






原理:
服务端采用免费的网络记事本,客户端爬取相应的字符串实现验证的目的,适合需要验证功能且对安全性要求不高的朋友。
优点:
不花钱,可随时停用旧版程序
弱点:
1、验证字符串是为明文方式读取,不包含加/解密代码,解决方式:加解密文章放下面给大家参考,可自行加上
https://www.cnblogs.com/xiao-apple36/p/8744408.html
2、稳定性不确定,解决方式:可多注册1-2家同类型的网络记事本链接,当其中一家无法访问时自动跳转至备用链接
服务端:
封装类:
# 基于python3.x
import requests #爬虫库
import threading #线程库
# 定义类
class wlyz:
def __init__(self, text):
self.text=text #赋值验证字符串
print(self.text)
def Get_url(self,text): #验证代码
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36
(KHTML, like Gecko) Chrome/65.0.3325.146 Safari/537.36'
} # 设置爬虫头部,伪装成浏览器
# url,网址
url = 'https://tibiji.com/share/G0bab1ahhd'
res = requests.get(url, headers=headers) # 利用requests对象的get方法,对指定的url发起
请求,该方法会返回一个Response对象
res.encoding = res.apparent_encoding
if res.text.find(self.text) > 0:
self.compare = True
else:
self.compare = False
def compare(self): # 用线程方式调用验证,确保UI不阻塞
t = threading.Thread(target=self.Get_url, args=("",))
t.setDaemon(True) # 把子进程设置为守护线程,必须在start()之前设置
t.start()调用:
from wlyz import wlyz
import time
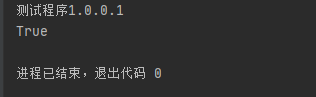
yz=wlyz("测试程序1.0.0.1")
yz.compare()
time.sleep(3)
print(yz.compare)
输出结果:
最后附上我自己使用的网络记事本网址:https://tibiji.com















 720
720











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









