





2021年9月22日, Cheese, clamchowder
"Electronic Boogaloo" 是一句流行语,源自于1984年的电影《电子舞步2》(Breakin' 2: Electric Boogaloo)。这部电影是一部舞蹈电影,讲述了一组街头舞者为了挽救他们的社区而组织舞蹈表演的故事。由于电影名字中“Electric Boogaloo”这个短语的重复和韵律感,因此这个短语被用来指代任何具有续集或追加内容的事物。现在,“Electronic Boogaloo”一词已经成为了互联网上的一个流行吐槽,常被用于表示某种不受欢迎、低质量或过度商业化的续集。
目录
在本篇的第一部分中,我们谈到了第三家x86设计公司威盛,更具体地说,威盛最近的商业化架构Isaiah。今天我们讨论的是威盛与上海市政府的合资企业--兆芯。
一点背景历史
兆芯是在2013年开始的,是上海市和威盛集团的合资企业。

兆芯的CPU系列和架构图
根据 Wikichip 上的信息,张江是 Isaiah II 内核的一个小修改,其中最大的变化是在 Padlock 中增加了中国的散列算法 SM3 和 SM4。
大的架构变化来自于五道口核心,兆芯公司声称每时钟的性能提高了25%,这不是一个小成就。我们今天看到的内核是兆芯最新的陆家嘴,兆芯声称它比五道口的性能提高了50%,但是,时钟速度也提高了50%,这让我怀疑陆家嘴是将五道口的内核从华虹宏力的28纳米移植到台积电的16纳米,因此有一个很好的时钟提升。
陆家嘴与以赛亚的对比有什么变化?
缓存金.....或者在这种情况下,是一种交换
缓存金(Cache Money)是 ActiveRecord 的一个写通和读通的缓存库。穿透式: 像 User.find (:all, :condition =>...) 这样的查询,首先会在 Memcached 中寻找,然后在数据库中寻找该查询的结果。如果有一个缓存缺失,它将填充缓存。
兆芯公司对陆家嘴架构所做的最大改变之一是对高速缓存层次的改变。
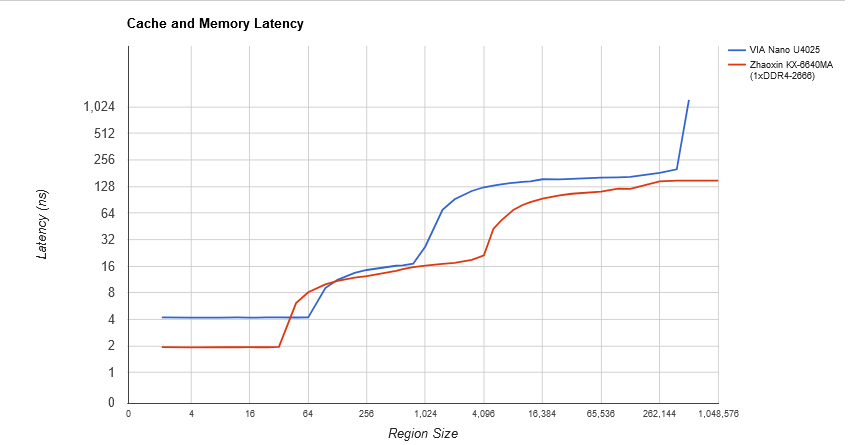
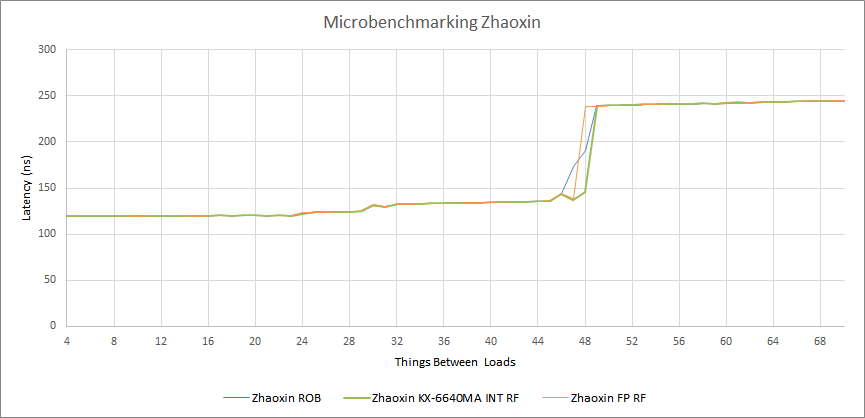
兆芯和威盛的 L1 延迟的绝对值相同,都是5个周期。但是,威盛记录的 L1 延迟是 2 个周期,而我们显示的是 5 个周期的延迟;这可能是因为我们的测试使用了复杂的地址生成,看起来给 L1 的延迟增加了 3 个周期。根据英特尔和 AMD 的文件,我们怀疑兆芯有一个 4 周期的 L1 延迟和一个 1 周期的复杂地址生成惩罚,但是我们不可能根据这个测试来判断。
兆芯将 L1 从 Isaiah 的 64KB L1 减为 32KB L1。这是一个有趣的举动,有几个原因:一个更小的 L1 是更低的功率,花费更少的芯片面积,并将减少 L1 的命中率,因此更多的请求被送到 L2。
说到这一点,陆家嘴的 4MB L2 现在在一个四核集群中共享,抛弃了 Isaiah 的每个核心 1MB 的私有 L2。因此,陆家嘴的最后一级缓存配置类似于 AMD 的 Zen 1 和 Zen 2 APU,这是一个巨大的变化,因为 Isaiah 没有共享缓存。
然而,这种新的共享 L2 是有很大代价的。L2 延迟从 Isaiah 上的 20 个周期变成了陆家嘴上惊人的 48 个周期。作为比较,Zen 1 的 L3(LLC)是 8MB 的两倍大,但却有 35 个周期的延迟,尽管 Zen 1 以更高的时钟运行。
这将向我们表明,这不是一个高性能的设计,然而兆芯和威盛都声称 KX-6000 系列的设计是为了在性能上与 Skylake 对抗,这是一个高性能的核心。现在,Tom's Hardware 对 KX-U6780A 做了非常深入的性能评测,发现它在性能上根本无法与 Skylake 相比。 Tom’s Hardware did a very in-depth performance review of the KX-U6780A
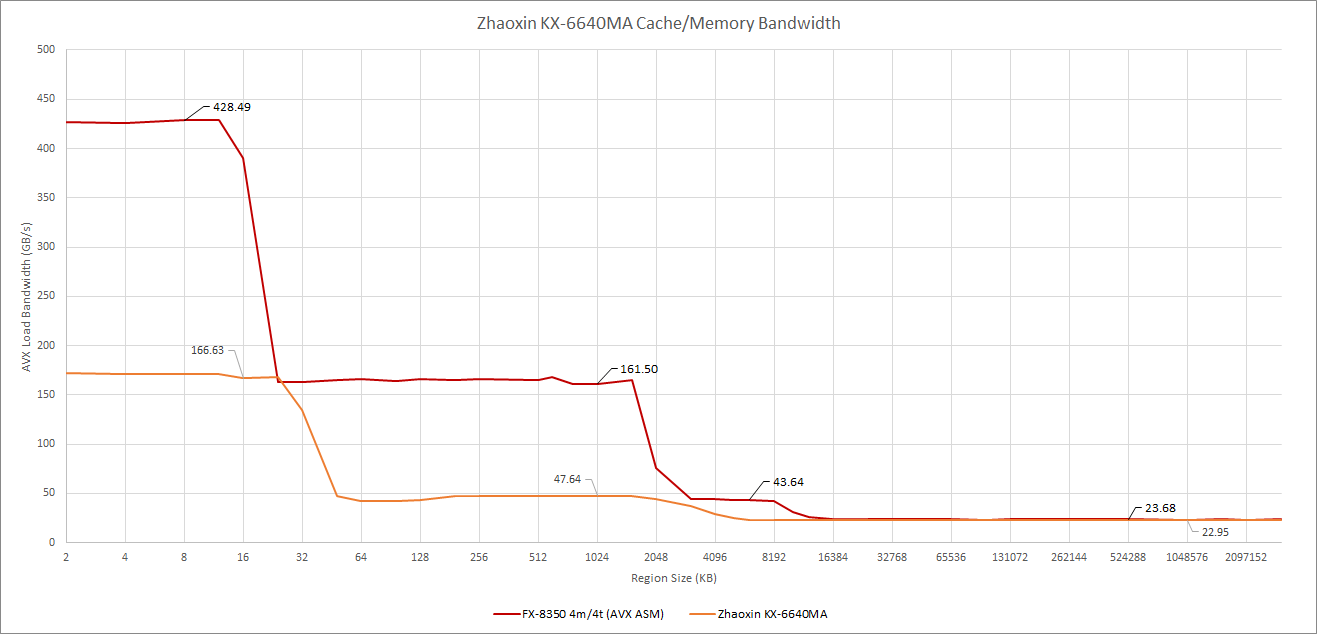
在每个模块配置1个线程的情况下,兆芯和超微的打桩机对比缓存带宽。打桩机同样支持 AVX,将 256 位指令拆分成两个 128 位的微操作。
陆家嘴的缓存带宽即使与其他不使用全宽 AVX 实现的 CPU 相比也不令人印象深刻(后面会有更多的介绍)。我们甚至不能维持每周期从二级缓存中向每个核心发送8个字节。单线程的带宽,如下图所示,也没什么可写的。很明显,如果兆芯真的想和 Zen 2 抗衡的话,缓存的层次结构需要改进。
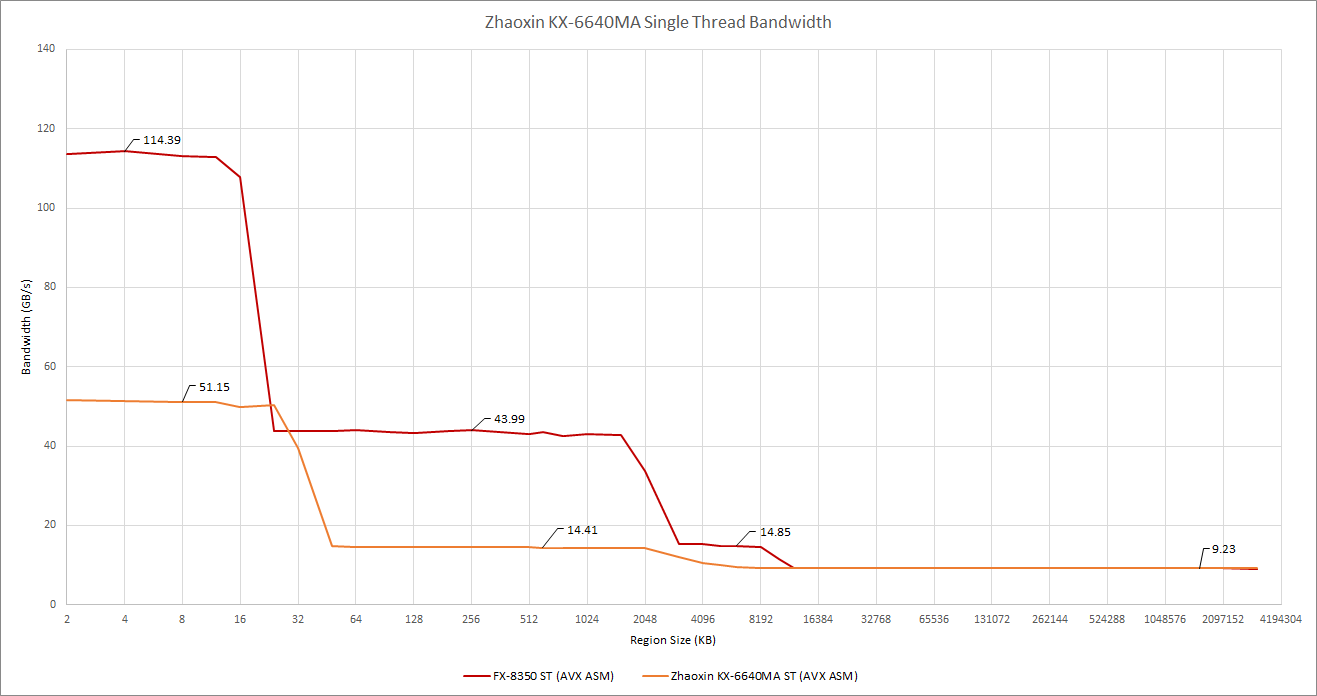
单线程的内存带宽。同样,提供了打桩机作为比较。
除了 L2 之外,陆家嘴将内存控制器放在片上,而不是通过前端总线(FSB)访问它,从而减少了内存延迟,而且陆家嘴的集群内互连在核心之间跳转高速缓存线时,延迟相当低:
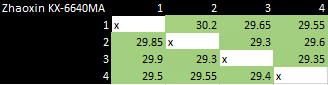
陆家嘴的 "核心到核心的延迟",其中核心使用原子指令来弹跳缓存线的所有权。
重要的分支预测器单元
在本文的前一部分,我们谈了很多关于 Isaiah 的非常独特的 BPU,以及它是如何以速度换取准确性的。
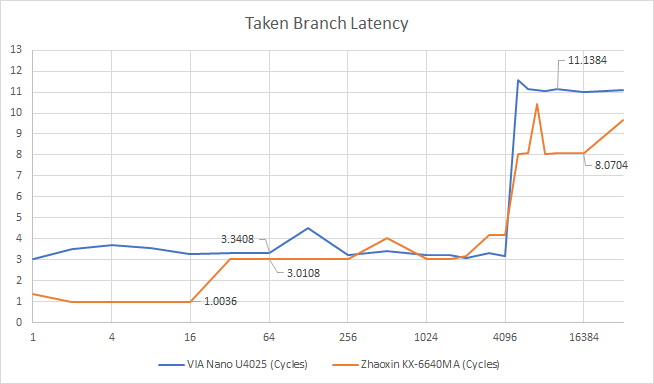
兆芯试图通过增加一个 16 入口的 L0 BTB 来获得两方面的好处,它可以处理没有气泡的已取分支。Zen 2 有一个类似的机制,通常可以处理它所看到的大约一半的分支,而不去使用更大、更高延迟的 BTB。陆家嘴的主 BTB 和 Isaiah 的一样,有 4096 个条目,如果它被用来提供一个分支目标,会产生两个气泡。如果有一个 BTB 失误,陆家嘴能够比 Isaiah 更快地提供一个分支目标。
现在让我们来看看分支预测器处理长的、重复的模式的能力如何。
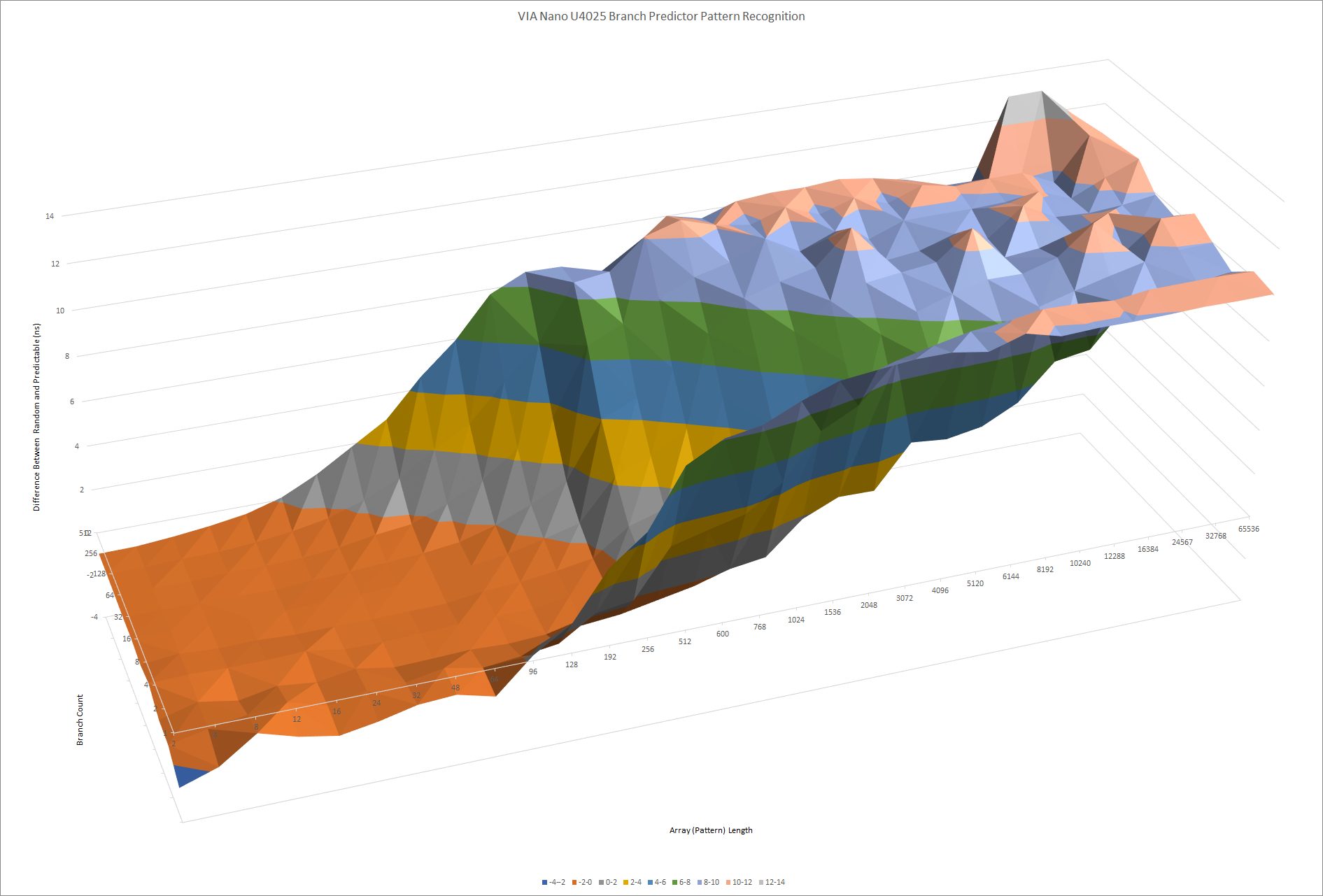
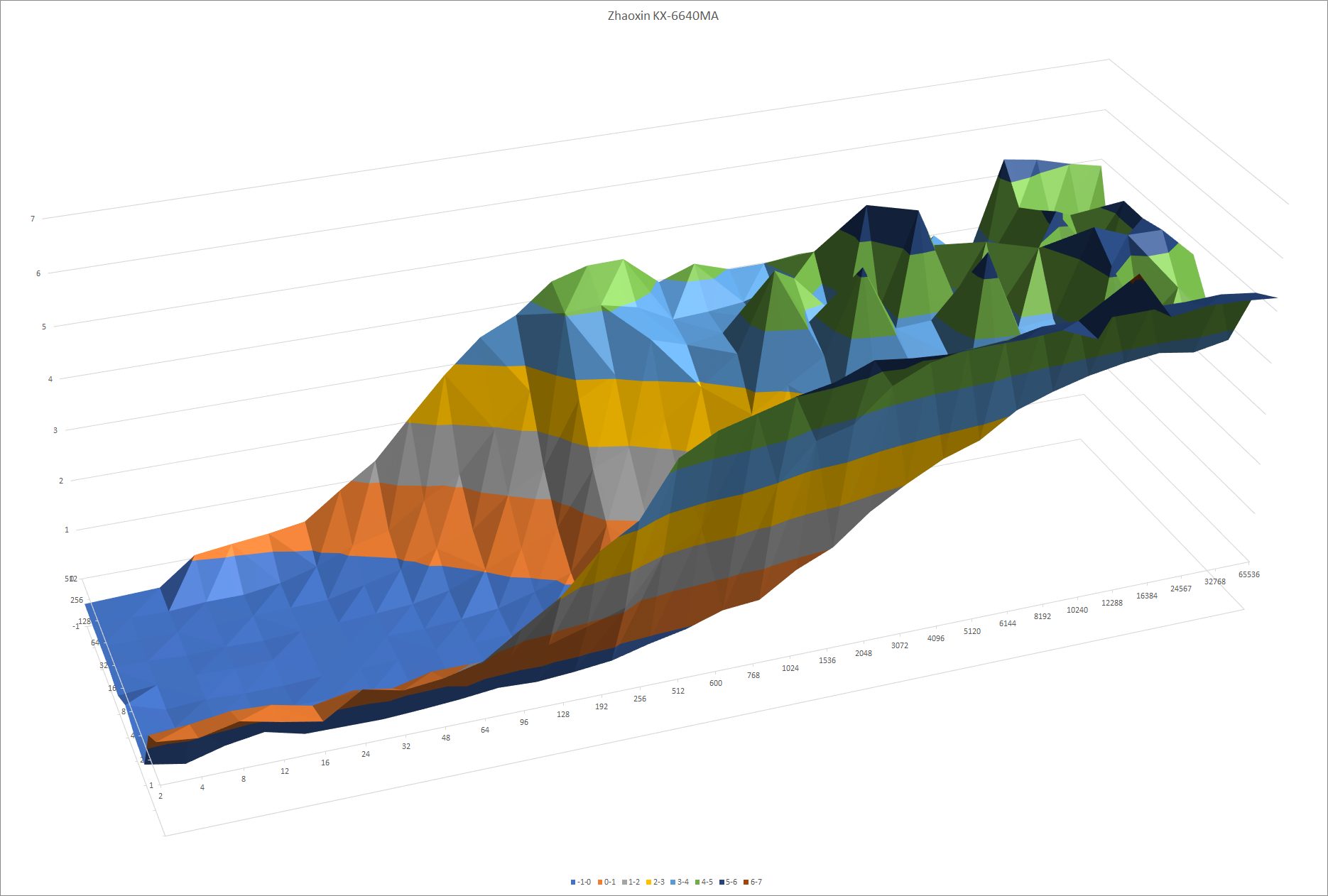
威盛(上)和兆芯(下)的模式识别能力。在执行时间不增加的情况下沿X轴走得更远,表明分支预测器可以跟踪更长的模式。沿着Y轴越走越远,表明分支预测器可以跟踪更多分支的模式。
模式识别能力并没有什么变化。正如你所看到的,威盛和兆芯的BPU在这项测试中非常相似。以赛亚的方向预测器在 2008 年对于一个低功率的内核来说是非常复杂的。但是十年之后,它就相当平庸了。陆家嘴推出时的高性能内核,如 AMD 的 Zen 和英特尔的 Skylake,可以处理更长的模式而不会出现错误预测:
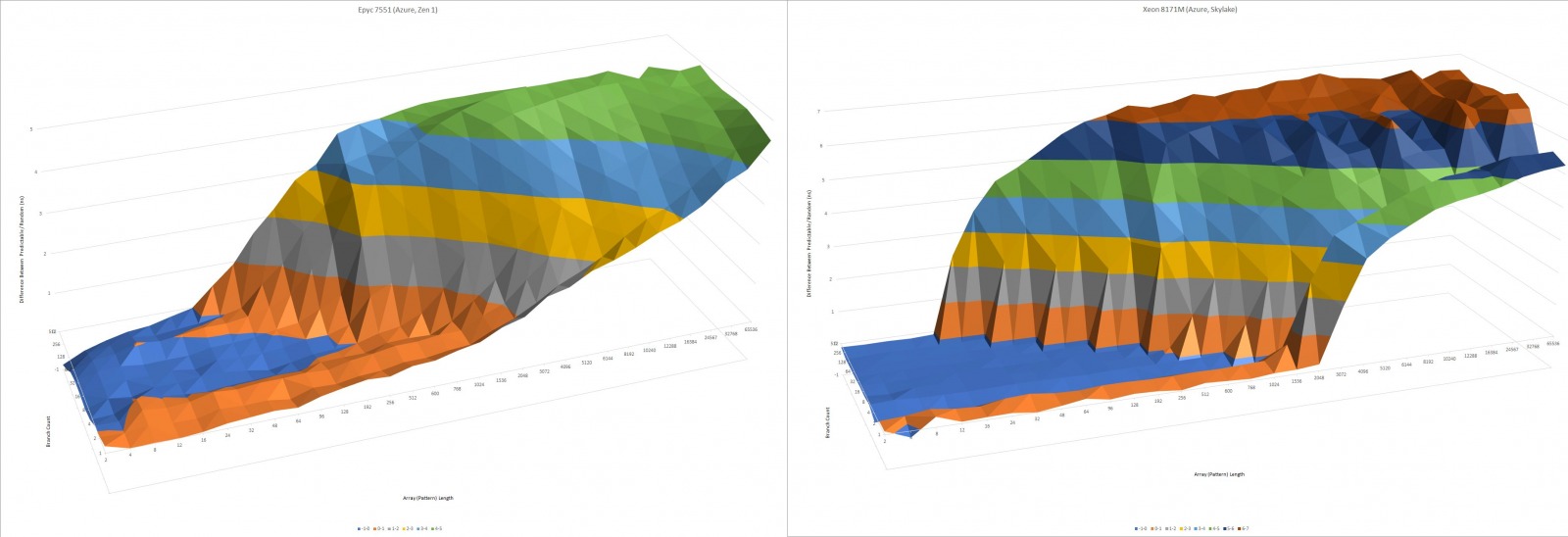
Zen 1和 Skylake 具有更强大的模式识别能力,如这些图表所示
ARM 的 Cortex A75 是一个当代的架构,有一个更有可比性的方向预测器。A75 是一个为智能手机设计的低功耗内核,所以这也表明陆家嘴的设计并不是真的要与英特尔和AMD的高手正面交锋。
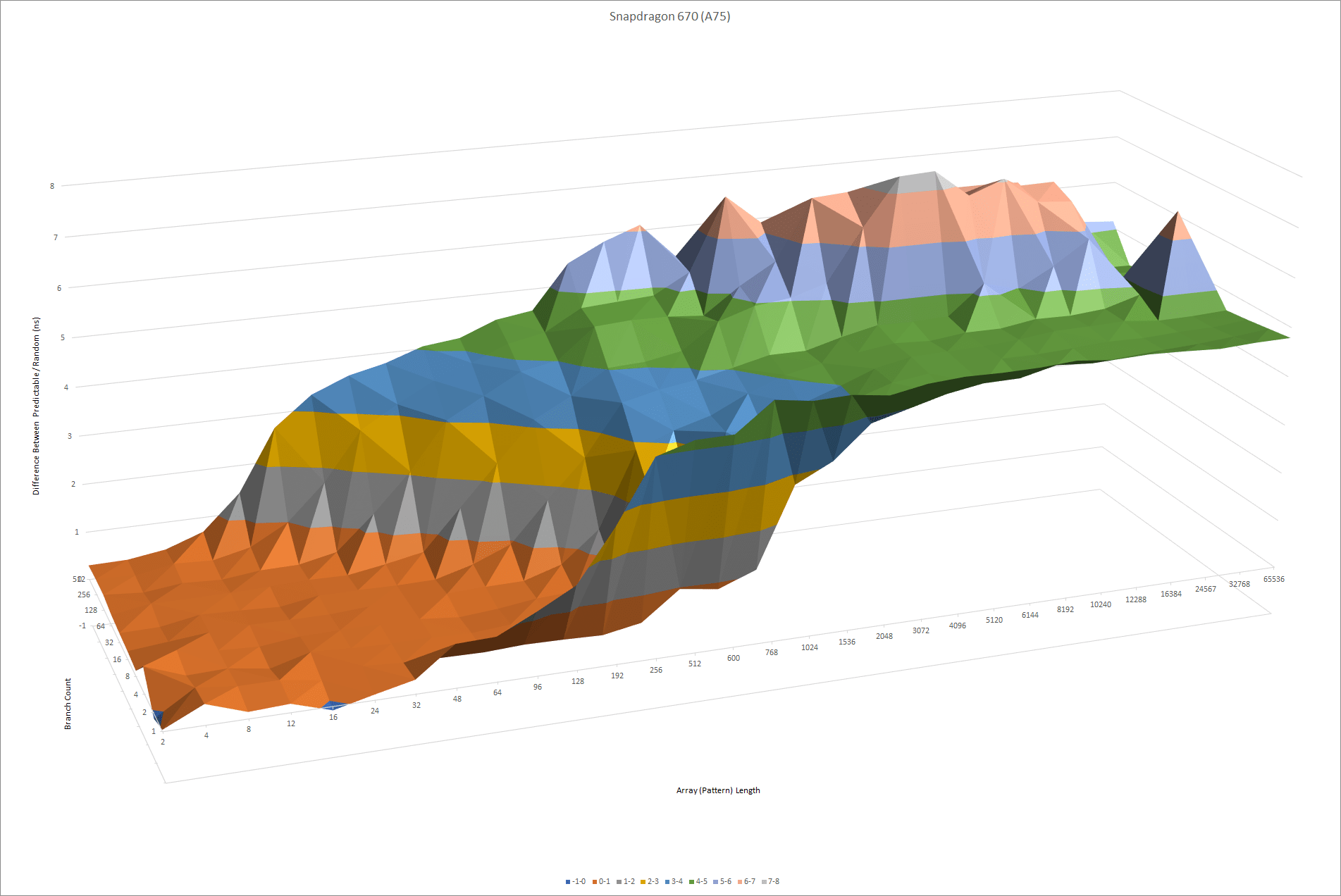
陆家嘴的模式识别能力与 Cortex A75 的大致相同
陆家嘴的调用/返回预测很奇特:
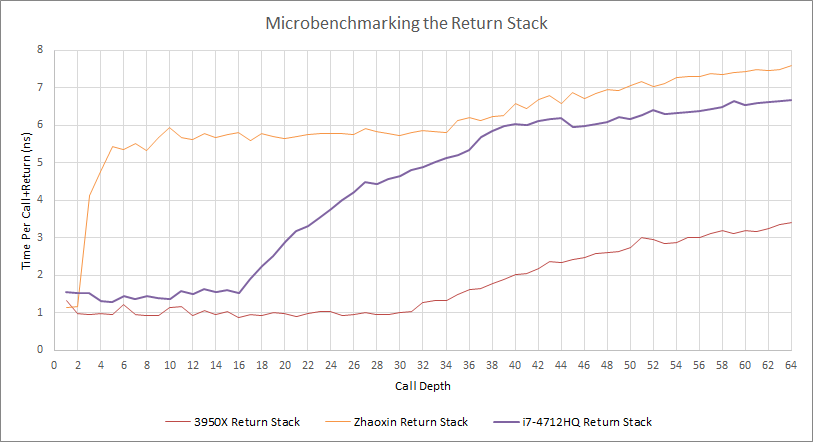
陆家嘴在深度嵌套调用时的行为,Haswell 和 Zen 2 的结果也在此进行了比较
看起来陆家嘴实现了一个快速但微小的 L1 返回栈,只有两个条目。陆家嘴可能有一个 34 个条目的 L2 返回堆栈,因为性能计数器只在调用深度超过这个数字时才显示错误预测。
5-6 纳秒在 2.6GHz 下是 13 到 16 个周期,所以这个 L2 返回栈慢得可怕。打击陆家嘴的 L2 返回栈和溢出 Haswell 上的返回栈一样糟糕。在陆家嘴上应该避免深度嵌套的调用,即使它们被正确预测了。
一个更小、更窄的核心?
这让我们有点吃惊,但看起来陆家嘴已经将解码宽度从 Isaiah 的 3 宽缩小到 2 宽。重命名和/或退休似乎也是 2 宽的——一半指令解码为两个微操作的测试只能以 1.5 IPC 运行,或每周期 2 微操作。
你选择缩小内核的三个原因是,如果你想要更高的时钟速度,更低的功率,和/或更小的内核占用的面积。然而,兆芯纯粹是为了提高时钟速度的理由并不成立,因为以赛亚达到了与五道口相同的时钟速度,两个架构在 28 纳米工艺上的最高频率都是 2GHz。
兆芯可能削减了宽度,以便在可接受的功率和芯片面积的情况下构建一个 8 核芯片。这是一个很好的提醒,以较低的时钟运行的更宽的核心并不总是更好。ARM 的 A73 也将核心宽度降至 2 宽(A72 为 3 宽),以提高电源效率,因此兆芯的举措并非没有先例。
ROB 和寄存器文件——向后倒退?
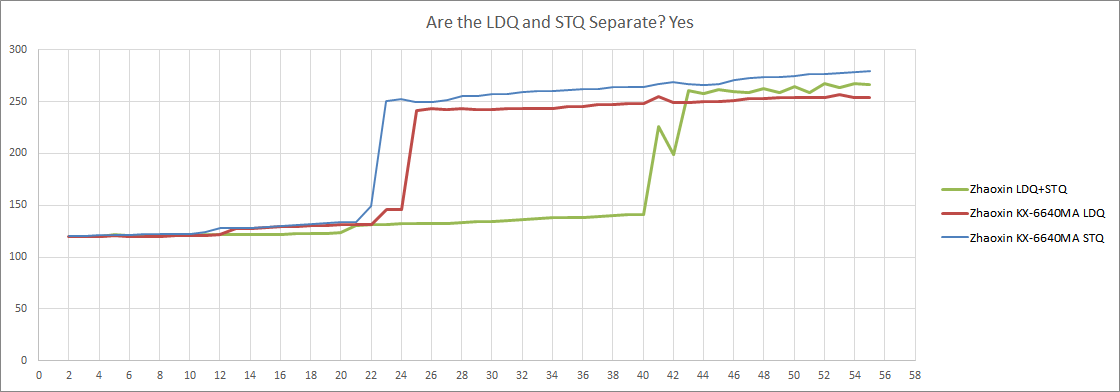
兆芯公司还将 ROB(重排缓冲区)的大小从 65 个条目削减到 48 个。即使我们使用写入整数或浮点寄存器的指令,也会受到陆家嘴 48 条 ROB 的限制,这说明 ROB 中每条指令都有足够的寄存器文件条目。显然,陆家嘴抛弃了 Isaiah 的独立寄存器文件,回到了 P6 风格的 ROB + RRF。几乎所有的现代高性能 CPU 都使用与 ROB 解耦的寄存器文件,所以这是一个令人费解的选择。
一种猜测是,ROB + RRF 方案需要更少的寄存器存储,因为整数和 FP/SIMD 指令共享同一个寄存器文件。它可能也更容易实现,因为你只需要处理 ROB,而不管指令是否写到寄存器。
值得称道的是,兆芯公司对未采取的分支进行了有趣的优化,以缓和较小的 ROB 带来的打击。具体来说,我们能够让两个长延迟的负载并行执行,它们之间有多达 64 个未采取的分支。这些分支中的每一个都是 cmp + je 对,因此有 128 条指令在运行。未采取的分支约占指令流的 5% 或 7%(分别在 Cinebench R20 和 Call of Duty Vanguard )。因此,陆家嘴的有效重排能力可能并不像 ROB 大小所显示的那样远远落后于 Nano。我们找不到任何其他指令或指令组合可以在飞行中突破 48 的限制。
调度所有这些队列
好吧,CPU 实际上不是在调度队列,这只是我非常糟糕的尝试,我们现在正在看陆家嘴的调度器。
兆芯似乎在很大程度上保留了 Nano 的端口布局,同时重新平衡了调度器的大小,以提高普通整数工作负载的性能。整数调度队列增加了一点,与 Nano 相比,我们看到 ALU 多了一个可用的调度器条目。
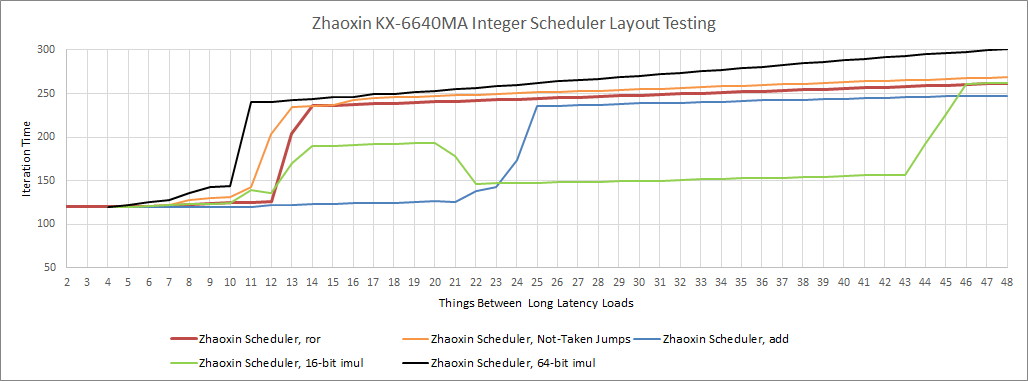
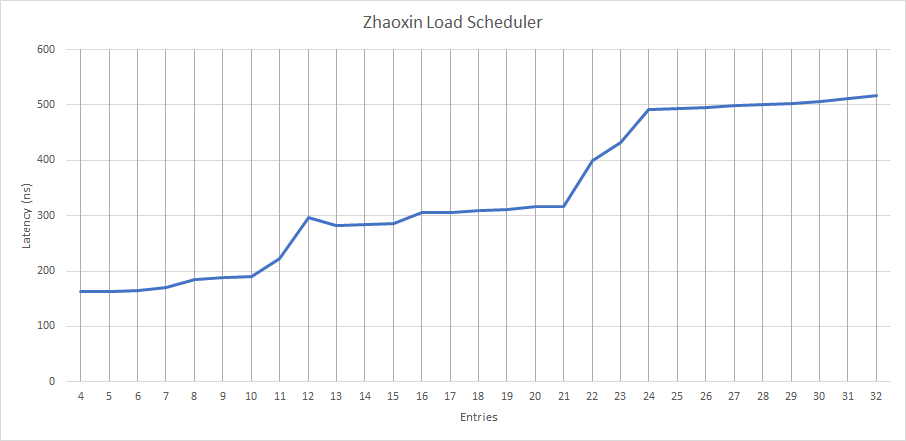
在内存方面,陆家嘴将负载调度器的大小增加到 12 个条目,并同样将存储调度器加强到 20 个条目。与 Isaiah 相比,存储调度器增加了 4 个条目,而负载调度器则增加了大约 7 个条目。
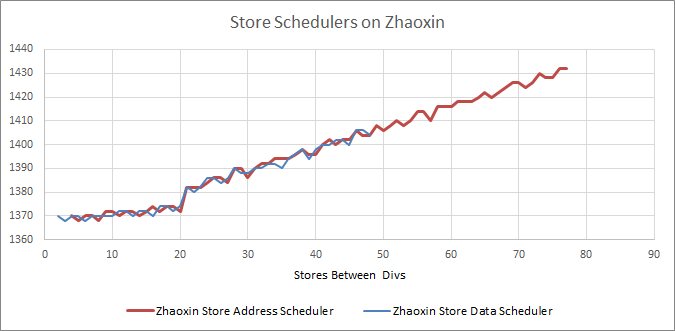
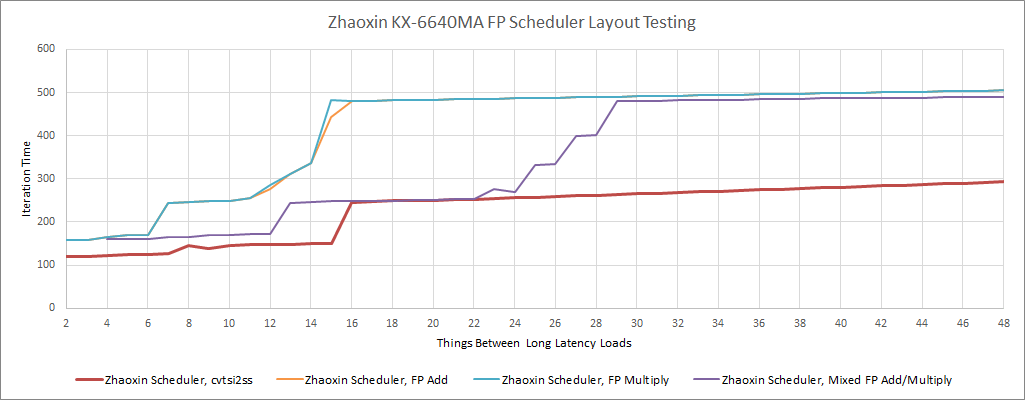
陆家嘴重新平衡并略微削减了 FP / SIMD 端的调度器。FP 乘法和加法端口有 12 个条目的调度队列,与 Nano 的 8 + 24 分割不同。
执行端口
我们假设陆家嘴保留了 Nano 的大部分端口布局和执行单元。因为内核是 2 宽的,所以很难确定哪些执行单元是在独立的端口上。在可能的情况下,我们试图看看哪些指令可以一起开始执行。如果这种技术是不可能的(例如,如果一条指令可以进入两个端口,使内核宽度成为限制,而不是执行端口),我们试图看看它们是否共享一个调度队列。
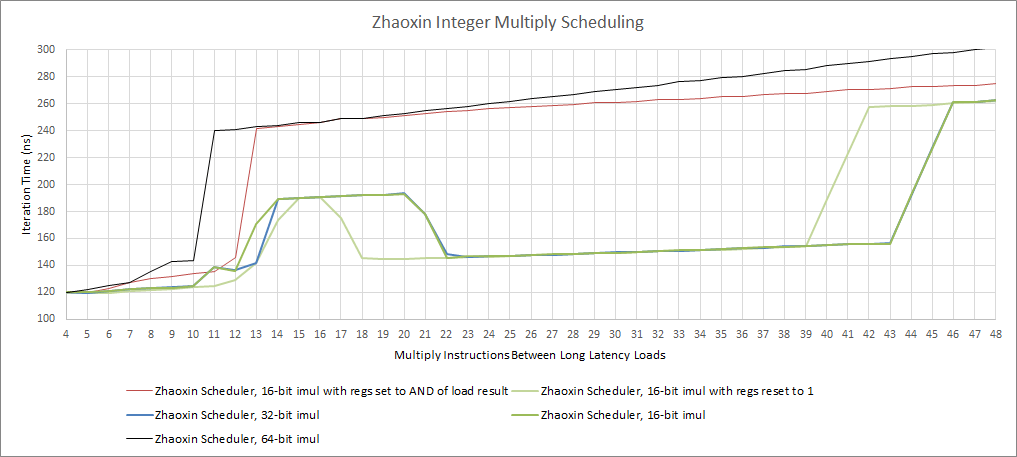
和 Isaiah / Nano 一样,陆家嘴也有两个 ALU 端口,并根据寄存器宽度以不同的方式处理整数乘法。例如,16 位输入的 IMUL 的延迟为 2 个周期。在 64 位乘法的情况下,延迟会上升到 9 个周期。它们还进入了不同的调度队列。浮点吞吐量没有变化。
兆芯在某些方面也加强了执行引擎。现在有两个 128 位矢量整数 ALU,而不是 Isaiah 的一个。陆家嘴也得到了一个额外的负载管道,让它每个周期可以从 L1 数据缓存中维持两个 128 位的负载。
另一方面,陆家嘴失去了 Isaiah 令人印象深刻的 2 周期浮点加器。FP 加法器的延迟现在是 3 个周期。
AVX——纸面上支持,实践中不实用
Tomshardware 将陆家嘴的 AVX 性能描述为 "不合格",我们可以很容易地看到原因。256 位 AVX 指令被分成两个 128 位的微操作,因此消耗了两个调度器条目。由于内核似乎是两个微操作的宽度,使用 AVX 指令并不能提供比 SSE 更多的吞吐量优势。
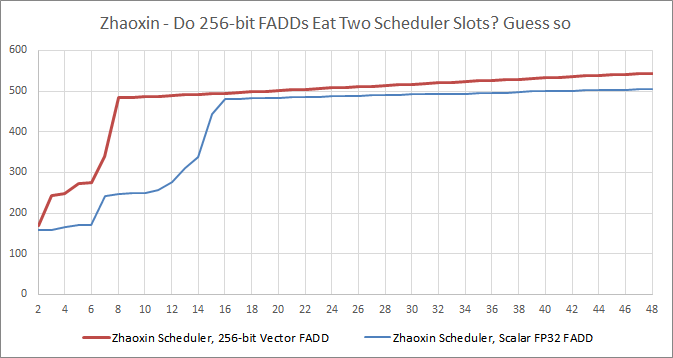
256 位 AVX 指令消耗了两倍的调度器条目,表明它们被分割成 2×128 位微操作。X 轴 = 长延时负载之间的指令,Y 轴 = 迭代延时,单位为纳秒
但事情变得更糟。256位指令的重新排序能力下降到了一半以下:
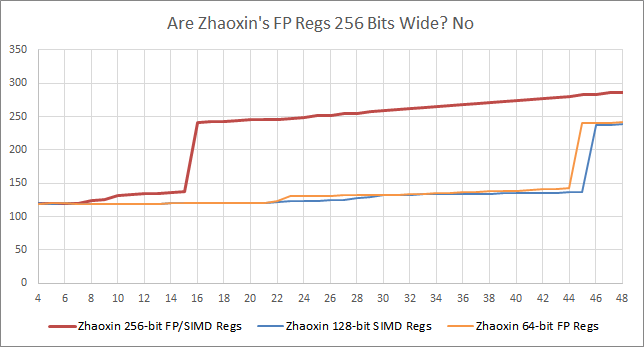
看起来 256 位 AVX 指令消耗了两个以上的 ROB 插槽。对于一个已经很小的 ROB 的内核来说,这是一个令人担忧的惩罚。从这个角度来看,AMD 的 K10 架构有一个 72 条 ROB,并因 ROB 的填充而受到严重影响:
K10 的 72 条 ROB 已经相当频繁地填满了。陆家嘴的 48 个条目的 ROB 更小,所以从存储 256 位状态中失去更多的条目会受到伤害。
256 位操作会因为陆家嘴的延迟增加而进一步受到影响:
| 指令 | 延迟 | 吞吐量 |
| 128-bit FP Add | 3 clocks | 1 per clock |
| 128-bit FP Multiply | 3 clocks | 1 per clock |
| 256-bit FP Add | 5.8 clocks | 0.5 per clock |
| 256-bit FP Multiply | 5 clocks | 0.5 per clock |
兆芯 KX-6640MA 上测量的矢量浮点运算的吞吐量和延迟情况
兆芯在陆家嘴上的 AVX 实现看起来只是为了确保与较新软件的兼容性而做的最小努力。打桩机和Zen 1 也将 256 位 AVX 指令分成两个 128 位的微操作,但保持延迟不变。而且,他们并没有受到超出你对解码为两个微操作的指令所期望的惩罚。在这两种 AMD 架构上使用 256 位 AVX 指令是完全可以的。你不会得到重新排序能力或数学吞吐量的增加,但你仍然得到更好的代码密度。
另一方面,在陆家嘴上应该避免使用 256 位 AVX。任何指令密度的优势都被增加的执行延迟和减少的重排能力的组合所抵销。
加载 加载 加载,储存 储存 储存 储存
Isaiah 的加载和存储队列相当小,每条都是 16 个入口。陆家嘴将加载和存储队列分别增加到 24 个和 22 个条目,实现了一代的改进。
和 Isaiah 一样,陆家嘴似乎缺乏对内存依赖性的预测。负载不能在有未知地址的存储之前被重新排序。这是在 Core 2 中首次出现时的一个闪亮的新功能,但今天几乎所有的高性能内核都可以做到这一点。
现在把所有这些放在一起
利用我们收集的所有数据,我们已经能够创建一个陆家嘴的大致方框图。
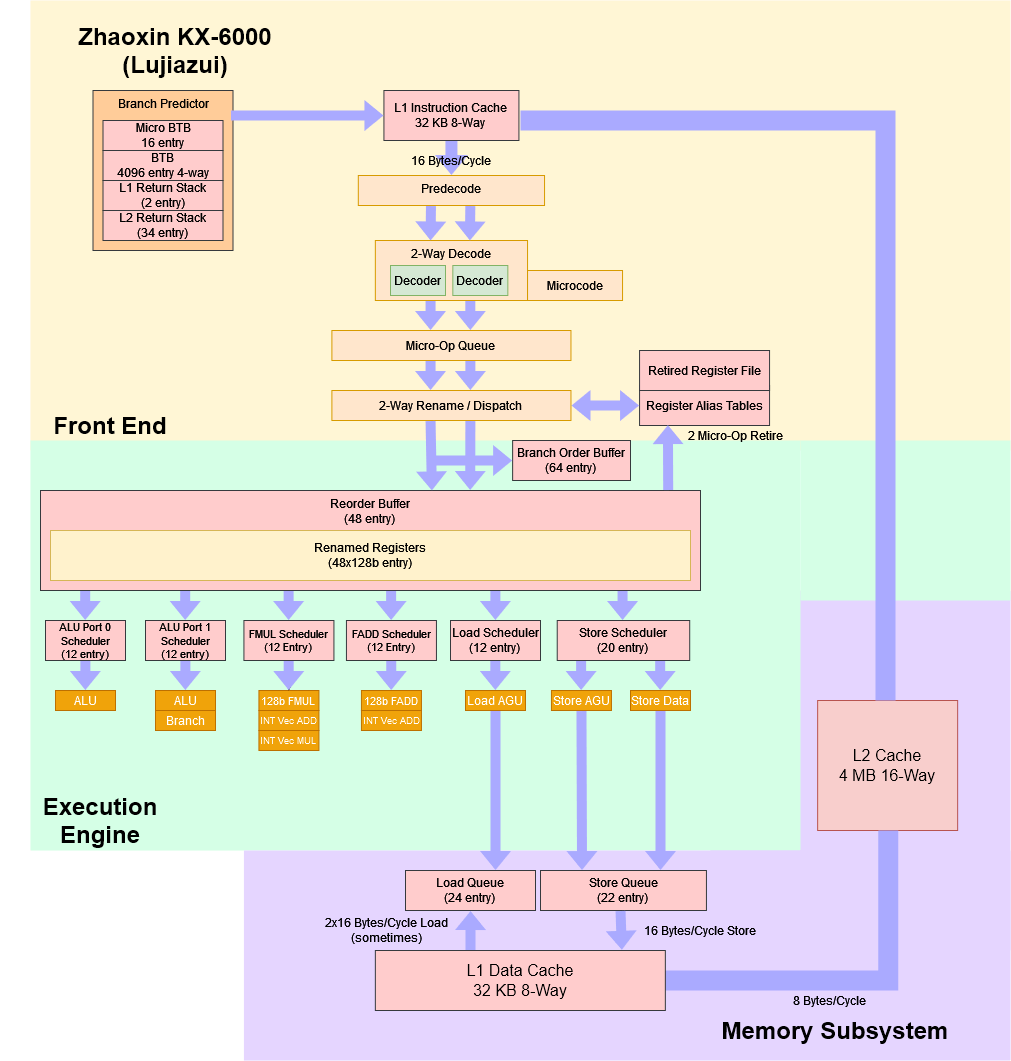
总结
五道口和陆家嘴在很大程度上不只是一个换皮的 Isaiah。它是一个明显不同的设计,对威盛最初的 Nano 设计进行了修剪和重新平衡,让它在适度增加 IPC 的情况下达到更高的时钟速度。
但陆家嘴绝对是一个没有高性能追求的低功率核心。很多变化似乎都是针对芯片面积和电源效率,而不是性能。十年来,25% 的 IPC 增益远远不足以赶上 AMD 或英特尔。就每核性能而言,当代高性能的英特尔和 AMD 的 CPU 完全扫平了陆家嘴。
在某些方面,陆家嘴是 Nano 的翻版。从纸面上看,Nano 是一个低功耗内核,但其架构比几年后推出的低功耗内核更强大,而且与当代高性能设计相差无几。同时,陆家嘴的目标是与英特尔和 AMD 的大核竞争,但离这个目标还差得远。AMD 的 Jaguar 和英特尔的 Goldmont 可能是更好的对比点。
现在这篇文章已经变得很长了,所以兆芯与 Nano 的基准测试将不得不等待第三部分,但我要说的是,兆芯声称的每时钟多 25% 的性能并不只是吹牛。
附录
P6 风格的 ROB 和寄存器文件
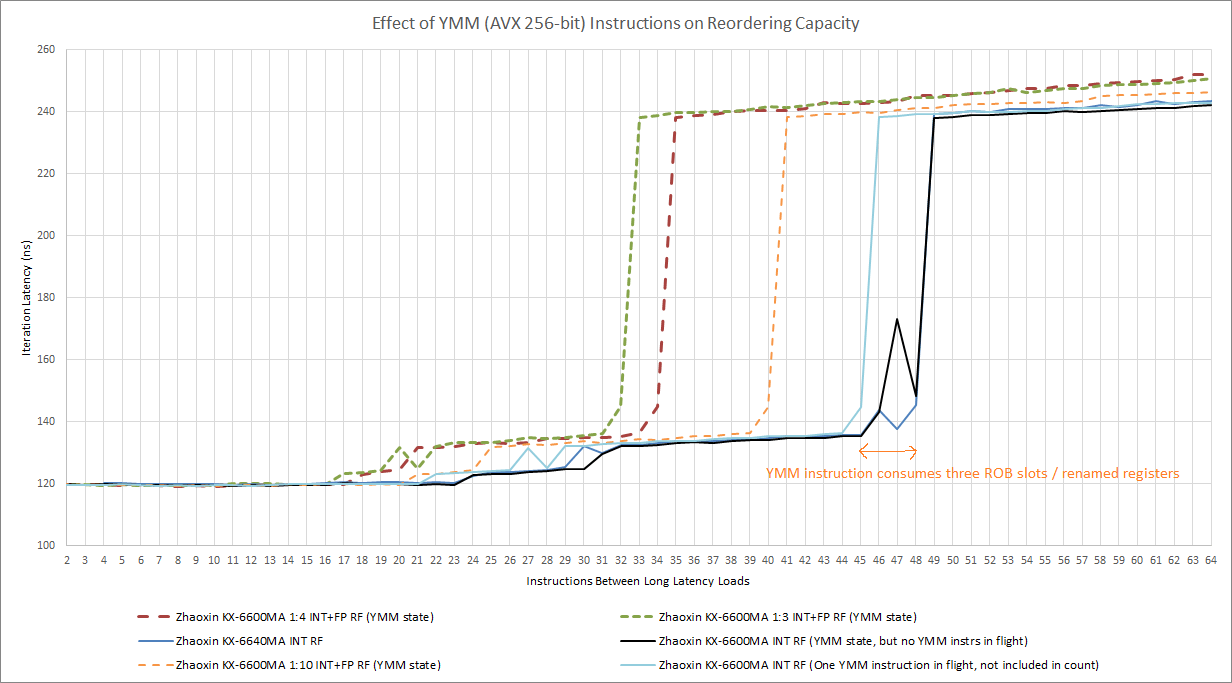
当混合使用整数和 256 位 AVX 指令时,我们看到一个重命名的寄存器文件用于两者。在独立的整数和 FP 寄存器文件中,混合使用整数和 FP 寄存器文件会将你的寄存器限制的重排能力增加到两者之和(这通常意味着 ROB 能力成为极限)。但是在陆家嘴,混入 256 位 AVX 指令会降低重排能力,所以整数和矢量指令会竞争性地共享一个寄存器文件。
而且正如我们前面提到的,256 位 AVX 指令似乎要消耗两个以上的 ROB 插槽/重命名寄存器。如果我们有一条 256 位 AVX 指令被一个长延迟的负载阻挡了,在第二个负载被阻挡进入后端之前,我们只能在飞行中得到 45 个整数添加。
即使没有 256 位 AVX 指令等待退役,仅仅在 YMM 寄存器中存在 256 位的值就会影响陆家嘴的 ROB/RF 入口回收逻辑。从黑线可以看出,有 YMM 状态会在我们到达 48 位前不久引入一个尖峰。这个结果是可以重复的,而且不是噪音。
我们很惊讶地看到一个较新的 CPU 有较少的重排能力,所以我们尝试了一批其他的东西,看看我们是否能让长延迟的负载在它们之间有超过 48 条指令的并行执行。
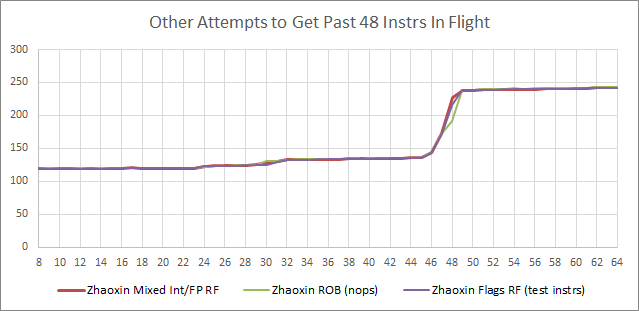
X轴 = 负载之间的指令,Y轴 = 迭代延迟(纳秒)。
在这些尝试中,只有一个使用未提取的分支的尝试是成功的(如前所述)。另外,在后端不得不让前端停滞之前,兆芯可以有大约 20 个已取的分支待退。
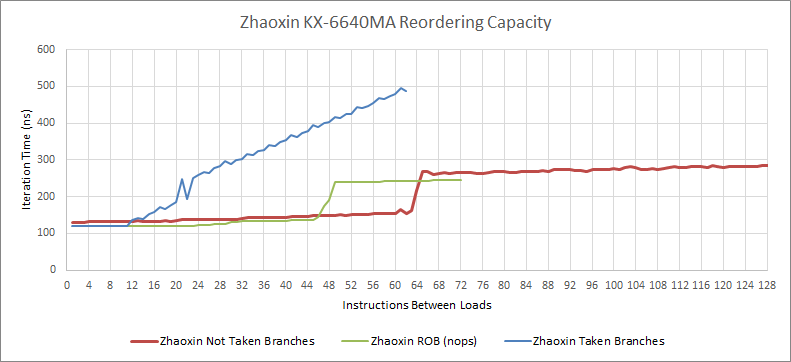
有趣的是,陆家嘴的分支跟踪是与 ROB 解耦的,尽管我们没有发现快速(检查点)错误预测恢复的证据
整数乘法
陆家嘴在 32 位和 16 位的乘法上也有令人难以置信的奇怪行为。重新排序的能力根据被乘的数值而变化,所以 CPU 可能会在调度器满的时候消除乘法(比如当输入为 1 时)。
部分 AVX2 支持
官方说,陆家嘴支持 AVX,但不支持 AVX2。AVX2 包括 FMA(fused multiply add)和 256 位整数指令。正如预期的那样,FMA 指令会产生一个故障。然而,256 位的整数指令似乎可以正确工作。就像 AVX/FP 一样,256 位整数指令被解码成两个 128 位微操作。有趣的是,与 128 位运算相比,256 位打包的整数乘法并没有遭受额外的延迟。
| 延迟 | 吞吐量 | |
| 128-bit Integer Add | 1 clock | 2 per cycle |
| 128-bit Integer Multiply | 3 clocks | 1 per cycle |
| 256-bit Integer Add | 1.66 clocks | 1 per cycle |
| 256-bit Integer Multiply | 3 clocks | 0.5 per cycle |
使用不支持(但可以工作)的 AVX2 指令的性能
另外,256 位整数加法并没有像严重的 256 位浮点运算那样降低重排能力。这一点相当奇怪——无论 256 位寄存器是被整数还是浮点指令访问,Zen 1 都会给出相同的结果。
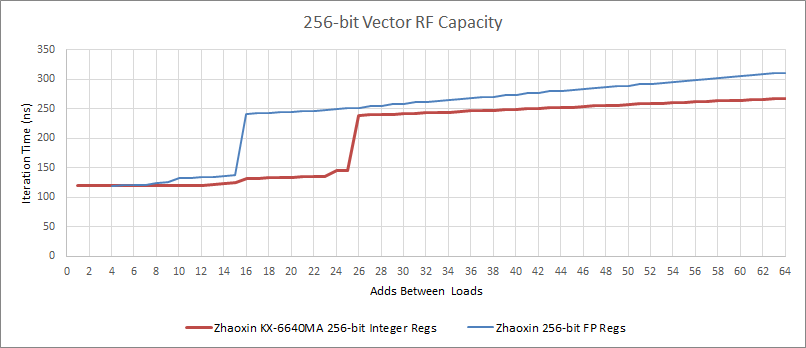
因为陆家嘴有两个 128 位的整数端口,每个端口都有自己的调度队列,256 位的整数操作最终也得到了更多的调度能力。
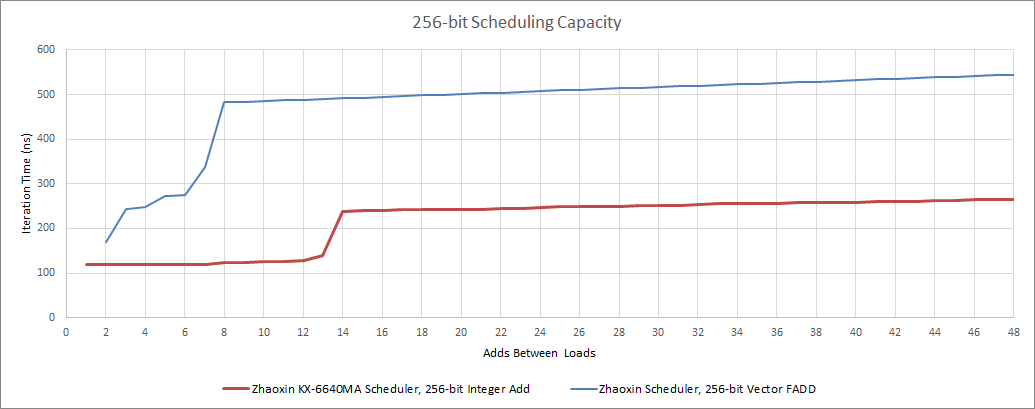
看起来兆芯在 256 位整数操作方面实际上已经做得很好了,但由于他们不支持 AVX2 的其他部分(即FMA)而无法暴露出来。
解释 FP 调度器的结果
如果你特别有眼力,你可能已经注意到我们的 FP 调度器图有多个延迟跳跃。这是因为为浮点指令创建一个依赖关系并不是 100% 直接的。整数指令的依赖性很容易——只要让测试指令消耗长延时负载的结果来阻止退休。
为 FP 指令创建依赖关系的一种方法是将整数加载结果转换成浮点(cvtsi2ss)。但是 cvtsi2ss 指令本身可能会消耗一个浮点调度器插槽。所以在大多数情况下,我们用长延时加载的结果来索引到一个单独的浮点值数组。对于这些测试,我们看的是延迟的最后一跳,因为那显示了只有一个负载在并行执行时的情况。下面是一个直观的解释,测试循环被解开(因为它在 CPU 的后端会有)。
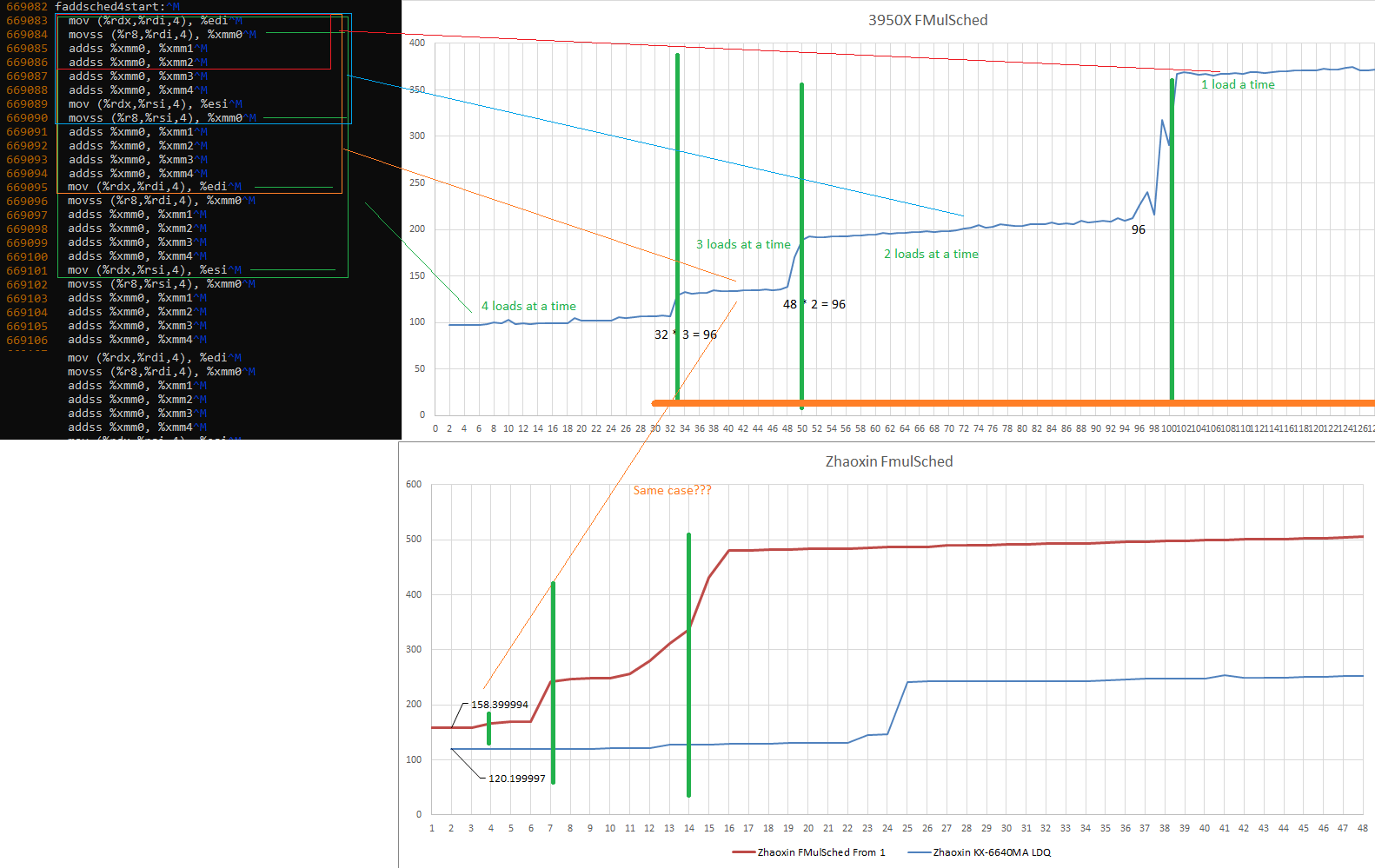
是的,这些图是针对乘法的,但也显示了加法。同样的概念。另外,兆芯并不像 Zen 2 那样完全叠加负载。我们为 Zen 2 得到了 96-100 个 "调度器 "条目,因为我们无法用这个测试来区分调度队列和非调度队列。
假设前两个追逐指针的负载已经完成。也就是把结果放入寄存器 edi 和 esi 的负载。标有绿线的负载是准备执行的负载。
第一个,最低的延迟拉伸是当 CPU 只受内存延迟和可用指令级并行的限制。然后,随着 CPU 的失序引擎能够看到更少的负载(因为FP调度器被填满了,阻止它接受更多的指令),迭代延迟增加。















 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









