







推荐系统 使用surprise库基于协同过滤的方法实现
自动交叉验证法
from surprise import SVD
from surprise import Dataset
from surprise.model_selection import cross_validate
data = Dataset.load_builtin('ml-100k') #加载movielens-100k数据集
algo = SVD() #使用SVD算法
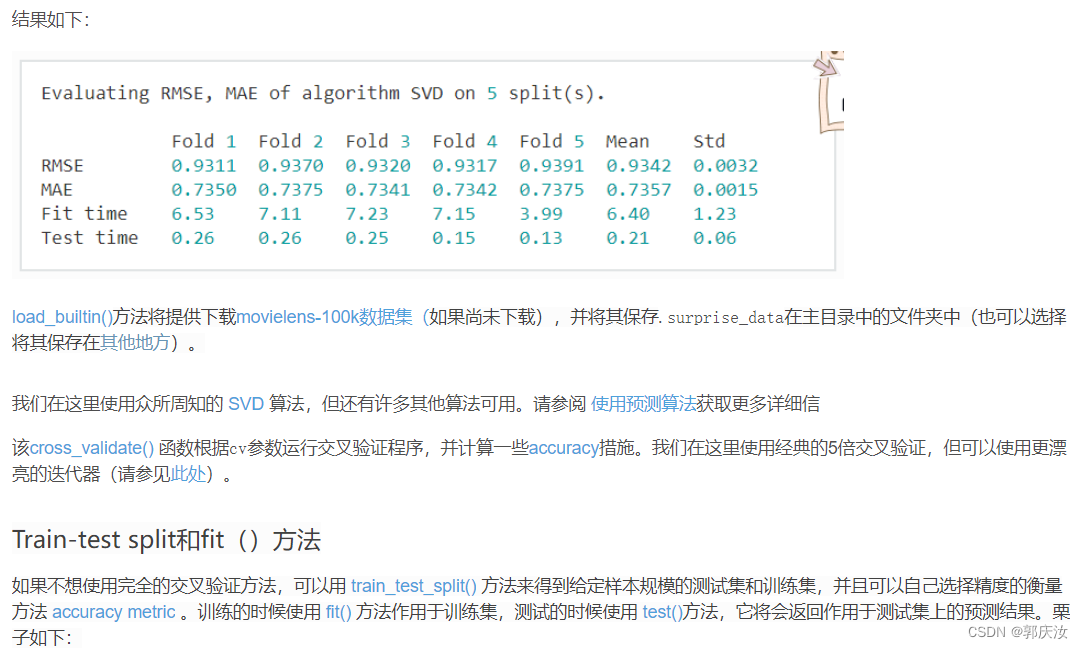
cross_validate(algo, data, measures=['RMSE', 'MAE'], cv=5, verbose=True) #采用5折交叉验证并打印结果
from surprise import SVD
from surprise import Dataset
from surprise import accuracy
from surprise.model_selection import train_test_split
data = Dataset.load_builtin('ml-100k') #加载movielens-100k数据集
trainset, testset = train_test_split(data, test_size=.25) #随机抽样选出训练集和测试集,这里选取了25%作为测试集
algo = SVD() #使用SVD算法
algo.fit(trainset) #做训练
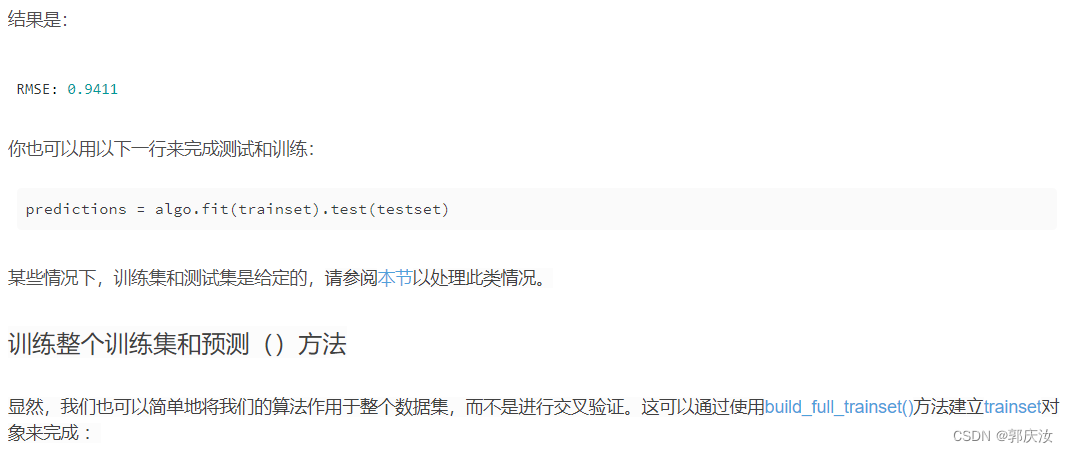
predictions = algo.test(testset) #做测试
accuracy.rmse(predictions) #计算RMSE
from surprise import KNNBasic
from surprise import Dataset
data = Dataset.load_builtin('ml-100k') #加载movielens-100k数据集
trainset = data.build_full_trainset() #纠正/取出训练集
algo = KNNBasic() #建立算法并训练
algo.fit(trainset)

uid = str(196) # 原始user id (在评分文件中的). 注意,是个字符串
iid = str(302) # 原始item id (其他同上)
pred = algo.predict(uid, iid, r_ui=4, verbose=True) #对某一个具体的user和item给出预测

使用自定义数据集

from surprise import BaselineOnly
from surprise import Dataset
from surprise import Reader
from surprise.model_selection import cross_validate
file_path = os.path.expanduser('~/.surprise_data/ml-100k/ml-100k/u.data')#数据集文件所在目录
reader = Reader(line_format='user item rating timestamp', sep='\t')
data = Dataset.load_from_file(file_path, reader=reader)
cross_validate(BaselineOnly(), data, verbose=True) #现在可以使用这个数据集,例如调用cross_validate

如下所示:
import pandas as pd
from surprise import NormalPredictor
from surprise import Dataset
from surprise import Reader
from surprise.model_selection import cross_validate
# Creation of the dataframe. Column names are irrelevant.
ratings_dict = {'itemID': [1, 1, 1, 2, 2],
'userID': [9, 32, 2, 45, 'user_foo'],
'rating': [3, 2, 4, 3, 1]}
df = pd.DataFrame(ratings_dict)
# A reader is still needed but only the rating_scale param is requiered.
reader = Reader(rating_scale=(1, 5))
# The columns must correspond to user id, item id and ratings (in that order).
data = Dataset.load_from_df(df[['userID', 'itemID', 'rating']], reader)
# We can now use this dataset as we please, e.g. calling cross_validate
cross_validate(NormalPredictor(), data, cv=2)
使用交叉验证迭代器

from surprise import SVD
from surprise import Dataset
from surprise import accuracy
from surprise.model_selection import KFold
data = Dataset.load_builtin('ml-100k') #加载数据集
# define a cross-validation iterator
kf = KFold(n_splits=3) #定义交叉验证迭代器
algo = SVD()
for trainset, testset in kf.split(data):
# 训练并测试算法
algo.fit(trainset)
predictions = algo.test(testset)
# 计算并打印RMSE
accuracy.rmse(predictions, verbose=True)

from surprise import SVD
from surprise import Dataset
from surprise.model_selection import GridSearchCV
data = Dataset.load_builtin('ml-100k')
param_grid = {'n_epochs': [5, 10], 'lr_all': [0.002, 0.005],
'reg_all': [0.4, 0.6]}
gs = GridSearchCV(SVD, param_grid, measures=['rmse', 'mae'], cv=3)
gs.fit(data)
# best RMSE score
print(gs.best_score['rmse'])
# combination of parameters that gave the best RMSE score
print(gs.best_params['rmse'])

# 可以使用产生最优RMSE的算法
algo = gs.best_estimator['rmse']
algo.fit(data.build_full_trainset())
# coding=utf-8
# @Time : 2019/12/7 10:31
# @Author : Z
# @Email : S
# @File : 5.0surprise_film.py
#Surprise库使用KNNBaseline算法进行电影推荐
from __future__ import (absolute_import, division, print_function, unicode_literals)
import os
import io
from surprise import KNNBaseline
from surprise import Dataset,Reader
import logging
# level: 设置日志级别,默认为logging.WARNING
# format: 指定输出的格式和内容,format可以输出很多有用信息,如上例所示:
# %(levelno)s: 打印日志级别的数值
# %(levelname)s: 打印日志级别名称
# %(pathname)s: 打印当前执行程序的路径,其实就是sys.argv[0]
# %(filename)s: 打印当前执行程序名
# %(funcName)s: 打印日志的当前函数
# %(lineno)d: 打印日志的当前行号
# %(asctime)s: 打印日志的时间
# %(thread)d: 打印线程ID
# %(threadName)s: 打印线程名称
# %(process)d: 打印进程ID
# %(message)s: 打印日志信息
# datefmt: 指定时间格式
logging.basicConfig(level=logging.INFO,
format='%(asctime)s %(filename)s[line:%(lineno)d] %(levelname)s %(message)s',
datefmt='%a, %d %b %Y %H:%M:%S')
# 训练推荐模型 步骤:1
def getSimModle():
# Load the movielens‐100k dataset
file_path = os.path.expanduser('./u.data')
# 告诉文本阅读器,文本的格式是怎么样的
#定义一个Reader对象来解析文件或数据框
reader = Reader(line_format='user item rating timestamp', sep='\t')
#从用户文件加载数据文件
data = Dataset.load_from_file(file_path, reader)
#获取训练集,这里取数据集全部数据
trainset = data.build_full_trainset()
#使用pearson_baseline方式计算相似度 False以item为基准计算相似度 本例为电影之间的相似度
# Surprise中基于近邻的方法(协同过滤)可以设定不同的度量准则。具体如下:
# 1:cosine 用户(items)之间的cosine相似度
# 2:msd 用户(items)之间的均方差误差
# 3:pearson 用户(items)之间的皮尔逊相关系数
# 4:pearson_baseline 计算用户(item)之间的(缩小的)皮尔逊相关系数,使用基准值进行居中而不是平均值。
sim_options = {'name': 'pearson_baseline', 'user_based': False}
bsl_options = {'method': 'als', #sgd 随机梯度下降法 #als交替最小二乘法
'n_epochs': 20,
}
#使用KNNBaseline算法
#一种基本的协同过滤算法
# k(int):要考虑的(最大)邻居数聚合。默认为40个
# min_k(int):他要考虑的邻居的最少数量聚合,如果没有足够的邻居聚合,设置为零(因此预测结果相当于基线)。默认值为“1”。
# sim_options:相似性度量的选项字典
# bsl_options:基线估计的选项字典计算
algo = KNNBaseline(40,1,sim_options=sim_options,bsl_options=bsl_options)
#训练模型
algo.train(trainset)
return algo
# 获取id到name的互相映射 步骤:2
def read_item_names():
"""
获取电影名到电影id 和 电影id到电影名的映射
"""
#os.path.expanduser(path) 把path中包含的"~"和"~user"转换成用户目录
file_name = (os.path.expanduser('.') +'/u.item')
rid_to_name = {}
name_to_rid = {}
with io.open(file_name, 'r', encoding='utf-8') as f:
for line in f:
line = line.split('|')
rid_to_name[line[0]] = line[1]
name_to_rid[line[1]] = line[0]
return rid_to_name, name_to_rid
# 基于之前训练的模型 进行相关电影的推荐 步骤:3
def showSimilarMovies(algo, rid_to_name, name_to_rid):
# 获得电影Toy Story (1995)的raw_id
toy_story_raw_id = name_to_rid['Beauty and the Beast (1991)'] #Beauty and the Beast(1991) 或 Toy Story (1995)
logging.debug('raw_id=' + toy_story_raw_id)
#把电影的raw_id转换为模型的内部id
toy_story_inner_id = algo.trainset.to_inner_iid(toy_story_raw_id)
#将信息打印到控制台上
logging.debug('inner_id=' + str(toy_story_inner_id))
#通过模型获取推荐电影 这里设置的是10部
toy_story_neighbors = algo.get_neighbors(toy_story_inner_id, 10)
logging.debug('neighbors_ids=' + str(toy_story_neighbors))
#模型内部id转换为实际电影id
#列表表达式
neighbors_raw_ids = [algo.trainset.to_raw_iid(inner_id) for inner_id in toy_story_neighbors]
#通过电影id列表 或得电影推荐列表
neighbors_movies = [rid_to_name[raw_id] for raw_id in neighbors_raw_ids]
print('The 10 nearest neighbors of Toy Story are:')
for movie in neighbors_movies:
print(movie)
if __name__=="__main__":
# 获取id到name的互相映射
rid_to_name, name_to_rid = read_item_names()
# 训练推荐模型
algo = getSimModle()
##显示相关电影
showSimilarMovies(algo, rid_to_name, name_to_rid)


















 2229
2229

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









