







第一部分
Linux上查看内存的使用情况该用什么命令
free -mh
可以看到内存或者缓存情况
- total 总内存
- used 已用内存
- free 空闲内存
- buff/cache 已使用的缓存
- avaiable 可用内存

怎么清理已使用的缓存吗(buff/cache)?
sync; echo 3 > /proc/sys/vm/drop_caches
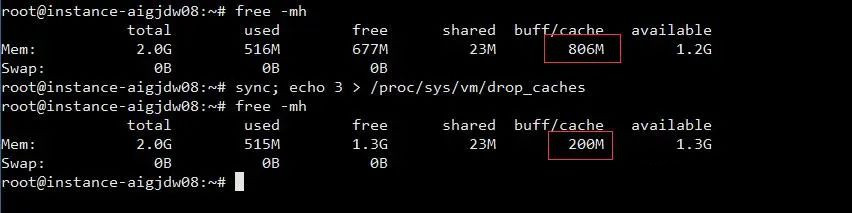
但是这句清楚缓存的语句不能在线上执行这条命令。
第二部分
SQL中的join可以根据某些条件把指定的表给结合起来并将数据返回给客户端
- inner join
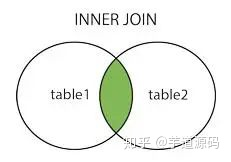
- left join
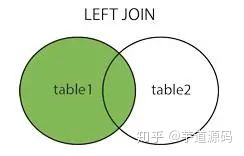
- right join

- full join

在项目开发中如果需要使用join语句,如何优化提升性能?
- 数据规模较小 全部干进内存就完事了嗷
- 数据规模较大
可以通过增加索引来优化join语句的执行速度 可以通过冗余信息来减少join的次数 尽量减少表连接的次数,一个SQL语句表连接的次数不要超过5次
第三部分
在执行join语句的时候必然要有一个比较的过程
逐条比较两个表的语句是比较慢的,因此我们可以把两个表中数据依次读进一个内存块中, 以MySQL的InnoDB引擎为例,使用以下语句我们必然可以查到相关的内存区域show variables like '%buffer%'
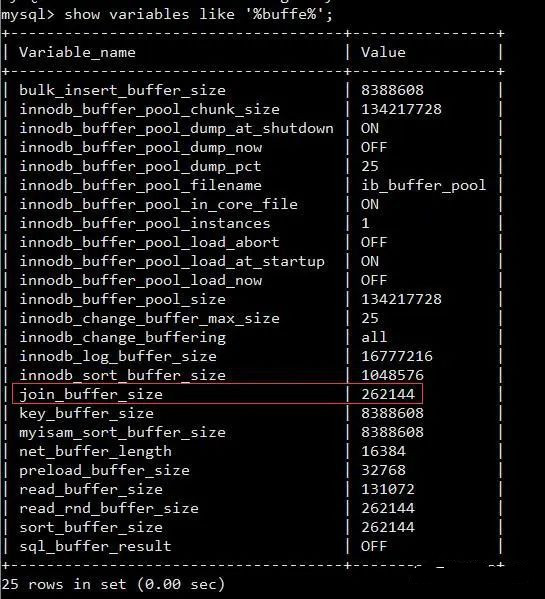
图中的,join_buffer_size的大小将会影响我们join语句的执行性能。
任何项目终究要上线,不可避免的要产生数据,数据的规模又不可能太小。大部分数据库中的数据最终要保存到硬盘上,并且以文件的形式进行存储。
以MySQL的InnoDB引擎为例
- InnoDB以页(page)为基本的IO单位,每个页的大小为16KB
- InnoDB会为每个表创建用于存储数据的.ibd文件
这意味着我们有多少表要连接就需要读多少个文件,虽然可以利用索引,但还是免不了频繁的移动硬盘的磁头。频繁的移动磁头会影响性能。
第四部分
面试官:再给你个机会,如果让你来实现Join算法你会怎么做?
我:无索引的话,嵌套循环就完事了嗷。有索引的话,则可以利用索引来提升性能.
面试官:说回join_buffer 你认为join_buffer里面存储的是什么?
我:在扫描过程中,数据库会选择一个表把他要返回以及需要进行和其他表进行比较的数据放进join_buffer
面试官:有索引的情况下是怎么处理的?
我:这个就比较简单了,直接读取两个表的索引树进行比较就完事了嗷,我这边介绍一下无索引的处理方式
个人意见
上学时,数据库老师最喜欢考数据库范式,直到上班才学会一切以性能为准,能冗余就冗余,实在冗余不了的就join如果join真的影响到性能。试着调大你的join_buffer_size, 或者换固态硬盘。















 6962
6962











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









