






Kafka中所有消息是通过Topic为单位进行管理,每个topic被分为多个分区,分区是是按照Segments存储文件块。每个分区日志是存储在磁盘上的日志序列,Kafka可以保证分区内消息的有序性。其中Leader负责对应分区的读写、Follower负责同步分区的数据,0.11 版本之前Kafka使用highwatermarker(高水位)机制保证数据的同步,但是基于高水位的同步数据可能会导致数据的丢失,不一致以及乱序。
要了解kafka数据同步机制,首先要了解如下概念
- LEO:log end offset 标识的是每个分区日志中最后一条消息的下一个位置,分区的每个副本都有自己的LEO.
- HW::high watermarker称为高水位线,所有分区的小于等于HW的数据都是已备份的,当所有节点都备份成功,Leader会更新水位线。
- ISR:In-sync-replicas,kafka的leader会维护一份处于同步的副本集合,如果在`replica.lag.time.max.ms`时间内系统没有发送fetch请求,或者已然在发送请求,但是在该限定时间内没有赶上Leader的数据就被剔除ISR列表。在Kafka-0.9.0版本剔除`replica.lag.max.messages`消息个数限定,因为这个会导致其他的Broker节点频繁的加入和退出ISR。
高水位会出现的问题
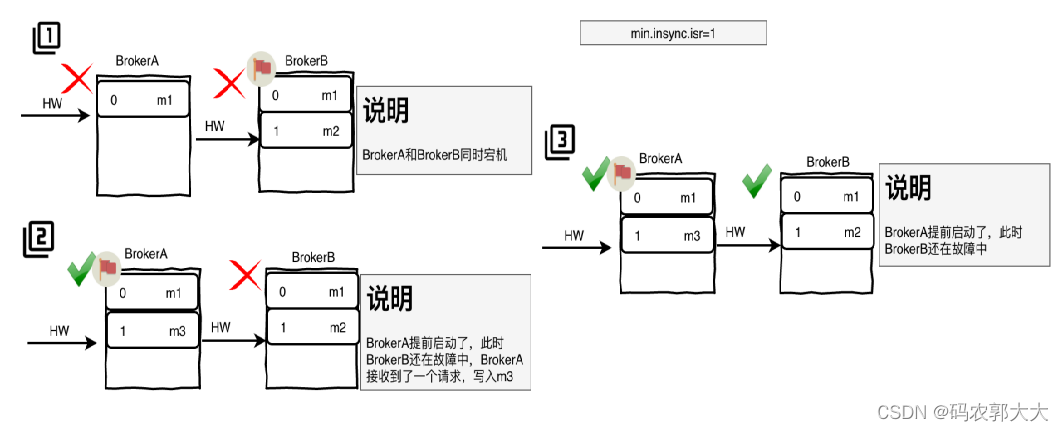
1、可能会出现数据不一致
- BrokerA为follower,BrokerB为Leader
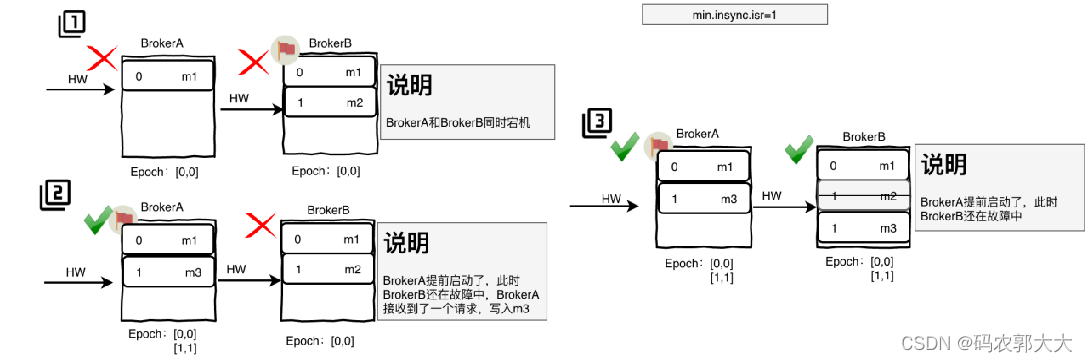
- 假设BrokerA中的HW=1,BrokerB中的HW=2,此时BrokerA和B同时宕机
- 此时BrokerA先重启了,此时BrokerA成为了Leader,同时BrokerA接收到了新请求,写入了新的消息日志m3,BrokerA的HW+1,HW=12
- 当BrokerB启动后,会向BrokerA发消息进行数据同步,由于只会更新高于水位线的数据,而此时BrokerA和BrokerB水位线一致,所以BrokerB不会更新数据,BrokerA与BrokerB中数据不一致
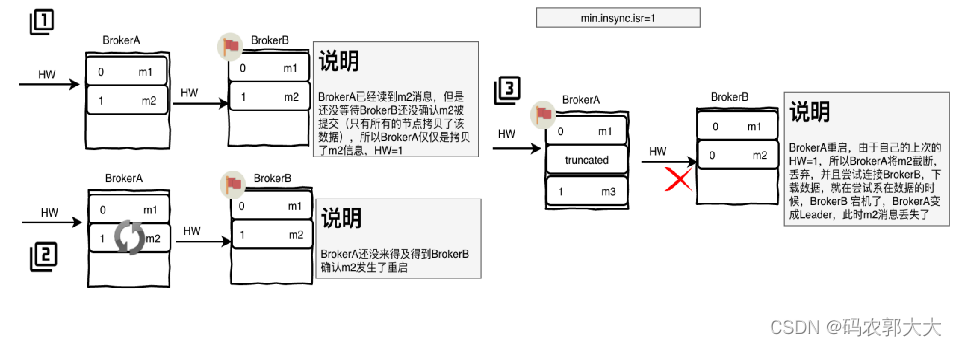
2、可能会出现数据丢失
- BrokerA为follower,BrokerB为Leader
- BrokerA读取到m2消息,此时只是BrokerA只是拷贝了消息,需要等待BrokerB确认提交m2消息,所以此时BrokerA的HW仍为1
- BrokerA还未等待BrokerB的确定提交,发生了宕机,当BrokerA重启后,发现BrokerB也宕机了,此时BrokerA成为了Leader,发现自己的HW=1,所以会截断大于HW的数据,此时m2消息丢失
由于0.11版本之前Kafka的副本备份机依赖HW存数据不一致问题和丢失数据问题,因此在0.11版本引入了 Leader Epoch同步机制解决这个问题。任意一个Leader持有一个LeaderEpoch。LeaderEpoch是一个由Controller管理的32位数字,存储在Zookeeper的分区状态信息中,会传递给每个新的Leader。Leader接受Producer请求数据上使用LeaderEpoch标记每个Message。然后,该LeaderEpoch编号将通过复制协议传播,并用于替换HW标记,作为消息截断的参考点,以下为Leader Epoch具体执行流程
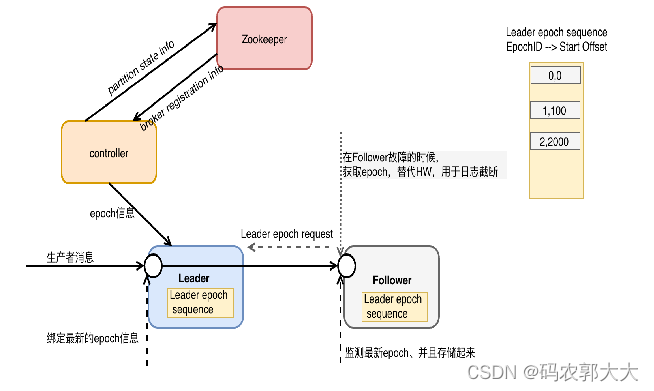
Lead Epoch实现原理
- 改进消息格式,每个消息集都带有一个4字节的Leader Epoch号。在每个日志目录中,会创建一个新的Leader Epoch Sequence文件,以此用来Leader Epoch的序列与消息的Start Offset。它也缓存在每个副本中,也缓存在内存中。
- 当Follower变成Leader时,它会将新的Leader Epoch和副本的LEO添加到Leader Epoch Sequence序列文件的末尾并刷新数据。给Leader产生的每个新消息集都带有新的“Leader Epoch”标记。
- Leader变成Followe时,会先从本地的Leader Epoch Sequence文件中加载数据,将数据存储在内存中,给相应的分区的Leader发送epoch 请求,该请求包含最新的EpochID,StartOffset信息.Leader接收到信息以后返回该EpochID所对应的LastOffset信息。该信息可能是最新EpochID的StartOffset或者是当前EpochID的Log End Offset信息。以此用来更新数据或者截断数据
同步情形
- Follower的Leader Epoch中的startOffset比Leader的小:Follower会向Leader发送epoch请求,Leadr会依次响应给Follower比Fllower大Leader Epoch Sequence,Follower更新本地的LED
- Follower的Leader Epoch的信息startOffset信息比Leader返回的LastOffset要大,Follower回去重置自己的Leader Epoch文件,将Offset修改为Leader的LastOffset信息,并且截断自己的日志信息。
- 注意:Follower在提取过程中,如果LeaderEpoch消息集大于其最新的LeaderEpoch,则会在其LeaderEpochSequence中添加新的LeaderEpoch和起始偏移量,并将Epoch数据文件刷新到磁盘。同时将Fetch的日志信息刷新到本地日志文件。
Lead Epoch 如何解决HW的数据不一致与数据丢失
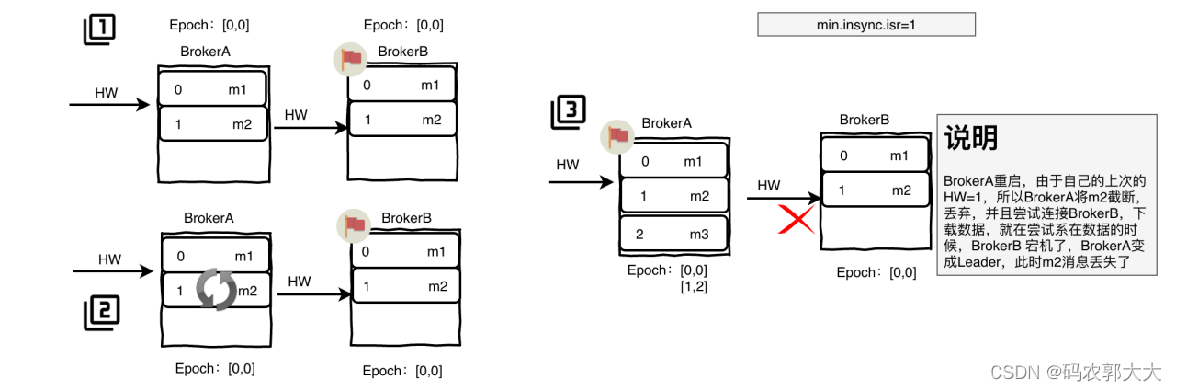
1、解决数据丢失
- BrokeA为Follower,Epoch :[0,0],BrokerB为Leader Epoch:[0,0]
- BrokerA读取到m2消息,此时只是BrokerA只是拷贝了消息,需要等待BrokerB确认提交m2消息,此时BrokerA发生了宕机
- BrokerA启动后,发现BrokerB发生了宕机,此时BrokerA变成了Leader,并接受了新的消息m3后,BrokerA它会将新的Leader Epoch和副本的LEO添加到Leader Epoch Sequence序列文件的末尾并刷新数据,此时Epoch:[1,2]
- BrokerB启动后,会向BrokerA发送epoch请求,由于BrokerB(Follower)的epoch小于BrokerA(Leader)的,leader会更新follower的epoch值,Follower会从最新的epoch的startOffset开始更新数据
2、解决数据不一致
- BrokerA为follower Epoch:[0,0],BrokerB为Leader Epoch:[0,0]
- 此时BrokerA和B同时宕机
- 此时BrokerA先重启了,此时BrokerA成为了Leader,同时BrokerA接收到了新请求,写入了新的消息日志m3,此时BrokerA的Epoch:[1,1]
- 当BrokerB启动后,会向BrokerA发Epoch请求,Leader返回Epoch为1的数据,即[1,1],BrokerB发现BrokerA是从offset=1开始更新,于是截断自己的本地offset为1的数据,并将leader的offset>=1的数据更新到本地,并更新本地的Epoch为[1,1]















 299
299











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









