






1、Beautiful Soup库是解析、遍历、维护“标签树”的功能库。BeautifulSoup对应于HTML/XML文档的全部内容。
2、Beautiful Soup库的引用:from bs4 import BeautifulSoup
3、Beautiful Soup库的解析器

4、Beautiful Soup类的基本元素

5、使用beautifulsoup提取丁香园论坛特定帖子的所有回复内容,包括回复人信息。
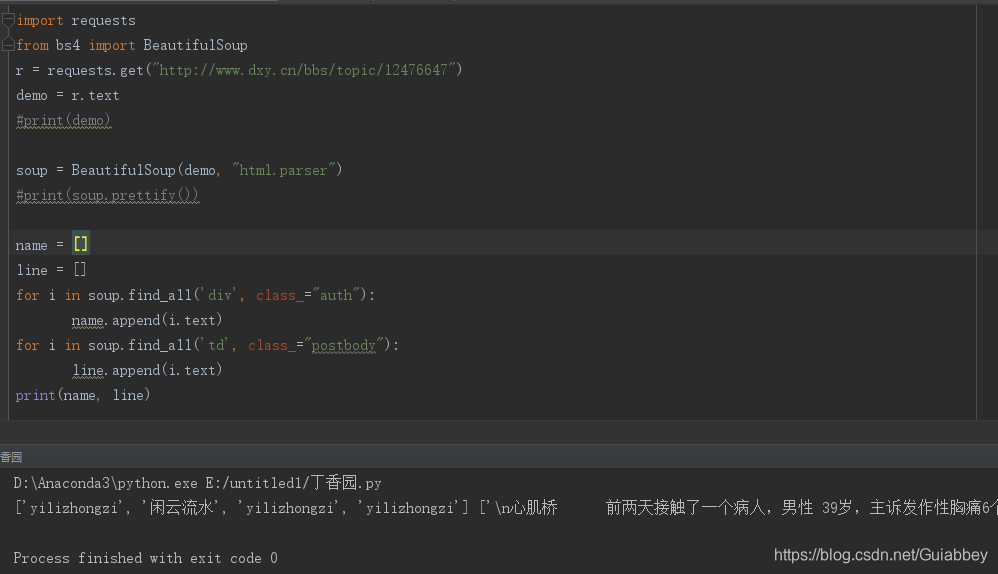
搞了很久,第一次接触爬虫实在是不太会。。。。继续加油!














03-21
 1246
1246
1246
04-26
04-26
06-02
“相关推荐”对你有帮助么?
-

 非常没帮助
非常没帮助 -

 没帮助
没帮助 -

 一般
一般 -

 有帮助
有帮助 -

 非常有帮助
非常有帮助
提交

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









