







SQL(Structured Query Language 结构化查询语言)是用来操作关系数据库的语言
SQL语句分类
Data Definition Language (DDL数据定义语言)
数据库
(1)创建数据库
①创建数据库:CREATE DATABADE 数据库名;
举例:create database db1;
②判断数据库是否已经存在,不存在则创建数据库:CREATE DATABASE IF NOT EXISTS 数据库名;
举例:create database if not exists db2;
③创建数据库并指定字符集:CREATE DATABASE 数据库名 CHARACTER SET 字符集;
举例:create database db3 default character set gbk;
(2)查看数据库
①查看所有的数据库:show databases;
②查看某个数据库的定义信息
show create database db3;
show create database db1;
(3)修改数据库
修改数据库默认的字符集:ALTER DATABASE 数据库名 DEFAULT CHARACTER SET 字符集;
举例:将db3数据库的字符集改成utf8
alter database db3 character set utf8;
(4)删除数据库:DROP DATABASE 数据库名;
举例:drop database db2;
(5)使用数据库
①查看正在使用的数据库:SELECT DATABASE(); 使用的一个mysql中的全局函数
②使用/切换数据库:USE 数据库名;
表
(1)创建表
①创建表的格式
CREATE TABLE 表名 (
字段名1 字段类型1,
字段名2 字段类型2
);
比如:CREATE TABLE Persons
(
PersonID int,
LastName varchar(255),
FirstName varchar(255),
Address varchar(255),
City varchar(255)
);
②快速创建一个表结构相同的表
CREATE TABLE 新表名 LIKE 旧表名;
③创建表时约束
CREATE TABLE table_name
(
column_name1 data_type(size) 约束名,
column_name2 data_type(size) 约束名,
column_name3 data_type(size) 约束名,
);
在 SQL 中,我们有如下约束:
- NOT NULL - 指示某列不能存储 NULL 值。
- UNIQUE - 保证某列的每行必须有唯一的值。
- PRIMARY KEY - NOT NULL 和 UNIQUE 的结合。确保某列(或两个列多个列的结合)有唯一标识,有助于更容易更快速地找到表中的一个特定的记录,每个表有且只有一个主键。
- FOREIGN KEY - 保证一个表中的数据匹配另一个表中的值的参照完整性,一个表中的 FOREIGN KEY 指向另一个表中的 UNIQUE KEY(唯一约束的键)。
- CHECK - 保证列中的值符合指定的条件。
- DEFAULT - 规定没有给列赋值时的默认值。
比如:CREATE TABLE Persons ( ID int NOT NULL, LastName varchar(255) NOT NULL, FirstName varchar(255) NOT NULL, Age int,CONSTRAINT chk_Person CHECK (P_Id>0 AND City='Sandnes') );
④创建表时,主键自动新增
Auto-increment 会在新记录插入表中时生成一个唯一的数字
CREATE TABLE Persons
(
ID int NOT NULL AUTO_INCREMENT,
LastName varchar(255) NOT NULL,
FirstName varchar(255),
Address varchar(255),
City varchar(255),
PRIMARY KEY (ID)
)
创建视图
基于制成的表格,也可以制作仅从用户角度看到的、虚拟的表格,即视图。
CREATE VIEW 高价商品(商品编码,商品名称,单价) AS SELECT * FROM 商品 WHERE 单价>=200;
(2)查看表
①查看某个数据库中的所有表:SHOW TABLES;
②查看表结构:DESC 表名;
③查看创建表的SQL语句:SHOW CREATE TABLE 表名;
(3)修改表
①添加表列ADD:ALTER TABLE 表名 ADD 列名 类型;
ALTER TABLE Persons ADD UNIQUE (P_Id); 在 "P_Id" 列创建 UNIQUE 约束
②修改列类型MODIFY:ALTER TABLE 表名 MODIFY列名;
ALTER TABLE Persons MODIFY Age int NOT NULL;
③修改列名 CHANGE:ALTER TABLE 表名 CHANGE 旧列名 新列名 类型;
④删除列 DROP:ALTER TABLE 表名 DROP 列名;
⑤修改表名:RENAME TABLE 表名 TO 新表名;
⑥修改字符集character set:ALTER TABLE 表名 character set 字符集;
(4)删除表
①直接删除:DROP TABLE 表名;
②判断表是否存在,如果存在则删除表:DROP TABLE IF EXISTS 表名;
如果我们仅仅需要删除表内的数据,但并不删除表本身,使用 TRUNCATE TABLE 语句:TRUNCATE TABLE table_name
Data Manipulation Language(DML数据操纵语言)
插入:INSERT
INSERT INTO 语句用于向表中插入新记录
①无需指定要插入数据的列名,只需提供被插入的值即可:
INSERT INTO table_name VALUES (value1,value2,value3,...);
②需要指定列名及被插入的值:
INSERT INTO table_name (column1,column2,column3,...) VALUES (value1,value2,value3,...);
INSERT INTO "public"."student" ("id", "name", "age", "gender") VALUES ('301001', '小明', '10', '男');
SELECT INTO 语句从一个表复制数据,然后把数据插入到另一个新表中
SELECT * INTO newtable FROM table1;
SELECT column_name(s) INTO newtable FROM table1;
也可以:CREATE TABLE 新表 AS SELECT * FROM 旧表
INSERT INTO SELECT 语句从一个表复制数据,然后把数据插入到一个已存在的表中
INSERT INTO table2 SELECT * FROM table1;举例:INSERT into 表A SELECT * from 表B where city_adcode = '411700';
INSERT INTO table2(column_name(s)) SELECT column_name(s) FROM table1;举例:INSERT INTO Websites (name, country) SELECT app_name, country FROM apps;
更新:UPDATE
UPDATE 语句用于更新表中已存在的记录
UPDATE table_name SET column1=value1,column2=value2,... WHERE some_column=some_value;
删除:DELETE
DELETE 语句用于删除表中的记录
删除某些数据:
DELETE FROM table_name WHERE some_column=some_value;
删除表中的所有数据:
DELETE FROM table_name;或 DELETE * FROM table_name;
Data Query Language(DQL 数据查询语言)
SELECT
①SELECT 列名(若是全部列 *) FROM 表名 WHERE 限制条件;
= 等于
<> 不等于。注释:在 SQL 的一些版本中,该操作符可被写成 !=
> 大于
< 小于
>= 大于等于
<= 小于等于
BETWEEN 在某个范围内
LIKE 搜索某种模式
IN 指定针对某个列的多个可能值
=:SELECT * FROM 商品 WHERE 单价 = 200;
like:SELECT * FROM Websites WHERE name LIKE 'G%';#选取 name 以字母 "G" 开始的所有客户
SELECT * FROM Websites WHERE name LIKE '%k';#选取 name 以字母 "k" 结尾的所有客户
SELECT * FROM Websites WHERE name LIKE '%oo%';#选取 name 包含模式 "oo" 的所有客户
SELECT * FROM Websites WHERE name NOT LIKE '%oo%';#选取 name 不包含模式 "oo" 的所有客户
SELECT * FROM Websites WHERE name LIKE '_oogle';#选取 name 以一个任意字符开始,然后是 "oogle" 的所有客户
其中,%是通配符,替代 0 个或多个字符, _ 通配符替代一个字符
in:SELECT column_name(s) FROM table_name WHERE column_name IN (value1,value2,...);
比如:SELECT * FROM Websites WHERE name IN ('Google','菜鸟教程');
BETWEEN:SELECT column_name(s) FROM table_name WHERE column_name BETWEEN value1 AND value2;
比如:SELECT * FROM Websites WHERE id BETWEEN 1 AND 20;
SELECT * FROM Websites WHERE id NOT BETWEEN 1 AND 20;
带有文本值的 BETWEEN 操作符实例
SELECT * FROM Websites WHERE name BETWEEN 'A' AND 'H';选取 name 以介于 'A' 和 'H' 之间字母开始的所有网站
SELECT * FROM Websites WHERE name NOT BETWEEN 'A' AND 'H';选取 name 不介于 'A' 和 'H' 之间字母开始的所有网站
带有日期值的 BETWEEN 操作符实例
SELECT * FROM access_log WHERE date BETWEEN '2016-05-10' AND '2016-05-14';
②检索 空值
SELECT * FROM 商品 WHERE 单价 IS NULL
③使用 子查询 检索(Subquery)
非相关子查询的执行不依赖与外部的查询。
执行过程:
(1)执行子查询,其结果不被显示,而是传递给外部查询,作为外部查询的条件使用
(2)执行外部查询,并显示整个结果
SELECT * FROM 商品 WHERE 商品编码 IN (SELECT 商品编码 FROM 销售明细 WHERE 数量>=1000);
SElECT 图书名,作者,出版社,价格 FROM Books WHERE 价格 > ( SELECT AVG(价格) FROM Books );
④使用相关子查询(correlated subquery)
相关子查询的执行依赖于外部查询的数据,外部查询执行一行,子查询就执行一次
相关子查询的执行依赖于外部查询,多数情况下是子查询的WHERE子句中引用了外部查询的表
执行过程:
(1)从外层查询中取出一个元组,将元组相关列的值传给内层查询
(2)执行内层查询,得到子查询操作的值
(3)外查询根据子查询返回的结果或结果集得到满足条件的行
(4)然后外层查询取出下一个元组重复做步骤1-3,直到外层的元组全部处理完毕
SELECT * FROM 销售明细 U WHERE 数量 > (SELECT AVG (数量) FROM 销售明细 WHERE 商品编码 = U.商品编码);
SELECT FROM Books As a WHERE 价格 > ( SELECT AVG(价格) FROM Books AS b WHERE a.类编号=b.类编号 );
⑤SELECT DISTINCT 语句用于返回唯一不同的值
SELECT DISTINCT 列名 FROM 表名;
⑥AND & OR 运算符用于基于一个以上的条件对记录进行过滤
SELECT * FROM Websites WHERE country='CN' AND alexa > 50;第一个条件和第二个条件都成立
SELECT * FROM Websites WHERE country='USA' OR country='CN';第一个条件和第二个条件中只要有一个成立
⑦ORDER BY 关键字用于对结果集进行排序
SELECT column_name,column_name FROM table_name ORDER BY column_name,column_name ASC|DESC;(按照多列升序/降序排列)
⑧SELECT TOP, LIMIT, ROWNUM 子句规定要返回的记录的数目
并非所有的数据库系统都支持 SELECT TOP 语句。 MySQL 支持 LIMIT 语句来选取指定的条数数据, Oracle 可以使用 ROWNUM 来选取。
SQL Server / MS Access:SELECT TOP number|percent column_name(s) FROM table_name;
MySQL:SELECT column_name(s) FROM table_name LIMIT number;比如SELECT * FROM Persons LIMIT 5;
Oracle:SELECT column_name(s) FROM table_name WHERE ROWNUM <= number;比如SELECT * FROM Persons WHERE ROWNUM <=5;
⑨JOIN:SQL join 用于把来自两个或多个表的行结合起来

举例:两个表,websites表(表A)、access_log表(表B)如下:
websites表:
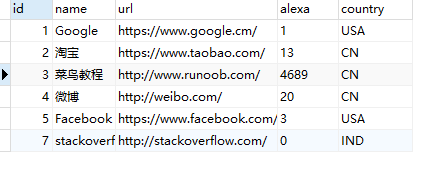
access_log表:

最常见的 JOIN 类型:SQL INNER JOIN(简单的 JOIN)。 SQL INNER JOIN 从多个表中返回满足 JOIN 条件的所有行,如果表中有至少一个匹配,则返回行。
SELECT column_name(s) FROM table1 INNER JOIN table2 ON table1.column_name=table2.column_name;
SELECT column_name(s) FROM table1 JOIN table2 ON table1.column_name=table2.column_name;
SELECT * from websites a inner join access_log b on a.id = b.site_id where a.id = '1';
SELECT * from websites a , access_log b where a.id = b.site_id and a.id = '1';结果:

LEFT JOIN:即使右表中没有匹配,也从左表返回所有的行和列。如果右表中没有匹配,则响应列结果为 NULL。
SELECT column_name(s) FROM table1 LEFT JOIN table2 ON table1.column_name=table2.column_name;
SELECT column_name(s) FROM table1 LEFT OUTER JOIN table2 ON table1.column_name=table2.column_name;
SELECT * from websites a left join access_log b on a.id = b.site_id and a.id = '1';
结果:
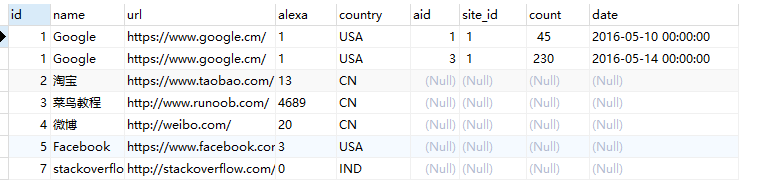
RIGHT JOIN:即使左表中没有匹配,也从右表返回所有的行。如果左表中没有匹配,则结果为 NULL。
SELECT column_name(s) FROM table1 RIGHT JOIN table2 ON table1.column_name=table2.column_name;
SELECT column_name(s) FROM table1 RIGHT OUTER JOIN table2 ON table1.column_name=table2.column_name;
SELECT * from websites a right join access_log b on a.id = b.site_id and a.id = '1';
结果:

FULL JOIN:只要其中一个表中存在匹配,则返回行,结合了 LEFT JOIN 和 RIGHT JOIN 的结果。
SELECT column_name(s) FROM table1 FULL OUTER JOIN table2 ON table1.column_name=table2.column_name;
(MySQL本身不支持ull join(全连接))
⑩UNION
合并两个或多个 SELECT 语句的结果(UNION 内部的每个 SELECT 语句必须拥有相同数量的列。列也必须拥有相似的数据类型。同时,每个 SELECT 语句中的列的顺序必须相同),默认地,UNION 操作符选取不同的值。如果允许重复的值,请使用 UNION ALL。UNION 结果集中的列名总是等于 UNION 中第一个 SELECT 语句中的列名。
SELECT column_name(s) FROM table1 UNION SELECT column_name(s) FROM table2;
SELECT country, name FROM Websites WHERE country='CN' UNION ALL SELECT country, app_name FROM apps WHERE country='CN' ORDER BY country;
⑪分组计算
将数据分组化,可以求取每一组的统计值:SELECT 地域,AVG(单价) FROM 商品 GROUP BY 地域;
分组后增加限定条件(用HAVING 而不是 WHERE):SELECT 地域,AVG(单价) FROM 商品 GROUP BY 地域 HAVING AVG(单价)>=200;
⑫CASE WHEN函数
CASE column
WHEN <condition> THEN value
WHEN <condition> THEN value
......
ELSE value END
举例:
select case sex WHEN "1" THEN "男"
WHEN "2" THEN "女"
ELSE "其他" END from student;当sex为1值,给其重新赋值为“男”,同理,当sex为2值,给其重新赋值为“女”,都不是时,赋值为“其他”,END表示结束。
THEN后边的值与ELSE后边的值类型应一致,否则会报错。
引用:SQL之CASE WHEN用法详解__Rt-CSDN博客_case when用法
场景1:有分数score,score<60返回不及格,score>=60返回及格,score>=80返回优秀
SELECT
STUDENT_NAME,
(CASE WHEN score < 60 THEN '不及格'
WHEN score >= 60 AND score < 80 THEN '及格'
WHEN score >= 80 THEN '优秀'
ELSE '异常' END) AS REMARK
FROM
TABLE
场景2:统计班中,有多少男同学,多少女同学,并统计男同学中有几人及格,女同学中有几人及格,要求用一个SQL输出结果。
SELECT
SUM (CASE WHEN STU_SEX = 0 THEN 1 ELSE 0 END) AS MALE_COUNT,
SUM (CASE WHEN STU_SEX = 1 THEN 1 ELSE 0 END) AS FEMALE_COUNT,
SUM (CASE WHEN STU_SCORE >= 60 AND STU_SEX = 0 THEN 1 ELSE 0 END) AS MALE_PASS,
SUM (CASE WHEN STU_SCORE >= 60 AND STU_SEX = 1 THEN 1 ELSE 0 END) AS FEMALE_PASS
FROM
THTF_STUDENTS
场景3:统计各个城市,总共使用了多少水耗、电耗、热耗,使用一条SQL语句输出结果
有能耗表如下:其中,E_TYPE表示能耗类型,0表示水耗,1表示电耗,2表示热耗
| E_CODE | E_VALUE | E_TYPE |
|---|---|---|
| 北京 | 28.50 | 0 |
| 北京 | 23.51 | 1 |
| 北京 | 28.12 | 2 |
| 北京 | 12.30 | 0 |
| 北京 | 15.46 | 1 |
| 上海 | 18.88 | 0 |
| 上海 | 16.66 | 1 |
| 上海 | 19.99 | 0 |
| 上海 | 10.05 | 0 |
SELECT
E_CODE,
SUM(CASE WHEN E_TYPE = 0 THEN E_VALUE ELSE 0 END) AS WATER_ENERGY,--水耗
SUM(CASE WHEN E_TYPE = 1 THEN E_VALUE ELSE 0 END) AS ELE_ENERGY,--电耗
SUM(CASE WHEN E_TYPE = 2 THEN E_VALUE ELSE 0 END) AS HEAT_ENERGY--热耗
FROM
THTF_ENERGY_TEST
GROUP BY
E_CODE
输出结果如下:
| E_CODE | WATER_ENERGY | ELE_ENERGY | HEAT_ENERGY |
|---|---|---|---|
| 北京 | 40.80 | 38.97 | 28.12 |
| 上海 | 48.92 | 16.66 | 0 |
场景4:根据城市用电量多少,计算用电成本。假设电能耗单价分为三档,根据不同的能耗值,使用相应价格计算成本。
价格表如下:
| P_PRICE | P_LEVEL | P_LIMIT |
|---|---|---|
| 1.20 | 0 | 10 |
| 1.70 | 1 | 30 |
| 2.50 | 2 | 50 |
当能耗值小于10时,使用P_LEVEL=0时的P_PRICE的值,能耗值大于10小于30使用P_LEVEL=1时的P_PRICE的值...
CASE WHEN energy <= (SELECT P_LIMIT FROM TABLE_PRICE WHERE P_LEVEL = 0) THEN (SELECT P_PRICE FROM TABLE_PRICE WHERE P_LEVEL = 0)
WHEN energy > (SELECT P_LIMIT FROM TABLE_PRICE WHERE P_LEVEL = 0) AND energy <= (SELECT P_LIMIT FROM TABLE_PRICE WHERE P_LEVEL = 1) THEN (SELECT P_PRICE FROM TABLE_PRICE WHERE P_LEVEL = 1)
WHEN energy > (SELECT P_LIMIT FROM TABLE_PRICE WHERE P_LEVEL = 1) AND energy <= (SELECT P_LIMIT FROM TABLE_PRICE WHERE P_LEVEL = 2) THEN (SELECT P_PRICE FROM TABLE_PRICE WHERE P_LEVEL = 2)
场景5:
结合max聚合函数
别名
SQL列名别名:SELECT name AS n, country AS c FROM Websites;
SELECT name, CONCAT(url, ', ', alexa, ', ', country) AS site_info FROM Websites;把三个列(url、alexa 和 country)结合在一起,并创建一个名为 "site_info" 的别名
SQL表名别名:SELECT column_name(s) FROM table_name AS alias_name;
SELECT w.name, w.url, a.count, a.date FROM Websites AS w, access_log AS a WHERE a.site_id=w.id;
Data Control Language(DCL 数据控制语言)
GRANT:授权
ROLLBACK [WORK] TO [SAVEPOINT]:回退到某一点
COMMIT [WORK]:提交
SQL函数
AVG() 函数返回数值列的平均值
SELECT AVG(column_name) FROM table_name
COUNT() 函数返回匹配指定条件的行数
COUNT(*) 函数返回表中的记录数:SELECT COUNT(*) FROM table_name;
COUNT(DISTINCT column_name) 函数返回指定列的不同值的数目:
SELECT COUNT(DISTINCT column_name) FROM table_name;
FIRST() 函数返回指定的列中第一个记录的值
SELECT FIRST(column_name) FROM table_name;
LAST() 函数返回指定的列中最后一个记录的值
SELECT LAST(column_name) FROM table_name;
MAX() 函数返回指定列的最大值
SELECT MAX(column_name) FROM table_name;
MIN() 函数返回指定列的最小值
SELECT MIN(column_name) FROM table_name;
SUM() 函数返回数值列的总数
SELECT SUM(column_name) FROM table_name;
GROUP BY
用于结合聚合函数,根据一个或多个列对结果集进行分组
select F_KCD_BM from TB_KCD c where c.KCD_LX is null GROUP BY F_KCD_BM;
- HAVING 子句,在 SQL 中增加 HAVING 子句原因是,WHERE 关键字无法与聚合函数一起使用,HAVING 子句可以让我们筛选分组后的各组数据。
select * from table_name where id in (select id from table_name group by id having count(id) > 1) ;
EXISTS
EXISTS 运算符用于判断查询子句是否有记录,如果有一条或多条记录存在返回 True,否则返回 False。
SELECT column_name(s) FROM table_name WHERE EXISTS (SELECT column_name FROM table_name WHERE condition);
SELECT Websites.name, Websites.url FROM Websites WHERE EXISTS (SELECT count FROM access_log WHERE Websites.id = access_log.site_id AND count > 200);//查找总访问量(count 字段)大于 200 的网站是否存在
UCASE() 函数把字段的值转换为大写
SQL UCASE() 语法:SELECT UCASE(column_name) FROM table_name;
用于 SQL Server 的语法:SELECT UPPER(column_name) FROM table_name;
LCASE() 函数把字段的值转换为小写
SQL LCASE() 语法:SELECT LCASE(column_name) FROM table_name;
用于 SQL Server 的语法:SELECT LOWER(column_name) FROM table_name;
MID() 函数用于从文本字段中提取字符
SELECT MID(name,1,4) AS ShortTitle FROM Websites;//从 "Websites" 表的 "name" 列中提取前 4 个字符
LEN() 函数返回文本字段中值的长度
SELECT LEN(column_name) FROM table_name;
MySQL 中函数为 LENGTH():SELECT LENGTH(column_name) FROM table_name;
ROUND() 函数用于把数值字段舍入为指定的小数位数
SELECT ROUND(column_name,decimals) FROM table_name;
| column_name | 必需。要舍入的字段。 |
| decimals | 必需。规定要返回的小数位数。 |
ROUND(X): 返回参数X的四舍五入的一个整数
ROUND(X,D): 返回参数X的四舍五入的有 D 位小数的一个数字。如果D为0,结果将没有小数点或小数部分
NOW() 函数返回当前系统的日期和时间
SELECT NOW() FROM table_name;
FORMAT() 函数用于对字段的显示进行格式化
SELECT FORMAT(column_name,format) FROM table_name;
| column_name | 必需。要格式化的字段。 |
| format | 必需。规定格式。 |
RANK()函数
1.rank() over (order by 排序字段 顺序) 别名
顺序可选,如果不写默认ASC。
别名可选。
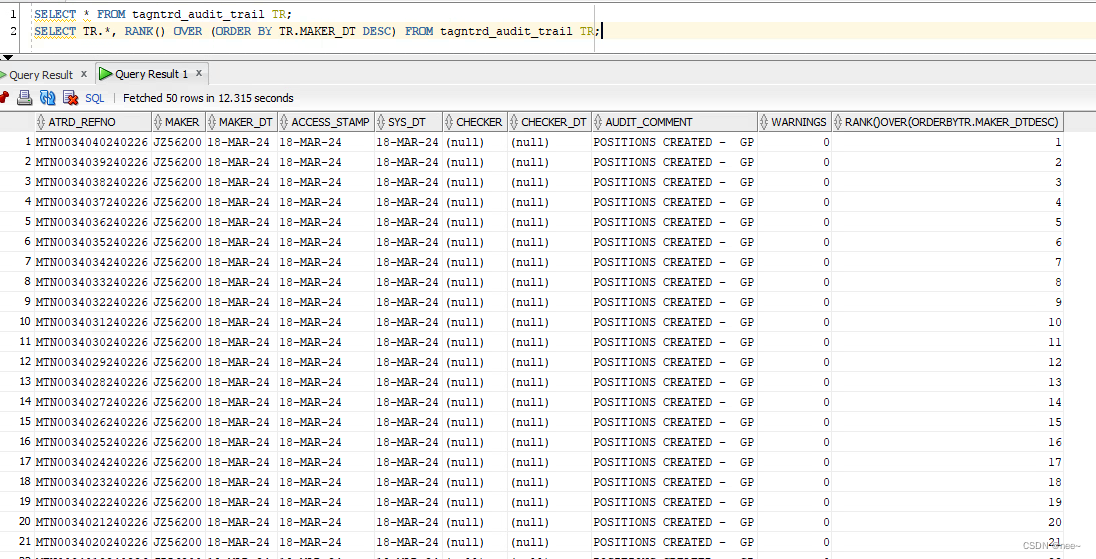
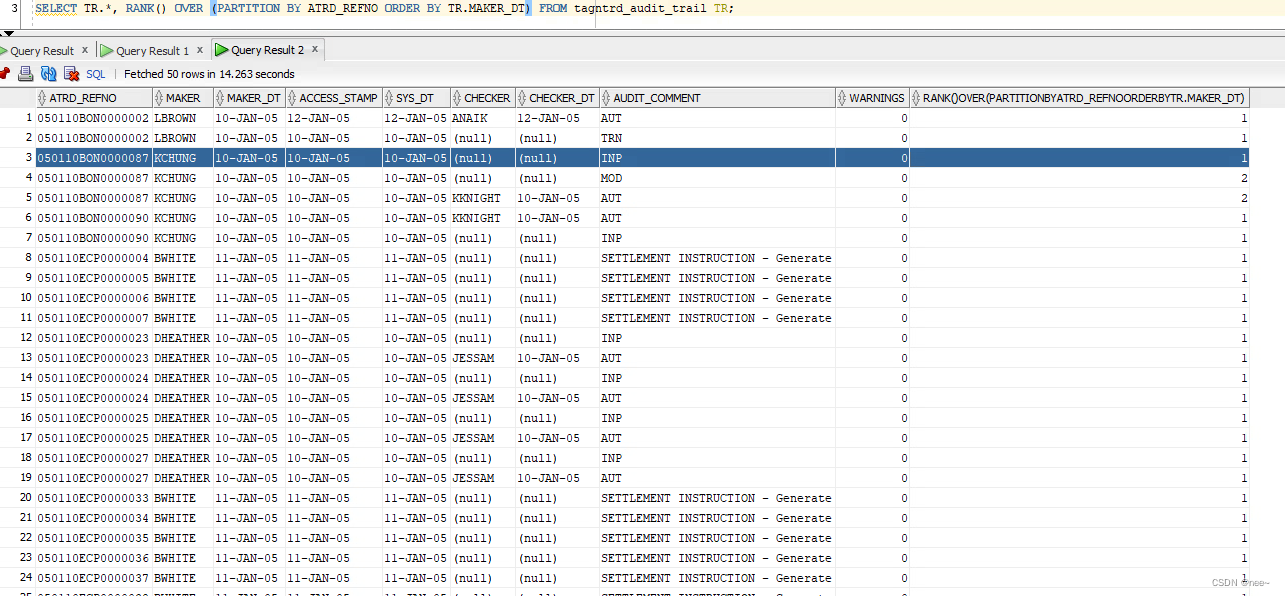
2.rank() over (partition by 分组字段 order by 排序字段 顺序)
分区排名,排序字段要是一样的话也会是一样的名次。
常用SQL语句
查询存在表A但不存在表B的数据
方法一:
子查询统计的是关联上的记录,等于0就是关联不上,就不存在(效率最好)
select * from a where (select count(1) as num from b where b.id = a.id) = 0
方法二:
select distinct a.id from a where a.id not in (select id from b);
方法三:
left join…on… 比较慢

查询数据表里的重复数据
select * from table_name where id in (select id from table_name group by id having count(id) > 1) ;
查询数据表里两个字段一样的数据
Select Name,ID From A group by Name,ID having count (*)>1
查询数据库的数量
select COUNT(*) from 表名;
select COUNT(1) from 表名;
更新数据库里的数据
update 表名 set name = '小花',age = '10' where id ='123456';
update 表名 set 字段=null;
筛选不为空的数据
select F_KCD_BM from TB_KCD c where c.KCD_LX is null GROUP BY F_KCD_BM;
select * from TB_KCD t where t.KCD_LX is null and t.F_KCD_BM in ('Z-WCY','Z-KCY','Z-KLMYCY','DSZ','TH');
查询某一字段包含某些值的数据
select * from 表名 where 字段 like '%A12%';
查询某表的数据按时间顺序排列
倒序:select * from 表名 ORDER BY 时间 DESC;
升序:select * from 表名 ORDER BY 时间 ASC;
清空数据表中的数据
delete from 表名;
同理,delete from 表名 where 条件;
delete from 表名 where id in();
delete from 表名 where id not in();
判断某列是否包含中文字符、英文字符、数字
select * from 表名 where 列名 like '%[吖-座]%' #中文
select * from 表名 where 列名 like '%[a-z]%' #英文
select * from 表名 where 列名 like '%[0-9]%' #数字
SQL正则表达式
MySQL 中使用 REGEXP 或 NOT REGEXP 运算符 (或 RLIKE 和 NOT RLIKE) 来操作正则表达式。

下面的 SQL 语句选取 name 以 "G"、"F" 或 "s" 开始的所有网站:
SELECT * FROM Websites WHERE name REGEXP '^[GFs]';
下面的 SQL 语句选取 name 以 A 到 H 字母开头的网站:
SELECT * FROM Websites WHERE name REGEXP '^[A-H]';
下面的 SQL 语句选取 name 不以 A 到 H 字母开头的网站:
SELECT * FROM Websites WHERE name REGEXP '^[^A-H]';















 1009
1009











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









