import java.util.regex.*;
//匹配汉字、字符串、数字
public class Test9
{
public static void main(String[] args)
{
String regEx1 = "[\\u4e00-\\u9fa5]";
String regEx2 = "[a-z||A-Z]";
String regEx3 = "[0-9]";
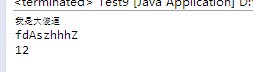
String str = "1 2fdAsz我是hhhZ大傻逼";
String s1 = matchResult(Pattern.compile(regEx1),str);
String s2 = matchResult(Pattern.compile(regEx2),str);
String s3 = matchResult(Pattern.compile(regEx3),str);
System.out.println(s1+"\n"+s2+"\n"+s3);
}
public static String matchResult(Pattern p,String str)
{
StringBuilder sb = new StringBuilder();
Matcher m = p.matcher(str);
while (m.find())
for (int i = 0; i <= m.groupCount(); i++)
{
sb.append(m.group());
}
return sb.toString();
}
}























 5750
5750

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









