字段,存放要返回的信息
public class ReturnDigestInterferface {
public static void main(String[] args) {
for (String filename : args) {
ReturnDigest dr = new ReturnDigest(filename);
dr.start();
//获取数据
StringBuilder result = new StringBuilder(filename);
result.append(": ");
byte[] digest = dr.getDigest();
result.append(DatatypeConverter.printHexBinary(digest));
System.out.println(result);
}
}
}问题:可能子线程的结果还没计算完或者字段还没初始化,主程序就通过get方法获取数据,造成出现错误。
2. 竞态条件
竞态条件就是给线程分配资源所用的算法。
改成:
先运行子线程,然后再取数据(实际上还是没解决问题,取决于线程的竞态条件)
public static void main(String[] args) {
ReturnDigest[] digests = new ReturnDigest[args.length];
for (int i=0;i<args.length;i++) {
digests[i] = new ReturnDigest(args[i]);
digests[i].start();
}
for (int i=0;i<args.length;i++) {
StringBuffer result = new StringBuffer(args[i]);
result.append(": ");
byte[] digest = digests[i].getDigest();
result.append(DatatypeConverter.printHexBinary(digest));
System.out.println(result);
}
}3. 轮询
public static void main(String[] args) {
ReturnDigest[] digests = new ReturnDigest[args.length];
for(int i =0;i<args.length;i++) {
digests[i] = new ReturnDigest(args[i]);
digests[i].start();
}
for(int i=0;i<args.length;i++) {
//循环查询
while (true) {
byte[] digest = digests[i].getDigest();
if (digest != null) {
StringBuffer result = new StringBuffer(args[i]);
result.append(": ");
result.append(DatatypeConverter.printHexBinary(digest));
System.out.println(result);
break;
}
}
}
}问题:不一定能解决问题,而且占CPU资源
4. 正确的方式:回调
在线程算出结果后调用:
CallbackDigestUserInterface.receiveDigest(digest, filename);主线程加一个静态方法,用于回调:
public class CallbackDigestUserInterface {
public static void receiveDigest(byte[] digest, String name) {
StringBuilder result = new StringBuilder(name);
result.append(": ");
result.append(DatatypeConverter.printHexBinary(digest));
System.out.println(result);
}
public static void main(String[] args) {
for (String filename : args) {
CallbackDigest cb = new CallbackDigest(filename);
Thread t = new Thread(cb);
t.start();
}
}
}静态方法可以用实例方法替代:
public class InstanceCallbackDigest extends Thread {
private String filename;
private InstanceCallbackDigestUserInterface callback;
public InstanceCallbackDigest(String filename, InstanceCallbackDigestUserInterface callback) {
this.filename = filename;
this.callback = callback;
}
@Override
public void run() {
try {
FileInputStream in = new FileInputStream(filename);
MessageDigest sha = MessageDigest.getInstance("SHA-256");
DigestInputStream din = new DigestInputStream(in,sha);
while (din.read()!=-1);
din.close();
byte[] digest = sha.digest();
callback.receiveDigest(digest);
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (NoSuchAlgorithmException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
}public class InstanceCallbackDigestUserInterface {
private String filename;
private byte[] digest;
public InstanceCallbackDigestUserInterface(String filename) {
this.filename = filename;
}
public void calculateDigest() {
InstanceCallbackDigest cb = new InstanceCallbackDigest(filename, this);
Thread t = new Thread(cb);
t.start();
}
public void receiveDigest(byte[] digest) {
this.digest = digest;
System.out.println(this);
}
@Override
public String toString() {
return "InstanceCallbackDigestUserInterface{" +
"filename='" + filename + '\'' +
", digest=" + Arrays.toString(digest) +
'}';
}
public static void main(String[] args) {
for (String arg : args) {
//创建实例,而不是采用静态方法
InstanceCallbackDigestUserInterface d = new InstanceCallbackDigestUserInterface(arg);
d.calculateDigest();
}
}
}这样做的优点:
各个实例只映射至一个文件,可以跟踪这个文件的信息(静态方法是通用的)
可以很容易的重复计算某个特定文件
注意点:这里增加了一个启动线程的方法,要避免在构造函数中启动线程。
Future、Callable、Executor
Java的多线程编程:需要创建一个ExecutorService,它会根据需要为你创建线程。可以向ExecutorService提交Callable任务,对于每个Callabel任务,会分别得到一个Future。之后可以向Future请求任务结果。如果结果已经就绪,就会得到这个结果,如果没有,轮询线程会阻塞,知道结果准备就绪。
如写一个找数组最大数的例子:
先定义一个Callable:
public class FindMaxTask implements Callable<Integer> {
private int[] data;
private int start;
private int end;
public FindMaxTask(int[] data, int start, int end) {
this.data = data;
this.start = start;
this.end = end;
}
@Override
public Integer call() throws Exception {
int max = Integer.MAX_VALUE;
for (int i = start; i < end; i++) {
if (data[i] > max) {
max = data[i];
}
}
return max;
}
}然后通过ExecutorService调用任务,通过Future获取数据
public class MultithreadedMaxFinder {
public static int max(int[] data) throws ExecutionException, InterruptedException {
if (data.length == 1) {
return data[0];
} else if (data.length == 1) {
throw new IllegalArgumentException();
}
//将任务分解成两个部分
FindMaxTask task1 = new FindMaxTask(data, 0, data.length / 2);
FindMaxTask task2 = new FindMaxTask(data, data.length / 2, data.length);
//创建两个进程
ExecutorService service = Executors.newFixedThreadPool(2);
Future<Integer> future1 = service.submit(task1);
Future<Integer> future2 = service.submit(task2);
//调用这个方法会阻塞,要等future1.get方法结束阻塞后才能运行future2.get
return Math.max(future1.get(), future2.get());
}
}同步
同步块(略)
同步方法(默认对this的同步)
对于同步问题,仅想所有方法添加synchronized修饰符不是一劳永逸的解决方案,他会使JVM性能下降,有可能会增加死锁的可能性。
同步的替代方式
- 多使用局部变量
- 定义为不可变类型(private final)
- 将非线程安全的类作为线程安全类的一个私有字段
- 使用java自带的线程安全的类
死锁
防止死锁,最重要的技术是避免不必要的同步。如果有其他方法可以确保线程安全,比如让对象不可变或者保存对象的一个局部副本,就最好使用那种方法。另外写代码的时候要确保所需的资源都请求到在进行下一步。
线程调度
避免线程饥饿问题
优先级
java中线程优先级从0到10,默认为5
抢占
每个虚拟机都有一个线程调度器,确定在给定时刻运行哪个进程。主要有两种线程调度:抢占式和协作式。java虚拟机确保在不同优先级之间采用抢占式线程调度,防止饥饿问题。
为了让其他线程有机会运行,有这几种可以暂停线程或指示它准备暂停的方法:
I/O阻塞;同步对象阻塞;放弃;休眠;连接另一个线程;等待一个对象;结束;被更高优先级的线程抢占;挂起;停止(后两种已经废弃)
1. 阻塞
不论是I/O阻塞还是对锁阻塞,都不会释放线程已经拥有的锁
2. 放弃
调用Thread.yield()方法,放弃不会释放这个线程拥有的锁
3. 休眠
不管有没有其他线程准备运行,休眠线程都会暂停。休眠同样不会释放锁。通过sleep睡眠和interrupt唤醒。
注意区别线程和thread之间的区别,线程在睡眠并不意味着醒着的线程不能处理这个线程相应的thread对象和interrup方法
4. 连接线程:join
使用join可以修改上面那个生成摘要的例子,等子线程运行玩再取数据。现在join用的并不多,因为Executor和Future可以更容易的实现。
5. 等待:wait
会释放锁并暂停,wait方法不在thread类中,而是在Object中。
线程结束wait的条件:
时间到期;
线程被中断(interrupt());
对象得到通知(notify()和notifyAll())
在wait和通知时,必须先获得对象的锁。notify基本上随机地从等待这个对象的线程列表中选择一个线程,并将它唤醒。notifyAll()方法会唤醒等待指定对象的么一个进程。
一旦等待线程得到通知,他就试图重新获取所等待对象的锁,如果失败,他就会对这个对象阻塞。
一个例子:创建一个线程读取归档文件,另一个线程读取归档文件中的清单文件,第一个线程等另一个线程读完清单后唤醒它,他再继续处理清单。
读清单文件的程序:
ManifestFile m = new ManifestFile();
JarThread t = new JarThread(m, int);
synchronized (m) {
t.start();
try {
m.wait();
//处理清单文件
} catch (InterruptedException ex) {
//处理异常
}
}读归档文件的程序:
ManifestFile theManifest;
InputStream in;
public JarThread(Manifest m, InputStream in){
theManifest = m;
this.in = in;
}
@Override
public void run(){
synchronized(theManifest){
//从流中读取清单文件
theManifest.notify();
}
//读取流的其余部分
}注意:由于可能存在多个线程等一个对象,最后一个等待的程序唤醒时可能过去很长时间了,对象有可能再次进入不可接受状态(其他线程造成的),如果不能保证,就要显式检查。如下例:
读取一个文件,文件的每一行都包含要处理的项:
处理的线程:
private List<String> entries;
public void processEntry() {
synchronized (entries) {
while (entries.isEmpty()) {
try {
entries.wait();
//停止等待,因为entries变为非0
//但是我们不知道它任然是非0
//所以在此通过外面的循环检查它现在的状态
} catch (InterruptedException e) {
//如果被中断,则最后一项已经处理过,所以返回
return;
}
}
String entry = entries.remove(entries.size() - 1);
//处理的程序
}
}读取的线程:
public void readLogFile() {
while (true) {
String entry = log.getNextEntry();
if (entry == null) {
//如果没有更多项添加到列表
//所以中断所有仍在等待的线程
//否则他们将永远等待下去
for (Thread thread:threads) {
thread.interrupt();
}
break;
}
synchronized (entries) {
entries.add(0, entry);
entries.notifyAll();
}
}
}线程池和Executor
对于IO受限或者网络程序来说,添加多个线程回极大地提升性能。如下面解压文件的例子:
解压的线程:
public class GZipRunnable implements Runnable {
private final File input;
public GZipRunnable(File input) {
this.input = input;
}
@Override
public void run() {
if (!input.getName().endsWith(".gz")) {
File output = new File(input.getParent(), input.getName() + ".gz");
if (!output.exists()) {
try (
InputStream in = new BufferedInputStream(new FileInputStream(input));
OutputStream out = new BufferedOutputStream(new GZIPOutputStream(new FileOutputStream(output)));
) {
int b;
while ((b=in.read())!=-1) out.write(b);
out.flush();
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}用户接口:
public class GZipAllFiles {
public final static int THREAD_COUNT =4;
public static void main(String[] args) {
ExecutorService pool = Executors.newFixedThreadPool(THREAD_COUNT);
for (String arg : args) {
File f = new File(arg);
if (f.exists()) {
if (f.isDirectory()) {
File[] files = f.listFiles();
for (int i = 0; i < files.length; i++) {
if (!files[i].isDirectory()) {
Runnable task = new GZipRunnable(files[i]);
pool.submit(task);
}
}
} else {
Runnable task = new GZipRunnable(f);
pool.submit(task);
}
}
}
pool.shutdown();
}
}一旦所有文件都增加到这个池,就调用pool.shutdown().这个方法不会终止等待的工作。它只是通知线程池再也没有更多的任务需要增加到它的内部队列,而且一旦完成所有等待的工作,就应当关闭。















 2440
2440











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









