








URL全面解析
开始
什么是 URL
这应该是相当简单的,但让我们说清楚。 URL 是网页的地址,可以在浏览器中输入以获取该网页的唯一内容。 可以在地址栏中看到它:
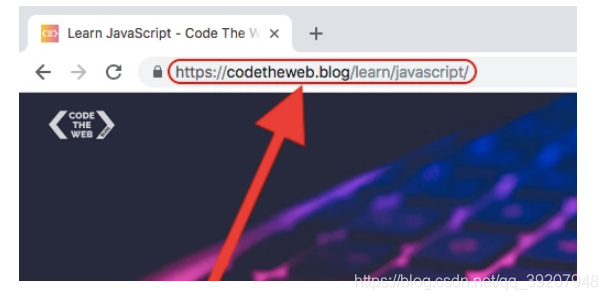
URL 是统一资源定位符,对可以从互联网上得到的资源的位置和访问方法的一种简洁的表示,是互联网上标准资源的地址。互联网上的每个文件都有一个唯一的 URL,它包含的信息指出文件的位置以及浏览器应该怎么处理它。
此外,如果你不熟悉基本 URL 路径的工作方式,可以查看此文学习。
URL 不都长的一样的
这是一个快速提醒 - 有时 URL 可能非常奇怪,如下:
https://example.com:1234/page/?a=b
https://154.23.54.156/page?x=...
file:///Users/username/folder/file.png
获取当前URL
获取当前页面的 URL 非常简单 - 我们可以使用 window.location。
试着把这个添加到我们形如写的的脚本中:
console.log(window.location);
查看浏览器的控制台:

不是你想要的?这是因为它不返回你在浏览器中看到的实际 URL 地址——它返回的是一个 URL 对象。使用这个 URL 对象,我们可以解析 URL 的不同部分,接下来就会讲到。
创建 URL 对象
很快就会看到,可以使用 URL 对象来了解 URL 的不同部分。如果你想对任何 URL 执行此操作,而不仅仅是当前页面的 URL,该怎么办? 我们可以通过创建一个新的 URL 对象来实现。 以下是如何创建一个:
var myURL = new URL('https://example.com');
就这么简单! 可以打印 myURL 来查看 myURL 的内容:
console.log(myURL);
出于本文的目的,将 myURL 设置为这个值:
var myURL = new URL('https://example.com:4000/folder/page.html?x=y&a=b#section-2')
将其复制并粘贴到 <script> 元素中,以便你可以继续操作! 这个 URL 的某些部分可能不熟悉,因为它们并不总是被使用 - 但你将在下面了解它们,所以不要担心!
URL 对象的结构
使用 URL 对象,可以非常轻松地获取 URL 的不同部分。 以下是你可以从 URL 对象获得的所有内容。 对于这些示例,我们将使用上面设置的 myURL。

href
URL 的 href 基本上是作为字符串(文本)的整个 URL。如果你想把页面的 URL 作为字符串而不是 URL 对象,你可以写 window.location.href。
-
console.log(myURL.href);
-
// Output: "https://example.com:4000/folder/page.html?x=y&a=b#section-2"
-
协议 (protocol)
URL的协议是一开始的部分。这告诉浏览器如何访问该页面,例如通过 HTTP 或 HTTPS。 但是还有很多其他协议,比如 ftp(文件传输协议)和 ws(WebSocket)。通常,网站将使用 HTTP 或 HTTPS。
虽然如果你的计算机上打开了文件,你可能正在使用文件协议! URL对象的协议部分包括:,但不包括 //。 让我们看看 myURL 吧!
-
console.log(myURL.
protocol);
-
// Output: "https:"
主机名(hostname)
主机名是站点的域名。 如果你不熟悉域名,则它是在浏览器中看到的URL的主要部分 - 例如 google.com 或codetheweb.blog。
-
console.log(myURL.hostname);
-
// Output: "example.com"
端口(port)
URL 的端口号位于域名后面,用冒号分隔(例如 example.com:1234)。 大多数网址都没有端口号,这种情况非常罕见。
端口号是服务器上用于获取数据的特定“通道” - 因此,如果我拥有 example.com,我可以在多个不同的端口上发送不同的数据。 但通常域名默认为一个特定端口,因此不需要端口号。 来看看 myURL 的端口号:
-
console.log(myURL.port);
-
// Output: "4000"
主机(host)
主机只是主机名和端口放在一起,尝试获取 myURL 的主机:
-
console.log(myURL.host);
-
// Output: "example.com:4000"
来源(origin)
origin 由 URL 的协议,主机名和端口组成。 它基本上是整个 URL,直到端口号结束,如果没有端口号,到主机名结束。
-
console.log(myURL.origin);
-
// Output: "https://example.com:4000"
pathname(文件名)
pathname 从域名的最后一个 “/” 开始到 “?” 为止,是文件名部分,如果没有 “?” ,则是从域名最后的一个 “/” 开始到 “#” 为止 , 是文件部分, 如果没有 “?” 和 “#” , 那么从域名后的最后一个 “/” 开始到结束 , 都是文件名部分。
-
console.log(myURL.pathname);
-
// Output: "/folder/page.html"
锚点(hash)
从 “#” 开始到最后,都是锚部分。可以将哈希值添加到 URL 以直接滚动到具有 ID 为该值的哈希值 的元素。 例如,如果你有一个 id 为 hello 的元素,则可以在 URL 中添加 #hello 就可以直接滚动到这个元素的位置上。通过以下方式可以在 URL 获取 “#” 后面的值:
-
console.log(myURL.hash);
-
// Output: "#section-2"
-
查询参数 (search)
你还可以向 URL 添加查询参数。它们是键值对,意味着将特定的“变量”设置为特定值。 查询参数的形式为 key=value。 以下是一些 URL 查询参数的示例:
?key1=value1&key2=value2&key3=value3
请注意,如果 URL 也有 锚点(hash),则查询参数位于 锚点(hash)(也就是 ‘#’)之前,如我们的示例 URL 中所示:
-
console.log(myURL.search);
-
// Output: "?x=y&a=b"
但是,如果我们想要拆分它们并获取它们的值,那就有点复杂了。
使用 URLSearchParams 解析查询参数
要解析查询参数,我们需要创建一个 URLSearchParams 对象,如下所示:
var searchParams = new URLSearchParams(myURL.search);
然后可以通过调用 searchParams.get('key')来获取特定键的值。 使用我们的示例网址 - 这是原始搜索参数:
?x=y&a=b
因此,如果我们调用 searchParams.get('x'),那么它应该返回 y,而 searchParams.get('a')应该返回 b,我们来试试吧!
-
console.log(searchParams.get(
'x'));
-
// Output: "y"
-
console.log(searchParams.get(
'a'));
-
// Output: "b"
-
扩展
获取 URL 的中参数
方法一:正则法
-
function getUrlParam(name){
-
var regexp=
new
RegExp(
'(^|&)+name+'=([^&]*)(&|$)
','i
');
-
var params=location.search.substr(1).match(regexp);
-
return params ? decodeURIComponent(params[2]) :null;
-
}
-
方法二:split拆分法
-
function getparam(name) {
-
var params=location.search.substr(
1);
-
var arr1=params.split(
"&");
-
for(
let item
of arr1){
-
var arr2=item.split(
"=");
-
if(arr2[
0]==name){
-
return
decodeURIComponent(arr2[
1]);
-
}
-
}
-
}
修改 URL 的中某个参数值
-
//替换指定传入参数的值,paramName为参数,replaceWith为新值
-
function replaceParamVal(paramName,replaceWith) {
-
var oUrl =
this.location.href.toString();
-
var re=
eval(
'/('+ paramName+
'=)([^&]*)/gi');
//构造正则表达式
-
var nUrl = oUrl.replace(re,paramName+
'='+replaceWith);
-
this.location = nUrl;
-
window.location.href=nUrl
-
}
-
原文:
https://codetheweb.blog/2019/...














 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









