






1. 指令集
CPU本身是由一堆的晶体管组成的,执行的时候,只有高低电平状态。我们定义低电平为0,高电平为1,就有了数字电路的概念。从而引申出来了各种门电路,如与门,非门,或门等等。这些门电路经过综合,最后又形成了各种加法器,乘法器等运算单元。当然,这些都是通过VHDL硬件描述语言写的,相当于逻辑功能硬件化了。
有了这么多的运算单元后,我们需要增加一些控制逻辑。告诉CPU,我现在要进行的算法是什么,需要参与计算的数据存储在哪儿。而控制逻辑的核心,就是指令寄存器IR和指令译码器ID,当然也包括我们最常用到的PC寄存器,即程序计数器,它指明了下一条指令的地址。通过PC寄存器,得到将要执行的指令,该指令内容被放到指令寄存器IR中,然后,经由指令译码器ID进行译码。译码后,CPU就明确了要进行的操作和操作数的位置,然后建立相应的数据通路去执行操作。
整个过程中,通过指令寄存器等传递的指令,形成的集合就是指令集。其实,也就是常说的机器语言,通过机器语言我们和CPU进行沟通交互。告诉它我们想要进行的操作。那么,指令长什么样子呢?
1.1 分析一个机器指令
1.1.1 生成汇编文件
我们拿一个最简单的stm32程序,打开keil工具,按照如下截图位置,添加指令
fromelf --text -a -c --output=Project.dis Objects\Project.axf
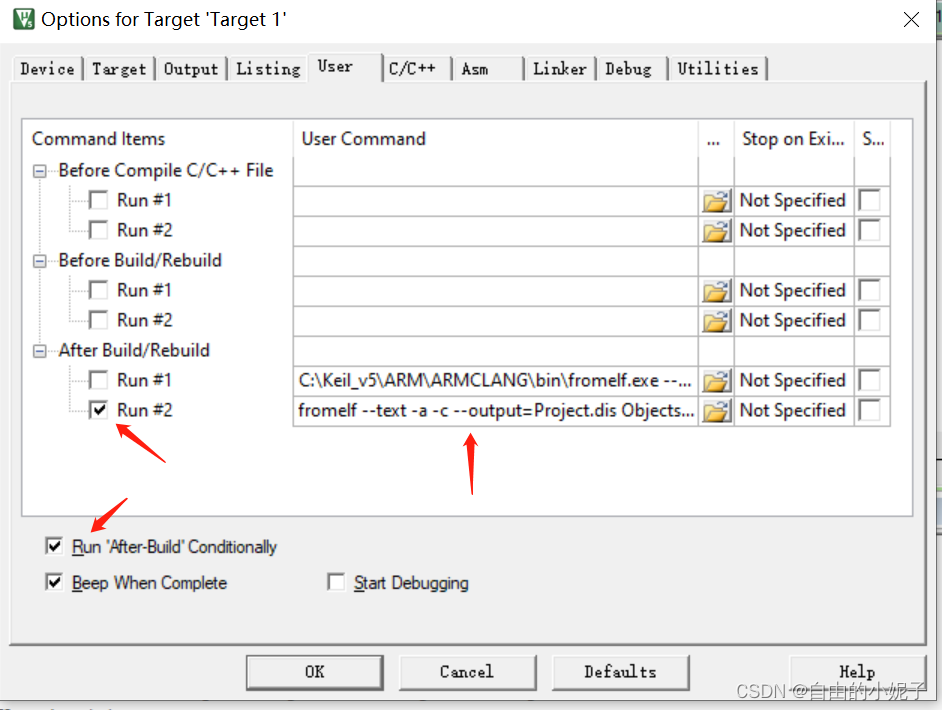
如此,重新编译后,你会得到Project.dis,这样你会得到一个汇编文件。
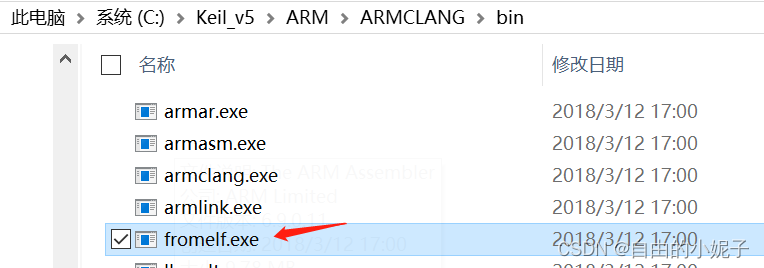
另外,你得确定你的keil安装中,存在以下工具
1.1.2 指令解析
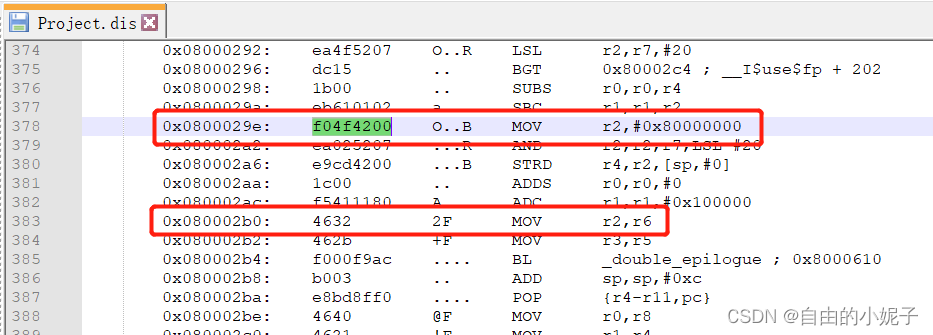
由于stm32是Cortex-M3 内核。Cortex-M3 处理器采用 ARM v7-M 架构。它包括所有的 16 位 thumb 指令集和基本的 32 位 thumb-2 指令集架构。
所以,汇编文件中,会出现两种不同长度的MOV指令。
参考以下《Arm® v7-M Architecture Reference Manual》文档,里面包含了thumb和thumb-2的指令集内容。
1)分析thumb-2指令
f04f4200,MOV
转换成二进制格式 ——> 1111 0000 0100 1111 0100 0010 0000 0000
参照手册,通过分析指令的每一个section,我们跳转到绿色箭头指向的段落。
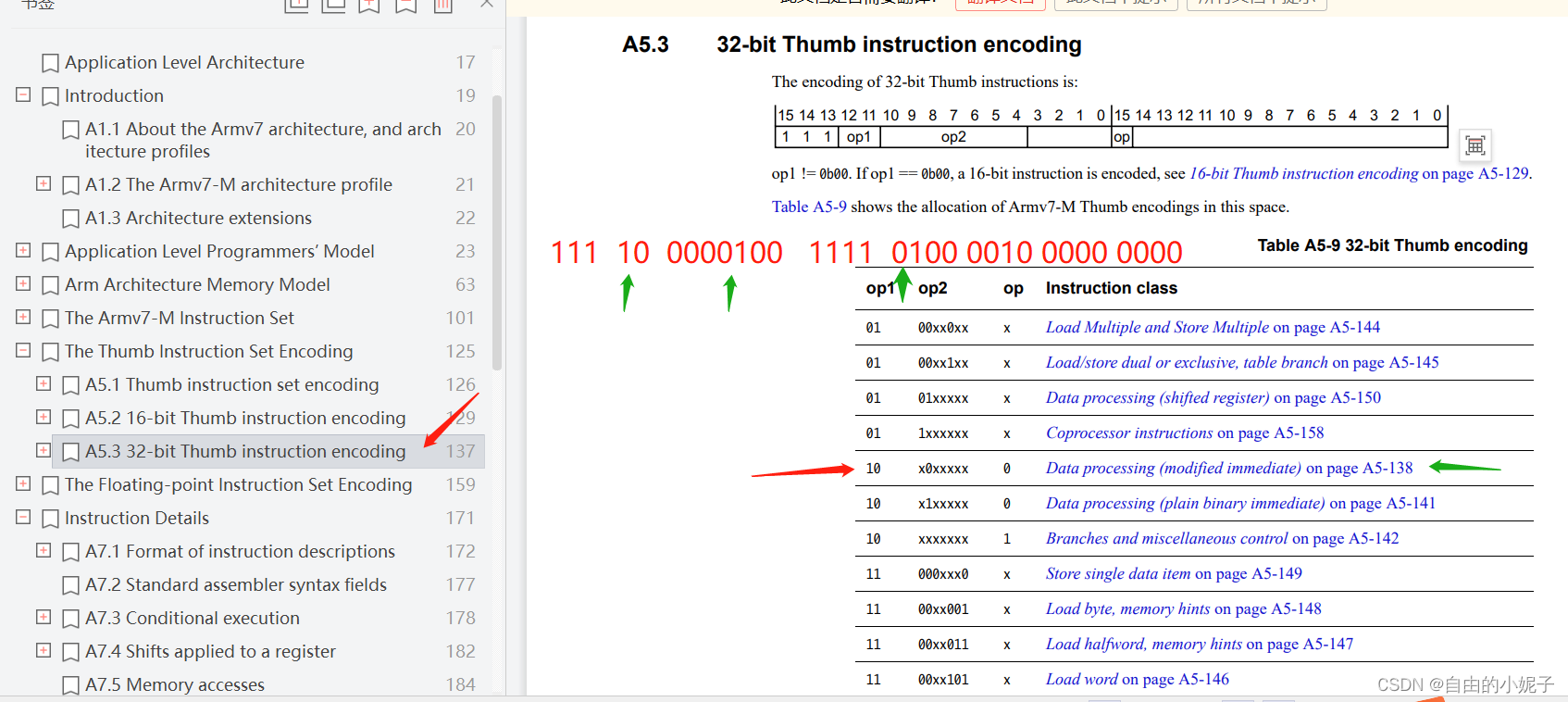
通过新的段落的分析,这个是个MOV指令。
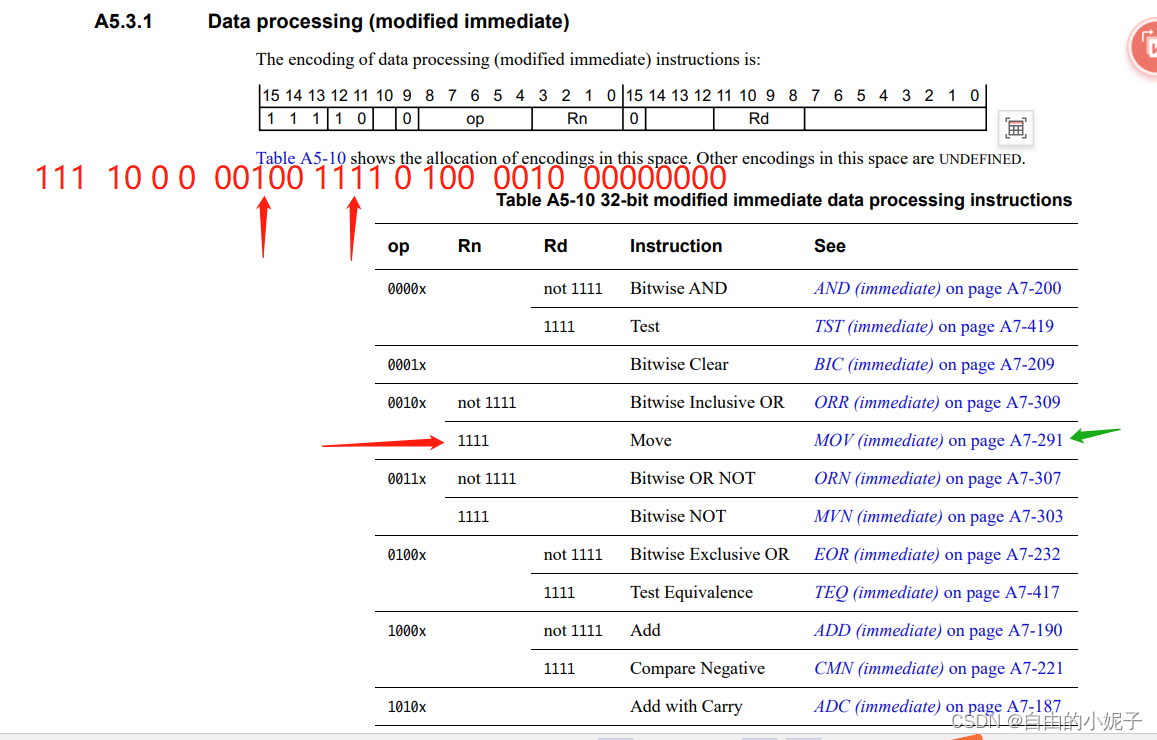
再根据MOV指令的具体定义,我们就可以得到寄存器,立即数等具体的内容。

同理,我们也可以分析出thumb的指令。
1.2 机器指令 -> 汇编指令
机器指令,也就是0101的各种组合,不同的组合代表了不同的行为。一般指令集包括的指令包括MOV、ADD、BL等。进行CPU设计的时候,需要遵循这样的指令集定义,然后让CPU根据不同的机器指令执行不同的操作。
但是,机器指令过于生硬,不方便于人们编写程序。所以,才有了汇编语言,通过MOV、ADD等这样的汇编指令编写程序,再通过assembly汇编工具,将这些汇编指令翻译成机器指令,再传送给CPU去做执行。
所以,指令集定义了一系列CPU的行为规范,指令集定义的过于繁琐,就会导致CPU的执行效率下降。目ARM采用的都是RISC精简指令集,目前arm产品使用的指令集包括A32、A64和Thumb-2和Thumb指令集。Thumb指令集和A的最大区别就是,Thumb指令集不支持条件执行。ARM根据不同的使用场景,对指令集进行了不同的支持。对于中低端产品,要求更低的成本,一般只支持thumb指令集。而对于性能要求很高,使用场景复杂的产品,有的ARM产品就支持到了A64指令集。然后,考虑兼容性和不同的使用场景,有一些ARM产品还可以做到对A64\A32\T32所有的指令集的兼容,并诞生了两个新的名词AArch32 和 AArch64。针对CPU处于不同的状态,调用不同的指令集。其中, AArch32 包含 32 位 A32 和 T32 指令,而 AArch64 包含 64 位 A64 指令。如果处理器当前处于 AArch64 状态并且需要使用 A32 指令,就必须切换到 AArch32 状态。在 AArch64 模式下,可以访问 32 位和 64 位寄存器,而在 AArch32 模式下只能使用 32 位寄存器。
2 寄存器和位宽
位宽是指计算机寄存器(一般指通用寄存器)能够存储的二进制数据的位数,一般进行CPU设计的时候,都会让运算器的位宽和通用寄存器的位宽一致,这个宽度反映了CPU的计算能力,即一次性处理的数据长度。
比如stm32,Cortex-M3架构的处理器。它具备的寄存器如下:

然后它支持的thumb-2指令集,也具备了处理32bit的数据的能力。所以,cortex-M3处理器就具有32bit的运算能力。
再比如ARMv8架构的CPU,它的通用寄存器如下:
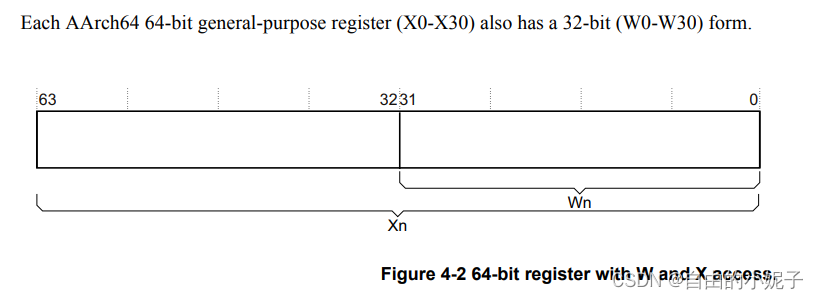
由于ARMv8支持AArch32 和 AArch64指令集,所以它的通用寄存器在使用A64的指令集时,会将通用寄存器当做64bit的寄存器使用,即Xn。但是,当其使用A32或T32的指令集时,会将通用寄存器当做32bit的寄存器使用,即Wn。所以,对于ARMv8的处理器,它本身具备了最大64bit的运算能力。
所以,我们平时说的32位的操作系统,或者64位的操作系统,指的是针对具备32bit/64bit运算能力的CPU设计的系统。我们说的,ARM64或ARM32,一般也指的是CPU的位宽,也就是它的运算能力是64bit / 32bit。
3 总线宽度和访存能力
CPU可访问的内存空间能力,由总线宽度决定,确切说由数据总线宽度决定。
比如,以stm32来说:
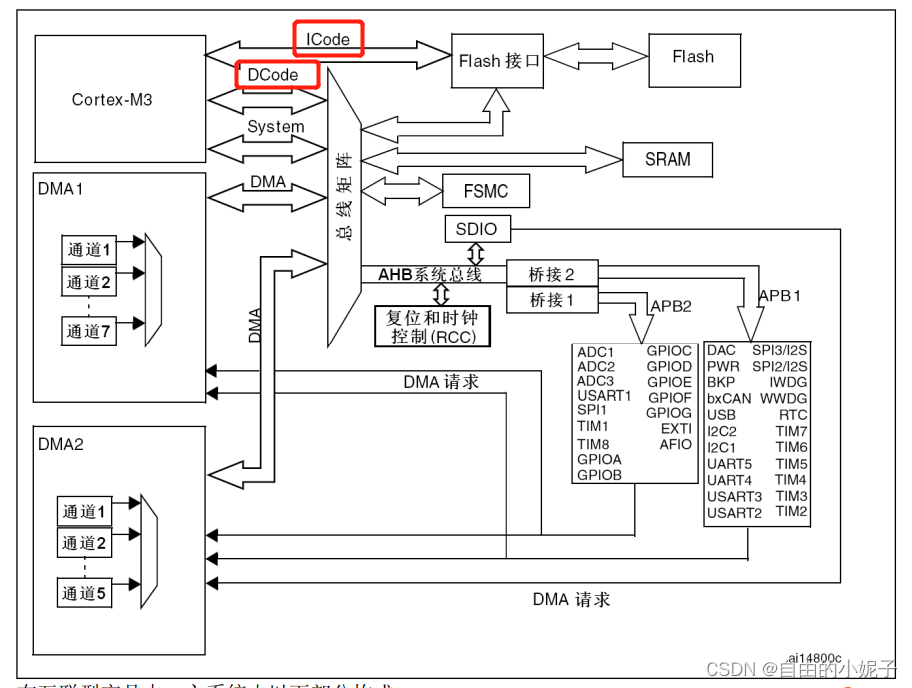
我们只关注2个总线:
- ICode总线,该总线将Cortex™-M3内核的指令总线与闪存指令接口相连接。指令预取在此总线上完成。ICode 接口是一个 32 位的 AHBLite 总线接口。
- DCode总线,该总线将Cortex™-M3内核的DCode总线与闪存存储器的数据接口相连接(常量加载和调试访问)。DCode 接口是 32 位的 AHBLite 总线。
- 系统总线,此总线连接Cortex™-M3内核的系统总线(外设总线)到总线矩阵,总线矩阵协调着内核和DMA间的访问。系统接口是 32 位的 AHBLite 总线。
cortex-M支持32bit的thumb-2指令集,所以,必然要求指令总线宽度也可以达到32bit宽度。
然后其数据总线的宽度为32位的AHBLite总线,所以,cortex-M可访存的空间大小为0~0xFFFFFFFF,即4G的空间大小。这是,硬件条件具备的访存能力。
4 Cortex-M3和stm32的内存空间划分
下图是cortex-M3的存储空间划分。
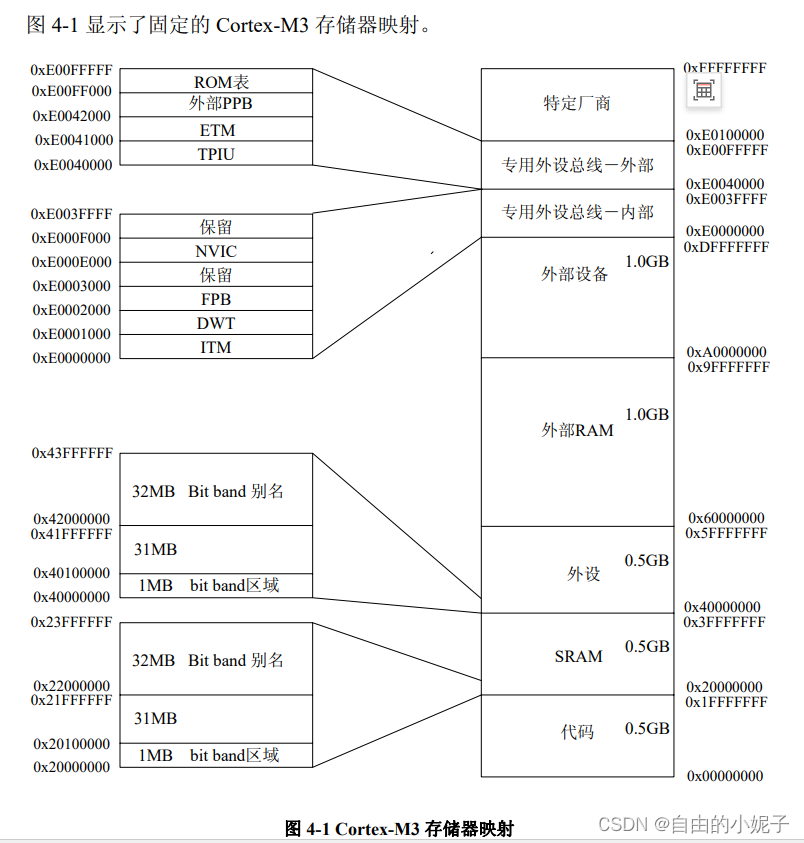
其代码区在0x00000000~0x1FFFFFFF这个空间范围。而STM32F103又对其代码区做了更细致的划分。如下:
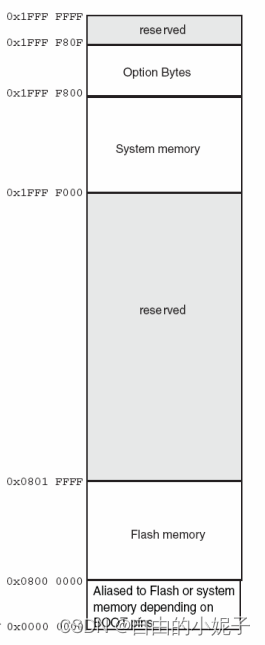
也正因为如此,如果用过STM32这款芯片的同学就知道了,我们自己写的代码每次都是从0x08000000这个地址开始执行的。
5 Cortex-M3的中断向量表
在M3核中,有个嵌套向量中断控制器(NVIC)的概念,可以对中断事件进行管理和配置。其中有个Vector Table Offset Register,即向量表便宜寄存器。可以对中断向量表的位置进行重定位。向量表偏移寄存器将向量表定位在 CODE 或 SRAM 中,默认情况下复位时为 0(CODE 空间)。所以,一般我们的代码,起始位置存放的是中断向量表。
那么中断向量表是什么呢?比如,以stm32来说。
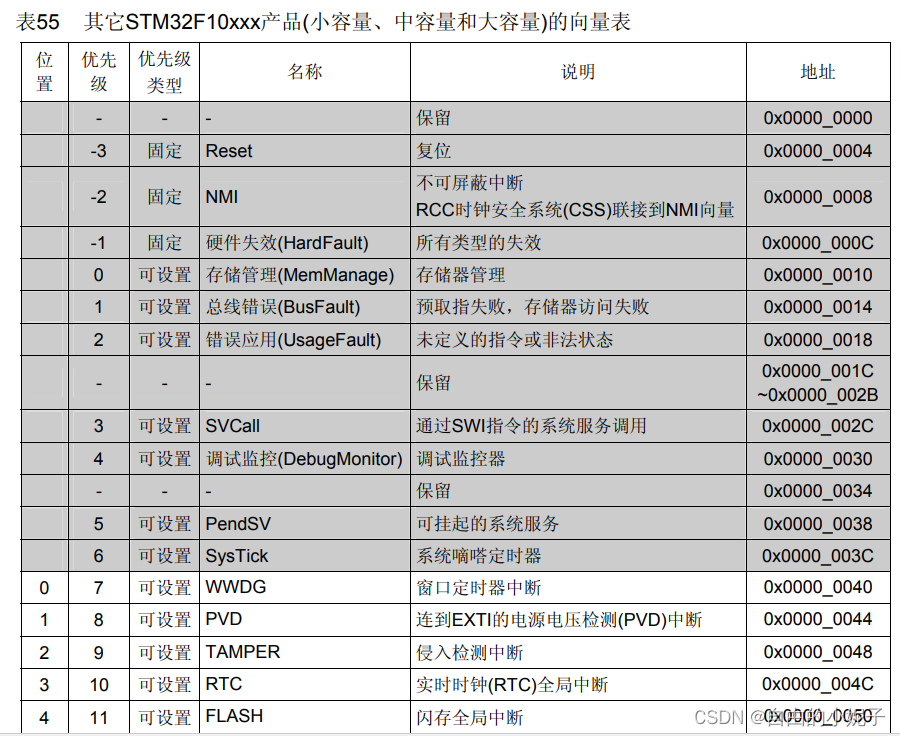
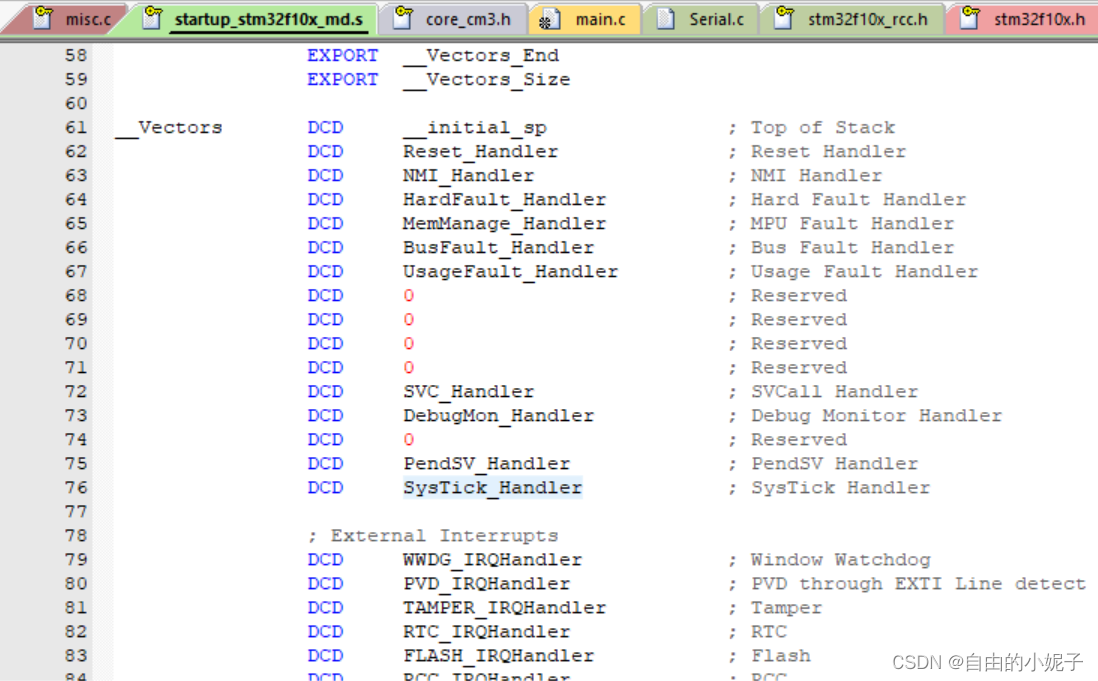
这是其中某一款的中断向量表,灰色的这些是内核中断。一般在.s文件中,对这些中断向量进行了配置。当触发对应的中断时候,执行响应的中断函数。
以下是参考文献。如有侵权请告知,会及时删除。谢谢


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









